高信頼性データパイプラインを容易に構築
ETLのバッチとストリーミング処理が簡素化し、自動化による信頼性と質の高い組み込みデータが伴います。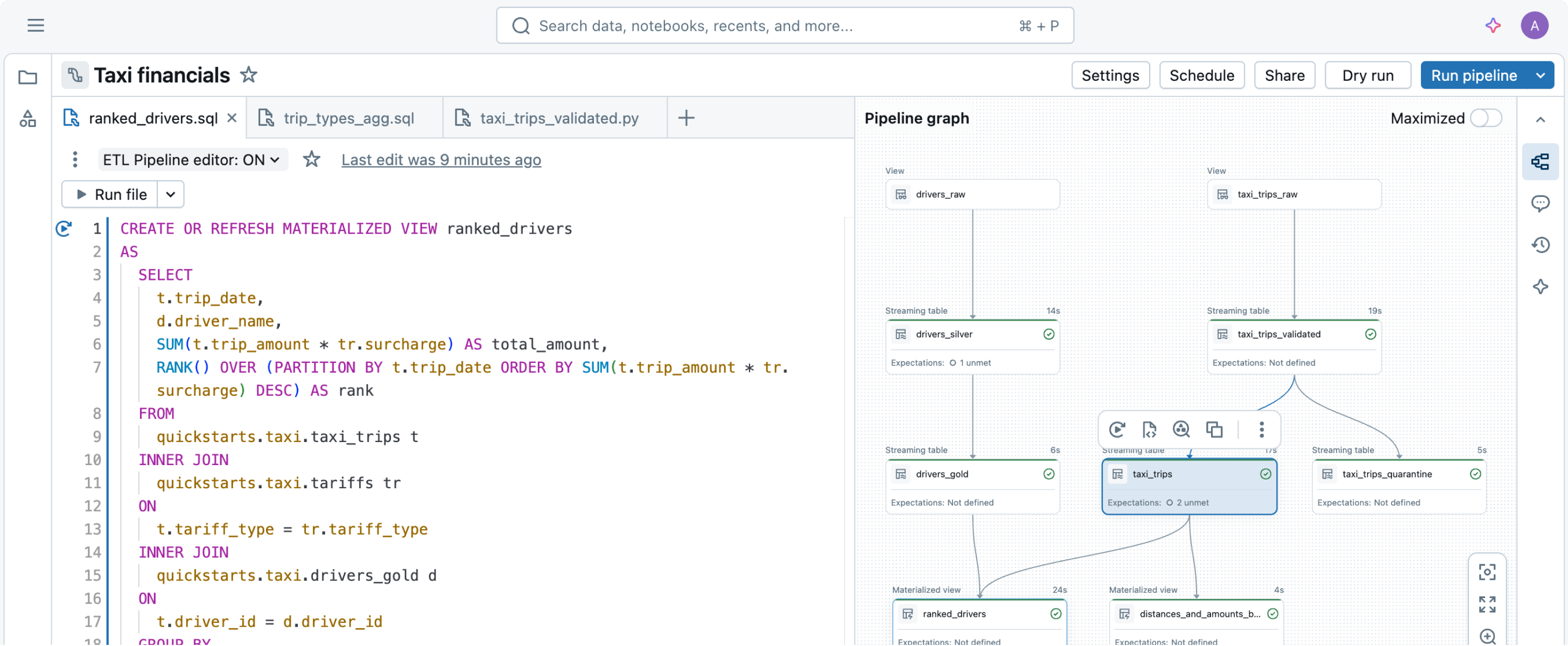
トップチームはインテリジェントなデータパイプラインで成功を収めています
データパイプラインのベストプラクティス、コード化
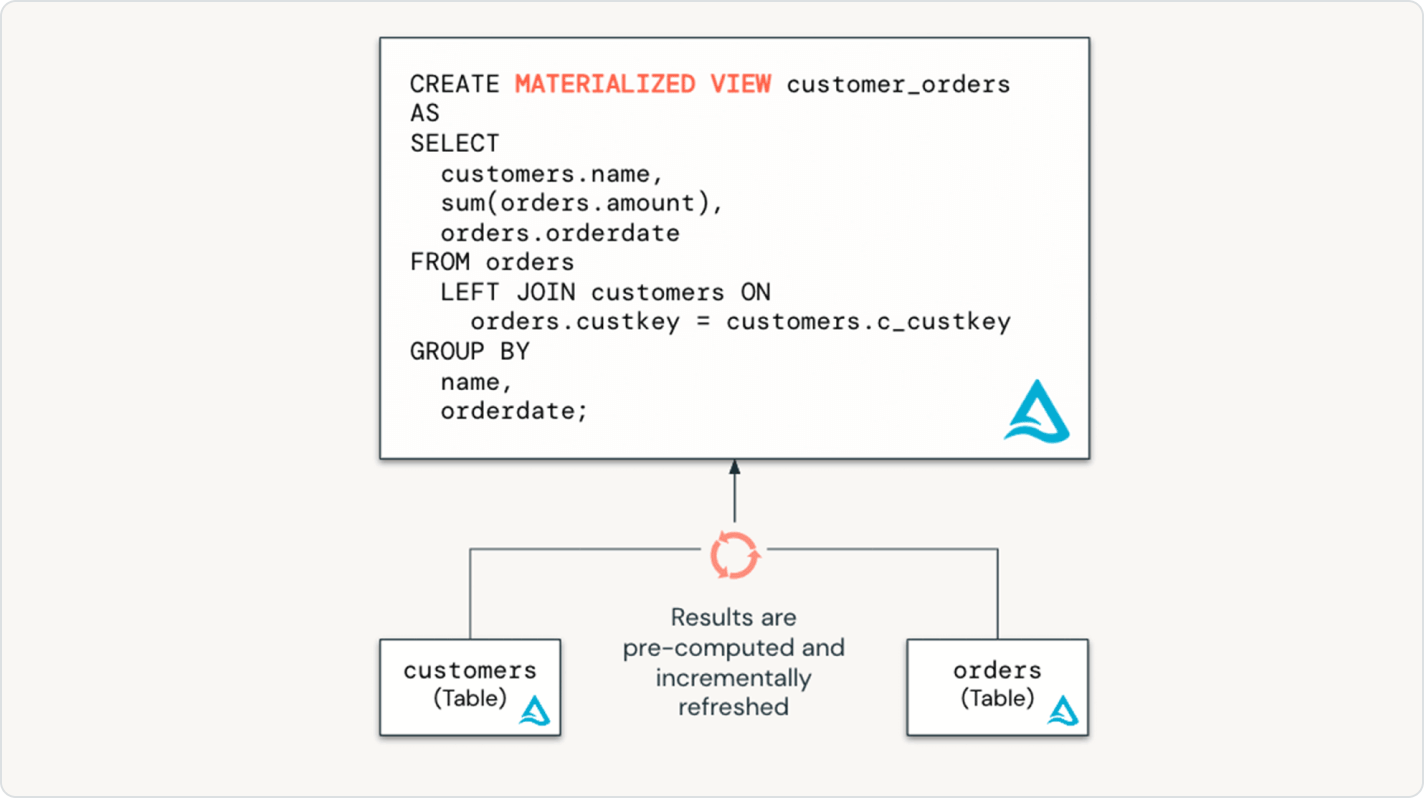
必要なデータ変換を単に宣言するだけで、Spark Declarative Pipelinesが残りの部分を処理します。効率的な取り込み
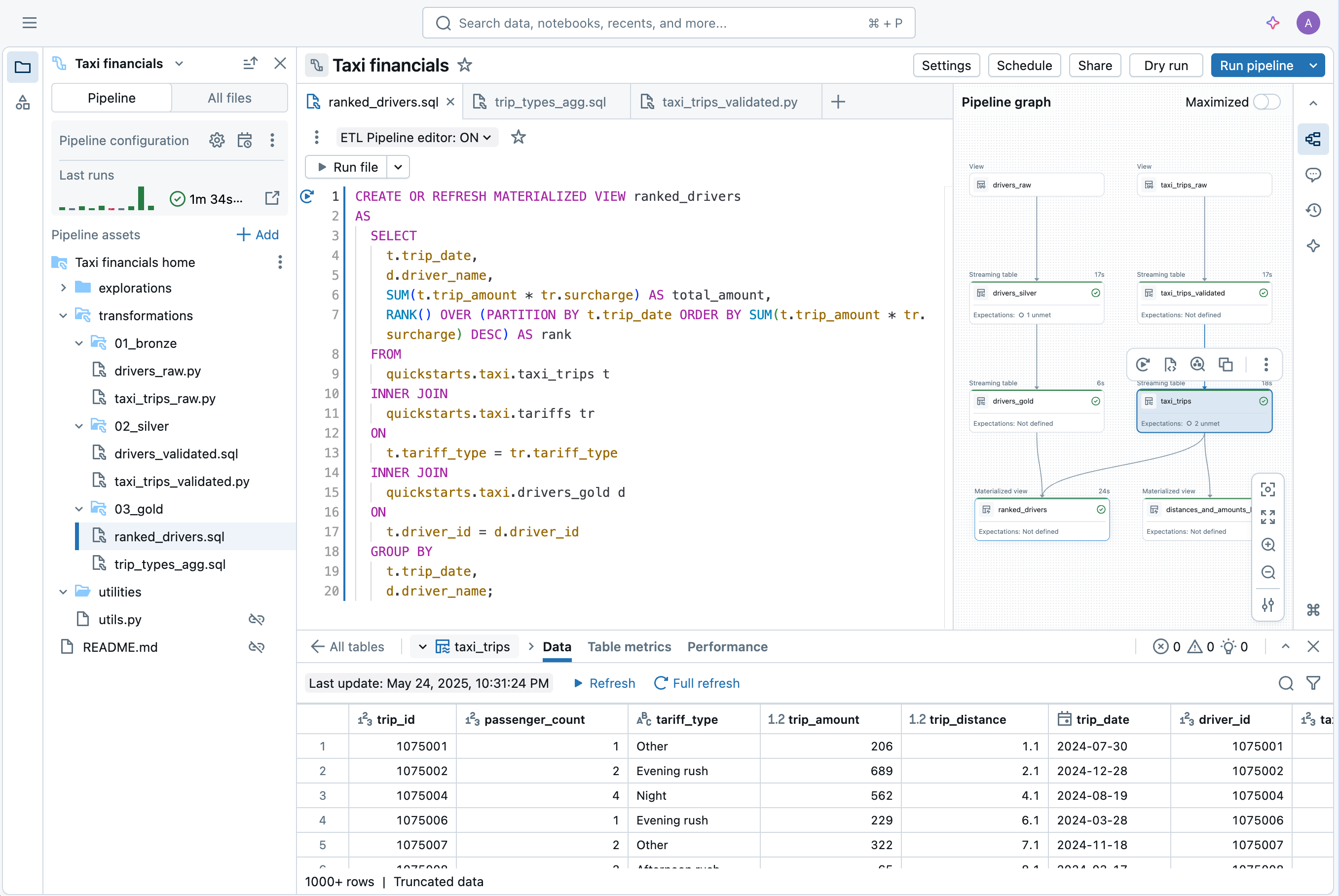
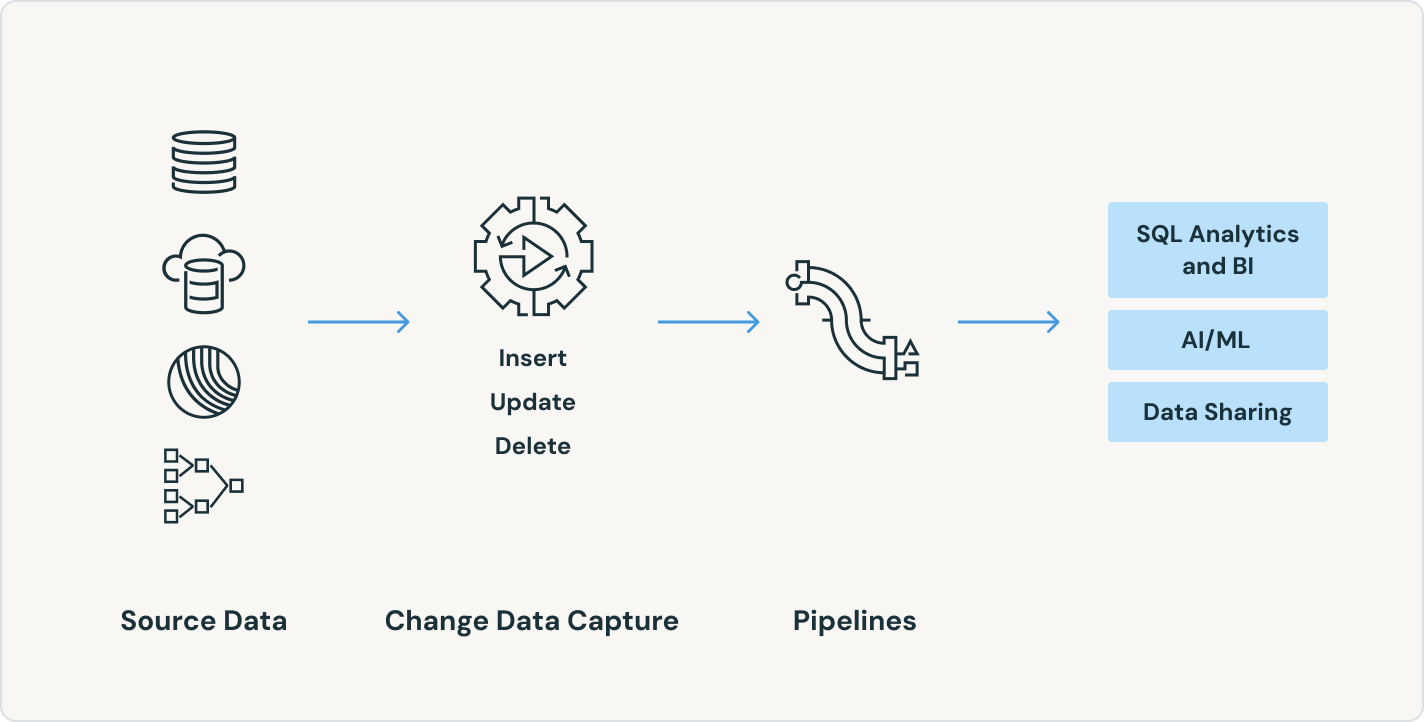
本番環境でのETLパイプラインの構築は、取り込みから始まります。Spark Declarative Pipelinesは、データエンジニア、Python開発者、データサイエンティスト、SQLアナリストのための効率的な取り込みを可能にします。DatabricksでApache Spark™がサポートする任意のソースからデータをロードします。バッチ、ストリーミング、またはCDCに関係なく。
インテリジェントな変換
たった数行のコードから、Spark Declarative Pipelinesはバッチまたはストリーミングデータパイプラインを構築し実行する最も効率的な方法を決定し、コストまたはパフォーマンスを自動的に最適化しながら複雑さを最小限に抑えます。
自動化された操作
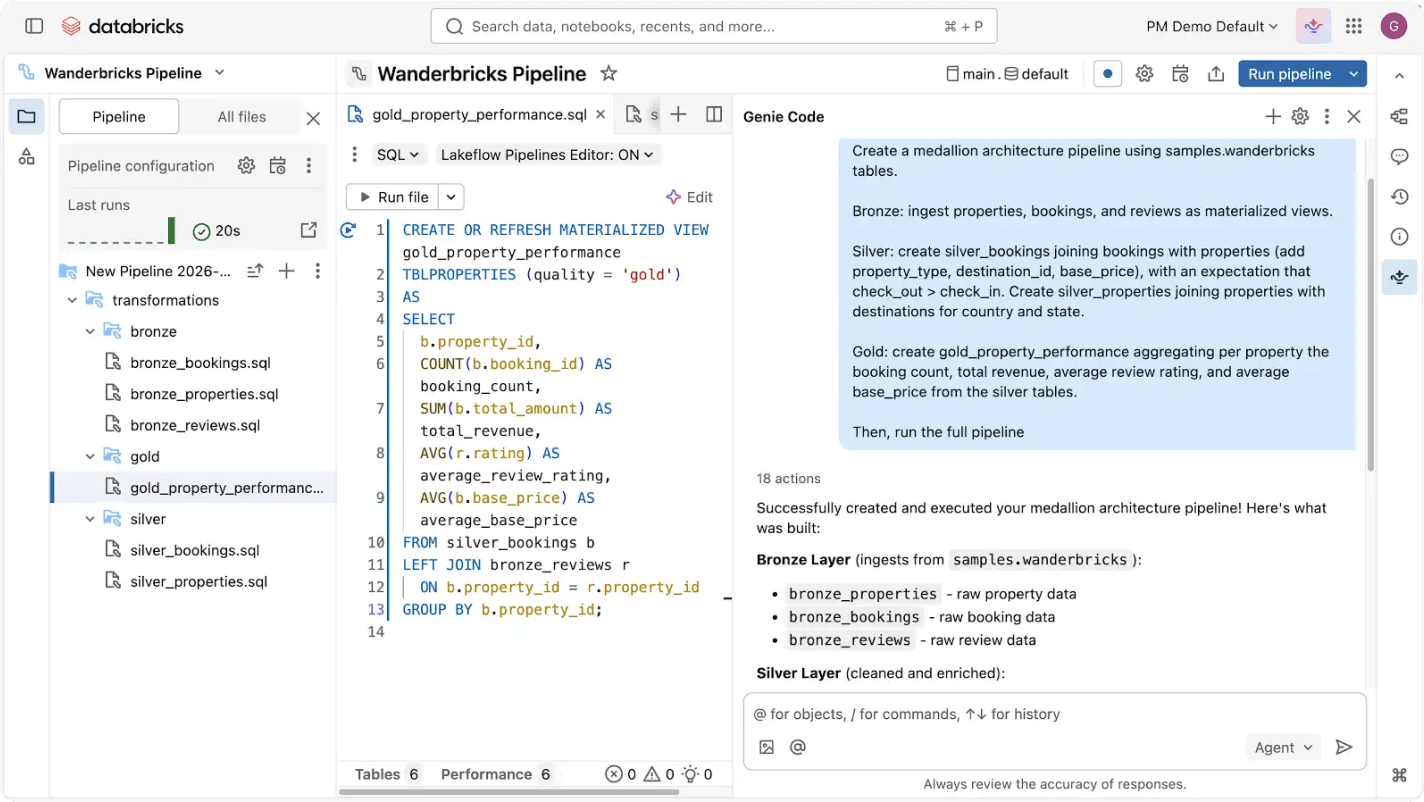
Spark Declarative Pipelinesは、ベストプラクティスをコード化し、運用上の複雑さを自動化することでETL開発を簡素化します。Spark Declarative Pipelinesを使用すると、エンジニアはパイプラインインフラの運用と保守ではなく、高品質なデータの提供に集中できます。
データパイプラインを簡素化するために構築
データパイプラインの構築と運用は難しいことがありますが、必ずしもそうである必要はありません。Spark Declarative Pipelinesは強力なシンプルさを備えて構築されているため、数行のコードだけで堅牢なETLを実行できます。
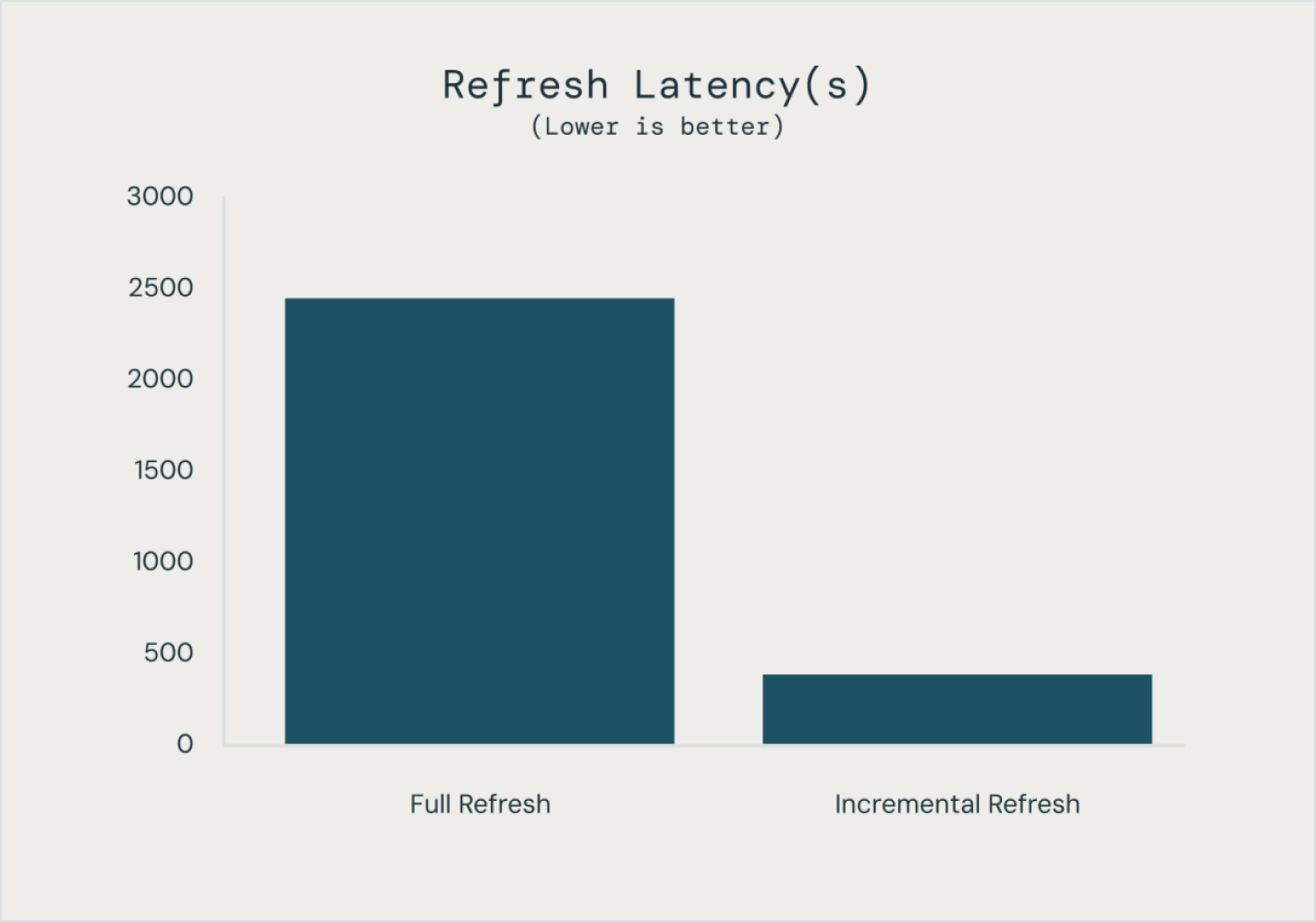
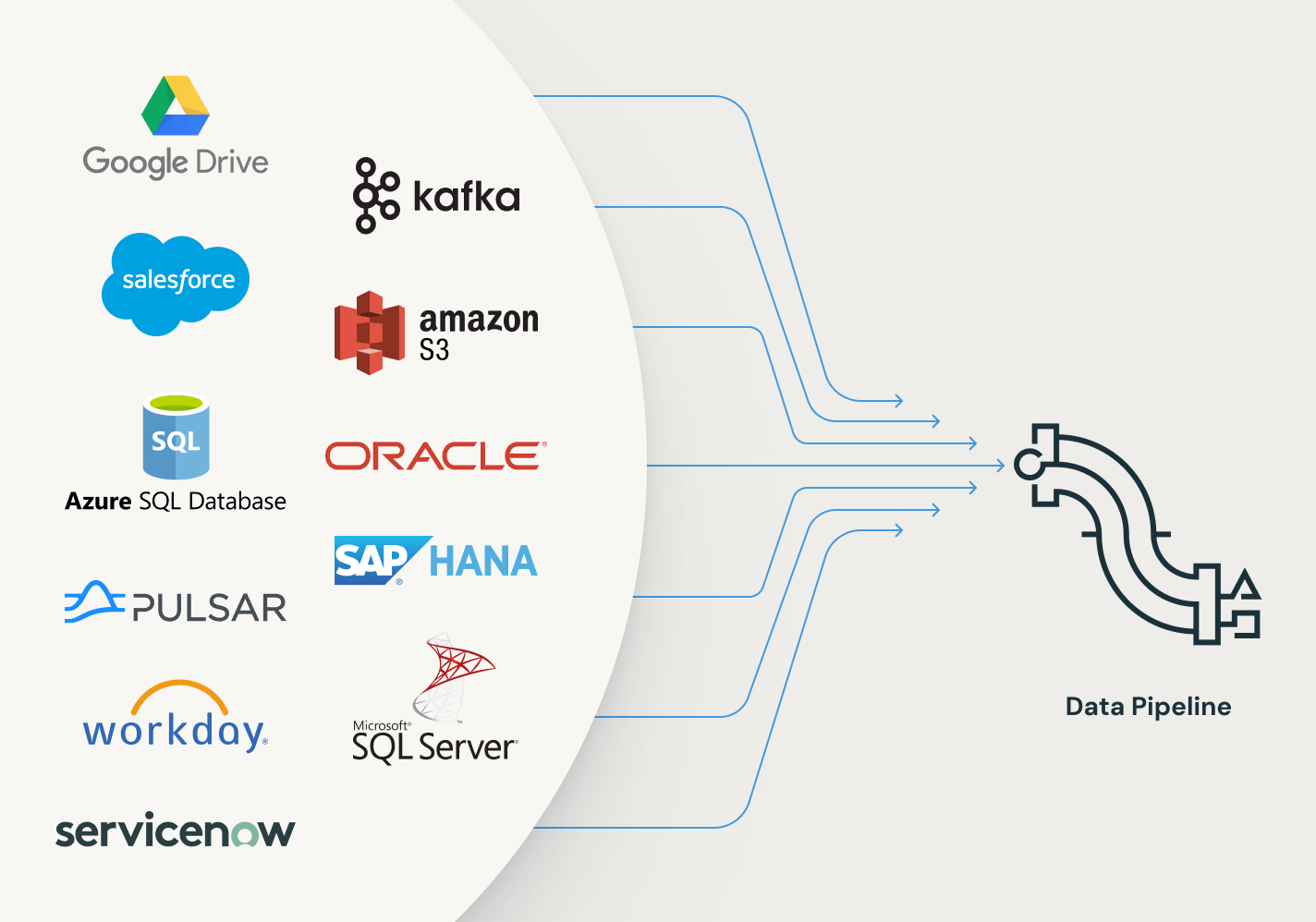
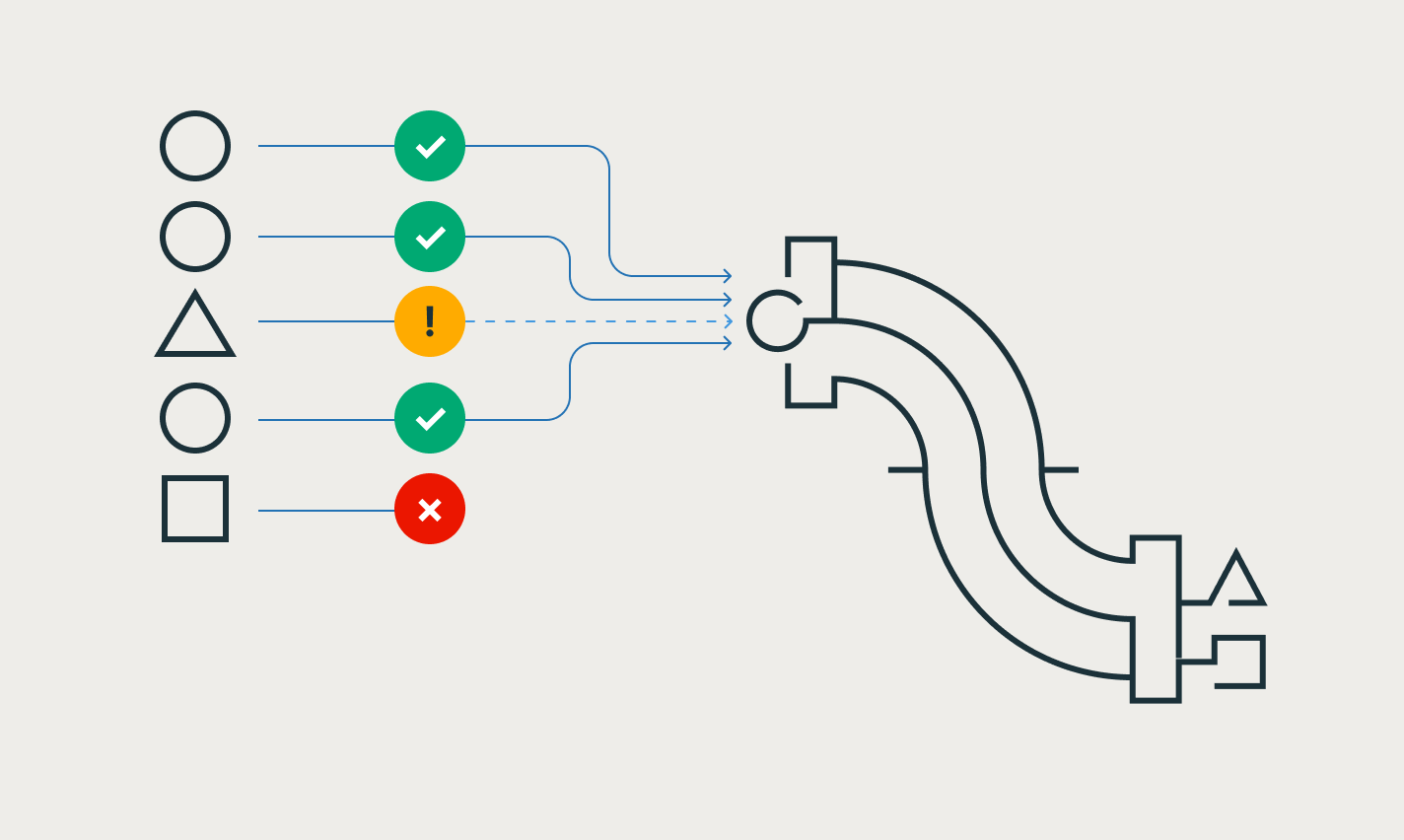
その他の機能
データパイプラインを効率化します

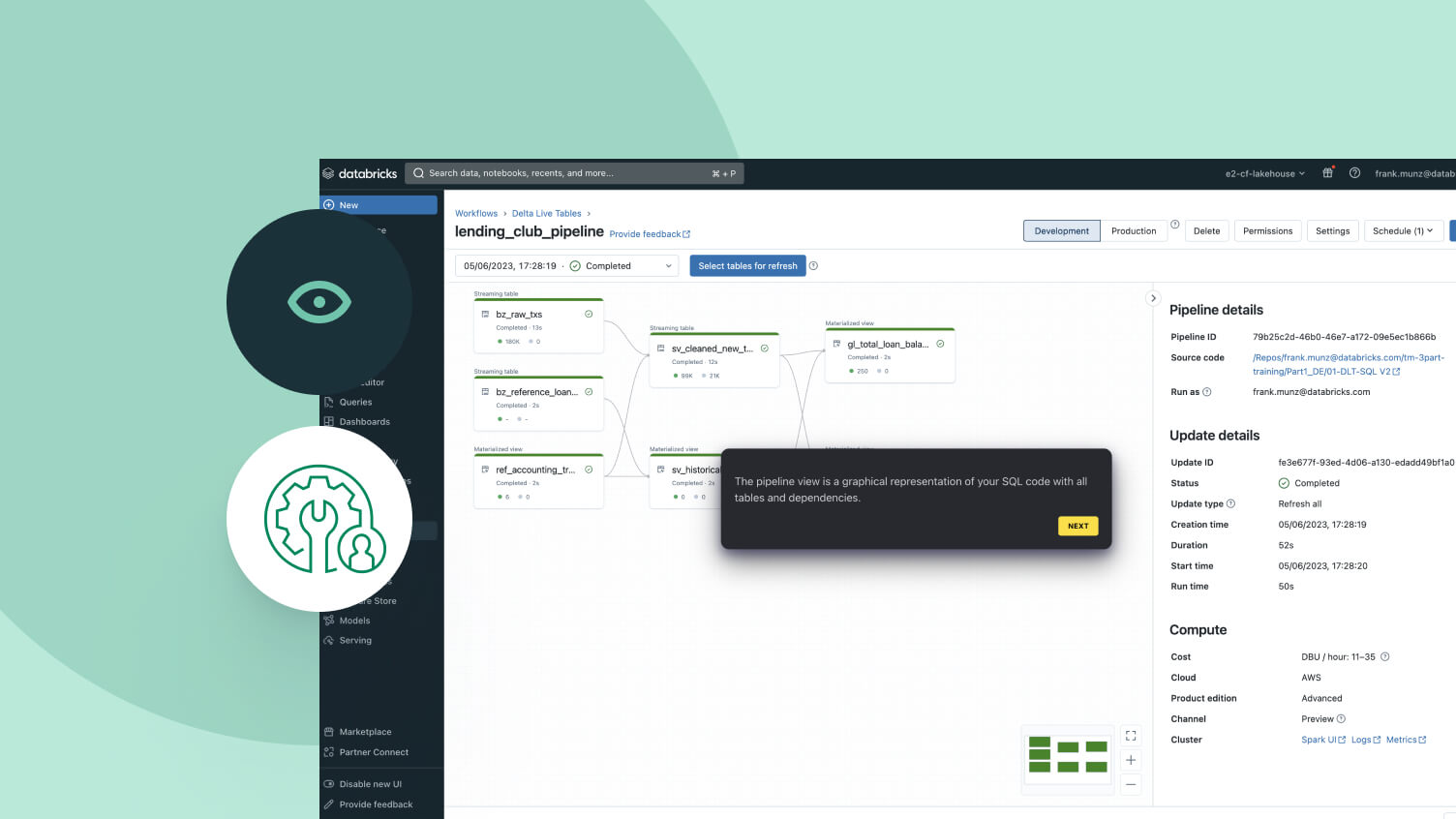
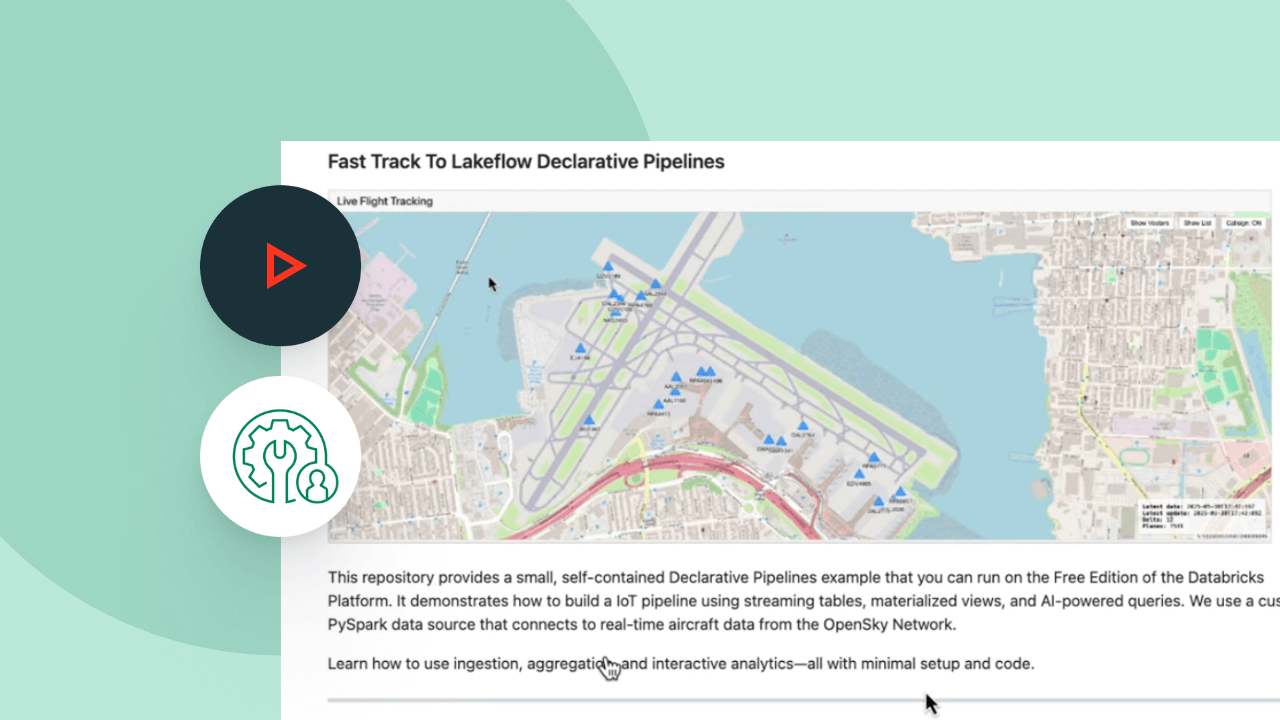
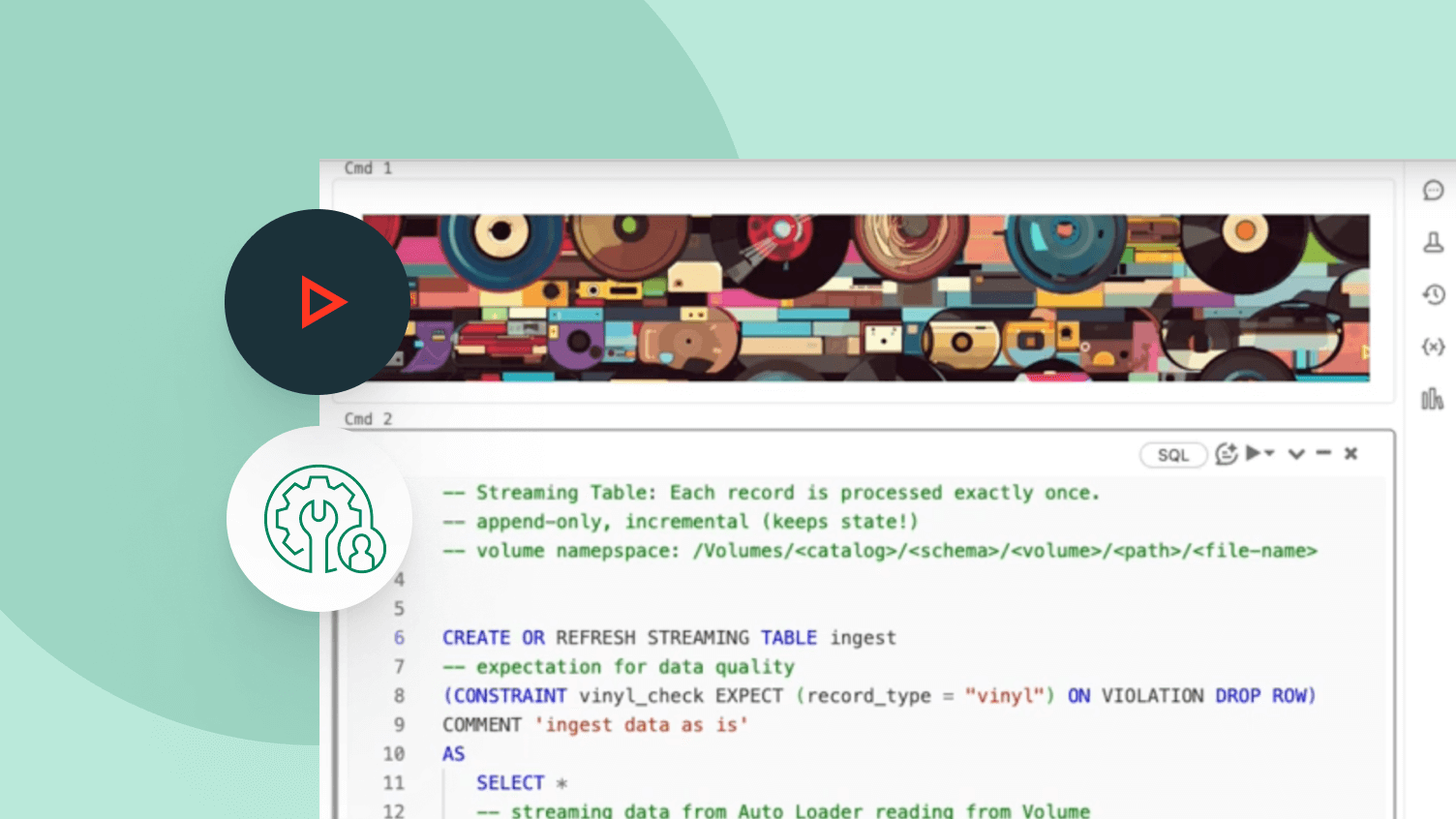
Spark Declarative Pipelinesのデモを探索します
使用量に応じた価格設定で、支出を抑制
使用した製品に対する秒単位での課金となります。さらに詳しく
Data Intelligence Platform上の他の統合された、インテリジェントなオファリングを探索してみてください。
LakeFlow Connect
任意のソースからの効率的なデータ取り込みコネクタとData Intelligence Platformとのネイティブな統合により、統一されたガバナンスを持つ分析とAIへの簡単なアクセスが可能になります。

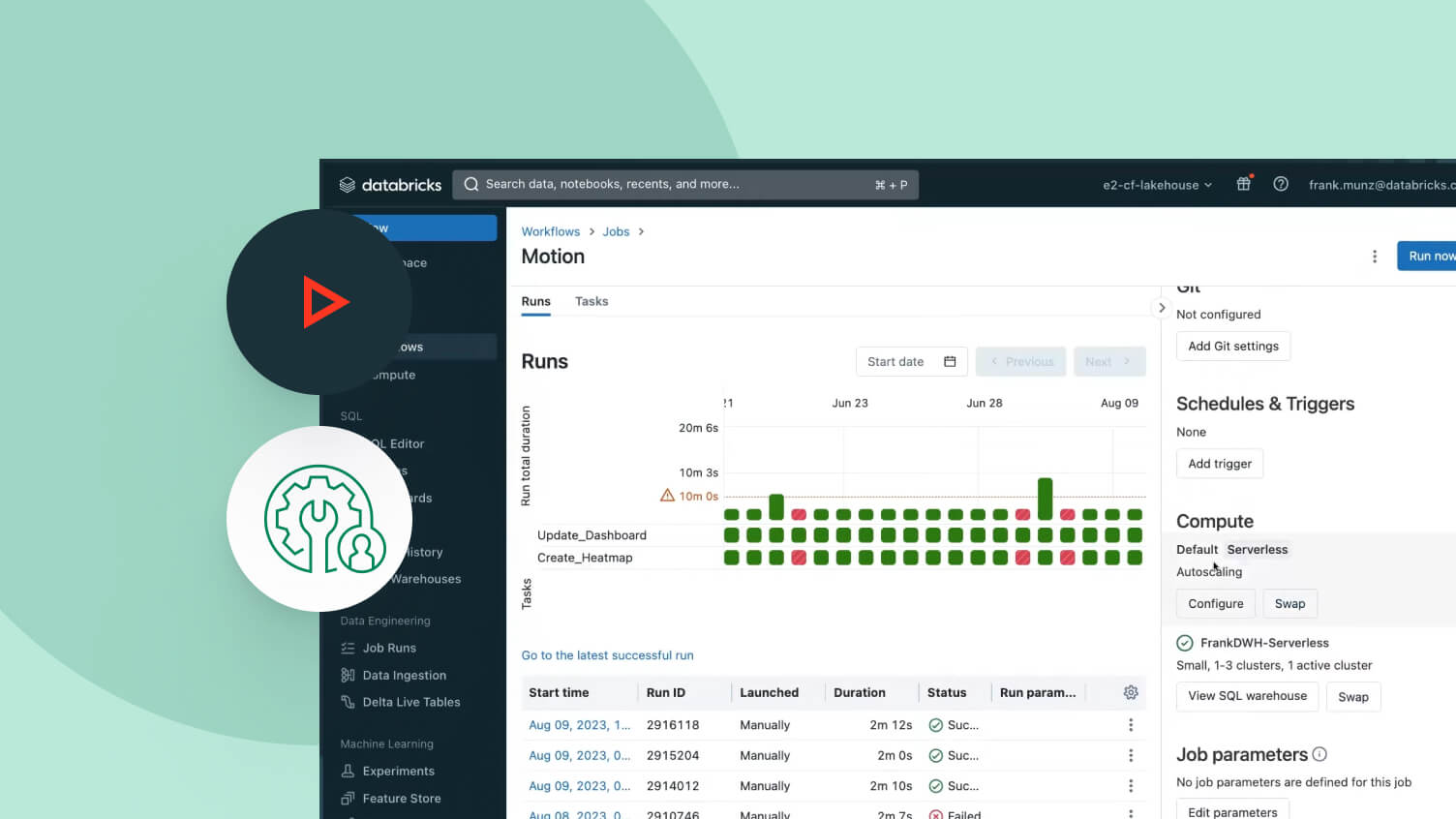
Lakeflowジョブ
ETL、分析、および機械学習パイプラインのマルチタスクワークフローを簡単に定義、管理、監視します。サポートされるタスクタイプの幅広い範囲、深い観察能力、高い信頼性により、データチームは任意のパイプラインをより効果的に自動化し、調整することができ、生産性を向上させることができます。
Lakeflowジョブ
ETL、分析、および機械学習パイプラインのマルチタスクワークフローを簡単に定義、管理、監視します。サポートされるタスクタイプの幅広い範囲、深い観察能力、高い信頼性により、データチームは任意のパイプラインをより効果的に自動化し、調整することができ、生産性を向上させることができます。

レイクハウスストレージ
あなたのレイクハウス内のデータを統一し、すべての形式とタイプを通じて、あなたの分析とAIワークロードのために。

Unity Catalog
業界唯一の統一されたオープンなガバナンスソリューションであるDatabricks Data Intelligence Platformに組み込まれた、データとAIのガバナンスをシームレスに行います。
データインテリジェンスプラットフォーム
Databricks データ・インテリジェンス・プラットフォームは、さまざまなデータ・AI のワークロードを支援しています。詳しい内容は、下記のページをご覧ください。



