LAKEFLOWを使用しているトップ企業
高品質なデータを提供するためのエンドツーエンドのソリューション。
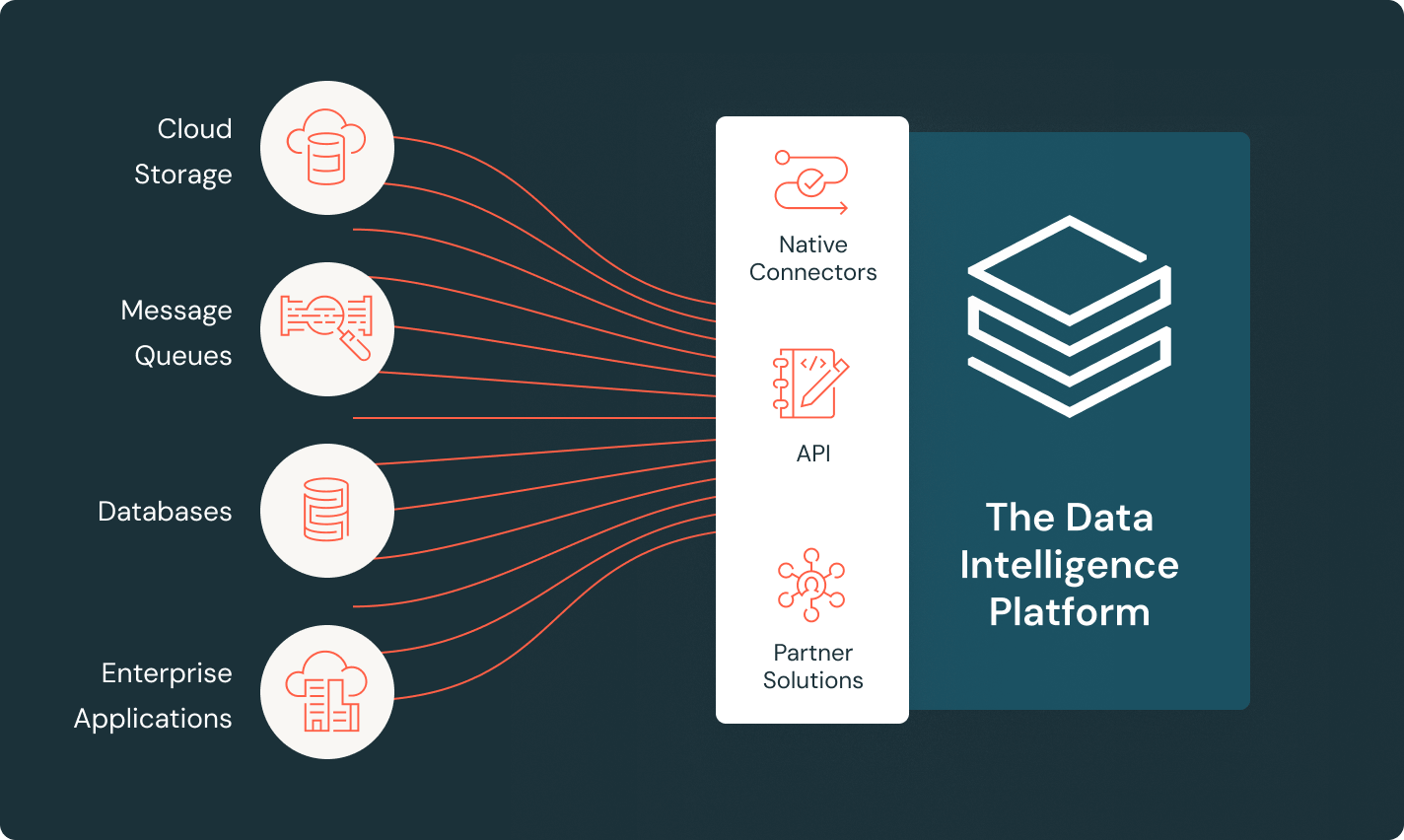
すべてのチームが信頼性の高いデータパイプラインを構築するのを容易にするツール統一されたツールスタック
すべてのデータを収集し、クリーニングするための一元化されたソリューションでコストと統合オーバーヘッドを削減します。組み込みの統一されたガバナンスと系統を持つことでコントロールを保ちます。
ストリームライン化されたETL開発
ノーコードのデータコネクタ、宣言的な変換、AI支援のコード作成を使用して、すべてのチームがより早く構築できるようにします。
効率的なデータ処理
パワフルなエンジンがリソース使用を自動最適化し、バッチと低遅延のリアルタイムの両方のユースケースでより良い価格/パフォーマンスを実現します。
データエンジニアのための統一ツール

LakeFlow Connect
効率的なデータ取り込みコネクタとData Intelligence Platformとのネイティブ統合により、統一されたガバナンスとともに分析とAIへの簡単なアクセスが可能になります。

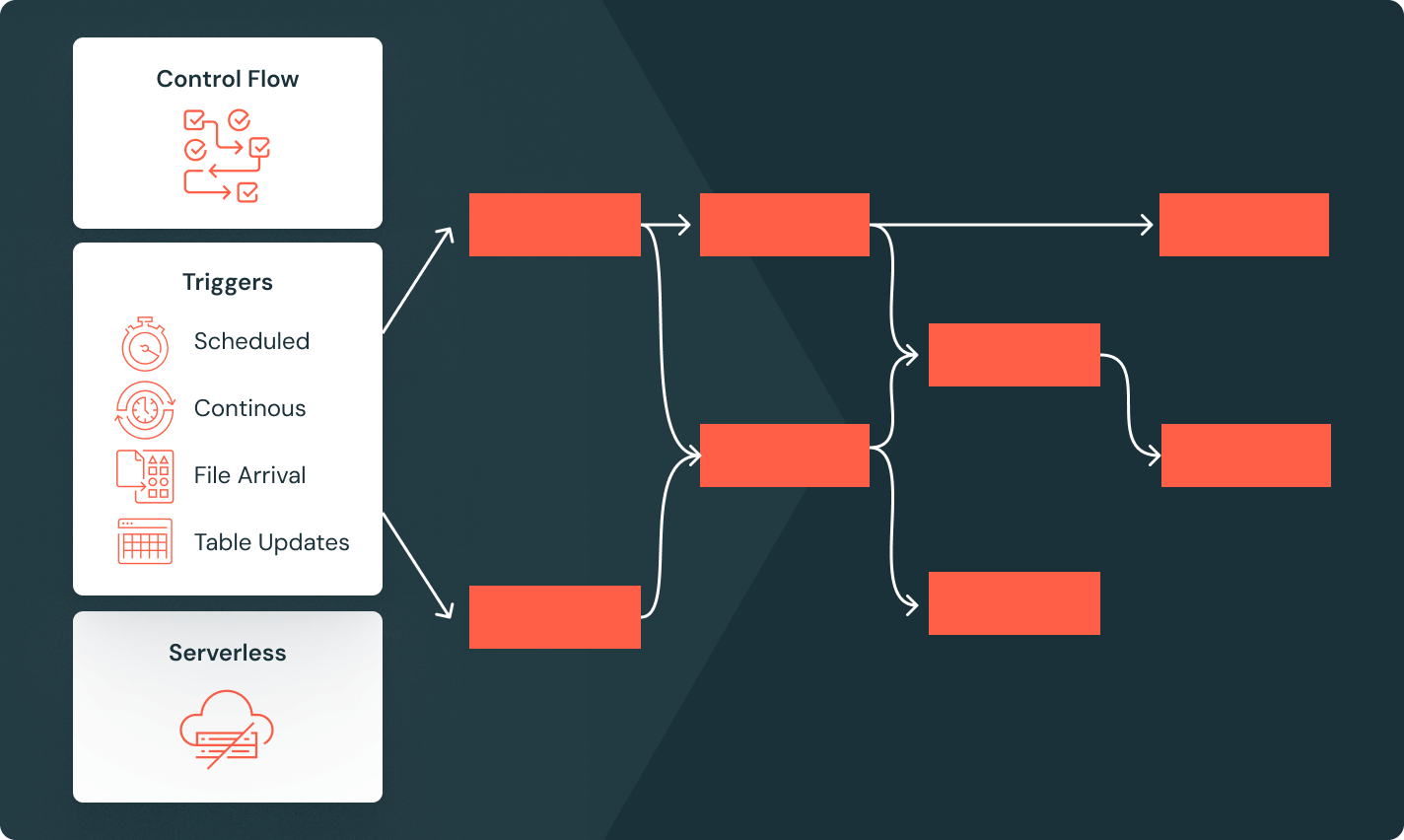
Spark Declarative Pipelines
自動化されたデータ品質、変更データキャプチャ(CDC)、データ取り込み、変換、統�一ガバナンスを用いてバッチおよびストリーミングETLを簡素化します。

Lakeflowジョブ
チームが深い観察可能性、高い信頼性、広範なタスクタイプのサポートを持つ任意のETL、分析、AIワークフローをより良く自動化し、調整するための装備を提供します。

Unity Catalog
業界唯一の統一されたオープンなガバナンスソリューションであるDatabricks Data Intelligence Platformに組み込まれた、データとAIのガバナンスをシームレスに行います。

レイクハウスストレージ
あなたのレイクハウス内のデータを統一し、すべての形式とタイプを通じて、あなたの分析とAIワークロードのために。
データインテリジェンスプラットフォーム
Databricks データ・インテリジェンス・プラットフォームで利用可能なあらゆるツールを活用し、組織全体のデータと AI をシームレスに統合できます。
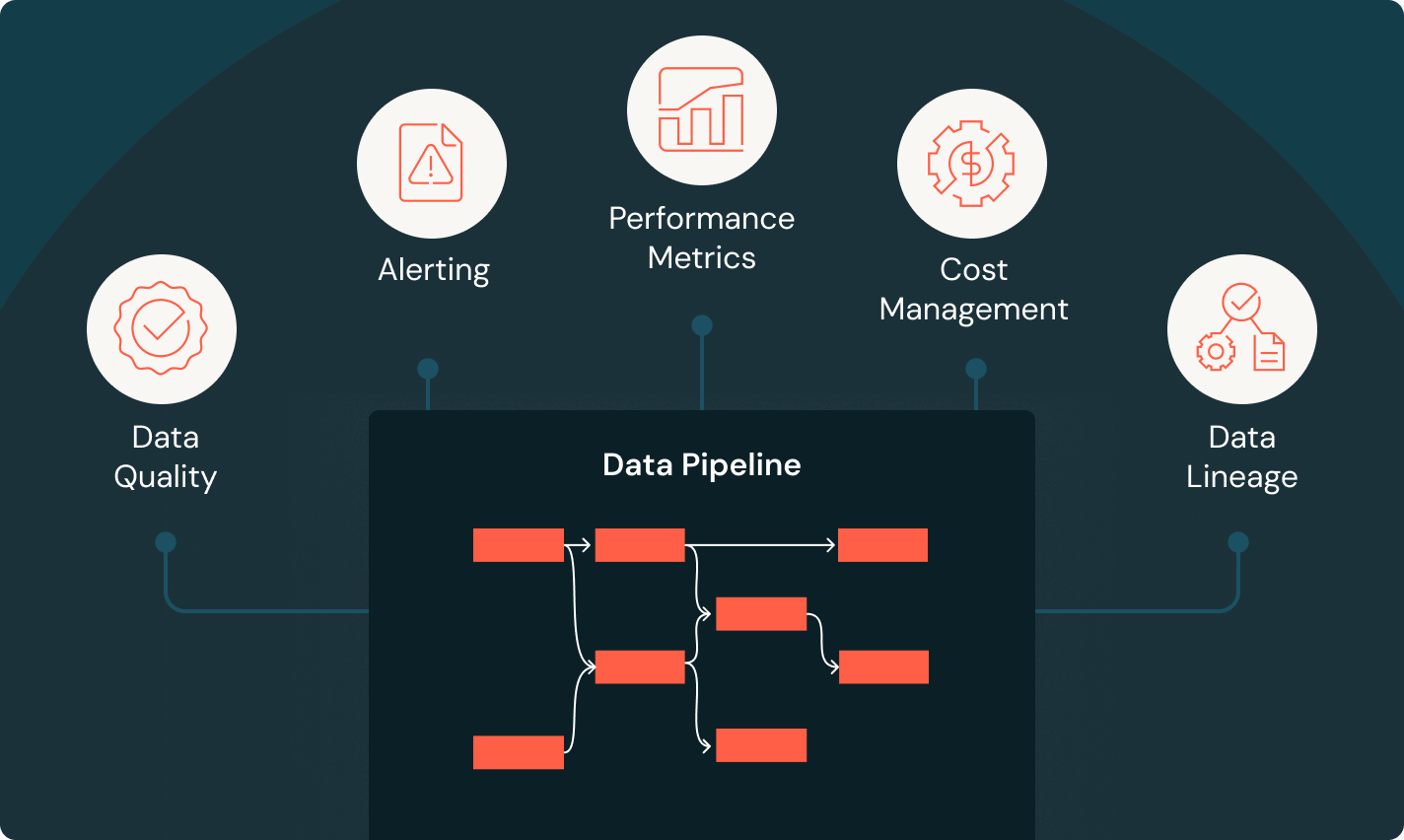
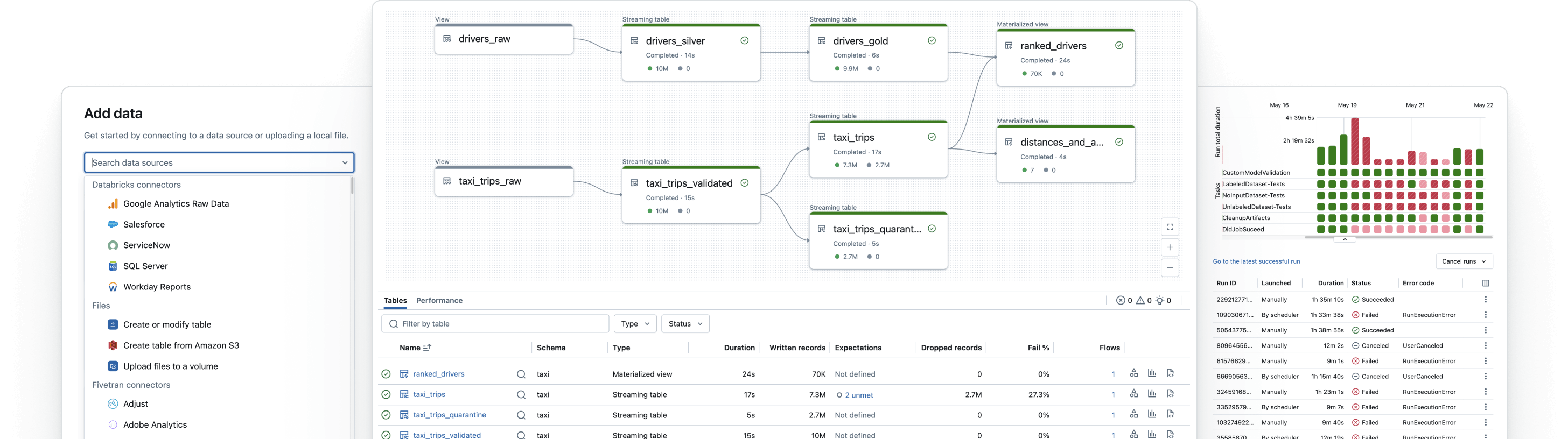
信頼性の高いデータパイプラインを構築します

生のデータを高品質のゴールドテーブルに変換します
ETLパイプラインを実装してデータをフィルタリング、豊かにし、クリーニングし、集約して分析、AI、BIの準備をし��ます。メダリオンアーキテクチャを追って、ブロンズからシルバー、ゴールドテーブルへのデータ処理を行います。