データ処理におけるETL(Extract, Transform, Load)とは?

ETL とは
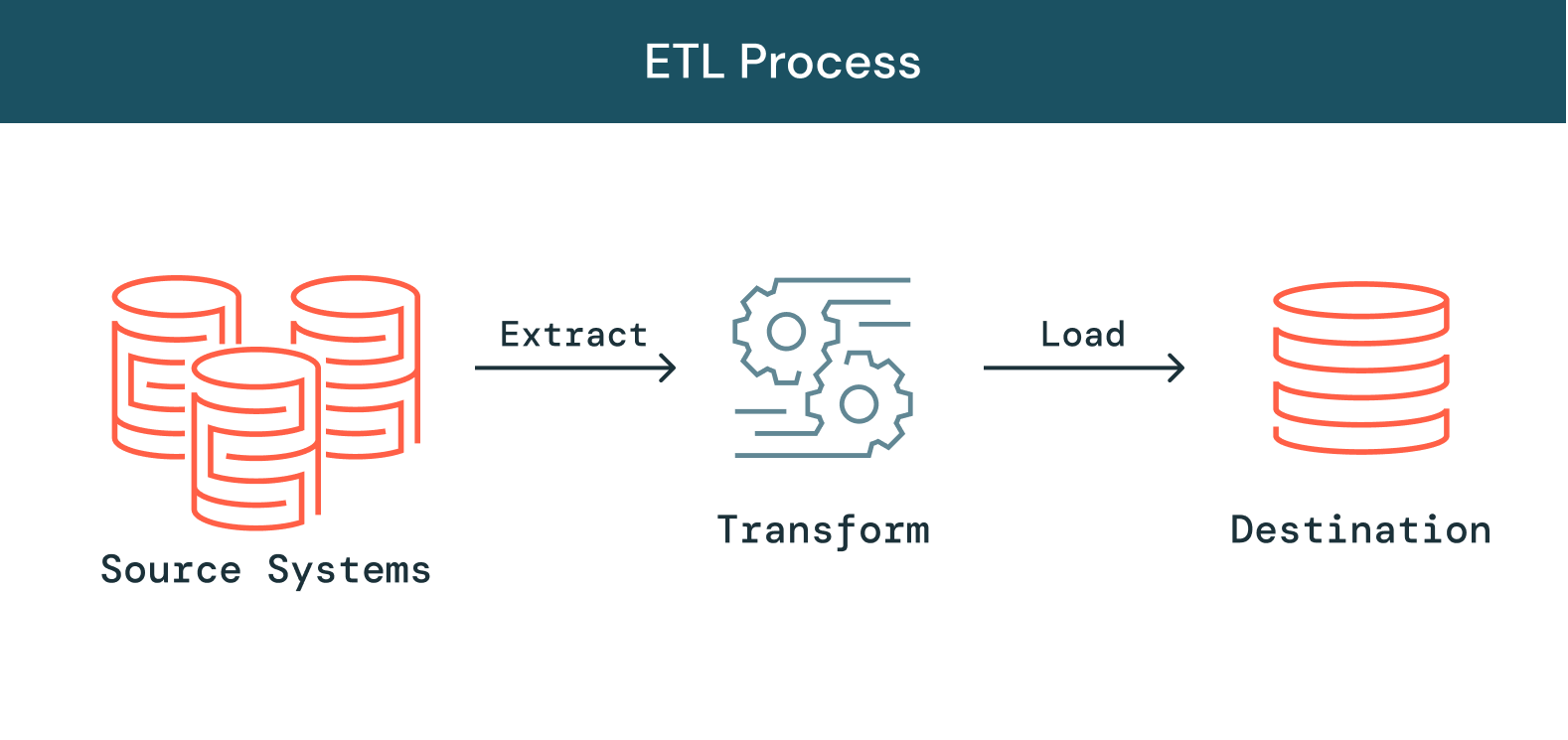
ETL(Extract, Transform, Load)とは、データの「抽出・変換・ロード」を意味するプロセスです。多様なデータソースからデータを抽出し、利用可能かつ信頼性の高い形式へ変換したうえで、対象システムへロードします。その結果、エンドユーザーがデータにアクセスし、ダウンストリームの分析や業務プロセスに活用できるようになります。
企業が扱うデータ量やデータソース、データタイプは年々増加しています。こうした環境下において、分析、データサイエンス、機械学習(ML)の取り組みにデータを活用し、ビジネスインサイトの創出を加速させることの重要性はますます高まっています。
一方で、これらの取り組みを推進するためには、データエンジニアリングチームの役割が不可欠です。煩雑な生データ(Raw Data)をクレンジングし、最新かつ信頼性の高い状態へ整備することは、AIやMLを本番環境で活用するための前提条件となります。ETLは、この重要な基盤プロセスを担っています。
Databricks についてさらに詳しく



ETL の仕組み
抽出(Extract)
最初のステップは、業務システム、API、センサーデータ、マーケティングツール�、トランザクションデータベースなど、通常は異種混在のさまざまなソースからのデータの抽出です。ご存じのとおり、これらのデータ型の一部は、広く使用されているシステムの構造化された出力である可能性が高く、他のデータ型は半構造化 JSON サーバーログです。抽出には、さまざまな方法があります。
-
部分抽出:最も簡単なデータの取得方法は、レコード変更時にソースシステムによって通知される場合です。
-
部分抽出(更新通知あり): 全てのシステムが更新の際に通知を提供できるわけではありませんが、変更されたレコードを指し示し、それらのレコードの抽出を提供できます。
-
完全抽出:変更されたデータをまったく特定できないシステムがあります。この場合、完全抽出によってのみ、システムからデータを抽出できる可能性があります。このメソッドでは、実施された変更を特定できるように、最後の抽出のコピーを同じ形式にする必要があります。
変換(Transform)
次のステップは、ソースから抽出された未加工のデータを異なるアプリケーションで使用できる形式への変換です。運用上のニーズを満たすために、データのクレンジング、マッピング、変換(多く場合、特定のデータスキーマに変換)が行われます。変換プロセスでは、データの品質と整合性を確保するために、いくつかのタイプの変換が行われます。データは通常、ターゲットデータウェアハウスに直接ロードされず、ステージングデータベー��スにアップロードされるのが一般的です。このステップにより、計画どおりに何かが進まない場合の迅速なロールバックを保証します。この段階の間に、規制遵守に関する監査レポートを作成したり、データの問題を診断して修復したりすることができます。
ロード(Load)
最後に、ロード機能は、変換されたデータをステージング領域からターゲットデータベースに書き込むプロセスです。ターゲットデータベースには、データが以前に存在していた場合とそうでない場合があります。アプリケーションの要件に応じて、このプロセスは非常に単純にも、複雑にもなり得ます。これらの各ステップは、ETL ツールやカスタムコードで実行可能です。
ETL パイプラインとは
ETL パイプライン(またはデータパイプライン)とは、ETL 処理を行うための仕組みのことです。データパイプラインは、データを保存・処理するシステムから、保存・管理方法が異なる別のシステムにデータを移動させるための一連のツールとアクティビティです。パイプラインを使用することで、さまざまなソースから情報を自動的に取得し、単一の高性能なデータストレージに変換して統合できます。
ETL の課��題
ETL は不可欠なものです。しかし、急激なデータソースの増大や、データタイプの多様化により、データエンジニアリングにとって、信頼性の高いデータパイプラインを構築し維持することが困難な課題となっているのが実情です。まず、データの信頼性を確保できるパイプラインの構築は時間がかかり、困難です。データパイプラインは、複雑なコードで構築され、再利用性にも限りがあります。構築済みのパイプラインは、基本的なコードがほぼ同じでも、別の環境では使用できません。そのため、データエンジニアはパイプラインを毎回最初から開発する必要があり、それがボトルネックになることがあります。また、パイプラインの開発以外にも課題はあります。複雑さが増すパイプラインアーキテクチャでのデータ品質の管理です。低品質のデータは、検知されずにパイプラインを通過することが多く、データセット全体の価値を下げることになります。品質の維持と信頼性の高いインサイトを確保するには、各ステップでのパイプラインの品質チェックと検証の実施が必要ですが、データエンジニアはそのために、広範なカスタムコードを記述しなくてはなりません。さらに、パイプラインの規模や複雑さが増すにつれ、企業におけるパイプラインの管理負荷が増大し、データの信頼性を維持することが非常に困難になっています。データ処理のインフラは、セットアップ、スケーリング、再起動、パッチ適用、更新が必要です。これにより、時間とコストが増大します。パイプラインの障害は、可視性とツールの不足が原因で、特定が難しく、解決はさらに困難です。
ETL にはこのような課題がありますが、信頼性の高い ETL は、データドリブンなインサイトの取得をめざすビジネスにとって、必要不可欠なプロセスです。データの信頼性の基準を維持する ETL により、ビジネスのチームは信頼できる指標やレポートを得ることができ、意思決定が促進されます。継続的にスケールアップするためには、ETL を合理化し、民主化するツールが必要です。データエンジニアは、ETL のライフサイクルを容易にし、データチームがデータパイプラインを構築、活用して、迅速にインサイトを得ることができるツールを必要としています。
Delta Lake で信頼性の高い ETL を自動化する
Delta Live Tables(DLT)は、Delta Lake に高品質データをもたらす信頼性の高いデータパイプラインの構築と管理を容易にします。DLT の宣言型パイプラインの開発、データテストの自動化、監視とリカバリの詳細な視覚化は、データエンジニアリングのチームによる ETL の開発と管理をシンプルにします。
