
トップチームは統一されたオープンなガバナンスで成功します
ガバナンス、発見、監視、共有 - すべて一箇所で
データとAI全体で開放的で知的なガバナンスを通じて、データランドスケープを統一し、コンプライアンスを合理化し、より速く信頼性のある洞察を引き出しますガバナンスを統合
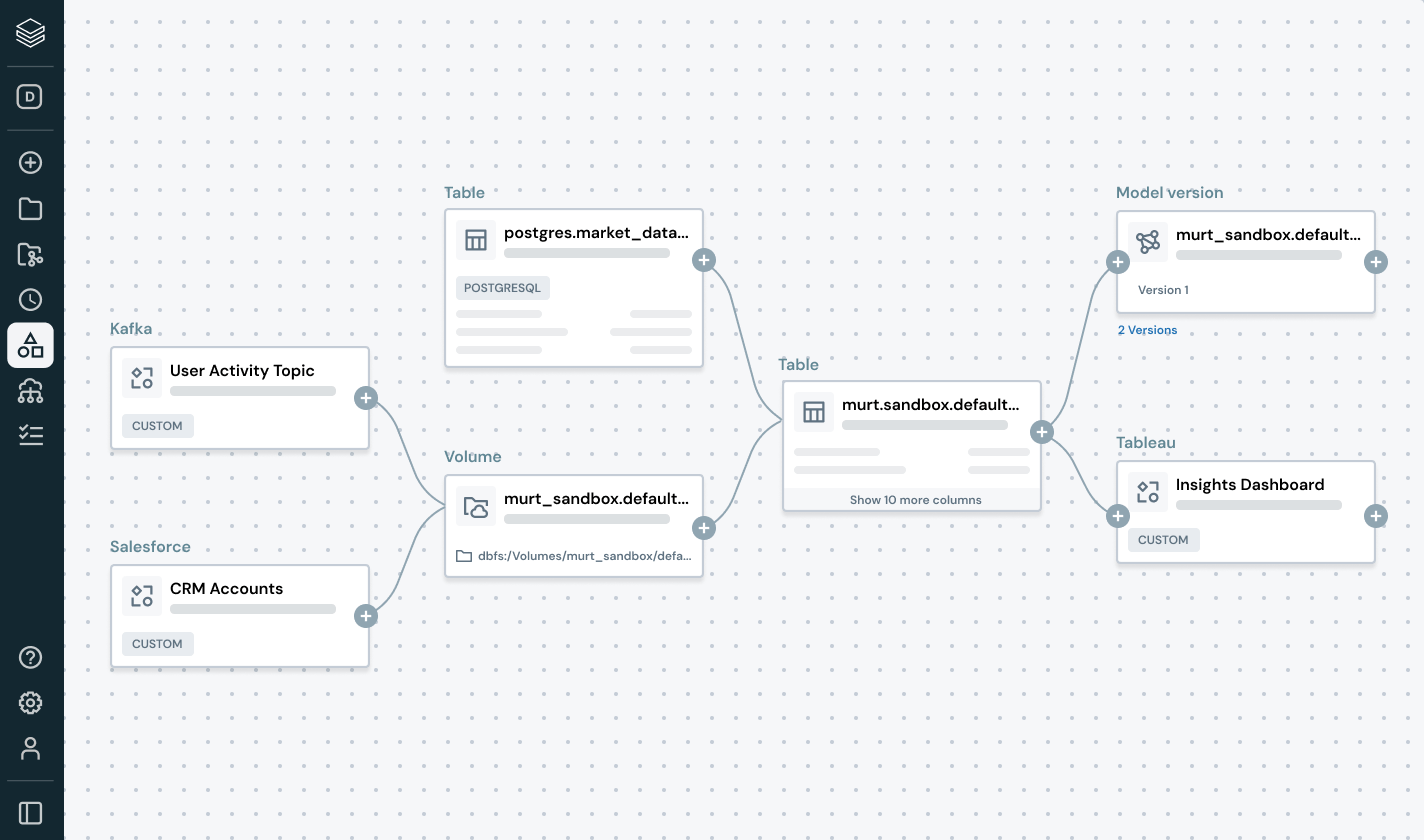
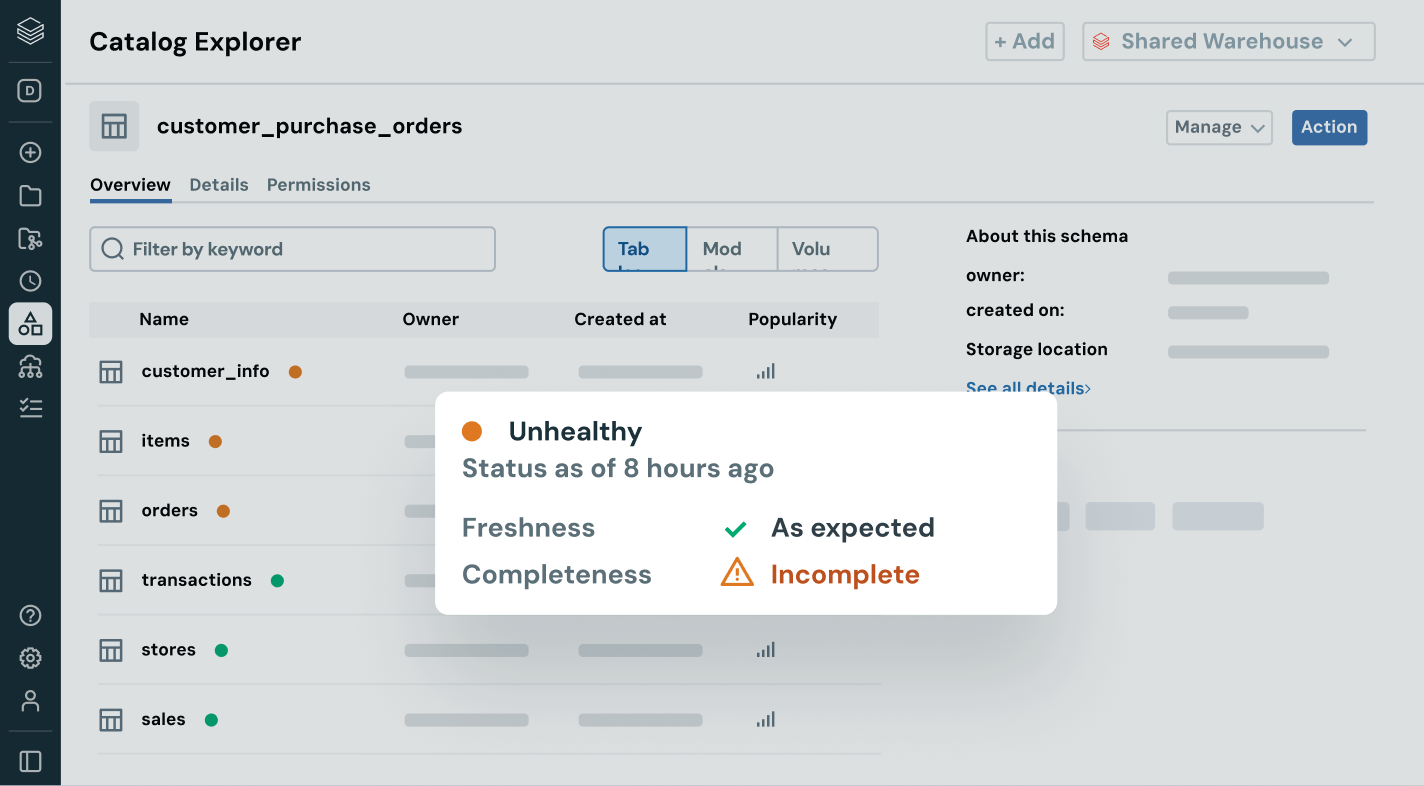
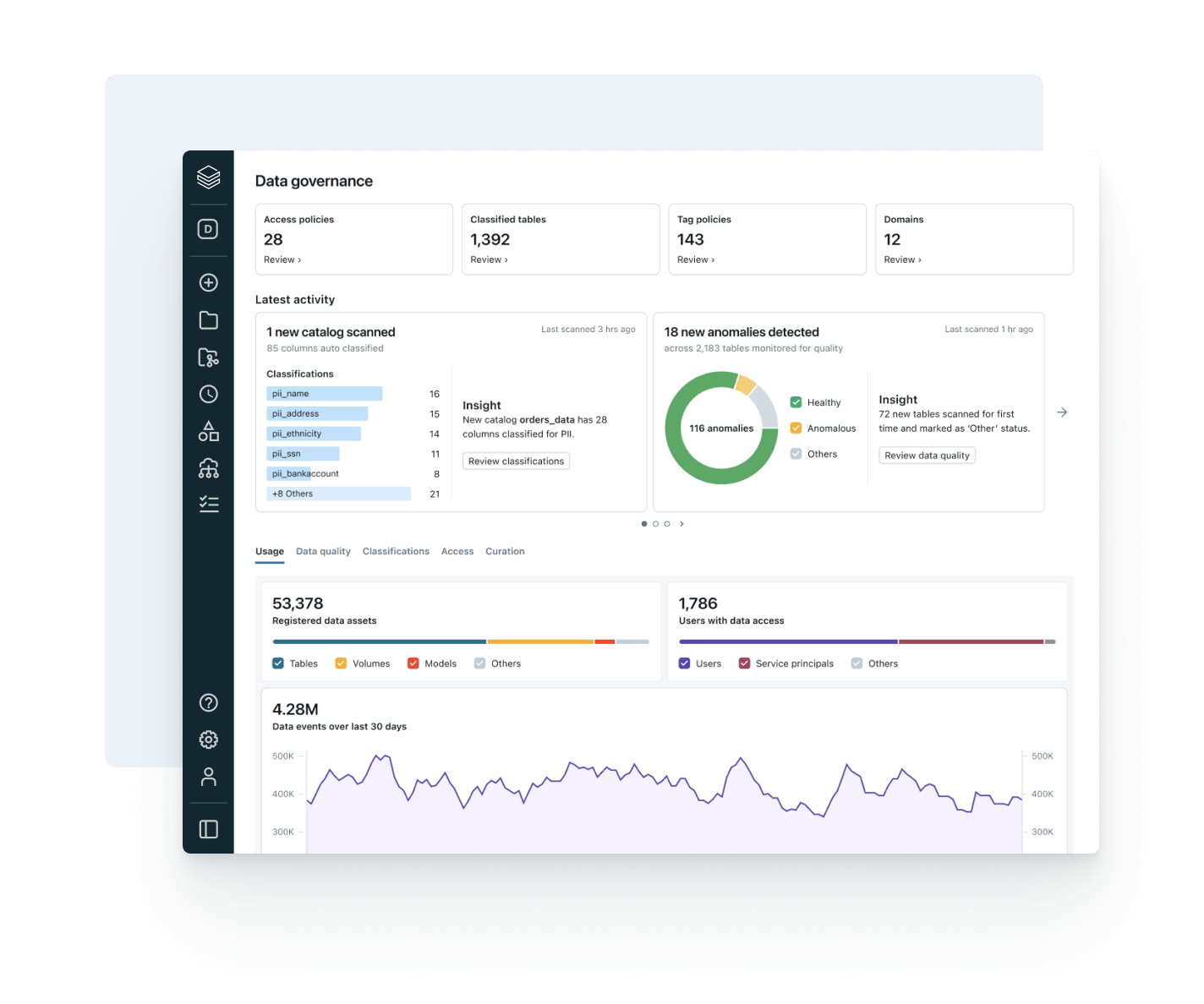
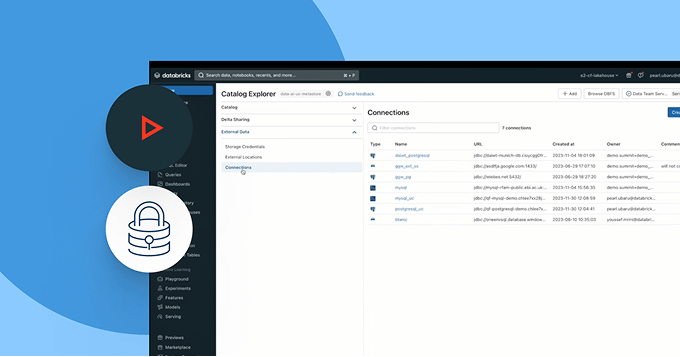
構造化データ、非構造化データ、MLモデル、ビジネス指標を問わず、一貫した発見、アクセス、品質監視、コンプライアンスコントロールを任意のクラウドで実施します。統一されたガバナンスにより、リスクを減らし、監査を簡素化し、コントロールを妥協することなくデータアクセスを加速できます。
オープン
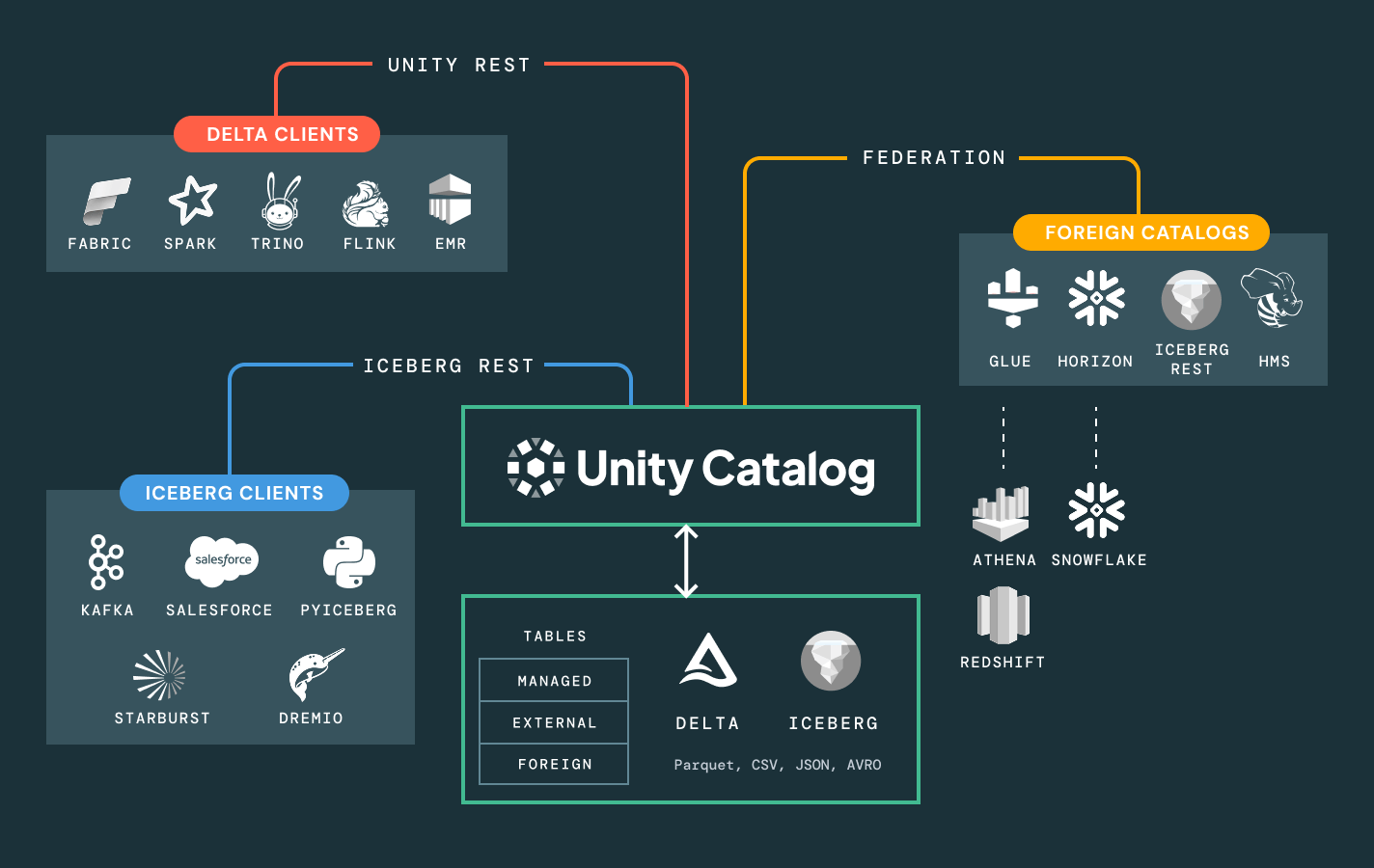
プラットフォームロックインから解放されます。お選びのオープンレイクハウスフォーマット(Delta、Apache Iceberg™、Hudi、Parquet)を活用し、移行なしで外部データソースに接続し、オープンAPIを通じて既存のBI、AI、カタログツールと統合します。データを内部またはパートナーと共有している場合でも、セキュアでスケーラブルなオープンスタンダードベースのコラボレーションを実現します。
組み込みのインテリジェンス
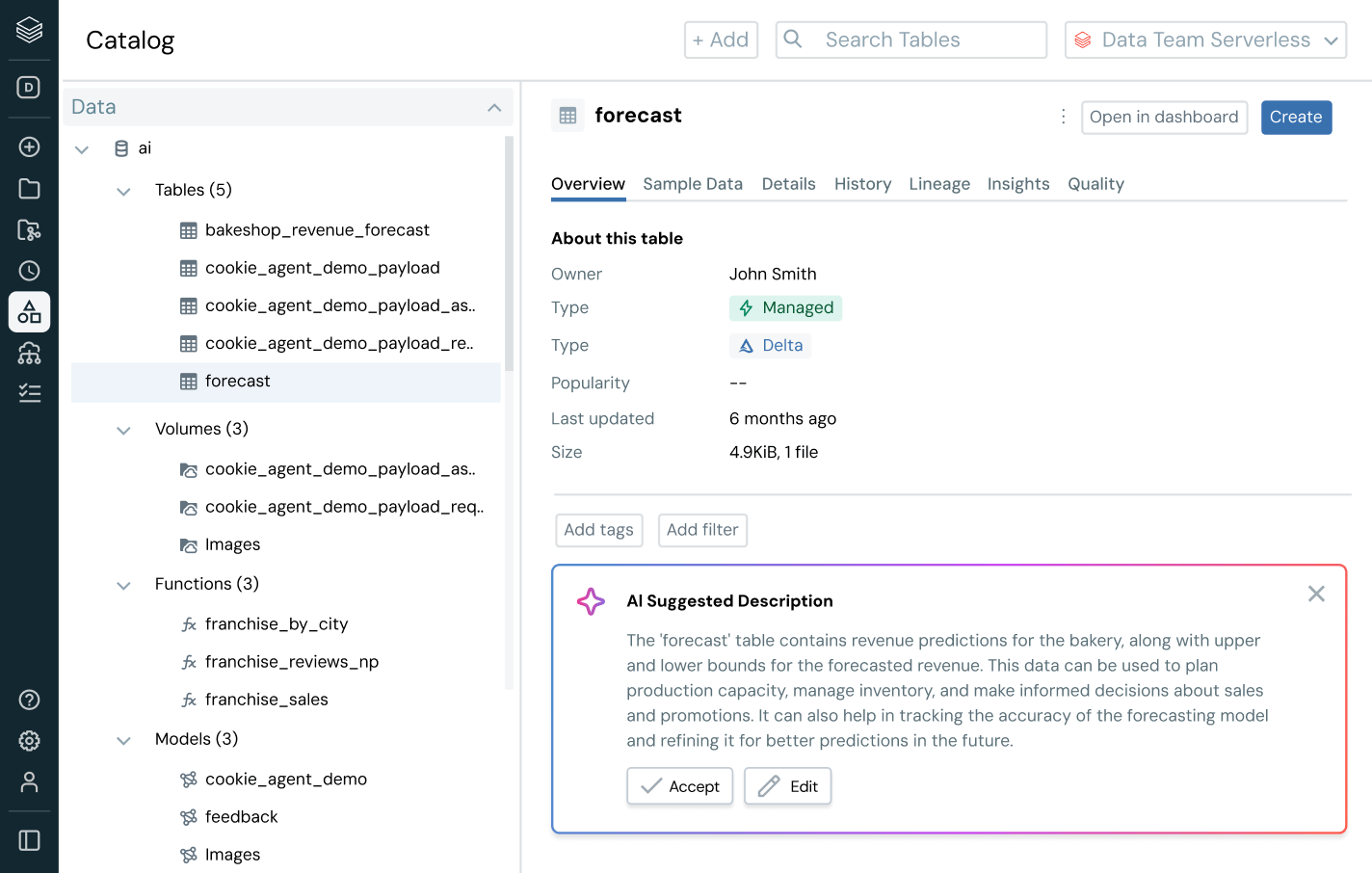
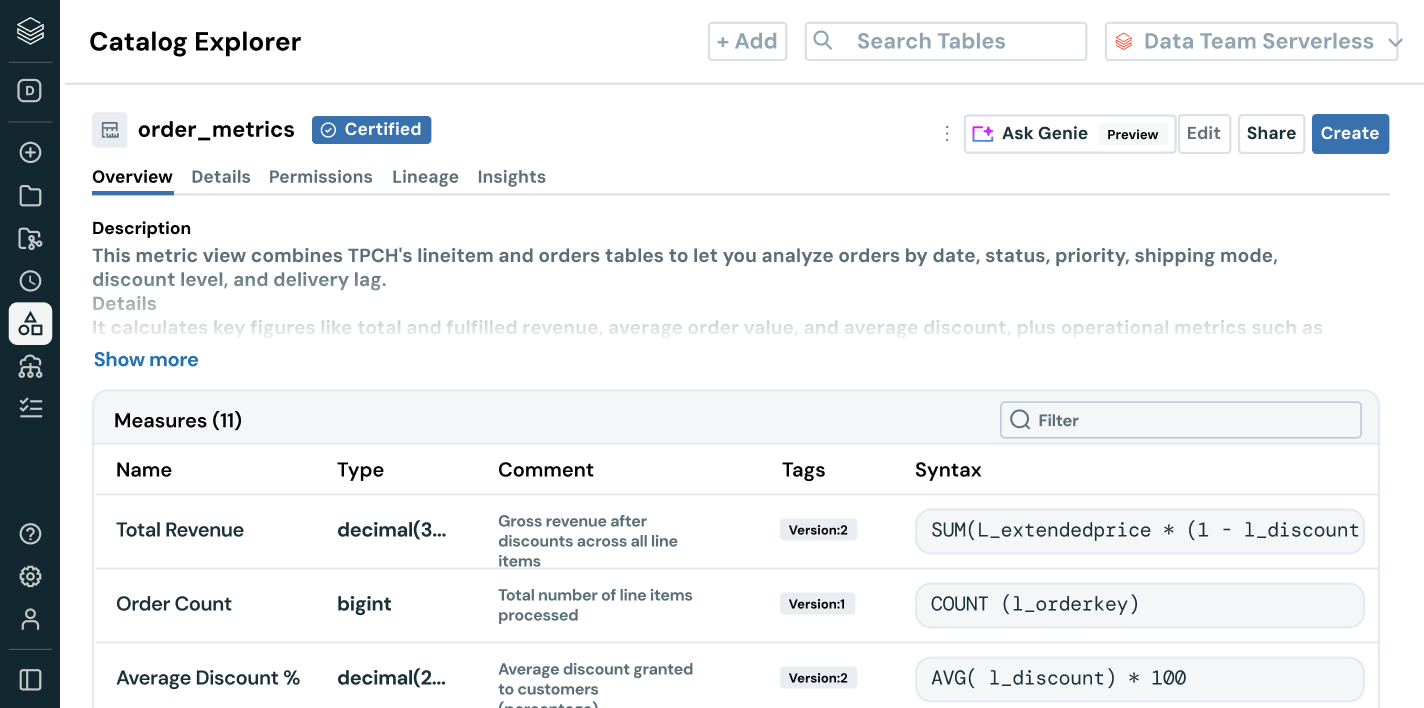
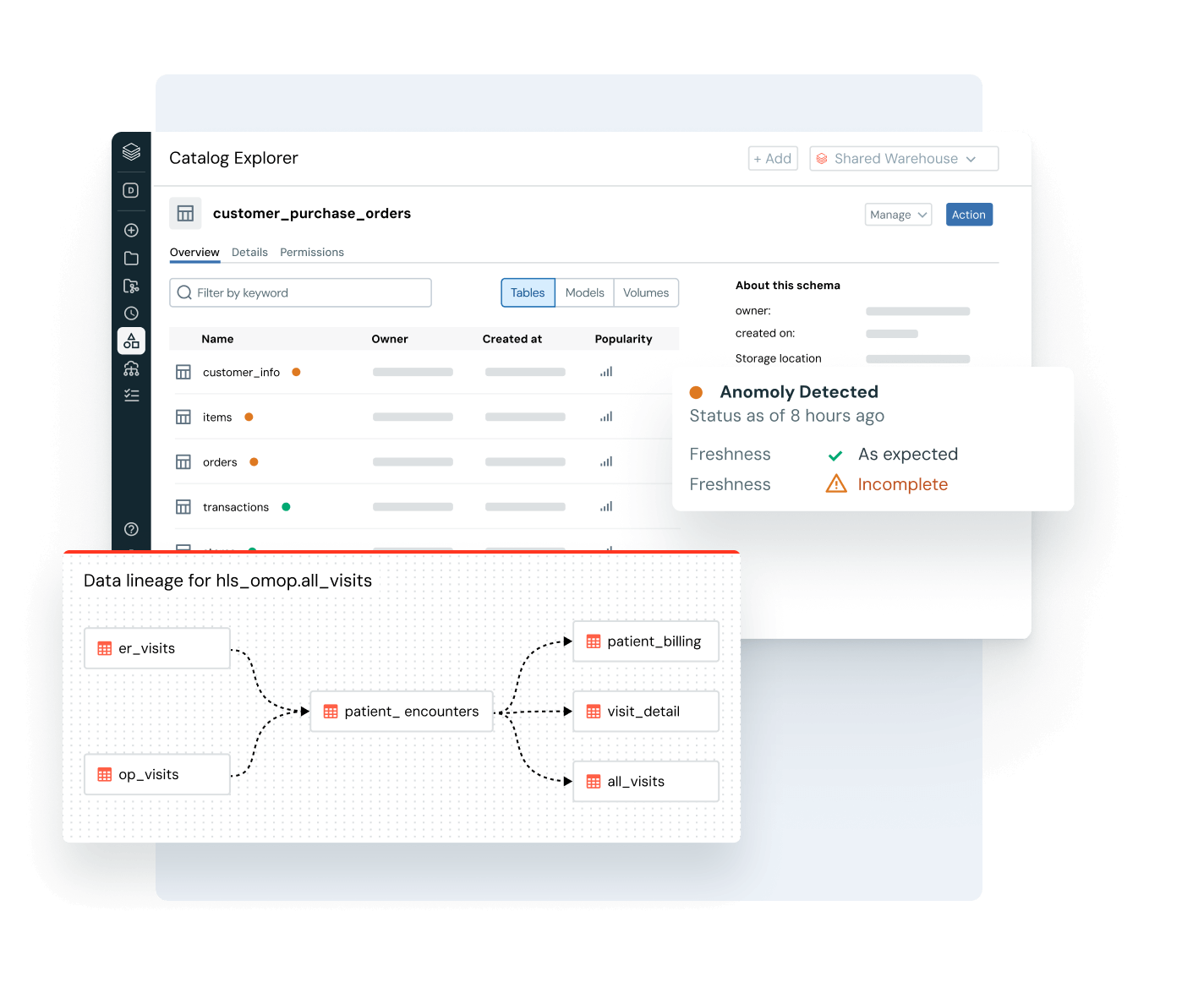
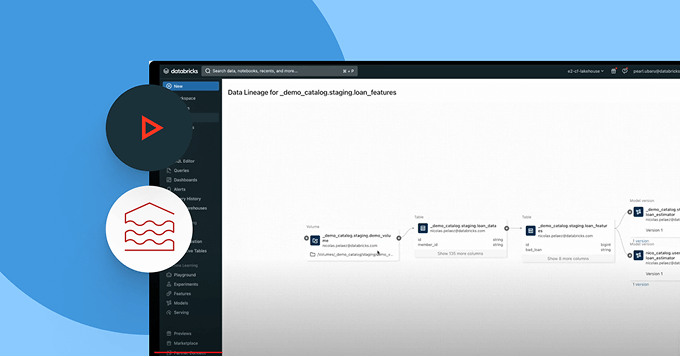
データの発見とアクセス管理を超えて - ユーザーにビジネスコンテキストを提供します。組み込みの系統、使用洞察、ビジネスセマンティクスにより、ユーザーはデータをより早く見つけ、理解し、探索できます。AIによる文書化、自然言語検索、会話型スペースが、技術者とビジネスユーザーがデータから意思決定に至るまでのプロセスを加速し、完全なビジネスコンテキストを提供します。
組み込みのインテリジェントガバナンス
インテリジェントなガバナンスを用いて、全体のデータとAIエステートを通じて発見、コンプライアンス、監視を簡素化しますDelta Lake、Apache Iceberg、Hudi、Parquetなどのオープンデータフォーマットを通じて、すべての構造化データ、非構造化データ、ビジネス指標、AIモデルのための統一カタログ。

その他の機能
統一されたガバナンスでデータの全ビジネス価値を引き出します

すべてのデータとAI資産、ユーザーを通じてガバナンスを標準化します - 妥協なしに
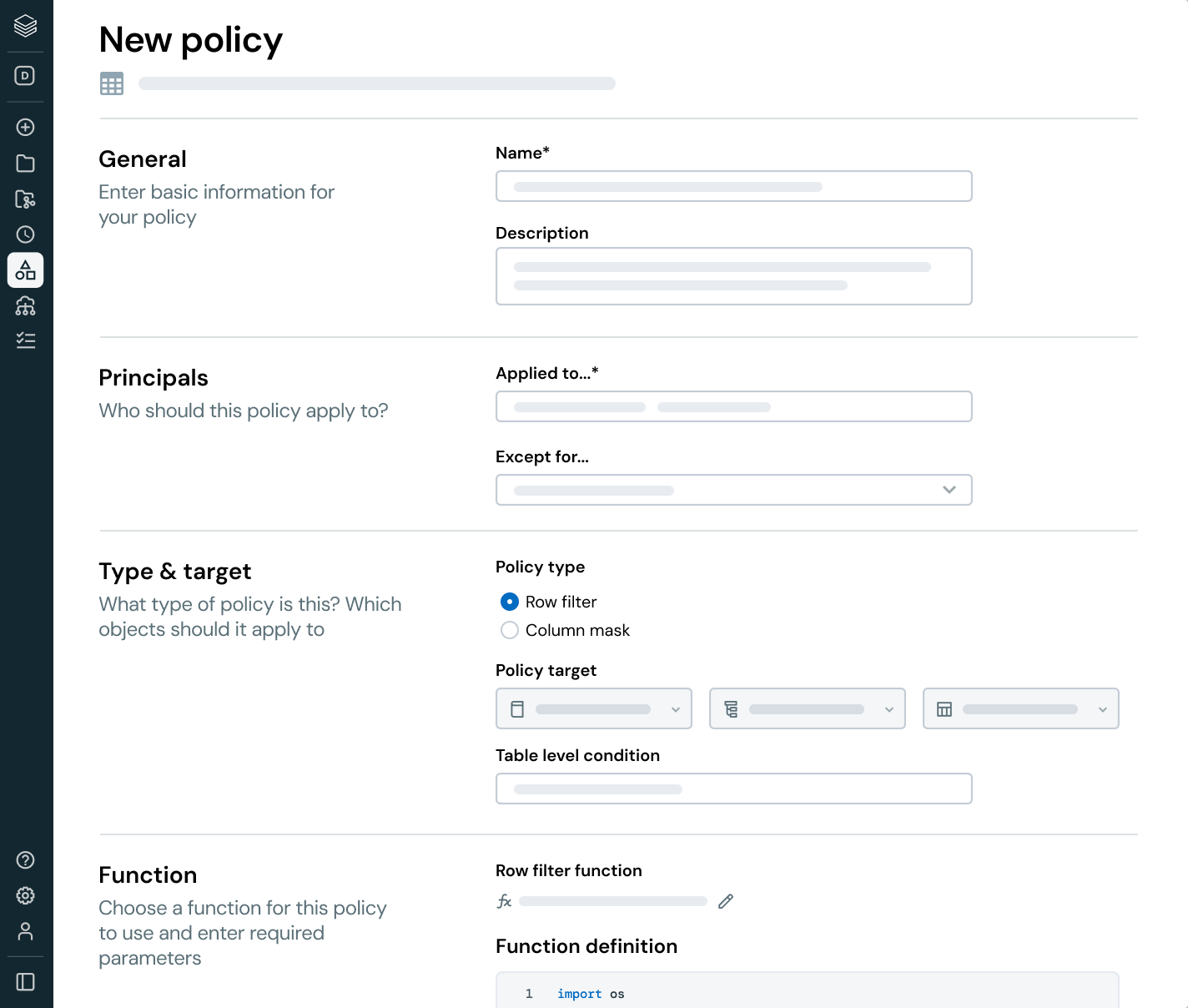
すべてのビジネスユニット、プラットフォーム、データタイプを通じてアクセス、分類、コンプライアンスポリシーを統一します。
- 構造化データ、非構造化ファイル、AI資産を通じて一貫したガバナンスを適用します
- 属性と自動化を使用してアクセス制御をスケールします
- データプライバシー、規制コンプライアンス、リスク軽減のためのポリシーを中央で管理します
- ポリシーの強制と監査のための単一の画面で運用オーバーヘッドを削減します
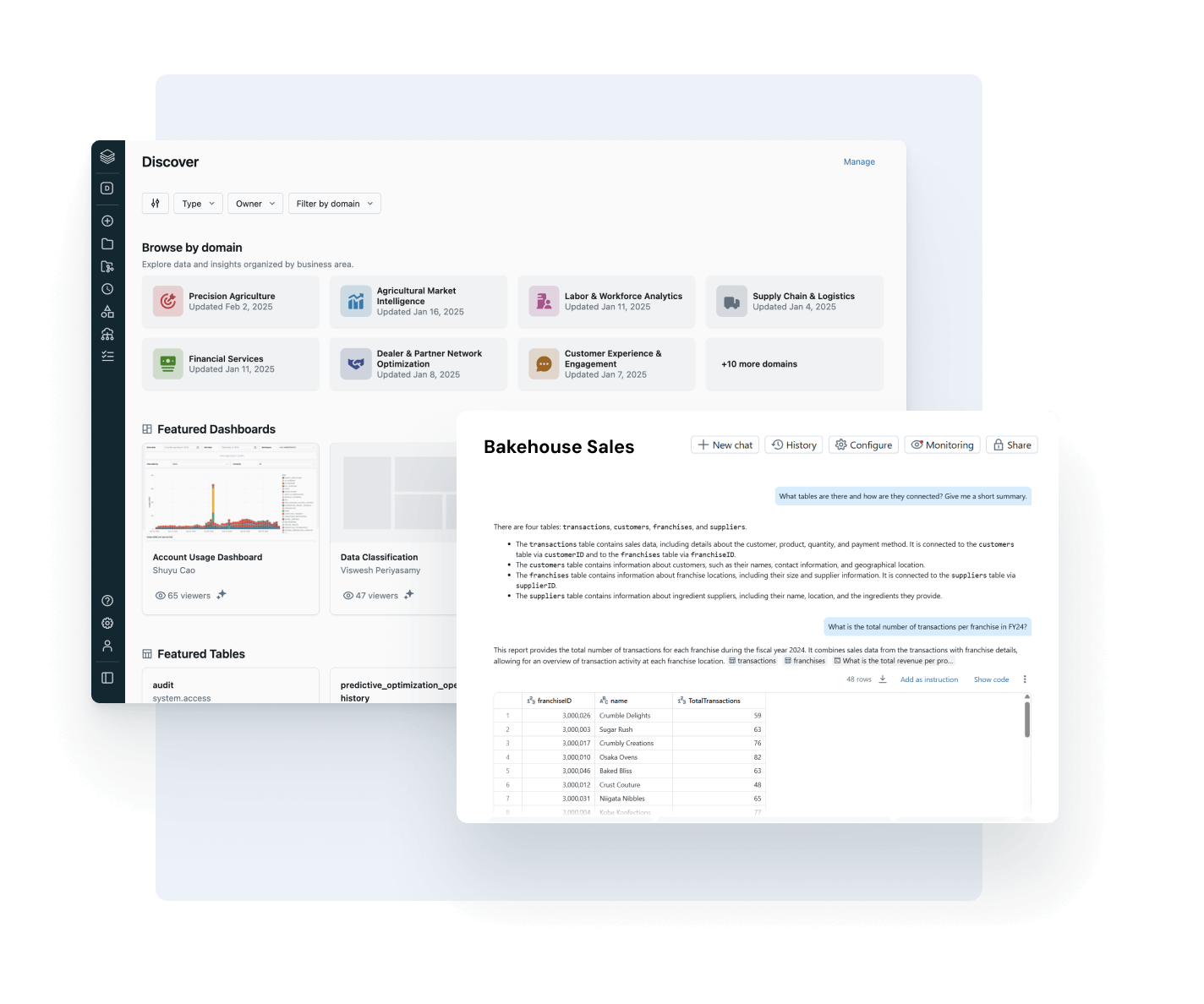
Unity Catalogのデモを探索します

さらに詳しく
ガバナンス、コラボレーション、データインテリジェンスを通じてUnity Catalogの力を拡張する製品を探索します。
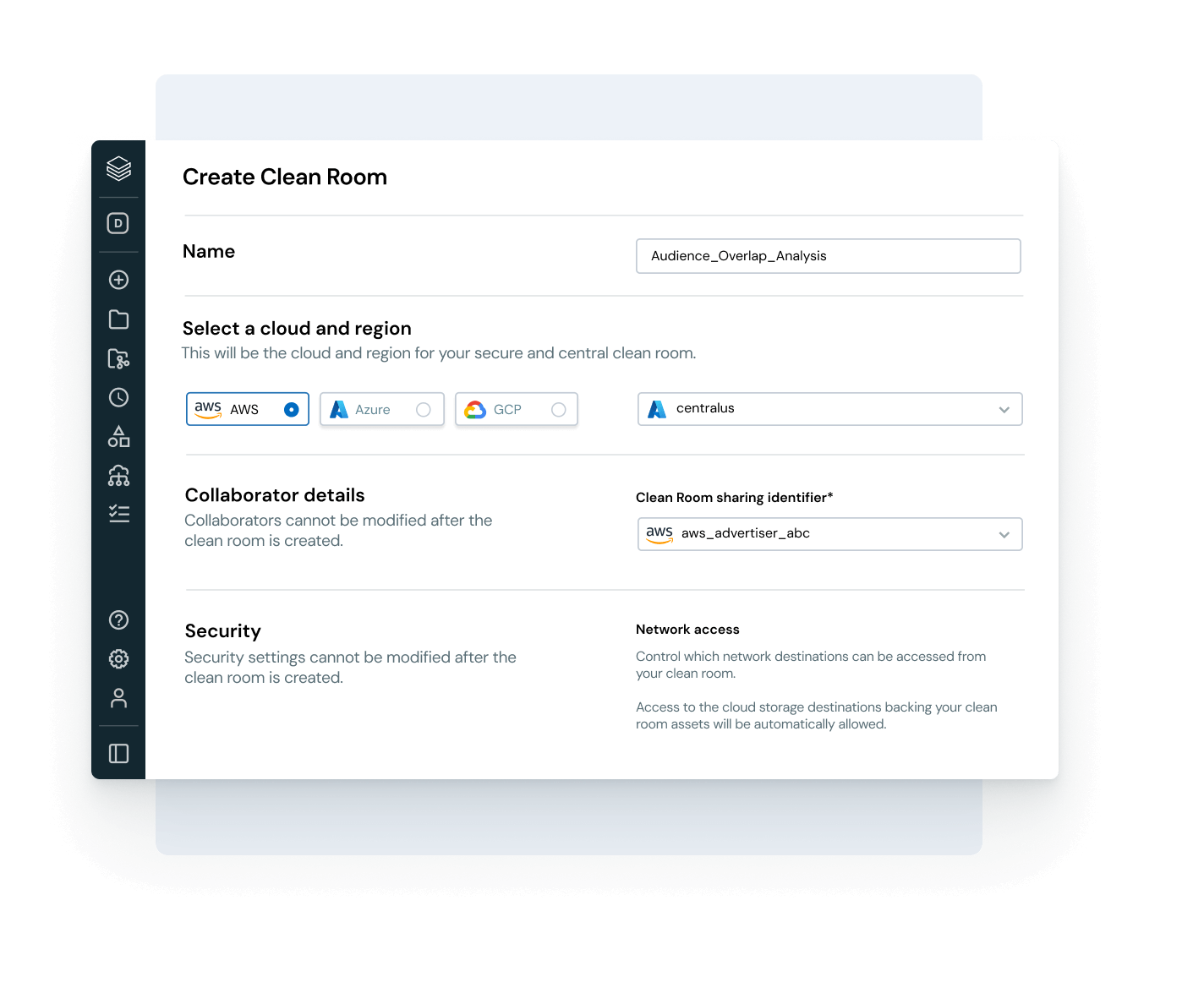
Databricks Clean Room
生のデータへの直接アクセスを提供せずに、複数のパーティからの共有データを分析します。

Databricks Marketplace
データ、AI、分析アセット(MLモデルやノートブックなど)のオープンマーケット。

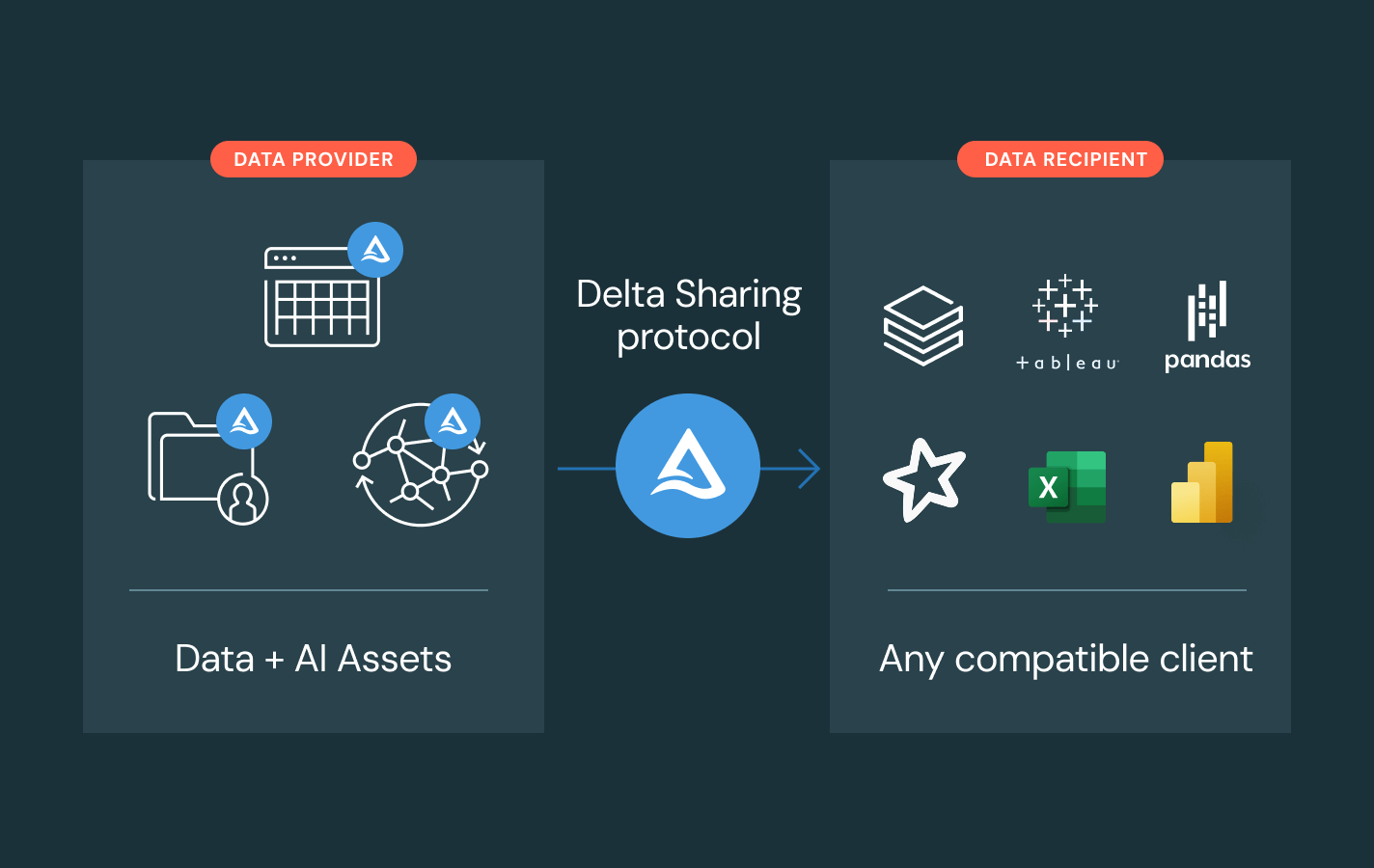
Delta Sharing
プラットフォーム間でのデータとAIの共有に対するオープンソースのアプローチ。中央集権的なガバナンスとレプリケーションなしでライブデータを共有します。

AI/BI Genie
生成型AIによって駆動される会話型体験で、ビジネスチームがデータを探索し、リアルタイムで自己サービスの洞察を得るためのものです。

Databricks Assistant
タスクを自然言語で説明すると、Assistant が SQL クエリの生成、複雑なコードの説明、エラーの自動修正をします。
Databricks データ・インテリジェンス・プラットフォーム
Databricks データ・インテリジェンス・プラットフォームで利用可能なあらゆるツールを活用し、組織全体のデータと AI をシームレスに統合できます。



