データウェアハウス

データウェアハウスとは?
データウェアハウス(DWH)は、複数のソースから得られた最新データや履歴データをビジネスに適した形で蓄積し、知見の取得やレポート作成を容易にするデータ管理システムです。データウェアハウスは通常、ビジネスインテリジェンス(BI)、分析、レポーティング、データアプリケーション、機械学習(ML)およびデータ分析のためのデータ準備に使用されます。
データウェアハウスでは、POS システ�ム、在庫管理システム、マーケティングや販売データベースなどの業務システムに蓄積されたデータを、迅速かつ容易に分析可能です。データは、オペレーショナルデータストアを経由する場合があり、データウェアハウスでレポート作成のために使用する前にデータクレンジングを行い、データ品質を確保する必要があります。
Databricks についてさらに詳しく


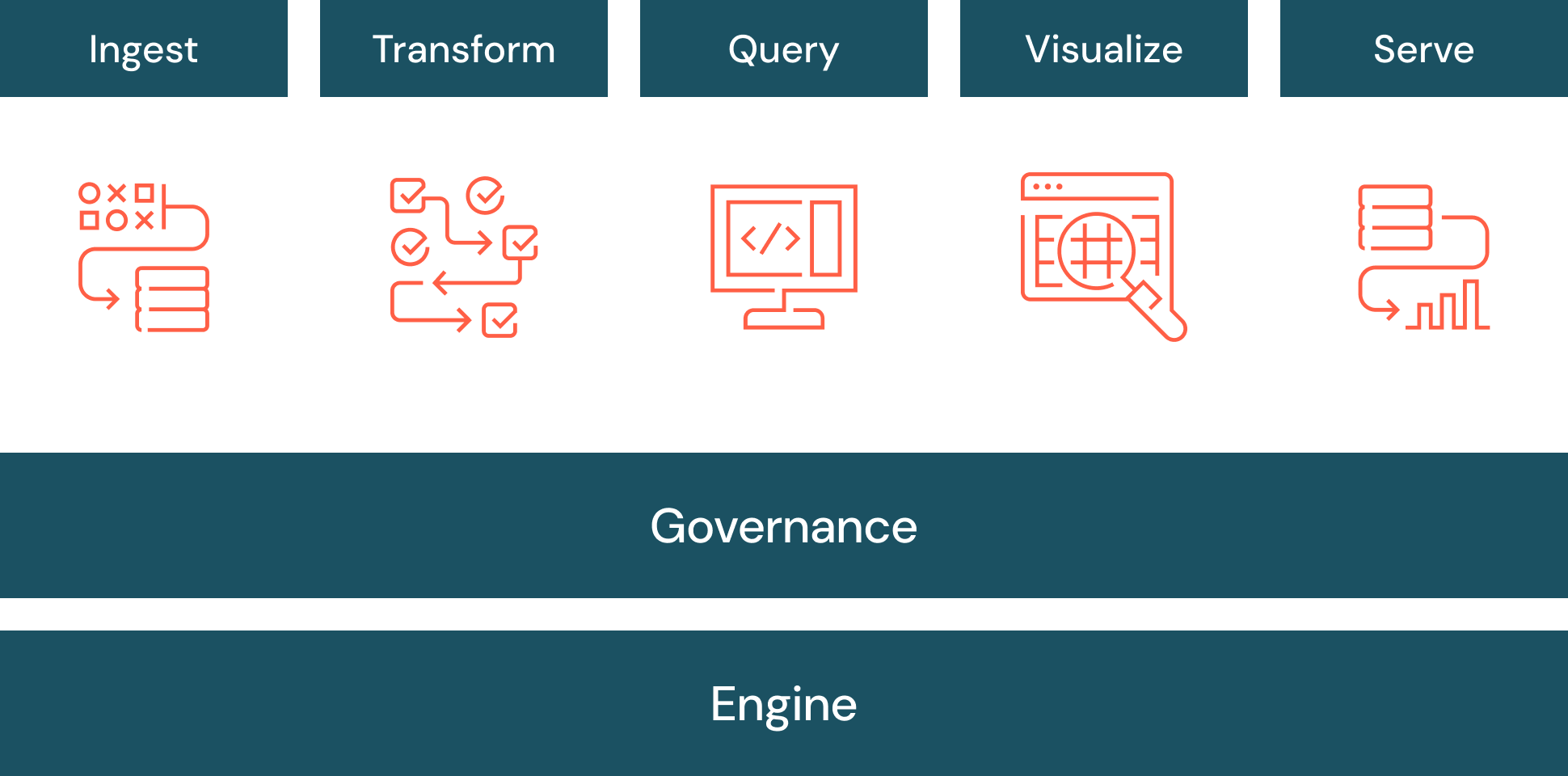
データウェアハウスの利用用途
データウェアハウスは、BI、分析、レポーティング、データアプリケーション、機械学習用データの準備、および運用データベースからデータを抽出して要約するデータ分析で使用されます。トランザクション・データベースから直接分析することが難しい情報でも、データウェアハウスを利用することで分析することができます。例えば、経営陣が各営業担当者が商品カテゴリーごとに月次で生み出した収益の合計を知りたい場合などです。トランザクション・データベースはこのようなデータを捕捉しないかもしれませんが、データウェアハウスは捕捉します。
データウェアハウスの種類は?
- 従来のデータウェアハウス:このタイプのデータウェアハウスは、構造化されたデータのみを保存します。DWH の構造により、レポートや分析のためのデータに迅速かつ容易にアクセス可能(使いやすい)
- インテリジェントデータウェアハウス:これは、レイクハウス・アーキテクチャ上に構築され、インテリジェントで自動的に最適化されるプラットフォームを備えた、最新のタイプのデータウェアハウスです。インテリジェントデータウェアハウスは、AIやMLモデルへのアクセスを提供するだけでなく、クエリ、ダッシュボードの作成、パフォーマンスとサイジングの最適化を支援するためにAIを使用します。
データウェアハウスのアーキテクチャ
データウェアハウスのアーキテクチャの一般的なモデルは多層構造です。このアーキテクチャーは、データウェアハウスの父とも言われるコンピューター科学者、ビル・インモンによって作られました。
下段
データウェアハウス・アーキテクチャの最下層は、データソースとデータストレージで構成されます。この階層には、API、ゲートウェイ、ODBC、JDBC、OLE-DBなどのデータ・アクセス・メソッドが含まれます。データの取り込みやETLも最下層に含まれます。
中間層
データウェアハウス・アーキテクチャの中間層は、リレーショナル(ROLAP)または多次元(MOLAP)のOLAPサーバーで構成されます。この2つのタイプは、ハイブリッドOLAP(HOLAP)に組み合わせることができます。
トップ
データウェアハウス・アーキテクチャの最上位層は、クエリ、BI、ダッシュボード、レポート、分析のためのフロントエンド・クライアントで構成されます。
データウェアハウスの3つのバリエーションとは?
- エンタープライズデータウェアハウス(EDW):組織内のさまざまなチームが使用する集中型のデータウェアハウス。BI、アナリティクス、レポーティングの単一ソースとなることがよくあります。
- オペレーショナルデータストア(ODS):データウェアハウスの一種で、最新のオペレーショナルデータやトランザクションデータに焦点を当てたもの。
- データマート:データウェアハウスの簡易版で、単一の事業部門(LOB)または単一のプロジェクトに対応するもの。 データマートはEDWよりも小規模ですが、組織が成長し、LOBがセルフサービスを望むようになると、データマートの数は通常増加します。
データレイク vs. データベース vs. データウェアハウス
データレイクとデータウェアハウスの違いは何ですか?
データレイクとデータウェアハウスは、データを管理・保存するための2つの異なるアプローチです。
データレイクとは、膨大な量の生データをそのままの形式で保存できる非構造化または半構造化データリポジトリのことです。データレイクは、構造化、半構造化、非構造化などあらゆる種類のデータを、事前に定義されたスキーマなしで取り込み、保存するように設計されています。データは多くの場合、そのままの形式で保存され、クレンジングや変換、統合が行われないため、大量のデータの保存やアクセスが容易になります。
一方、従来のデータウェアハウスは、ビジネスインテリジェンスと分析のための単一の真実のソースを提供することを目的として、さまざまなソースからのデータを適切に整理された方法で格納する構造化されたリポジトリです。データはクレンジングされ、変換され、クエリと分析に最適化されたスキーマに統合されます。
レイクハウスアーキテクチャを採用したインテリジェントなデータウェアハウスは、ビジネス・インテリジェンスとアナリティクスのための単一ソース・オブ・トゥルースも提供します。構造化データ、半構造化データ、非構造化データを格納することで、従来のデータウェアハウスを拡張します。 データ品質やしきい値アラートなどのデータ管理機能も含まれています。
データウェアハウスとデータベースの違いは何ですか?
データベースは構造化されたデータの集合体であり、テキストや数値だけでなく、画像や動画などにも及びます。 多くの人は、このデータベース管理システムをその頭文字で呼びます:DBMS。DBMSは、アプリケーションや分析に必要なデータのストレージシステムです。
一方、従来のデータウェアハウスは、ビジネスインテリジェンスと分析のためのデータを提供する構造化されたリポジトリです。データはクレンジング、変換され、一般的な集計の追加など、クエリや分析に最適化されたスキーマに統合されます。
データレイク、データウェアハウス、データレイクハウスの違いは何ですか?
データレイクハウスは、両者の長所を組み合わせたハイブリッドなアプローチです。これは、従来のデータウェアハウスとデータレイクの機能を統合プラットフォームに統合した最新のデータアーキテクチャです。データレイクのように生のデータをそのままの形式で保存できる一方、データウェアハウスのようにデータ処理や分析機能も提供します。
要約すると、データレイク、従来のデータウェアハウス、データレイクハウスの主な違いは、データの管理と保存に対するアプローチです。従来のデータウェアハウスは、あらかじめ定義されたスキーマで構造化されたデータを保存し、データレイクは生のデータをそのままの形式で保存します。
データレイク | レイクハウス | 従来のデータウェアハウス | |
|---|---|---|---|
データのタイプ | すべてのタイプ:構造化/半構造化/非構造化(生)データ | すべてのタイプ:構造化/半構造化/非構造化(生)データ | 構造化データのみ |
コスト | $ | $ | $$$ |
フォーマット | オープン | オープン | クローズド、独自 |
スケーラビリティ | あらゆるタイプ/量のデータを低コストでスケール | あらゆるタイプ/量のデータを低コストでスケール | ベンダーコストが爆発的に増大 |
ユーザー | 限定:データサイエンティスト | 統合型:あらゆるタイプのユーザー | 限定:データアナリスト |
信頼性 | 低品質、データスワンプ | データスワンプからの脱却 | データスワンプからの脱却 |
使いやすさ | 膨大な量の未加工データの探索には、データの整理・カタログ化のためのツールが必要(使いにくい) | データレイクの広範なユースケースで、DWH のシンプルさと構造を提供(使いやすい) | DWH の構造により、レポートや分析のためのデータに迅速かつ容易にアクセス可能(使いやすい) |
性能 | 低 | 高 | 高 |
データレイクはデータウェアハウスを置き換えることができますか?
いいえ、できません。データレイクとデータウェアハウスは、データを管理・保管するための2つの異なるアプローチであり、それぞれに長所と短所があります。データレイクは、高度な分析のための生データを提供することでデータウェアハウスを補完することはできますが、従来の意味でデータウェアハウスを完全に置き換えることはできません。その代わり、データレイクとデータウェアハウスは互いに補完し合うことができます。データレイクは高度な分析のための生データのソースとして機能し、データウェアハウスはレポーティングと分析のための構造化され、整理され、信頼できるビジネスデータのソースを提供します。
データレイクは、Delta Lake や Apache Iceberg™ などのオープンデータ形式での信頼性とパフォーマンスにより、従来のデータウェアハウスを置き換えることができるデータレイクハウスの基礎となります。
データレイクハウスは従来のデータウェアハウスを置き換えることができますか?
はい。データレイクハウスは、データウェアハウスとデータレイクの利点を統合プラットフォームに統合した最新のデータアーキテクチャです。データレイクハウスはオープンなデータレイク上に構築され、データレイクとデータウェアハウスの両方の機能を単一のプラットフォームで提供するため、従来のデータウェアハウスの代わりとして機能します。
データレイクハウスは、データレイクのように生データをそのままの形式で保存できる一方、データウェアハウスのようにデータ処理や分析機能も提供します。また、スキーマ・オンリード・アプローチを提供し、データ処理やクエリに柔軟性を持たせています。データレイクとデータウェアハウスを単一のプラットフォームに統合することで、柔軟性、拡張性、費用対効果が向上します。
最新のデータウェアハウスとは?
データウェアハウスは進化し続けています。最新のデータウェアハウスは、AIのような新しいテクノロジーを使用しているため、インテリジェントデータウェアハウスとも呼ばれています。インテリジェント・データウェアハウスは、従来のデータウェアハウス・アーキテクチャではなく、オープン・データレイクハウス・アーキテクチャを活用します。インテリジェントなデータウェアハウスは、データの独自性を理解し、低レイテンシーと高同時性を実現するためにプラットフォームを自動最適化します。インテリジェントなデータウェアハウスには、セキュリティ、コントロール、ワークフローに関する統一されたガバナンスも必要です。インテリジェントなデータウェアハウスは、AIを使用してクエリを生成し、間違いを修正し、視覚化などを提案します。
データウェアハウスにおけるETLとは?
データウェアハウスにはデータが必要です。そのデータは、データウェアハウスにロードされなければなりません(または、レイクハウス・フェデレーションと呼ばれる概念で参照されなければなりません)。ソースシステムからデータを抽出し、データを変換し、データウェアハウスにデータをロードするプロセスをETL(抽出、変換、ロード)と呼びます。ETLは通常、複数のソースからの構造化データを事前に定義されたスキーマに統合するために使用されます。
クエリフェデレーションは、複数のソースから、複数のクラウドにまたがるデータソースに対してクエリを実行するために使用されるETLのスタイルです。すべてのデータを統一されたシステムに移行することなく、1つの場所からすべてのデータを表示し、照会することができます。この概念はデータ仮想化と呼ばれることもあります。
データウェアハウスにおけるディメンジョンとは何ですか?
データウェアハウスのディメンジョンは、構造化されたラベリング情報でデータを記述するために使用されます。ディメンジョンは、情報を使用して、フィルタ、グループ化、およびラベル付けを行います。例えば、ディメンジョンは、顧客や製品などのビジネス・エンティティになります。
データウェアハウスにおけるファクトとは何ですか?
データウェアハウスのファクトは、データを数値で定量化するために使用されます。例えば、顧客からの注文や財務データなどです。
データウェアハウスにおける次元モデリングとは?
次元モデリングは、データを次元とファクトに整理するデータウェアハウジングの手法です。ディメンションモデリングは、重要なビジネスプロセスを特定し、それらのビジネスプロセスをサポートするデータウェアハウスをモデリングします。
データウェアハウスにおけるスタースキーマとは何ですか?
スタースキーマとは、データベース内のデータを整理し、理解・分析しやすくするために使用される多次元データモデルです。スタースキーマは、データウェアハウス、データベース、データマート、その他のツールに適用できます。スタースキーマの設計は、大規模なデータセットへのクエリを実行するために最適化されています。
1990 年代にラルフ・キンボールによって発表されたスタースキーマは、反復的なビジネス定義の重複を減らすことによってデータの保存や履歴の管理、データの更新を効率的に行い、データウェアハウスでのデータの集計やフィルタリングを高速に行うことができます。
企業が期待するデータウェアハウスのメリットとは?
- 多くの情報源から得られたデータの統合。 データウェアハウスは、ユーザーが何十、何百もの個別のデータストアに接続する必要がなく、すべてのデータへの単一アクセスポイントになります。
- ヒストリカルインテリジェンス:データウェアハウスは、多くのソースからのデータを統合し、過去のトレンドを表示します。
- 分析処理とトランザクションデータベースの分離:この 2 つの処理を分離することで、両システムのパフォーマンスを向上させます。
- データの品質、一貫性、正確性:整形式データウェアハウスでは、命名規則の一貫性、さまざまな製品タイプ、言語、通貨などのコードなど、データに関する標準的なセマンティクスを使用します。
- SQLの専門知識がなくても、誰でもデータから答えを見つけることができます。
データウェアハウスの課題
どのようなタイプのデータウェアハウスを使用しても、課題は残ります:
- データとAI資産にまたがるバラバラのツールが断片的なアプローチを生み出し、データガバナンスを損ないます。
- クエリの作成、データ構造の理解、最適なデータソースの検索と接続など、ユーザーには専門的なスキルとトレーニングが必要です。
- データウェアハウスが大きくなると、処理速度が遅くなります。クラウドでは、クラウドのコンピュート・コストですぐに高くつきます。
スケーラビリティとパフォーマンス
データ量が増大する中、レイクハウスアーキテクチャは、ストレージとは独立してコンピューティング機能を分散し、最適なコストで一貫したパフォーマンスを維持することを目指します。必要に応じてデータ運用を拡張できるような、弾力性のあるプラットフォームが必要です。スケーラビリティはさまざまな次元に及びます。
- サーバーレス:プラットフォームは、必要なコンピューティング能力に基づいてワークロードを調整し、弾力的に拡張できるようにする必要があります。このような動的なリソース割り当てにより、ピーク時でも迅速なデータ処理と分析が保証されます。
- 並行処理:プラットフォームは、サーバーレス・コンピューティングとAI主導の最適化を活用して、データ処理とクエリの同時実行を促進する必要があります。これにより、複数のユーザーやチームがパフォーマンスの制約を受けることなく、分析タスクを同時に実行できるようになります。
- ストレージ:プラットフォームはデータレイクとシームレスに統合し、データの可用性と信頼性を確保しながら、膨大なデータ量のコスト効率の高いストレージを容易にする必要があります。また、データストレージを最適化してパフォーマンスを向上させ、ストレージ費用を削減する必要があります。
スケーラビリティは不可欠ですが、パフォーマンスによって補完されます。プラットフォームは、パフォーマンスを最適化するために、AIによるさまざまな最適化を使用する必要があります。
- 最適化されたクエリ:プラットフォームは機械学習の最適化技術を使用してクエリの実行を高速化する必要があります。自動インデックス作成、キャッシング、述語プッシュダウンを活用して、クエリを効率的に処理し、迅速な洞察を実現します。
- オートスケール:プラットフォームは、ワークロードに合わせてサーバーレスリソースをインテリジェントにスケーリングし、最適なクエリパフォーマンスを維持しながら、使用するコンピュートに対してのみ支払いが発生するようにします。
- 高速なクエリパフォーマンス:プラットフォームは、データ取り込み、ETL、ストリーミング、データサイエンス、インタラクティブなクエリなど、データレイク上で非常に高速なクエリパフォーマンスを低コストで提供する必要があります。
- Delta Lake:このプラットフォームは、データストレージに関する一般的な課題を解決するためにAIモデルを使用する必要があり、時間の経過とともに変化するテーブルを手動で管理することなく、より高速なパフォーマンスを得ることができます。
- 予測最適化:お客様のデータを自動的に最適化し、最高のパフォーマンスと価格を実現します。 お客様のデータ使用パターンから学習し、適切な最適化プランを構築し、超最適化されたサーバーレスインフラ上で最適化を実行します。
従来のデータウェアハウスの課題
従来のデータウェアハウスには、さらなる課題があります:
- 非構造化データのサポート:画像、テキスト、IoT データなどの非構造化データ、HL7、JSON、XML などのメッセージングフレームワークには対応していません。ガートナー社の推定では、組織のデータの最大 80% が非構造化データであるにもかかわらず、従来のデータウェアハウスでは高度に構造化されたクリーンなデータしか格納できません。非構造化データを使用して AI を活用したいと考える組織は、他のツールに目を向ける必要があります。
- AI や機械学習のサポート:データウェアハウスは、履歴レポート、BI、クエリなどの一般的な DWH ワークロードのために設計、最適化されており、機械学習ワークロードをサポートするために設計されていません。
- SQL のみをサポート:データウェアハウスでは、アプリ開発、データサイエンス、機械学習で利用される Python や R をサポートしません。
- 重複データ:多くの企業では、データレイクに加えて、データウェアハウス、サブジェクトエリアまたは(部門)データマートを使用しています。その結果、データの重複や冗長な ETL が発生し、信頼できるソースが一意に定まりません。
- 同期が難しいレイクとウェアハウスの間でデータの2つのコピーを同期させ続けることは、複雑さと脆弱性を追加し、管理するのが大変です。データのドリフトは、一貫性のない報告や誤った分析の原因となります。
- クローズドな独自フォーマットは、ベンダーのロックインを増加させます:ほとんどの企業データウェアハウスは、オープンソースやオープンスタンダードに基づくフォーマットではなく、独自のデータフォーマットを使用しています。 このため、ベンダーロックインが進み、他のツールでのデータ分析が困難または不可能になり、データの移行も難しくなります。
- 高い:市販のデータウェアハウスでは、データの保管や分析に費用がかかります。そのため、ストレージとコンピュート・コストは依然として緊密に結合しています。レイクハウスでコンピュートとストレージを分離すれば、必要に応じてどちらかを独立して拡張できます。
- 個別のレポーティングソリューション:多くの場合、個別のレポーティングソリューションのすべての機能を使用することなく、データに簡単な質問を投げかける必要があります。例えば、「第3四半期の売上高は?」といった質問です。
- テーブルフォーマットの固定化:ビジネスラインやユースケースを横断する柔軟性が必要ですが、データウェアハウスでは特定のテーブルフォーマット(Apache Icebergなど)に固定化されることがあります。
独自のテーブルフォーマット
表形式は、データウェアハウスの利点をデータレイクにもたらす主要な技術です。テーブル・フォーマットは、時間経過に伴うテーブルの状態を表す方法で、データとメタデータを整理します。
独自のテーブル形式は、通常、クラウド環境で使用され、分析、レポート作成、機械学習などの作業では、大規模なデータセットへの効率的なアクセスが不可欠です。特定のベンダーは、ストレージサイズの縮小、読み取り/書き込み速度の短縮、バージョン管理の追加など、特定の問題に対処するためのファイル形式や構造を作成します。
Databricks 独自のフォーマットである Delta Lake は、データレイクとデータウェアハウスの両方の長所を組み合わせた、オープンソース、オープンフォーマットのデータ管理およびガバナンスレイヤーです。 主な特徴は以下の通りです:
- ACID トランザクション:Delta Lake は、更新、削除、挿入のような並行処理の実行中であっても、一貫したデータを可能にします。これにより、データは常に最新で一貫性のあるものとなります。
- スケーラブルなメタデータ:データセットが大きくなるにつれ、Delta Lake はそれに合わせて拡張し、ユーザーはメタデータをテーブルに保存することができます。その結果、データの変化を追跡し、共有することが容易になります。
- スキーマの強制:Delta Lake は、すべてのデータがテーブル内の特定のフォーマットに準拠していることを保証します。
- Apache Spark™ との互換性 :Delta Lakeはオープンソースであるため、Apache Spark APIと互換性があります。コードを変更することなく、既存のSparkアプリケーションでDelta Lakeを使用することができます。
オープンテーブルフォーマット(OTF)のロックインや、Delta Lake・Apache Icebergのどちらかを選択しなければならないことを避けるために、Delta Lake UniFormのようなユニバーサルフォーマットを使用することができます。
マルチクラウド
お客様の組織では、コストを最適化するため、またはデータセットの特定のニーズに適合させるために、データを2つ以上のクラウドプロバイダーに分散している場合があります。このため、データが異なるネットワークや異なるスキーマで管理されている場合、問題が発生する可能性があります。
最新のレイクハウスアーキテクチャは、単一のクラウドシステムに縛られることなく、複数のクラウドサービスプロバイダーにまたがってデータを管理することができます。これにより、組織は以下のことが可能になります。
- データの分散:さまざまなクラウドプラットフォームにデータを分散することで、予算やコンプライアンスに最適なサービス群を見つけることができます。
- 耐障害性の強化:マルチクラウド環境は、ワークロードとバックアップを複数のプロバイダーに分散することで、データの可用性を高めます。これは、1つのクラウド・サービスに障害や予期せぬダウンタイムが発生した場合に非常に重要になります。
- データ統合:マルチクラウドをサポートするデータウェアハウスは、これらのソースからのデータをリアルタイムで統合し、質の高いデータとより良い意思決定へのアクセスを提供します。
- コンプライアンス:マルチクラウドアーキテクチャは、データを地理的にどこに保存するか、または複数のクラウドサービス間でデータをどのように保存するかを規定する、特定の法的要件や規制要件を満たすのに役立ちます。
インテリジェントデータウェアハウスの課題
インテリジェントデータウェアハウスには、異なる課題があります:
- この現代的なアプローチはまだ進化しているため、戦略を進化させる意欲のある組織が必要です。
- AIポリシー:組織は、インテリジェントデータウェアハウスのAI機能を使用できる人やシステムを管理するポリシーを設定する必要があります。
Databricksはデータウェアハウスのためにどのようなソリューションを持っていますか?
Databricksは、オープンデータレイクハウスアーキテクチャに基づいて構築されたインテリジェントデータウェアハウス、Databricks SQLを提供しています。Databricks SQLは、ML、データガバナンス、ワークフローなどを含む統合プラットフォーム、データ・インテリジェンス・プラットフォームの一部です。すべてのデータにオープンで統一された基盤を使用することで、ML/AI、ストリーミング、オーケストレーション、ETL、リアルタイム分析、データウェアハウス、統一されたセキュリティ、ガバナンス、カタログ、さらに信頼性と共有のための統一されたデータストレージを同じプラットフォームで利用できます。さらに、Databricks データ・インテリジェンス・プラットフォームはオープンデータレイクハウスアーキテクチャに基づいて構築されているため、ログ、テキスト、オーディオ、ビデオ、画像など、あらゆる生データを保存することができます。
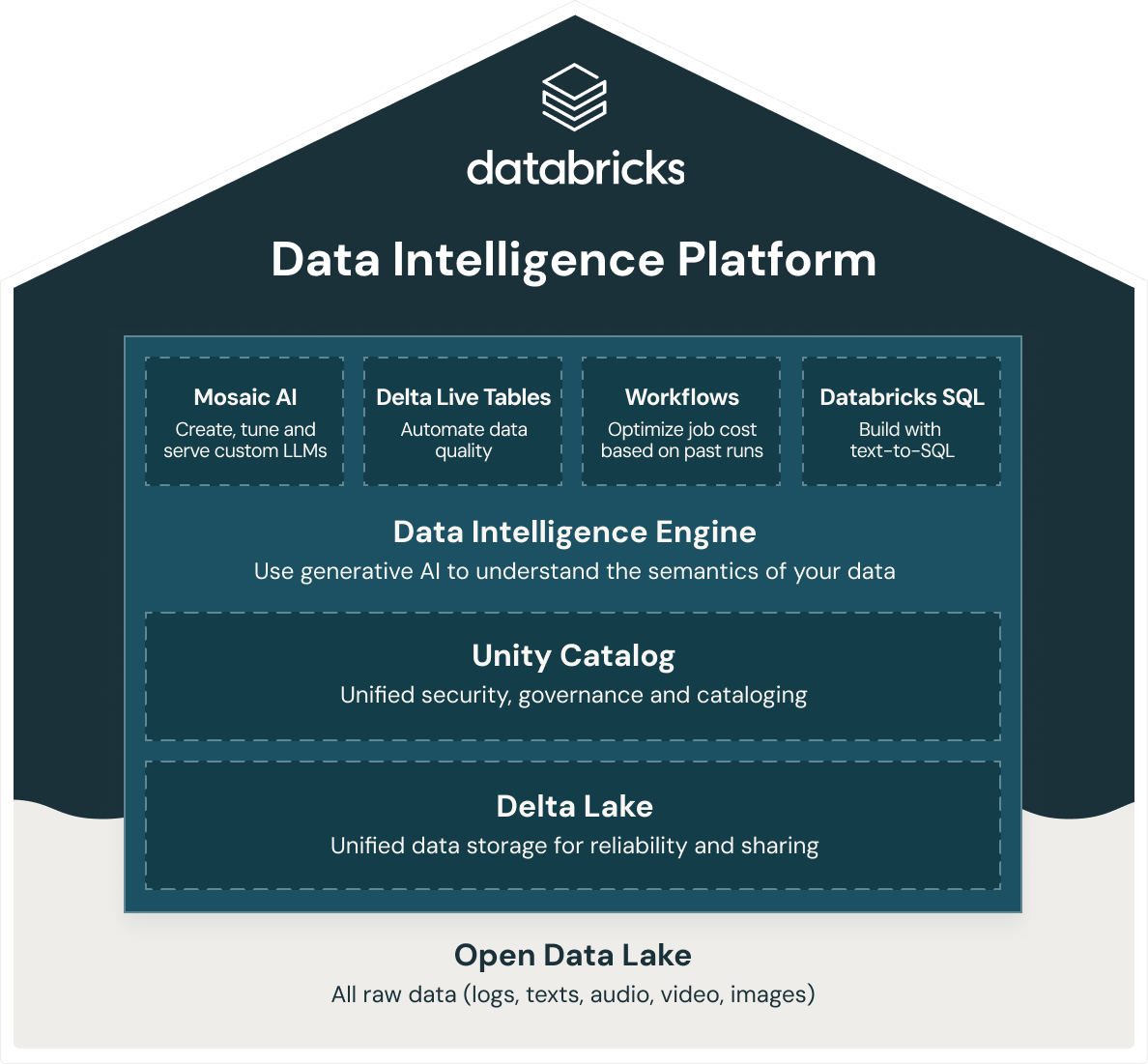
レイクハウスを効果的に構築するために、企業が注目しているのが、オープンソースの Delta Lake です。Delta Lake は、データレイクとデータウェアハウスの両方の利点を兼ね備えた、オープンフォーマットのデータ管理およびガバナンスレイヤーです。Databricksデータ・インテリジェンス・プラットフォームは、Delta Lakeを使用します:
- データレイクの経済性で、DWH パフォーマンスの公式記録を更新。
- インフラ管理の必要性を排除するサーバーレスの SQL 処理。
- dbt、Tableau、PowerBI、Fivetran などの最新のデータスタックとシームレスに統合し、インプレースでのデータインジェスト、クエリ、変換を実行。
- ANSI-SQL のサポートにより、組織内のすべてのデータユーザーにクラス最高の SQL 開発体験を提供。
- データリネージ、テーブルおよび行レベルのタグ、ロールベースのアクセスコントロールなど、きめ細かなガバナンス。
- データのセマンティクスを理解するAI搭載のデータ・インテリジェンス・エンジン