生成AI

まとめ
- チャットボットや画像ジェネレーターから創薬や不正検知まで、生成AI(GenAI)はテクノロジーを再構築し、小売、金融、ヘルスケアなど、さまざまな分野で新しいアプリケーションを推進しています。
- 生成AIは、トランスフォーマー、GAN、VAE、拡散モデルといったモデルを使用して大規模なデータセットからパターンを学習し、テキスト、画像、音楽、コード、さらには合成データを生成します。
- GenAIは生産性の向上、新たな収益源、イノベーションが期待される一方で、バイアス、誤情報、著作権、責任あるガバナンスの必要性をめぐる懸念も高まっています。
生成 AI とは
生成 AI(ジェネレーティブAI、GenAI)とは、新しいコンテンツを自動的に生成できる人工知能のことです。生成 AI は、テキスト、画像、動画、音楽、翻訳、要約、コードなど、さまざまな種類のコンテンツを生成できます。また、自由形式の質問に答えたり、ほぼ任意の指示を実行したり、チャットに参加するなど、特定のタスクを遂行できます。
ChatGPT や DALL-E のようなサービスにより、この技術の普及が進み、一般の人々も生成 AI についてより理解するようになりました。



生成 AI の仕組み
生成 AI モデルは、既存のデータセット内のパターンを識別し、分析するために深層学習を使用します。人間の脳の動きと同様に、トランスフォーマーやその他の深層学習アーキテクチャを使用してデータセットを処理し、「学習」します。これらの AI モデルは、膨大な量のデータでトレーニングされ、新しいオリジナルコンテンツを作成します。
AI モデルにテキストや画像、音符の並びなどを入力し、学習させたら「プロンプト」を与えます。するとアルゴリズムが新しいコンテンツを生成します。例えば、画像を使ってテキストのキャプションを作成したり、テキストの説明から画像を生成するなど、メディアをまたいだ作業も可能です。
生成 AI モデルの一般的なタイプは、テキストで学習される大規模言語モデル(LLM)です。これらのモデルは、連続して使用される単語を認識するように学習します。そして、どの単語が次に来る可能性が最も高いかを予測して文章を形成し、自然な出力が得られます。
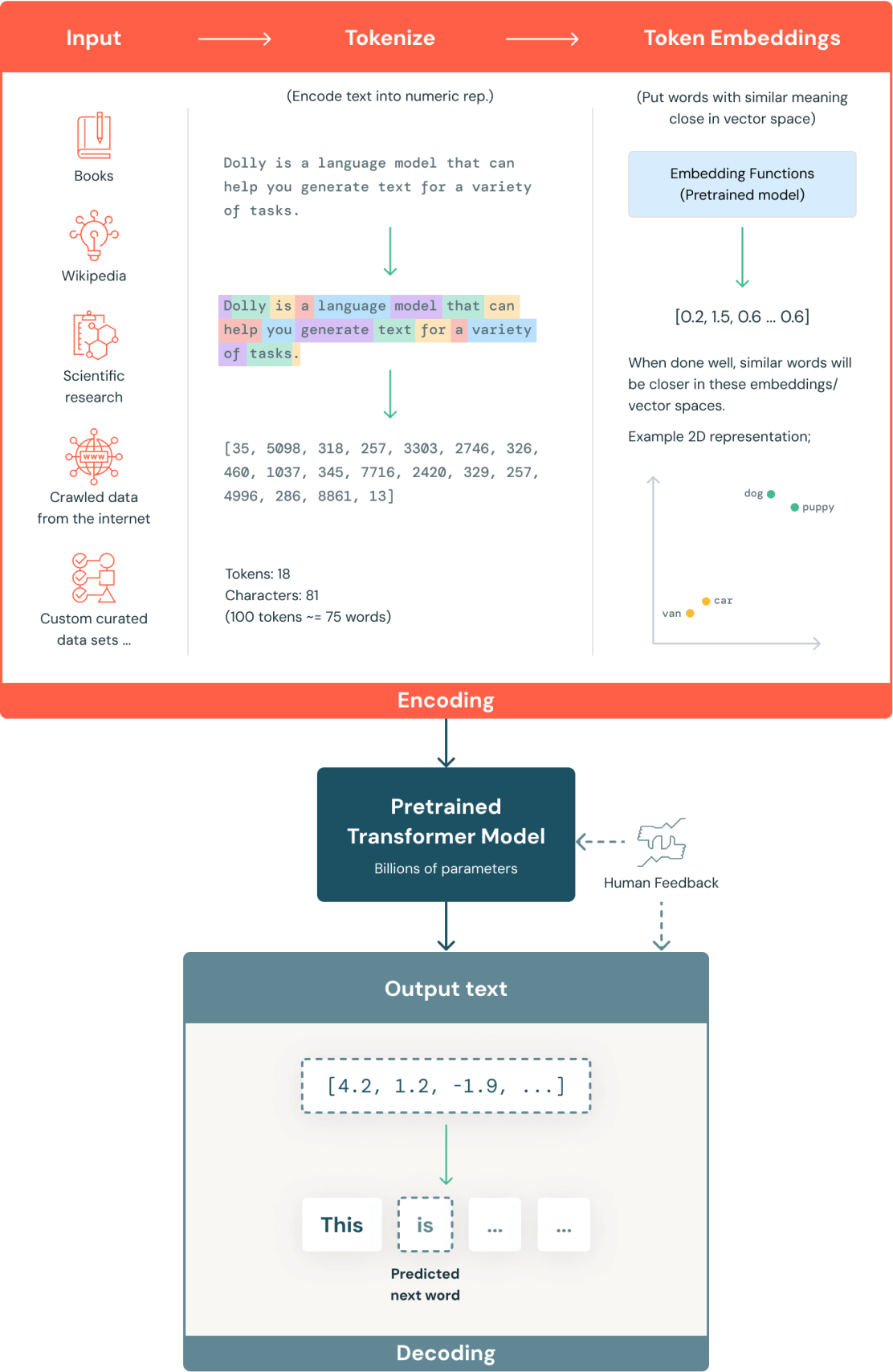
生成 AI モデルの例
現在使用されている生成 AI モデルにはいくつかの種類があります。その方法や使用例はそれぞれ異なりますが、いずれもさまざまなアルゴリズムを組み合わせてコンテンツを処理・作成します。
敵対的生成ネットワーク(GAN)
GAN モデルには、同時に学習される2つのニューラルネットワークが含まれています。これらのネットワークは生成器と識別器と呼ばれ、ゲーム形式のシナリオで互いに競合します。
生成器は、プロンプトに基づいて画像などの新しい出力を作成します。そして、識別器はこの新しいコンテンツが本物かどうかを評価し、出力を改善するために生成器にフィードバックを提供します。生成器は常に、識別器をだまして生成されたコンテンツを「本物」と認識させようとします。一方、識別器は、生成されたコンテンツと本物のコンテンツの違いをより正確に判断するよう努めます。
GAN モデルのよく知られる例として、Midjourney(テキストから画像への GenAI ツール)があります。しかし、GAN は画像の作成にとどまらず、テキストやビデオのコンテンツも作成しています。
GAN 生成器と識別器の間の継続的な競争は、高品質な出力を迅速に生成できることを意味します。た�だし、オーバーフィッティング、モード崩壊、勾配の減少などの問題を回避するために、2つのネットワークのバランスが取れていることを確認することが重要です。
変分オートエンコーダー(VAE)
オートエンコーダーモデルもまた、データを解釈し生成するために 2 つのネットワークを使用します。このモデルでは、ネットワークはエンコーダーとデコーダーと呼ばれます。エンコーダーネットワークは、データを、主要な特徴量を捉えた簡略形式または潜在形式のフォーマットに圧縮するように学習されます。一方、デコーダーモデルは潜在データからコンテンツを再構成するように学習されます。
VAE は、学習データポイント間の局所的な変化を可能にするために、連続的な潜在空間を使用します。わずかに変更された圧縮情報をデコードすることで、VAE モデルは類似した、しかし最終的にはオリジナルのコンテンツを出力します。
このモデルは、画像生成や異常検知によく使用されますが、テキストや音声を生成することもできます。VAE は画像のような出力をすばやく生成しますが、他のモデルと比べると詳細さに欠けることがあります。
自己回帰
自己回帰生成 AI モデルは、以前に生成された要素の文脈を考慮することで新しいサンプルを作成します。各データポイントの条件付き確率分布をモデル化し、シーケンスの次の要素を予測して新しいデータを生成します。
これらのモデルは、データを一度に 1 つの要素ずつ逐次的に生成し、複雑なシーケンスの生成を可能にします。自�己回帰 AI は通常、テキスト生成(ChatGPT など)、言語モデリング、音楽作曲に使用されます。
拡散モデル
拡散モデルは、デノイズ拡散確率モデル(DDPM)とも呼ばれることがあります。順拡散と逆拡散の 2 段階のプロセスで学習されます。
順拡散では、ランダムなガウシアンノイズが学習データに徐々に加えられ、効果的に破壊されます。その後、AI は逆拡散によってサンプルを再構築することを学習します。一度完全にトレーニングされると、拡散モデルは完全にランダムなノイズから新しいデータを作成することができます。
Transformer
Transformer は、連続した入力データ間の長期的な関係を処理するのに役立つ特定のタイプの機械学習を使用します。そのため、より大きなデータセットでモデルをトレーニングする必要があります。
「アテンション」と呼ばれるこの概念により、Transformer は、入力のどの部分が他の部分に影響を与えるかを把握することができます。そのため、文脈の理解が必要な自然言語処理(NLP)を含むテキスト生成タスクに最適です。よく知られた生成 AI プログラムの大半は、Transformer に基づくモデルの例です。
Transformer は非常に強力なテキストジェネレーターであることが証明されています。学習入力として必要なのはテキストだけであり、使用可能なページは何十億ページもあるからです。NLP 以外にも、Transformer AI モデルの用途には、コード、タンパク質、化学物質、DNA 内の接続の追跡や関係の特定などがあります。
生成AIモデルの活用
これらの各モデルタイプは特定のユースケースに適しており、たとえば、次のようなものが挙げられます。
- GANs: 高解像度画像、動画合成、データ拡張
- VAEs: 異常検知と迅速な画像生成
- 自己回帰モデル:テキスト生成、言語モデリング、シーケンシャルデータタスク
- 拡散モデル: 高品質な画像合成とノイズ除去アプリケーション
- Transformers: NLP、コード生成、マルチモーダルAI
これらのモデルのどれを使用するかを評価する場合、組織はユースケースを定義し、各ユースケースで達成したい目標を明確にしておく必要があります。状況に応じて最良の結果を生み出すモデルを選択するには、これらの目標と照らし合わせて各モデルの長所と短所を比較検討する必要があります。
ユースケースが決定すると、組織が生成AIモデルの有効性を評価および検証するために使用できる手法がいくつかあります。
- BLEU: このモデルは、生成テキストと参照テキストの重複度を測定します。もともと機械翻訳のために設計されたこのモデルは、出力の精度に重点を置いています。
- ROUGE:要約用に設計されており、n-gram の重複の再現率を評価し、モデルの出力に参照コンテンツがどの程度取り込まれているかを評価します。
- METEOR、ChrF:これらは、単語レベルのセマンティクスまたは文字レベルのパターンを使用して、生成テキストと参照テキストを比較することでテキストの品質を評価します。
- パープ�レキシティ: モデルが次のトークンにどれだけ「驚いた」かを測定する指標です(低いほど良い)。パープレキシティが低いことは予測能力が高いことを意味しますが、必ずしも実世界のタスクにおける生成品質と相関するわけではありません。
- Fréchet Inception Distance (FID) は、特徴分布を使用して、生成された画像が実際の画像にどれだけ近いかを測定します。
- Inception Score(IS)は、予測されたラベルの信頼度と多様性に基づいて画質を評価します。
- Databricks のサポート: MLflow を使用すると、評価パイプラインの一部としてこれらのスコアを記録し、比較できます。
生成 AI における深層学習の役割とは
深層学習へのシフトにより、AI モデルはより洗練され、自然言語のような複雑化するデータをモデル化できるようになりました。生成 AI モデルの大半は、深層学習を利用しています。
深層学習という名前は、これらのモデルに使用される処理層の数が多いことに由来します。相互に接続されたノードからなる最初の層には、学習データが供給されます。この層の出力は次の層の入力として使用されます。各レイヤーが前のレイヤーから得た知識を基に構築されるため、複雑さと抽象度が増し、データセットの細かいディテールがより大規模なパターンの理解に寄与するようになります。
従来の機械学習では、プログラマーが特徴抽出を行う必要がありましたが、深層学習プログラム�では、より少ない監視でデータの有用な表現を内部的に構築することができます。
さらに、深層学習技術により、AI モデルは自然言語理解や画像認識のような複雑で抽象的な概念を扱うことができます。
AI のパフォーマンスを向上させるには、データ増強、転移学習、微調整など、さまざまな方法があります。データ増強では、生成モデルを使用して学習データ用の新しい合成データを作成します。これを既存のデータに追加することで、データセットのサイズと多様性を高め、結果としてモデルの精度を向上させます。
転移学習では、事前に学習させたモデルを、関連する別のタスクに使用します。既存のモデルの出力を別の学習問題の入力として活用することで、モデルは最初の学習で得た知識を応用することができます。移転学習の例は、自動車を識別するためにトレーニングされたモデルを使用して、他の車両を識別するためのモデルを訓練することです。転移学習は、新しいモデルを学習するのに必要なデータ量を減らすことができるので便利です。
最後に、ファインチューニングとは、より具体的なデータを用いて AI モデルをトレーニングすることで、AI モデルをカスタマイズする手法です。これにより、事前にトレーニングされたモデルを、特定のドメインやタスクで使用するために改良することができます。ファインチューニングには、最終的なタスクを代表する高品質のデータセットが必要です。
生成 AI の実世界でのユースケース
生成 AI 技術は、テキストや画像��の生成からソフトウェア開発まで、実世界において非常に幅広い用途があります。現在一般的なユースケースを見てみましょう。
画像生成
DALL-E のようなツールは、ユーザーが視覚的または文字によるプロンプトを入力することで、新しい画像(写真、イラスト、さらには動画)を作成できます。マルチモーダルモデルは、テキストによる指示からイメージを作成することができるため、ユーザーは漠然としたものから具体的なものまで、自在に作成できます。
例えば、「動物」と「虹」をモチーフにした絵をお願いして、どんな絵が出てくるか見てみるという方法もあります。あるいは、「サングラスをかけたサイの赤ちゃんが、紫色のカーテンの窓から虹を見ている」というような細かい指示を出すこともできます。
もう 1 つのオプションは、ある画像のコンテンツと別の画像のビジュアルスタイルを組み合わせるスタイルトランスファーです。コンテンツ画像(サイの写真)とスタイル参照画像(ピカソの絵画)を入力すると、AI はそれらを融合させ、新しいピカソスタイルのサイ画像を作成することができます。
テキスト生成
テキストベースの生成 AI のユースケースとして最もよく知られているのはチャットボットですが、この技術は現在、他の多くのタスクにも応用できます。例えば、GrammarlyGo のようなツールは、ビジネスライクなスタイルでメールを書いたり、返信したりするのに役立ちます。
例えば、技術的な製品を宣伝するパンフレットを作成することになった場合、人間�であれば、まず商品の特徴や仕様に目をとおし、詳細なメモをとり、説明文の草稿を作成します。生成 AI プログラムなら、情報を提供してから数秒でその全てを行うことが可能で、即座にコンテンツを作成することができます。テキスト生成は、映画の吹き替え、動画コンテンツのクローズドキャプションの提供、コンテンツをさまざまな言語に翻訳する場合にも便利です。
楽曲制作
生成 AI は、特定のジャンルの音楽を作ったり、特定の作曲家のスタイルを模倣することができます。画像生成と同様に、詳細を提供することも、完全に自由に創造することもできます。例えば、「虹についての歌」や、「ウクレレとカズーの伴奏による、虹についての 3 楽章からなるワルツ拍子の童謡」などです。
また、AI に 2 つの異なる楽曲をスタイルトランスファーで合成するよう依頼することもできます。例えば、ガーシュウィン風の Happy Birthday ソングや、リミックスを作成することも可能です。Amper Music は事前に録音されたサンプルから音楽トラックを作成し、他のツールはビデオ映像内のオブジェクトを認識してサウンドトラックを作成できます。
合成データ
GenAIは、高度なアルゴリズムとシミュレーションを使用して、合成データを作成することもできます。これらの合成データセットは、実際の情報を一切含まずに、実世界のデータの統計的特性を再現します。従来のデータ収集はコストと時間がかかるものですが、GenAIを利用することで、構造化およびラベル付けされたデータセットをスケーラブルな量で、わずかなコストで組織に提�供できます。
AI モデルのトレーニングを強化するために使用されるデータ拡張に加えて、合成データの主なユースケースは次のとおりです。
- 研究とテスト: 生成AIの合成データは、経済市場や気象条件などの現実世界の環境をシミュレートすることで、予測モデルやプロダクトを安全にテストできます。
- プライバシー保護: 医療や金融などの業界で機密情報を扱う組織は、統計的な関連性を維持しつつ個人を特定できる情報(PII)を削除した合成データを生成します。これにより、消費者保護規制を遵守しながら、データを安全かつ正確に分析できます。
- バイアスの削減: 実世界のデータでトレーニングされたAIモデルは、不公平な結果につながるバイアスを継承することがよくあります。合成データは、データセット全体のバランス調整に役立ち、データが実世界の現実をより正確かつ公正に表すようにします。
生成 AI の業界への応用
この技術の活用方法は非常に多く、リテール・消費財、金融サービス、ヘルスケア向け生成 AI が例外ではなく標準になりつつあるのも当然のことです。
リテール・消費財
既に多くの小売企業がチャットボットを使って顧客サービスを自動化しており、生成 AI が進歩するにつれて、これらのチャットボットはより洗��練されていくと予想されます。将来的には、AI はバーチャル試着室、商品開発、プロアクティブマーケティングによって、顧客にさらなるパーソナライゼーションを提供できるようになるでしょう。小売業はまた、より強固なセキュリティのためのフィッシングや詐欺の識別だけでなく、在庫と需要計画のために生成 AI を使用することから利益を得ることができます。
金融サービス
金融サービス業界(FSI)では、膨大なデータを分析するために、既に生成 AI に投資している企業があります。その一例が、今年初めに発表された BloombergGPT LLM です。この 500 億パラメータ AI は、FSI のレポーティングと予測のために作られたものです。
現在および将来の FSI における生成 AI のその他の用途には、リスク管理や不正検知、業務効率の改善、顧客のパーソナライゼーションの向上などがあります。
製造
産業革命以来、製造業は自動化による効率の最適化を目指してきました。生成 AI は、この産業を再び未来へと押し進める新たなツールを提供します。
AI は、継続的な製造オペレーションに関する自動化されたレポートを提供し、パフォーマンスのギャップやボトルネックを特定し、データ駆動型の優先順位付けを使用して効率を高めることができます。オペレーションの監視だけでなく、AI は機器を監視し、予知保全やトラブルシューティングによってダウンタイムを削減することもできます。
また、製造業における LLM は、顧客サービスや、自動車やスマートテクノロジーなどの特定の製品において、顧客体験をパーソナライズできます。
メディア
エンターテインメント業界が AI をどのように活用するかは、最近多くの議論の対象となっています。しかし、業界の仕事に影響を与えることなく生成 AI を利用できる方法はたくさんあります。
AI モデルによるユーザーの嗜好、消費パターン、ソーシャルメディアシグナルの分析は、エンターテインメントサービスからのメディア推薦を最適化するために使用できます。生成 AI モデルは、ターゲット広告を改善することもできます。しかし、エンターテインメントにおける LLM に関する最もエキサイティングな開発は、視聴者の意思決定が物語を形成するような、没入型のインタラクティブなストーリーテリングの可能性です。
医療・ヘルスケア
ヘルスケアでは、生成 AI モデルが新しい化合物や分子を示すグラフを作成することで、新薬の発見に役立ちます。アストラゼネカはすでに AI を創薬に活用しており、2025 年までに新薬や新素材の 30% 以上が生成 AI 技術を使って発見されると推��定されています。
これらのモデルはまた、試験すべき新しい化合物の提案や、適切な試験候補の特定、合成画像による医療画像分析アプリケーションの微調整できます。さらに、AI を使用して、個別の治療計画の生成や、電子カルテにアップロードするために診察を書き起こしたりすることもできます。
生成 AI の活用がビジネスにもたらすもの
現実の世界での応用例をいくつか見てきましたが、生成 AI はビジネスにどのような効果をもたらすのでしょうか?主なメリットは以下の通りです。
収益ストリームの構築
この技術により、企業は斬新なデザインを考案し、R&D プロセスを加速させることで、新製品を迅速に開発・発売できます。また、傾向や顧客行動を分析し、新たな収益源となるアイデアを提示できます。
製品のイノベーションだけでなく、AIは新しいマーケティングプランの作成や販促物の作成にも役立ちます。顧客の嗜好を分析することで、ターゲットを絞った広告の作成や、おすすめ商品の調整、商品やサービスのパーソナライズができます。AIのデータ分析は、企業が競合他社よりも優位に立ち、競争力を維持する機会を見出すのにも役立ちます。
また、生成 AI を活用することで、ビジネスチャットボットのパフォーマンスが向上し、顧客満足度、売上、定着率が高まります。
生産性の向上
もう 1 つの大きな利点は生産性です。生成 AI は、データ入力、定型メール、会議や通話の書き起こしなど、時間のかかる手作業を�自動化するために使用できます。
AI モデルは複雑な情報を要約し、人間が理解・解釈しやすいようにするのが得意です。また、データを分析し、既存のワークフローを最大限に効率化するための改善策を提案することもできます。
カスタマーサポートにおいて、企業は AI を搭載したチャットボットやバーチャルアシスタントを導入することで、サポートエージェントの負担を軽減できます。AI が一般的な問い合わせに対応する間、エージェントは他のタスクを処理できます。
リスク軽減
生成 AI プラットフォームは、データをより深く可視化するだけでなく、財務やセキュリティの脆弱性を迅速に特定することができます。高度な AI プログラムでは、潜在的なビジネスリスクをシミュレートすることもできるため、コンプライアンスを評価し、問題を回避または軽減するためのプロトコルを導入できます。
一方、データの圧縮は、組織が必要なデータだけを保持すればよいことを意味し、多くの個人情報を保持するリスクを軽減します。
一般的な LLM にはどのような違いがありますか?
混み合った分野を形成する LLM は、その選択肢の数は今後も増え続けることが予想されます。しかし、一般的に LLM はプロプライエタリなサービスとオープンソースモデルの 2 つに分類することができます。もう少し具体的に見ていきます。
プロプライエタリなサービス
最もよく知られている LLM サービスは、OpenAI が 2022 年末にリリースした ChatGPT です。ChatGPT はユ�ーザーフレンドリーな検索インターフェイスを提供し、プロンプトを受け付け、通常、迅速かつ適切な応答を提供します。ChatGPT の API は開発者もアクセス可能で、LLM を独自のアプリケーションや製品、サービスに統合することができます。
他の独自サービスの生成 AI の例としては、Google Bard や Anthropic の Claude があります。
オープンソースモデル
もう 1 つのタイプの LLM はオープンソースで、商用利用が可能です。オープンソースコミュニティは、プロプライエタリなモデルの性能に急速に追いつき、そのモデルは、セルフホストまたはクラウドサービスの API を介して提供され、微調整によってカスタマイズできます。
代表的なオープンソースの LLM には、Meta の Llama 2 や、Databricks に買収された MosaicMLの MPT があります。
最適な生成 AI LLM の選択
プロプライエタリな LLM とオープンソースの LLM の違いを理解することは最初のステップですが、生成 AI アプリケーションのための LLM を選択する際に考慮すべきことはまだたくさんあります。クローズドなサードパーティベンダーの API か、オープンソース(または微調整された) LLM のどちらかを選択する際には、将来性、コスト、競争優位性としてのデータの活用の全てを考慮する必要があります。
プロプライエタリサービスの LLM は極めて強力であることが多いのですが、「ブラックボックス」スタイルであるため、学習プロセスや重みの監視が�行き届かず、ガバナンス上の懸念が生じることもあります。もう 1 つのリスクは、プロプライエタリモデルが非推奨または削除される可能性があることで、既存のパイプラインやベクトルインデックスが壊れてしまいます。
一方、オープンソースモデルは、購入者が無期限でアクセスできます。また、オープンソースモデルは、カスタマイズや監視が容易であるため、パフォーマンスとコストのトレードオフを改善できます。最後に、オープンソースモデルを将来的に微調整することで、組織は自社のデータを競争上の優位性として活用し、公開されているモデルよりも優れたモデルを構築できます。
生成 AI の倫理に懸念があるのはなぜですか?
どのような形態の AI であれ、人間は知的な機械による影響を理解しようとするため、倫理的な懸念を引き起こす傾向があります。では、生成 AI の倫理とは?そもそも、この技術は比較的新しく、また極めて急速に進化しています。この分野の開発者でさえ、この技術がどこに行き着くのかよく分かっておらず、モデルがより人間に近い反応を返すように学習するにつれ、不正確さを検出することが難しくなっています。
生成 AI モデルで指摘されている問題のひとつに、「幻覚」があります。これは、チャットボットが本質的に作り話をすることです。モデルが医療アドバイスや正確な報告のようなものに使用されている場合、深刻な結果をもたらすおそれがあります。
さらに、人種差別や同性愛嫌悪など、無意識または意図的なバイアスがトレーニングデータセ�ットに含まれている場合、それがモデルに符号化され、AI の出力に影響を与える可能性があります。
誤報や潜在的に有害なコンテンツとは別に、デジタル的に偽造された画像や動画である「ディープフェイク」についても共通の懸念があります。サイバー攻撃者は生成 AI を使用して、信頼できる送信者のスタイルを模倣し、パスワードや金銭を要求するメッセージを書くこともできます。
さらに、モデルから出力されたものを作者までさかのぼるのは難しいことが多く、著作権や盗作の問題が生じます。これは、特定のデータセットに関する情報が不足しているために、さらに複雑になっています。例えば、画像生成ツールでは、ユーザーは「アーティスト X のスタイルで」何かを要求することができますが、「アーティスト X」は自分の画像がデータセットの一部であることに同意していない場合があります。
生成 AI と倫理をめぐるその他の懸念には、この技術が膨大なコンピューティング能力と電力を必要とするため、持続可能性や、ネット上の言葉や画像に対する不信感を煽ることで、本物の報道がフェイクであるという主張に信憑性を与えることなども含まれます。
AI の品質をテストするには?
前のセクションで述べたように、生成 AI は不正確または低品質のアウトプットを生成することがあります。生成 AI のツールやフレームワークを研究していると、販促資料にパフォーマンス指標が表示されますが、常に自分で確認するのが一番です。
開発者やエンジニアは、AI が生成したコンテンツの品質や多様性をテストし、モデルがトレーニングされたとおりに動作していることを確認する必要があります。誤った「事実」の記述があるかどうかを確認するのは比較的簡単ですが、主観的なものである芸術的または創造的なアウトプットの質を評価するのは厄介です。
Databricks の MLflow の評価 API のようなツールを使って、生成 AI のパラメータとモデルを追跡し、出力がニーズに十分かどうかを確認することができます。これは人間による評価と組み合わせることもできます。例えば、生成された音楽やアートが魅力的かどうかを自分の判断で評価することができます。より客観的な評価指標としては、画像ではISやFID、テキストではBLEU/ROUGE等、また正解データ(グラウンドトゥルース)に基づく評価があります。
グラウンドトゥルース
この評価方法には、生成 AI がトレーニングされたグランドトゥルースを特定することが含まれます。グランドトゥルースとは、基本的に、事実上真実であることが知られている情報に基づく、クエリに対する「正しい」応答のことです。これは、AI が信頼できる出力に到達する方法を教えるトレーニングデータセットに含まれている必要があります。
例えば、不正確なコンテンツを認識するモデルをトレーニングする場合、真か偽かに分類されたテキストや画像の大規模なデータセットが必要になります。開発者は、このデータセットを標準として、回答や予測の精度を測定することができます。
しかし、グランドトゥルースを構築するのは AI デザイナーで�あるため、その情報が正しいかどうかを確認するためには、彼らの注意力に頼ることになります。理想的には、グランドトゥルースはユーザーから直接フィードバックされることです。
Databricks レイクハウスモニタリングは、AI プロフェッショナルが自社の資産を高品質、高精度、高信頼性で維持できるよう支援します。プロアクティブなレポーティングと統合ツールにより、データとモデルを完全に可視化し、異常を容易に検出できます。また、ビルトインのモデル判定メトリクスは、ユーザー独自の品質メトリクスで補強できます。
AI の品質メトリクス
AI の品質メトリクスは、生成 AI モデルのパフォーマンスを決定するために使用される測定値です。度や想起のような伝統的な ML メトリクスに加えて、生成 AI に特化したカスタムメトリクスにより、これらのモデルの重要な評価が可能になります。
例えば、Fréchet Inception Distance(FID)メトリクスは、生成 AI によって作成された画像の品質を評価します。生成された画像の分布を、ツールのトレーニングに使用された実際の画像の分布と比較することで、分類器の一部の深層における活性化の分布間の距離を計算できます。スコア 0.0 が FID の最良の結果です。
Databricks は、チャットボットの品質を判断する基準として LLM を使用することの価値を示しています。こうした最先端の手法により��、さまざまな AI モデルからのテキスト出力を比較して毒性や難解性を評価できる、新しい MLflow Model-as-a-Judged 機能が誕生しました。
現在の生成 AI の課題
技術は急速に発展していますが、生成 AI モデルを使用するにはまだかなりの課題があります。
インフラのスケーリング
生成AIを成功させるうえでの重要な課題の一つは、スケーラビリティです。これらのモデルは、望ましい出力を生成するために、膨大な量の高品質で偏りのないデータを必要とすることが、これまでの経験からもわかっています。
生成 AI モデルの開発と保守には大規模なコンピューティングインフラとパワーが必要であり、そのためには多額の設備投資と技術的専門知識が必要となります。そのため、スケーラブルなソリューションに対する需要が高まっています。
最適化における複雑さ
また、機械学習の専門家は、生成AIモデルを最適化する必要があるために、多くの低レベルの課題に直面する可能性があります。これらの複雑さの例として、モード崩壊や勾配消失が挙げられます。
モード崩壊は、GAN モデルで発生する失敗の一種で、生成器が、より多様な出力を生成する代わりに、識別器が受け入れた 1 つの信じられる出力を繰り返すことを学習するときに発生します。もし識別器が似たような、繰り返される出力を拒否することを学ばなければ、生成器のその後のすべての反復は、出力タイプの小さなセットを通して回転します。
勾配の消失は、特定の活性化関数を持つ��層がニューラルネットワークに追加され、損失関数の勾配が小さくなりすぎた場合に起こります。勾配が小さすぎると、初期層の重みとバイアスが適切に更新されなくなり、入力データ認識の重要な要素が機能しなくなり、ネットワークが不正確になります。
GenAIでは、高コストなラベル付きデータやファインチューニングのサイクルを繰り返すことなく、大規模モデルを専門的なエンタープライズタスクに適応させるという、さらなる複雑さがあります。新たなアプローチの1つがTest-time Adaptive Optimization (TAO)です。これはDatabricks Mosaic AI Researchチームによって開発されたもので、ラベルなしの入力、テスト時のコンピューティング、強化学習を使用して、推論コストを増やすことなくモデルを効率的にチューニングします。
分散されたデータ、ML、AI ツール
データ、従来型の機械学習、生成 AI のための、それぞれ独立した、統合性の低いツールも、データサイエンティストに課題をもたらす場合があります。
高品質なデータは機械学習モデルと GenAI モデルの両方のトレーニングに不可欠であり、ML と GenAI モデルの出力はデータパイプラインにフィードバックされる必要があります。ガバナンス、品質、実装はデータとML/AI全体で包括的に対処する必要があり、プラットフォームが分かれていると組織の摩擦や非効率、追加コストにつながる可能性があります。
Databricks Data Intelligence Platform は、コ��アデータワークロード、古典的な ML、生成 AI をサポートし、全体的なデータ使用量を把握します。データインテリジェンスプラットフォームは、レイクハウスのオープンで統一された構造と生成AIを組み合わせることで、パフォーマンスを最適化し、ユーザーエクスペリエンスを簡素化して、強力で安全なガバナンスとプライバシーを提供します。
Model Context Protocol (MCP) は、LLM がエンタープライズ コンテキストに基づいて動作するために必要なデータやツールに、安全で標準化された方法でアクセスできるようにすることで、この課題にさらに対応します。MCPは、AIアシスタントとデータシステム間の双方向接続を構築するためのオープンプロトコルとして、エージェントが新たなサイロを作ることなく、関数の呼び出し、ナレッジの取得、パイプラインとの統合を可能にします。Databricks では、MCP をエージェントの構築と評価のために Mosaic AI と、ガバナンスのために Unity Catalog と組み合わせることで、企業はセキュリティと可観測性を維持しながら AI にコンテキストを付与できます。
生成 AI の未来
ガートナーによると、生成 AI は蒸気機関や電気、インターネットと同様のインパクトを与え、最終的には「汎用技術」になると考えられています。それは、この技術には非常に多くの応用の可能性があるからです。
例えば、現在米国経済全体で労働時間�の最大 30% を占める業務は、2030 年までに自動化される可能性があります。また、ソフトウェアプロバイダが自社のツールに AI 機能を統合するケースも増えると予想されます。
人間の仕事が機械に奪われることを心配するのは当然ですが、AI の未来では多くの新しい仕事が生まれる可能性もあります。例えば、与えられたタスクに最適なモデルを選んだり、アウトプットを評価するためのトレーニングデータを集めたりといった、生成 AI システムの開発とトレーニングは依然として人間が行う必要があります。
ChatGPT のような技術の急速な普及は、責任を持って生成 AI を利用するうえでの課題を浮き彫りにしています。国や州はすでに、著作権やサイバーセキュリティへの脅威をめぐる問題に対処するために、新たな法的およびセキュリティプロトコルが必要であることに気づいており、これらのテクノロジーは今後さらに規制される可能性があります。
一方、Databricks データインテリジェンスプラットフォームには生成 AI が組み込まれているため、データセキュリティとガバナンスの維持、データ品質の追跡、モデルの監視と微調整が容易になります。
アーキテクチャと学習アルゴリズムがより高度になるにつれて、生成 AI モデルはより強力になります。組織は、技術のパワーには責任が伴うことを忘れず、自動化と人間の関与のバランスを取る必要があります。
生成 AI に関する詳しい情報はどこで��入手できますか?
生成 AI についての詳しい情報は、次のような多くのリソースから得ることができます。
トレーニング
- 生成 AI の基礎:Databricks の無料コースで生成 AI の基礎を習得できます。
- LLM:基礎モデルを一から学ぶ(edX と Databricks トレーニング)。Databricks が提供するこの無料トレーニングでは、LLM における基盤モデルの詳細について深く掘り下げます。
- LLM:アプリケーションの本番運用(edX と Databricks トレーニング)でスキルをレベルアップできます。Databricks が提供するこの無料トレーニングでは、最新かつ最も一般的なフレームワークを使用して LLM に特化したアプリケーションを構築する方法に重点を置いています。
サイト
- Databricks AI と機械学習のページ
eBook
- グレート・アクセラレーション:生成 AI に対する CIO の視点:600 人以上の CIO の生成 AI に関するインサイトをまとめた MIT テクノロジーレビュー・インサイトのレポート。
- 生成 AI で可能性を再定義:52 のユースケースから始める
- MLOps のビッグブック
技術ブログ
- Databricks で高品質の RAG アプリケーションを作成する
- RAG アプリケーションにおける LLM 評価のベストプラクティス
- MLflow AI Gateway と Llama 2 を使用した生成 AI アプリの構築(RAG を使用した自社データでの精度向上)
- 検索拡張生成(RAG)、基盤モデル、ベクトル検索を使用した LLM チャットボットの展開
- LLMOps:LLM を管理するための全てがここに
この他、Databricks の専門家によるデモや LLM プロジェクトについてのご相談、Databricks が提供する LLM 向けサービスの詳細についてのお問い合わせも承っております。