Azure 上のデータレイク
レイクハウスをパワーアップさせる完全かつ信頼性のあるデータソース

Azure データレイクとは何ですか?
Azure データレイクには、スケーラブルなクラウドデータストレージおよび分析サービスが含まれます。 Azure Data Lake Storage は、さまざまな処理、分析、データサイエンスのユースケース向けに、あらゆるサイズ、フォーマット、速度のデータを保存できるようにします。 Azure Data Lake Storage は、Azure Databricks などの他の Azure サービスと併用することで、組織全体でデータを保存・取得するための、はるか��にコスト効率の高い方法となります。
Azure Data Lake は、データの大小、高速・低速、構造化・非構造化を問わず、Azure ID、管理、セキュリティと統合し、データ管理とガバナンスを簡素化します。 Azure ストレージはデータを自動的に暗号化し、Azure Databricks は組織のセキュリティとコンプライアンスのニーズに合わせてデータを保護するツールを提供します。

なぜ Azure データレイクが必要なのですか?
データレイクはオープンフォーマットなので、ユーザーはデータウェアハウスのようなプロプライエタリなシステムにロックインされることはありません。 オープンスタンダードとフォーマットは、最新のデータアーキテクチャにおいてますます重要になってきています。 また、データレイクは、オブジェクトストレージを拡張して活用できるため、高耐久性、低コストのメリットがあります。現在の企業において、非構造化データを高度な分析と機械学習に利活用することは最も戦略的な優先事項の 1 つです。さまざまな形式(構造化、非構造化、半構造化)で未加工データを取り込む独自の機能と、これまでに挙げた他のメリットにより、データレイクはデータストレージの明確な選択肢となり��ます。
データレイクが適切に設計されている場合、次のことが可能になります。
- データサイエンスと機械学習の強化
- データの一元化、統合、カタログ化
- 多様なデータソースとフォーマットを迅速かつシームレスに統合
- セルフサービスツールの提供によりデータを民主化
Azure データレイクと Azure データウェアハウスの違いは何ですか?
データレイクとは、膨大なデータを未加工のネイティブ形式で保存する一元管理のリポジトリです。多種多様な大量データの編成に利用されます。ファイルやフォルダ内にデータを格納する階層型データウェアハウスと比較して、データレイクはフラ��ットなアーキテクチャとオブジェクトストレージでデータを格納します。データレイクは通常、スケーラブルでコモディティ化したハードウェアでクラスタ上に構成されます。その結果、将来必要になった場合に備えて、データ形式やサイズ、保存容量を気にすることなく、未加工データをレイクに保存することができます。
さらに、データレイククラスター 、オンプレミスやクラウドに存在することができます。 歴史的に、「データレイク」という用語は、Hadoop 指向のオブジェクトストレージと関連付けられることが多かったのですが、今日では一般的に、この用語はより広範なオブジェクトストレージのカテゴリを指します。 データをメタデータタグと一意の識別子で格納するオブジェクトストレージにより、リージョン間でのデータの検索と取得は容易で、性能を向上させます。Databricks レイクハウスプラットフォームは、データレイク内の全てのデータを、任意の数のデータドリブンユースケースで利用できるようになります。

Azure データレイクに Delta Lake フォーマットを使用する理由
データレイ�クを Apache Parquet、CSV、JSON、その他のフォーマットから Delta Lake フォーマットに変換する 5 つの主な理由は、以下のとおりです。
- データ破損の防止
- 高速クエリ
- データの鮮度向上
- ML モデルの再現
- コンプライアンスの達成
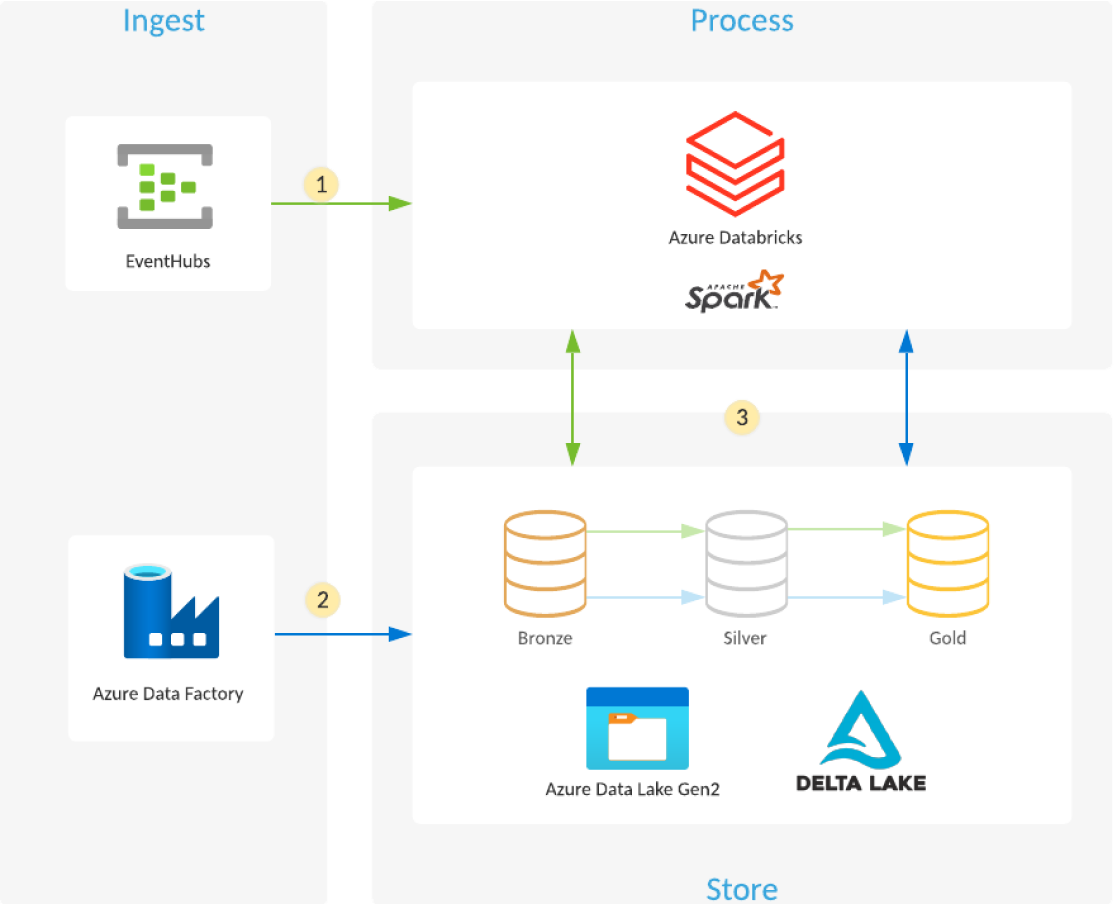
Azure Databricks と Azure Data Lake Storage を使用してデータレイクを構築する方法
Azure Databricks の Managed Delta Lake は、クラウド上でデータレイクのキュレーション、分析、価値の導出を可能にする信頼性のレイヤーを提供します。
- Azure Databricks は、 Azure Event Hub Hub、AzureIoT、または Kafka などのイベントキューからストリーミングデー��タを読み込み、 最適化、圧縮された Delta Lake テーブルとフォルダ(ブロンズ層)に未加工イベントをロードし、Azure Data Lake Storage に保存します。
- スケジュールされた、またはトリガーされた Azure Data Factory パイプラインは、異なるデータソースから未加工フォーマットで Azure Data Lake Storage にデータをコピーします。 Azure Databricks の Auto Loader は、着地したファイルを処理し、Azure Data Lake Storage に格納されている最適化、圧縮された Delta Lake のテーブルとフォルダ(ブロンズ層)にロードします。
- ストリーミングまたはスケジュール化/トリガー化された Azure Databricks ジョブは、ブロンズレイヤーから新しいトランザクションを読み取り、それらを結合、クリーンアップ、変換、集約してから、ACID トランザクション(INSERT、UPDATE、DELETE、MERGE)Delta Lake を使用して、Azure Data Lake Storage 上の に格納されたキュレーションされたデータセット(シルバーおよび ゴールドレイヤー)にロードします。
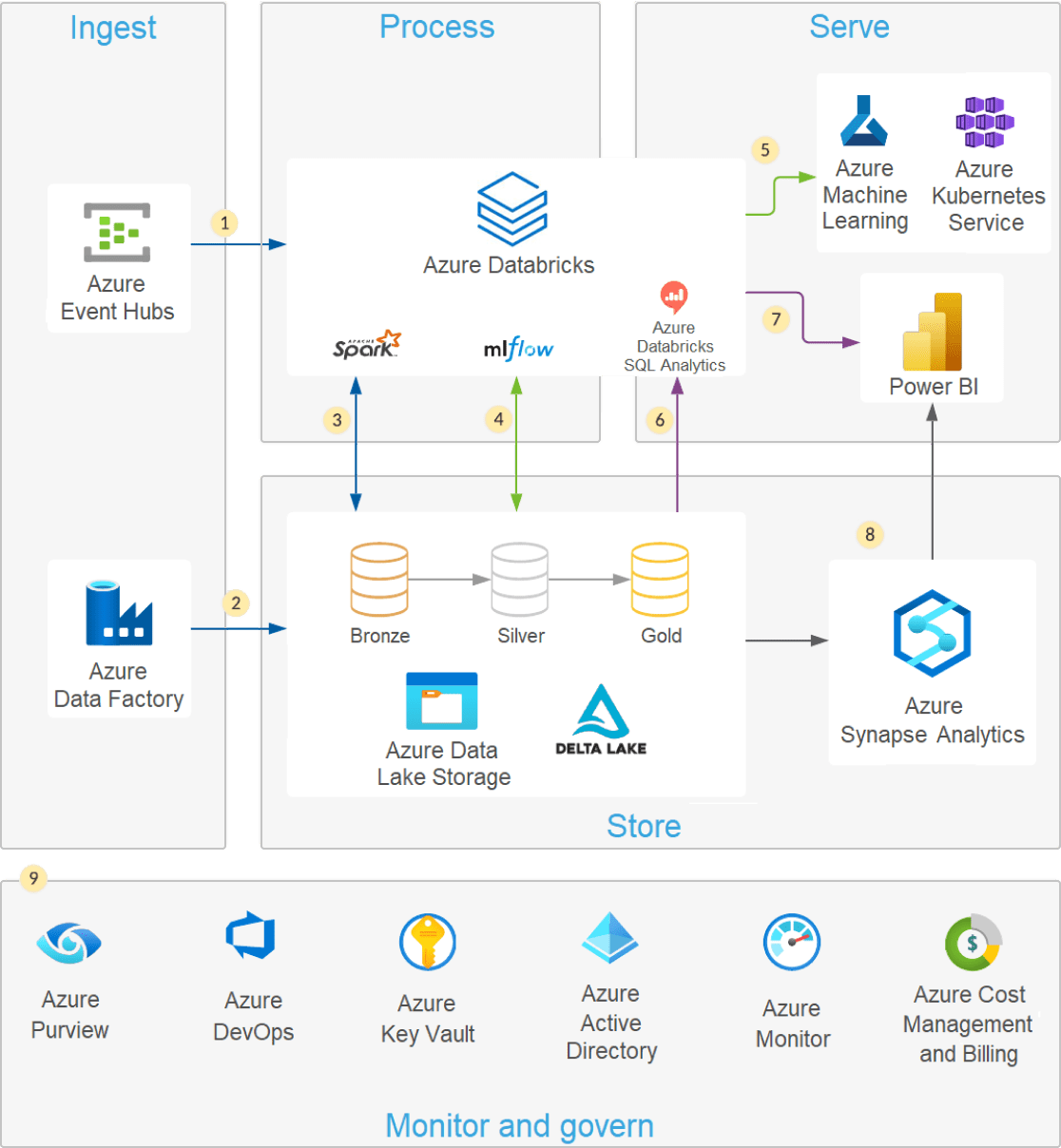
モダンデータレイクアーキテクチャ
モダンなレイクハウスアーキテクチャは、ウェアハウスの性能、信頼性、データの完全性を維持しつつ、データレイクで利用可能な柔軟性、拡張性、非構造化データのサポートを組み合わせています。
最新のデータレイクはクラウドの弾力性を活用し、スキーマや構造を強制することなく、事実上無制限のデータを "そのまま" 保存することができます。 Structured Query Language(SQL)は、データを探索し、価値ある知見を発見するための強力なクエリ言語です。 Delta Lake は、ACID トランザクション、スケーラブルなメタデータ処理、統一されたストリーミングとバッチのデータ処理により、データレイクに信頼性をもたらすオープンソースストレージレイヤーです。 Delta Lake は完全な互換性があり、既存のデータレイクに信頼性をもたらします。
Azure Databricks を使用すれば、SQL と Delta Lake を使用してデータレイクを簡単にクエリできます。 Delta Lake では、データを移動またはコピーすることなく、ストリーミングデータとバッチデータの両方で SQL クエリを実行することができます。 Azure Databricks Delta Lake 、クラウドサービスとのネイティブな統合によるデータレイクのセキュリティ確保、最適なパフォーマンスの提供、データパイプラインの監査とトラブルシューティングの支援など、さらなるメリットを提供します。
- Delta Lake はスケーラブルなクラウドストレージや HDFS と統合し、データのサイロ化を解消します。
- データレイク上で直接 SQL クエ��リと ACID 準拠のトランザクションレイヤーを使用してデータを探索します。
- ゴールド、シルバー、ブロンズの「メダリオンテーブル」を活用して、データパイプラインとアナリティクスワークフローのデータ品質を統合し、簡素化します。
- Delta Lake タイムトラベルを使用して、データの経時変化を確認できます。
- Azure Databricks は、Delta キャッシュ、ファイル圧縮、データスキップなどの機能で性能を最適化します。