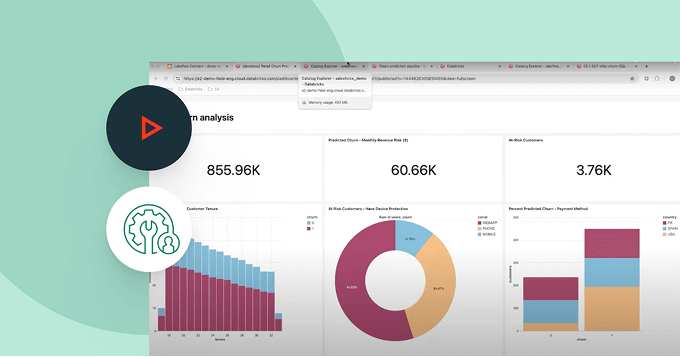
あなたのデータから価値を引き出すための簡単な手順をいくつか紹介します
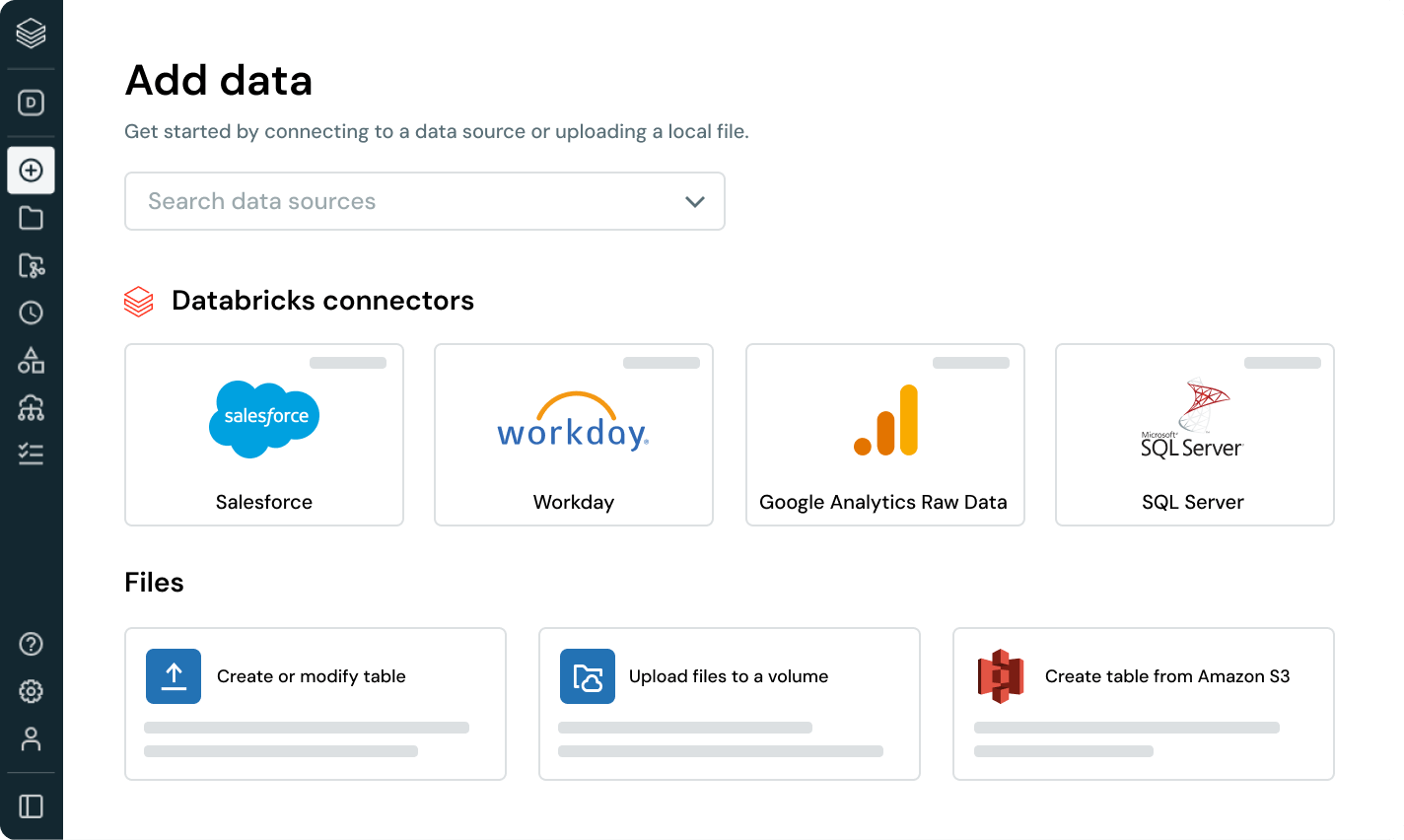
人気のエンタープライズアプリケーション、ファイルソース、データベース用の組み込みデータコネクタが利用可能です。柔軟で使いやすい
完全に管理されたコネクタは、簡単な設定とデータアクセスの民主化のためのシンプルなUIとAPIを提供します。自動化された機能も、最小限のオーバーヘッドでパイプラインのメン�テナンスを簡素化するのに役立ちます。
組み込みコネクタ
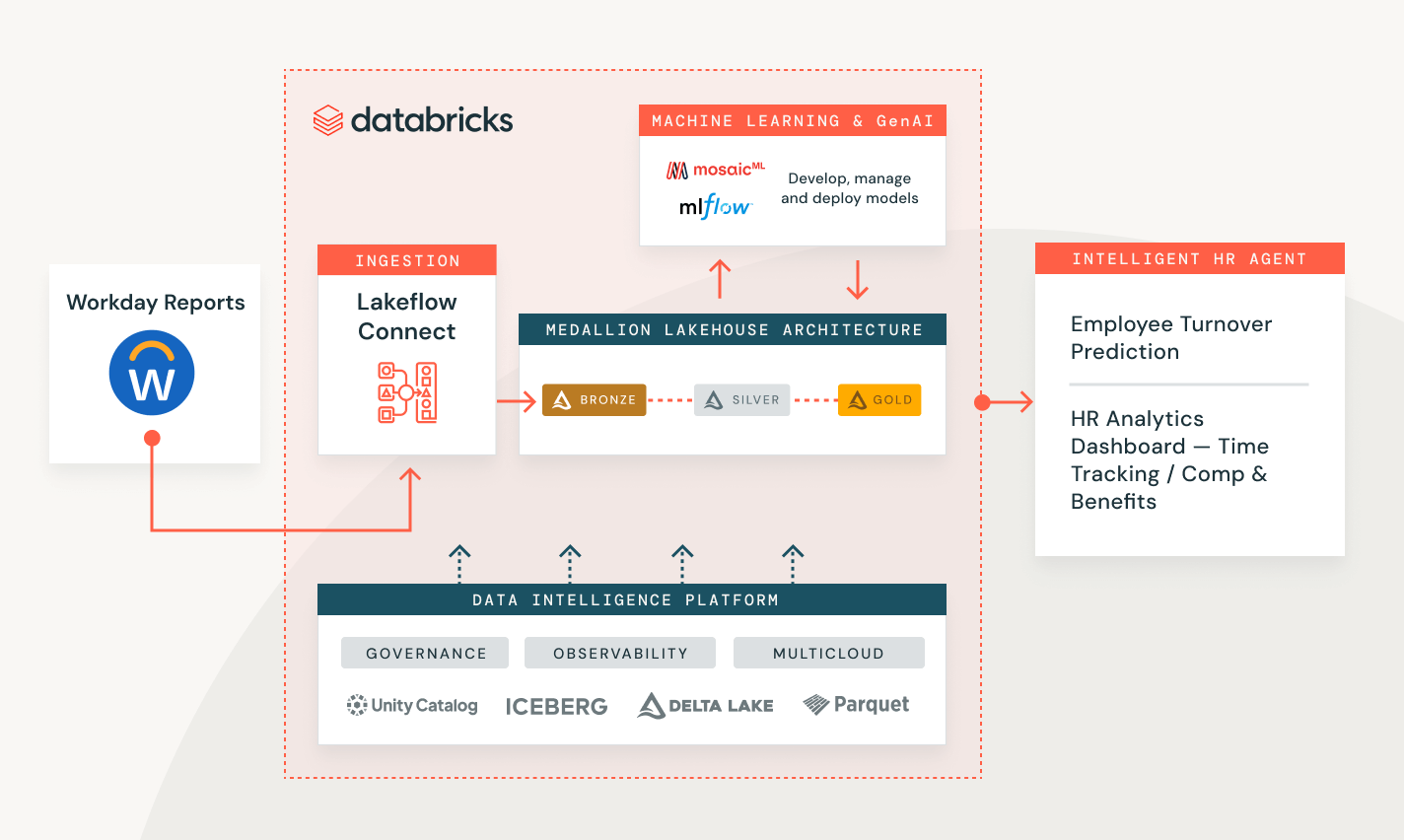
データの取り込みは、データインテリジェンスプラットフォームと完全に統合されています。Unity Catalogからのガバナンス、Lakehouse Monitoringからの観測性、そして分析、機械学習、BIのワークフローとのシームレスなオーケストレーションを用いて、摂取パイプラインを作成します。
効率的な取り込み
効率を上げ、価値を得るまでの時間を短縮します。最適化された増分読み取りと書き込み、およびデータ変換は、パイプラインのパフォーマンスと信頼性を向上させ、ボトルネックを減らし、スケーラビリティのためのソースデータへの影響を軽減します。

人気のデータソースに対する堅牢な取り込み機能
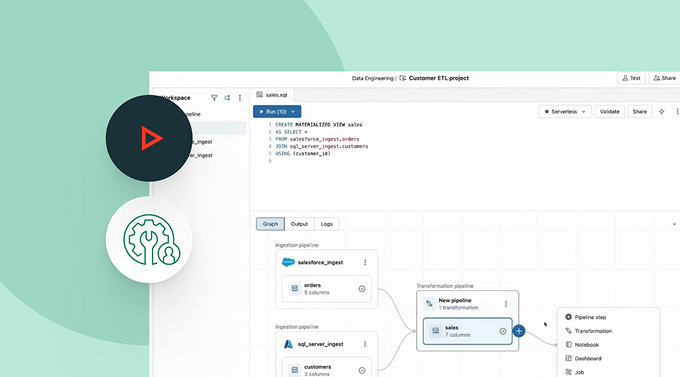
すべてのデータをデータインテリジェンスプラットフォームに取り込むことは、価値を抽出し、組織の最も困難なデータ問題を解決するための最初のステップです。ノーコードのユーザーインターフェース(UI)またはシンプルなAPIは、データ専門家が自己サービスを提供できるようにし��、プログラミングの時間を節約します。



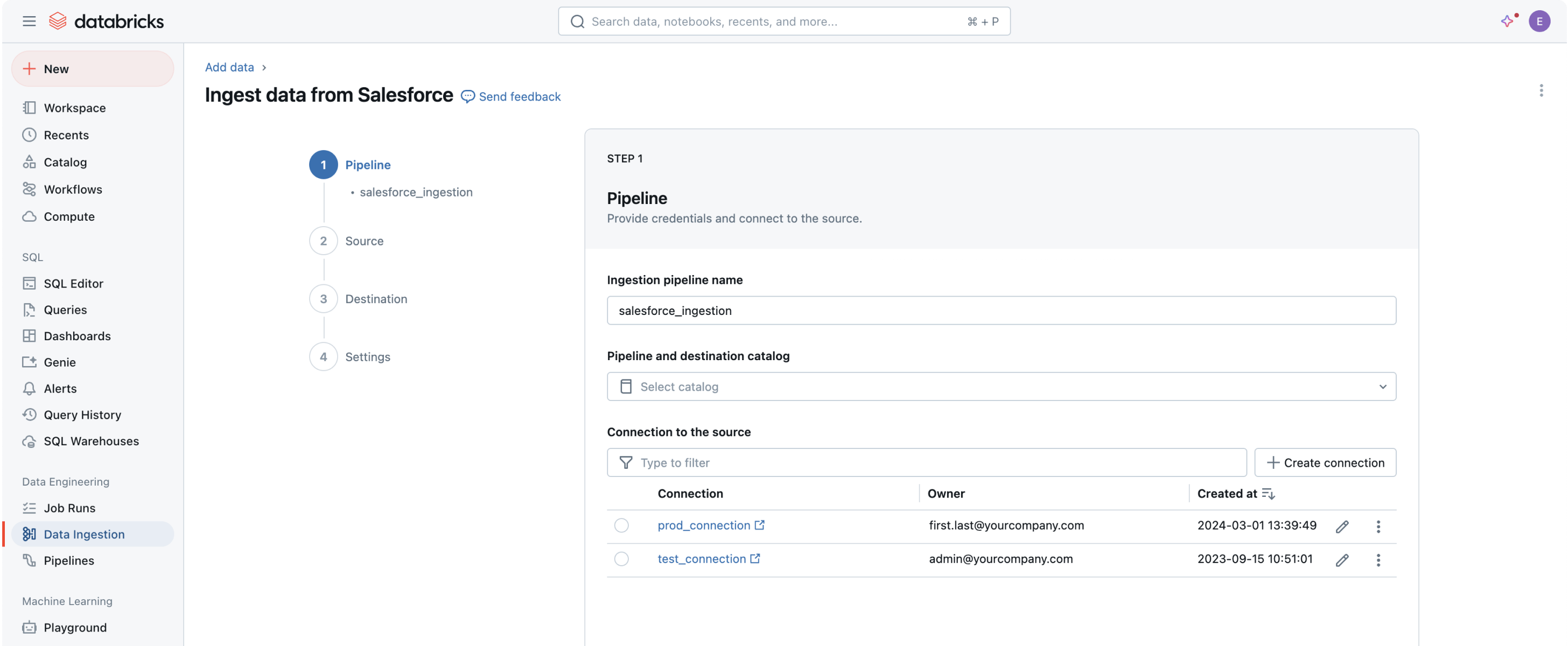
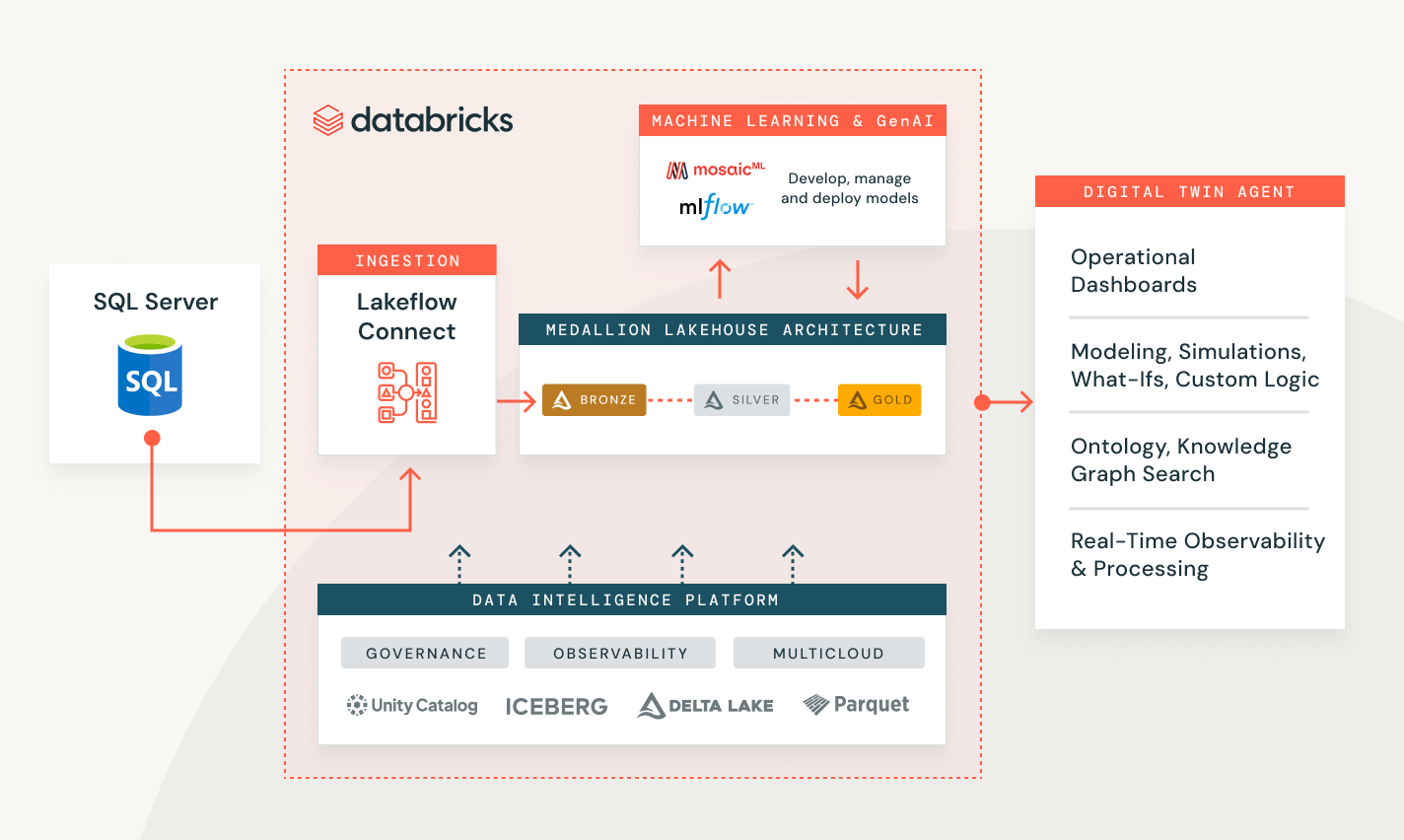
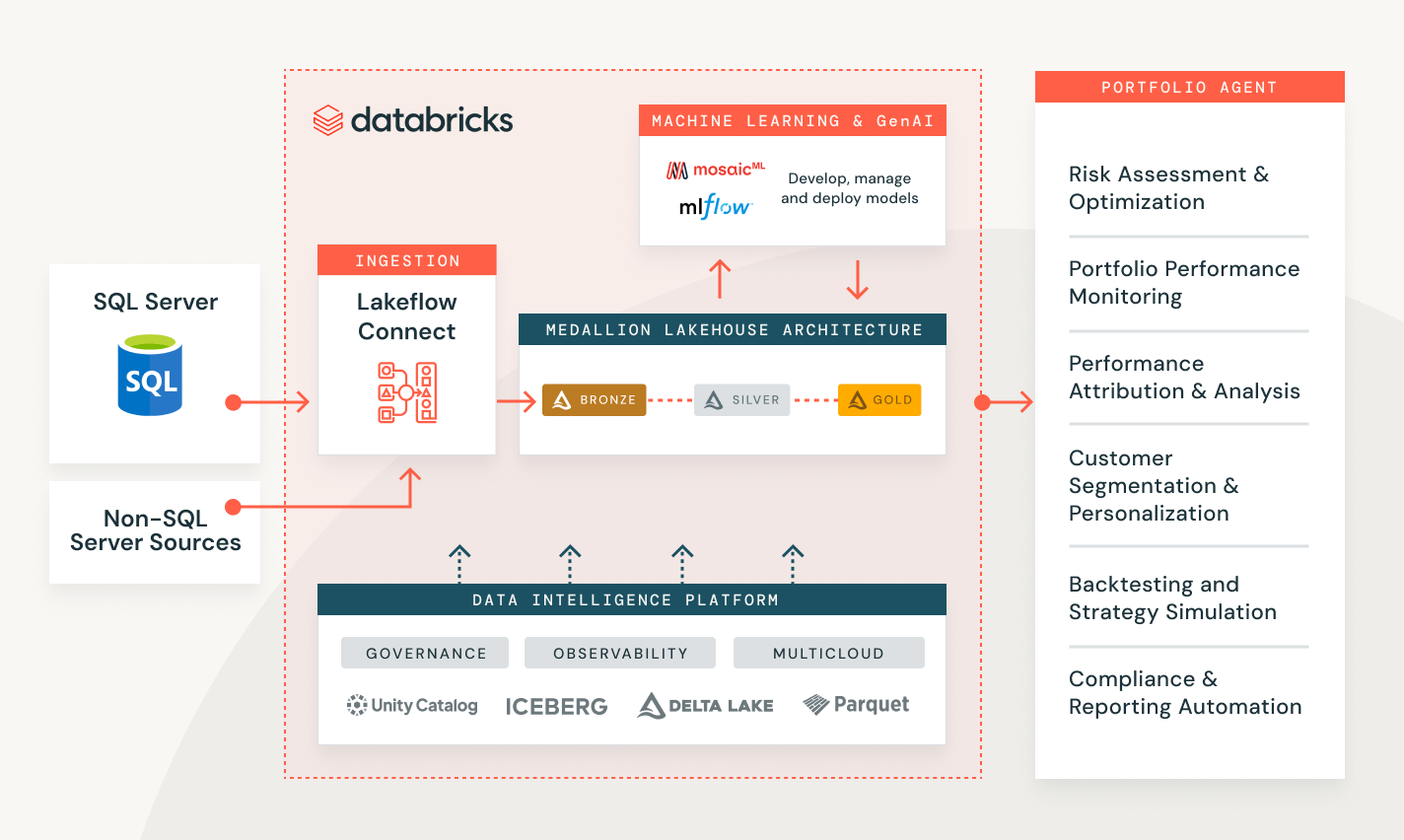
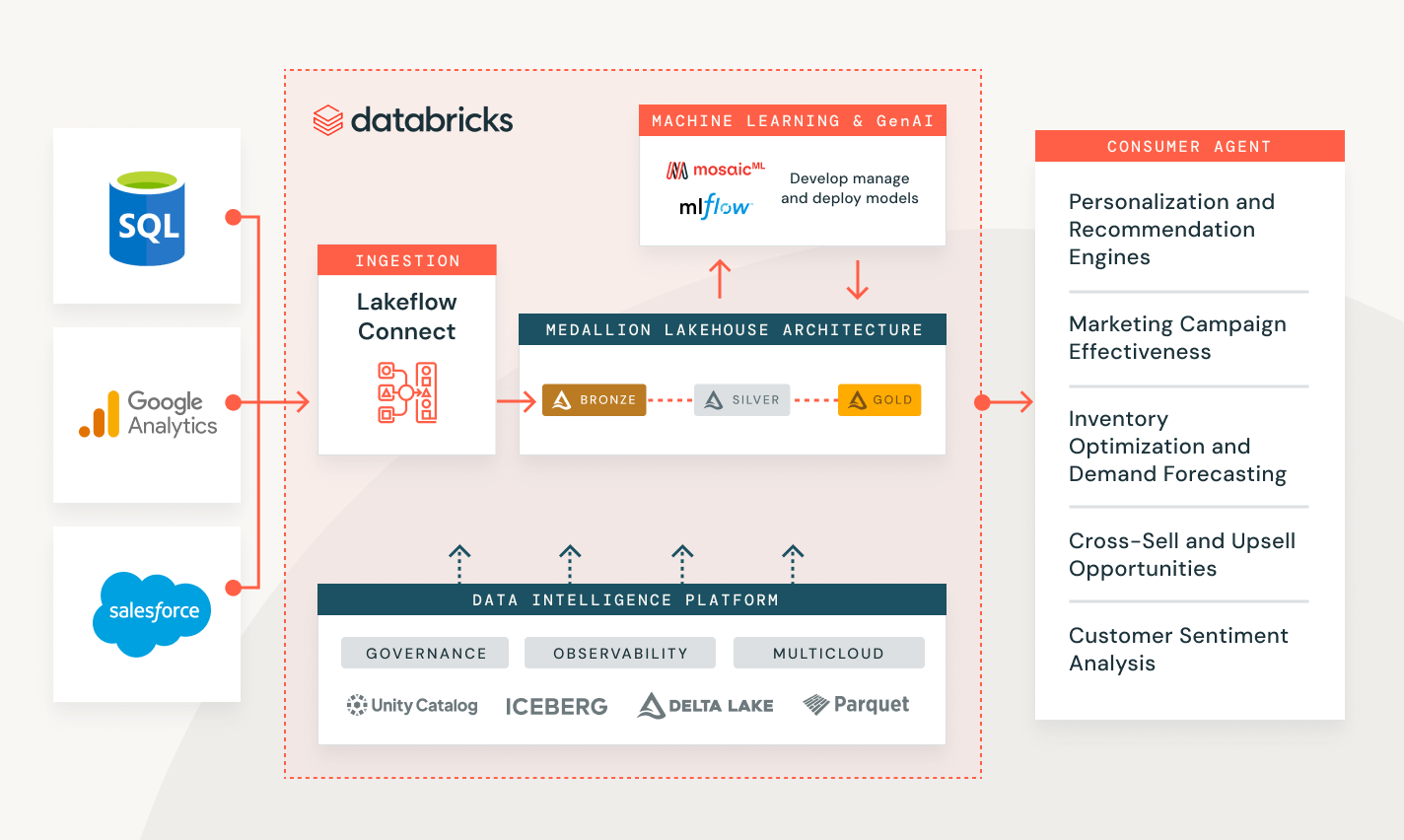
Databricksを使用したデータ取り込み
様々な業界での顧客の問題を解決



使用量に応じた価格設定で、支出を抑制
使用した製品に対する秒単位での課金となります。さらに詳しく
データインテリジェンスプラットフォームで他の統合された、インテリジェントなオファリングを探索してみてください。
Lakeflowジョブ
チームが深い観察可能性、高い信頼性、幅広いタスクタイプのサポートを持つETL、分析、AIワークフローをより良く自動化し、調整するための装備。
Spark宣言的パイプライン
自動化されたデータ品質、変更データキャプチャ(CDC)、データ取り込み、変換、統一されたガバナンスでバッチおよびストリーミングETLを簡素化します。

Unity Catalog
Databricks Data Intelligence Platformに組み込まれた、データとAIのための業界唯一の統一されたオープンなガバナンスソリューションで、すべてのデータ資産をシームレスに管理します。

Delta Lake
あなたのレイクハウス内のデータを統一し、すべての形式とタイプを通じて、すべての分析とAIワークロードのために利用します。