Partner Connect は、Databricks プラットフォームでのデータ、分析、AI ツールの活用を容易にします。シンプルな操作で現行ツールとの統合が可能で、レイクハウスの能力を素早く拡張できます。
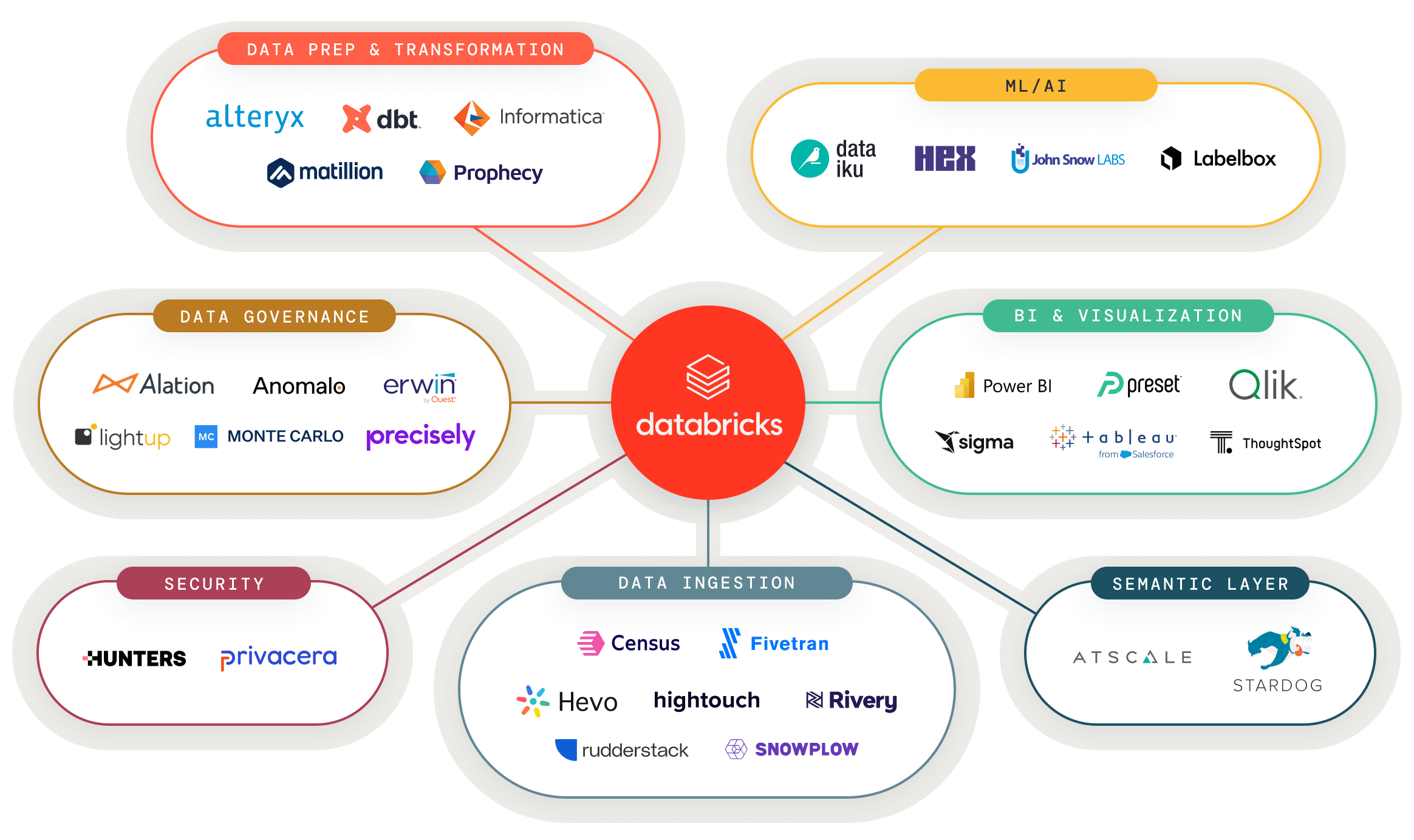
データ・ AI ツールをレイクハウスに接続
現行のデータ・AI ツールとレイクハウスを容易に接続。レイクハウスが分析のユースケースを強化します。

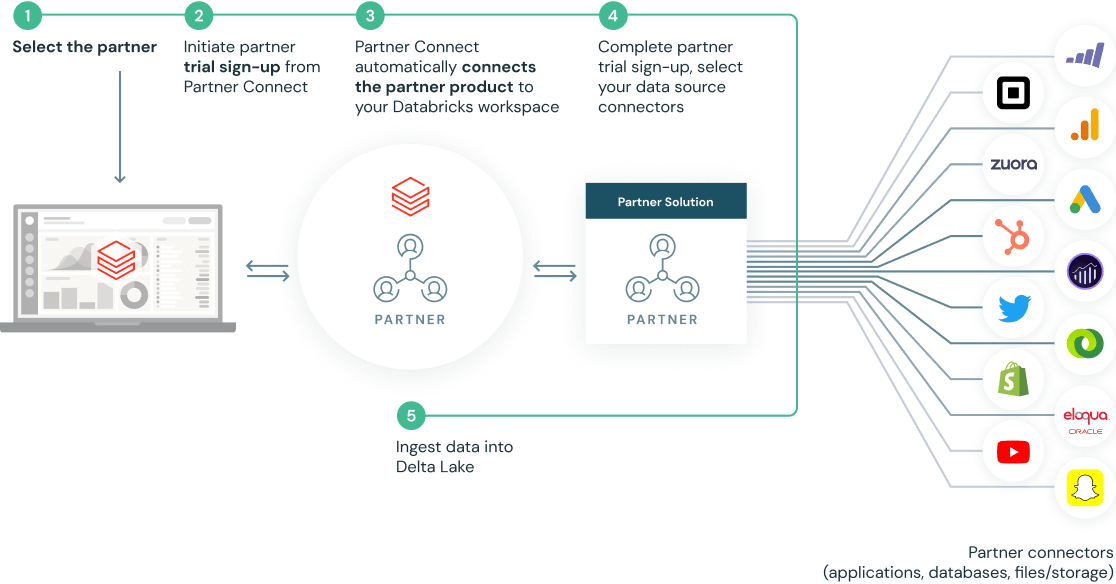
Databricks 認定のデータ・AI ソリューションで新たなユースケースを構築
認定済みのパートナーソリューションがポータルに集約されており、新たなデータアプリケーションの構築に利用できます。
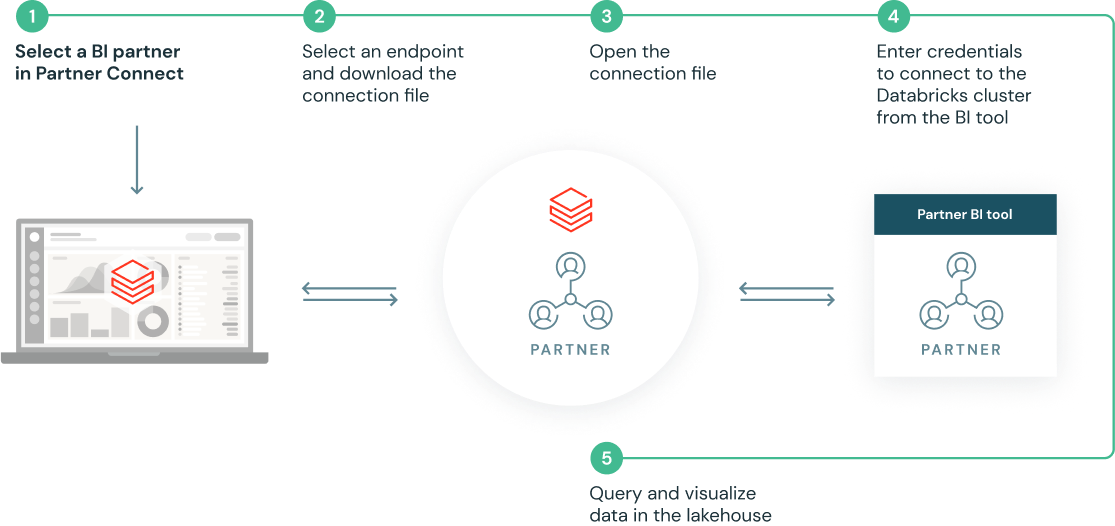
事前構築された統合で設定を容易に
Partner Connect は、クラスタ、トー�クン、接続ファイルなどのリソースを自動的に構成することで、パートナーのソリューションの統合をシンプルにします。
Databricks のパートナーとして
Databricks のパートナーになることで、分析結果や知見をより迅速にお客様に提供できるユニークなポジショニングが可能になります。Databricks の開発者およびパートナー向けのリソースと、クラウドベースのオープンなプラットフォームを活用して、共にビジネスを発展させましょう!
デモ
関連リソース
ブログ
ドキュメント
ご相談をお待ちしております
Databricks の開発者およびパートナー向けのリソースと、クラウドベースのオープンなプラットフォームを活用して、共にビジネスを発展させましょう!