機械学習ライフサイクルの簡素化
オープンな統合プラットフォームで組織や技術のサイロを解消し、優れたデータと機械学習ライフサイクルを実現

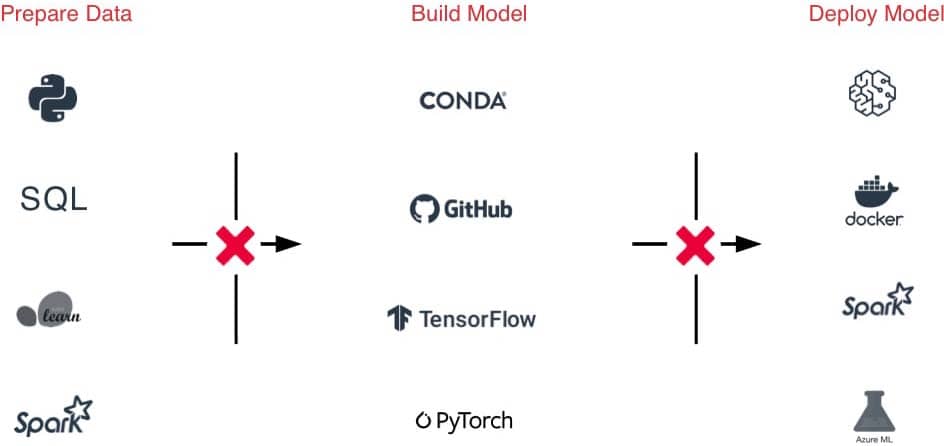
機械学習モデルの構築は容易ではありません。実運用への移行はさらに困難です。データの品質やモデルの精度の長期的な維持は、挙げられる課題のほんの一例に過ぎません。Databricks は、データ準備、モデルトレーニング、デプロイメントなど、機械学習の開発を独自の方法で大規模に効率化します。
課題
ML フレームワークの種類が多すぎる:ML 環境の管理を難しくしている。
ハンドオフが困難:データ準備から実験、本番まで、ツールやプロセスがバラバラであるため、チーム間のハンドオフが困難。
追跡が困難:実験、モデル、依存関係、アーティファクトの追跡が困難で、結果の再現ができない。
セキュリティとコンプライアンスの要件を満たすのが困難。
ソリューション
ワンクリックのアクセス:ライフサイクル全体にわたって、すぐに利用でき、最適化され、スケーラブルな ML 環境に容易にアクセス可能。
単一プラットフォーム:データインジェスト、フィーチャライゼーション、モデル構築、チューニング、プロダクション化を単一のプラットフォームで実行できるため、ハンドオフが簡素化。
追跡の自動化:実験、コード、結果、成果物を自動的に追跡し、モデルを一元管理。
コンプライアンス要件に対応:招請に設定されたアクセス制御、データ系列、バージョン管理により、コンプライアンス要件を満たす。
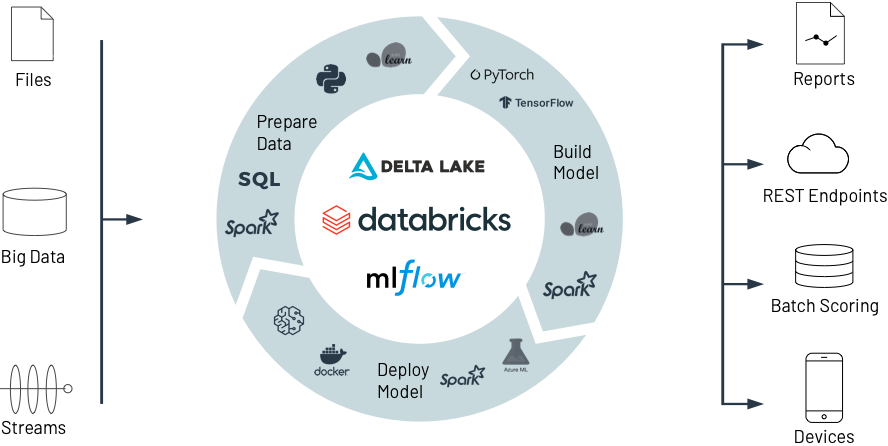
機械学習のための Databricks
Databricks がどのように共同作業でデータを準備し、最先端の ML モデルを構築、デプロイ、管理し、実験から本番まで、かつてない規模で支援するかをご覧ください。
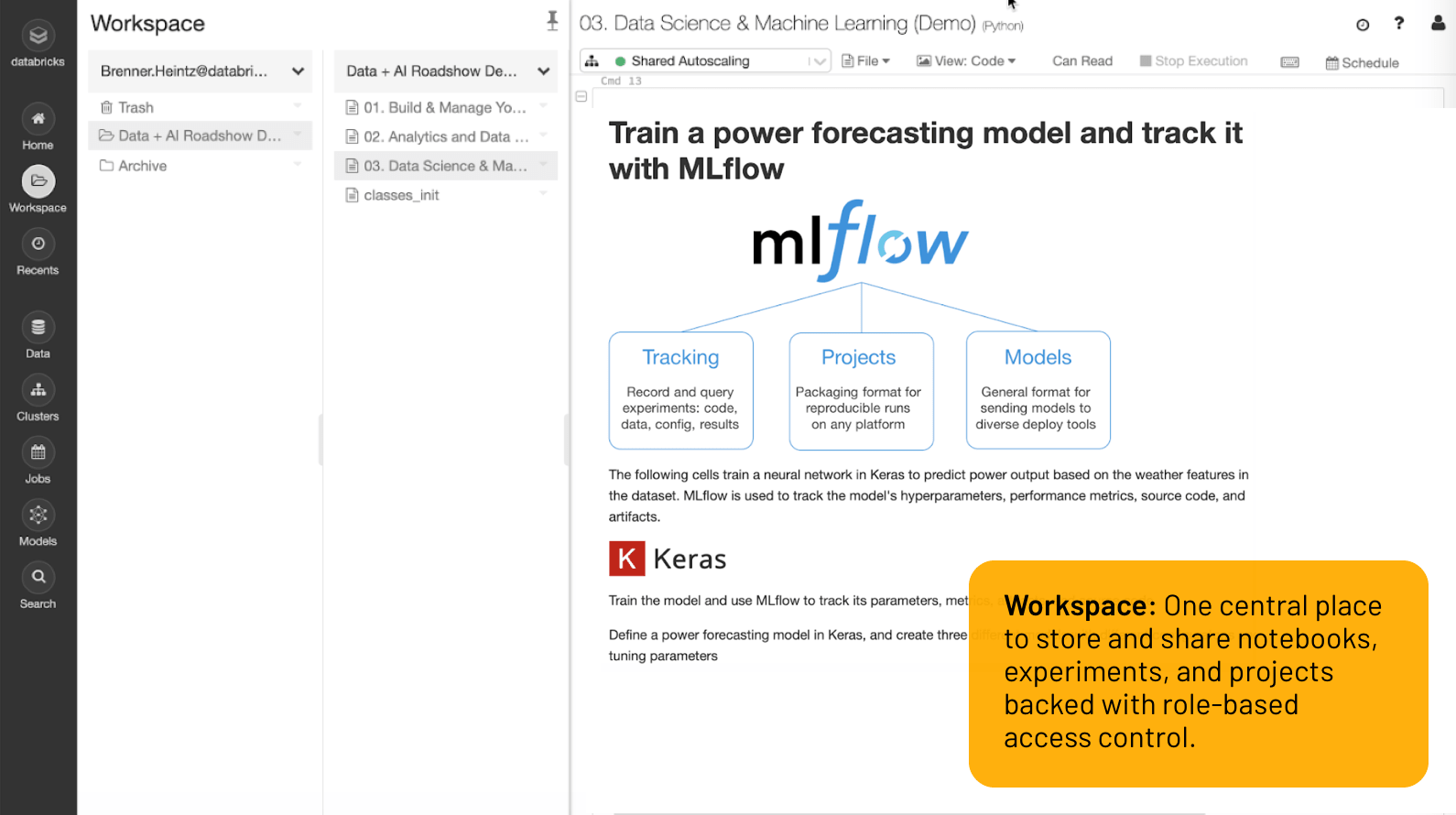
ワークスペース
Notebook 、実験、プロジェクトを保存・共有するための一元的な場所で、役割ベースのアクセス制御が可能。
機械学習の実験から実運用までを大規模に実現
クラス最高の開発環境
データセット、ML環境、Notebook 、ファイル、実験、モデルなど、仕事をこなすために必要なものが全て1か所に集約されており、ワンクリックで安全に利用できます。
多言語(Python、R、Scala、SQL)をサポートするコラボレーションK可能なNotebookが、共同オーサリング、Git 統合、バージョン管理、ロールベースのアクセス制御など、チームとしての作業を容易にします。また、Jupyter Lab、PyCharm、IntelliJ、RStudio のような使い慣れたツールをDatabricks と一緒に使うだけで、無限のデータストレージとコンピューティングの恩恵を受けることができます。
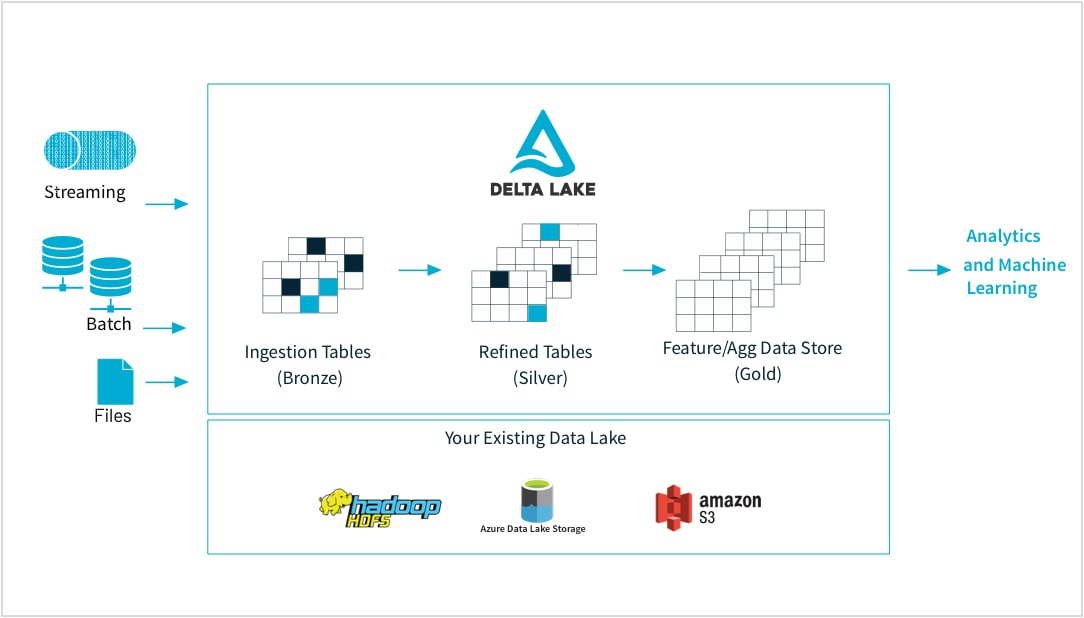
未加工データを高品質な特徴ストアに
機械学習の専門家は、多様な形式のデータを使用してモデルをトレーニングします。大/小規模のデータセット、DataFrame、テキスト、画像、バッチ、ストリーミングなど、これらのデータは、いずれも特定のパイプラインと変換を必要とします。
Databricks は、あらゆるソースからの未加工データの取り込み、バッチおよびストリーミングデータの統合、変換のスケジューリング、テーブルのバージョン管理、品質チェックの実行を可能にし、データを優れた状態にして、組織の他部門がすぐに分析に利用できるようにします。これにより、CSV ファイル、大規模なデータレイクの取り込みなど、ニーズに応じたあらゆるデータのシームレスかつ確実な作業が可能になります。

scikit-learn、TensorFlow、PyTorch などを実行するのに最適な場所...
MLフレームワークは急激に進化しており、IT 、ML 環境を維持することが難しくなっています。Databricks の機械学習ランタイムは、最も一般的な ML フレームワーク(scikit-learn、TensorFlow など)と Conda サポートを含む、すぐに使えて最適化された ML 環境を提供します。
ハイパーパラメータチューニングなどのビルトイン AutoML により、結果をより早く取得できます。また、簡素化されたスケーリングにより、スモールデータからビッグデータへの移行が容易になり、利用可能なコンピューティング量に制限されなくなります。例えば、HorovodRunner を使用してクラスタ全体にコンピューティングを分散させることで深層学習モデルのトレーニングを高速化し、CUDA に最適化されたバージョンの TensorFlow を実行することでクラスタ内の各 GPU からより多くの性能を引き出すことができます。
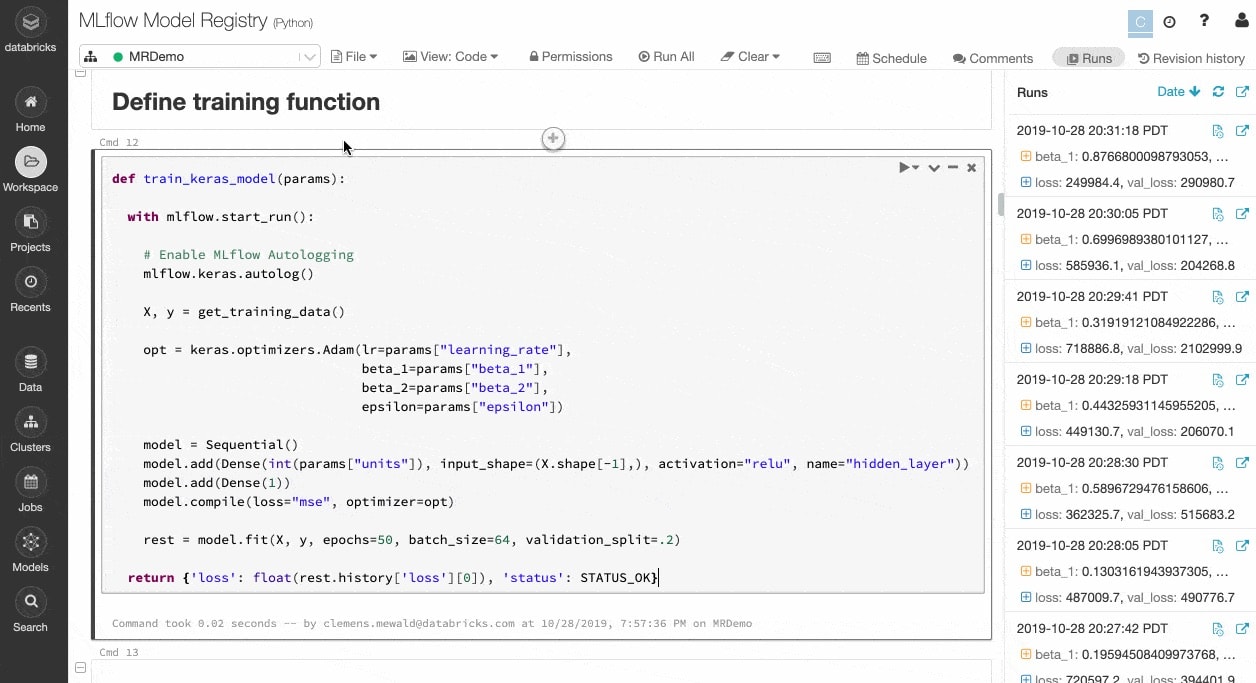
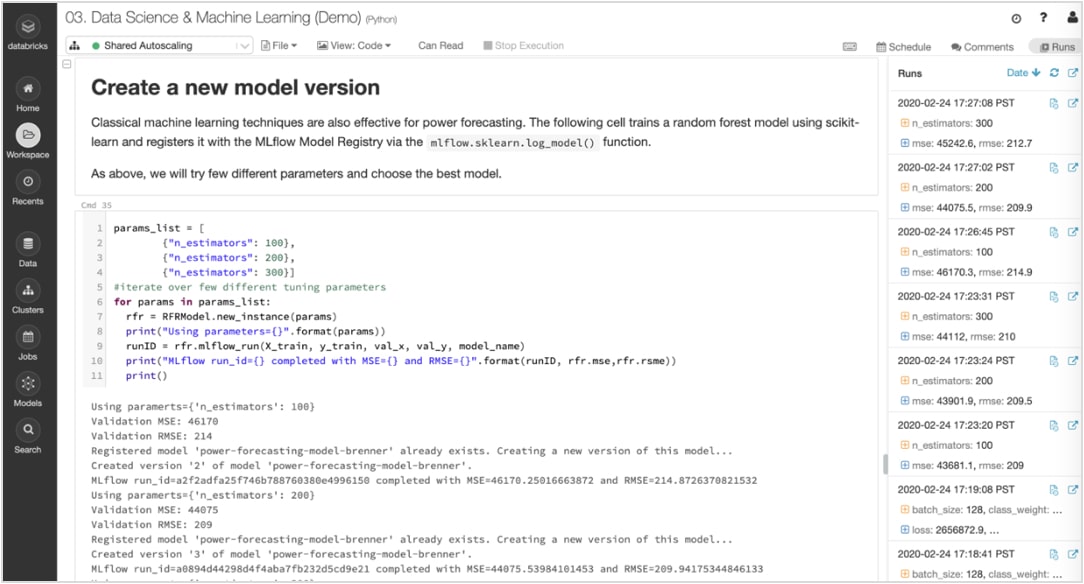
実験と成果物を追跡し、後で再現できるようにする。
機械学習アルゴリズムには多数の設定可能なパラメータがあります。個人作業、チーム作業、どちらの場合においても、モデル生成のために各実験に使用したパラメータ、コード、データを追跡することは困難です。
MLflow は、Notebook 内から各トレーニング実行のデータ、コード、パラメータ、結果などの成果物とともに実験を自動的に追跡します。そのため、過去の実行結果を一目で確認したり、結果を比較したり、必要に応じて以前のバージョンのコードに戻したりすることができます。本番環境に最適なモデルのバージョンを特定した後は、中央のリポジトリに登録し、デプロイメントのために送信し、ハンドオフを簡素化します。
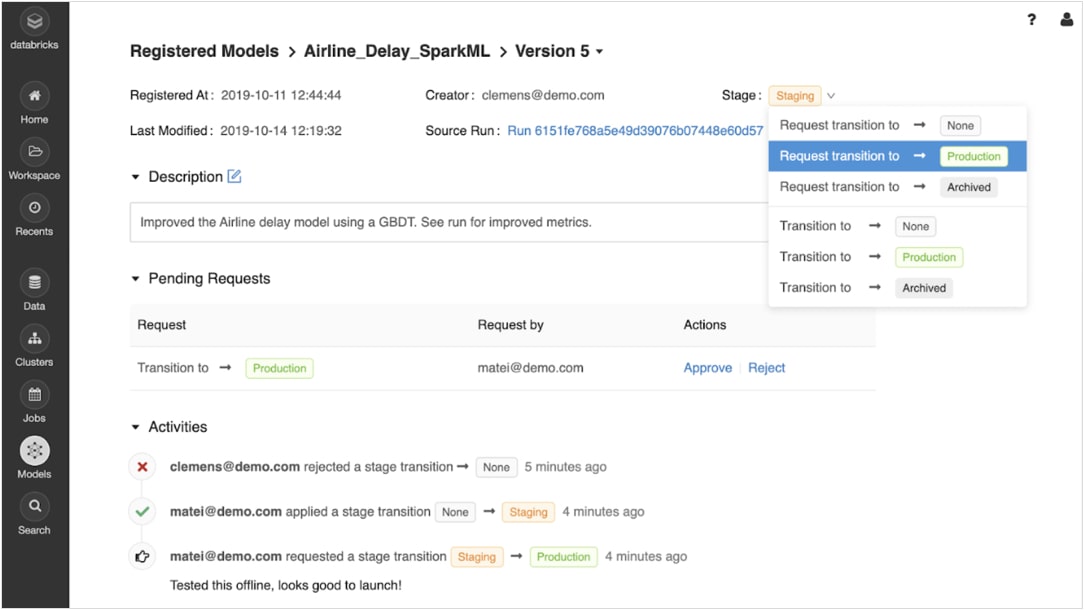
プロトタイプから実運用への移行を確実に実行
トレーニングされたモデルを登録すると、MLflow のモデルレジストリを使用してモデルのライフサイクルを共同管理できます。
モデルのバージョン管理や移動は、実験、ステージング、本番環境、アーカイブなどさまざまな段階で可能です。ステークホルダーは、コメントやリクエストを送信し、ステージ変更ができます。ライフサイクル管理は、承認やガバナンスのワークフロー、ロールベースのアクセス制御と統合されています。
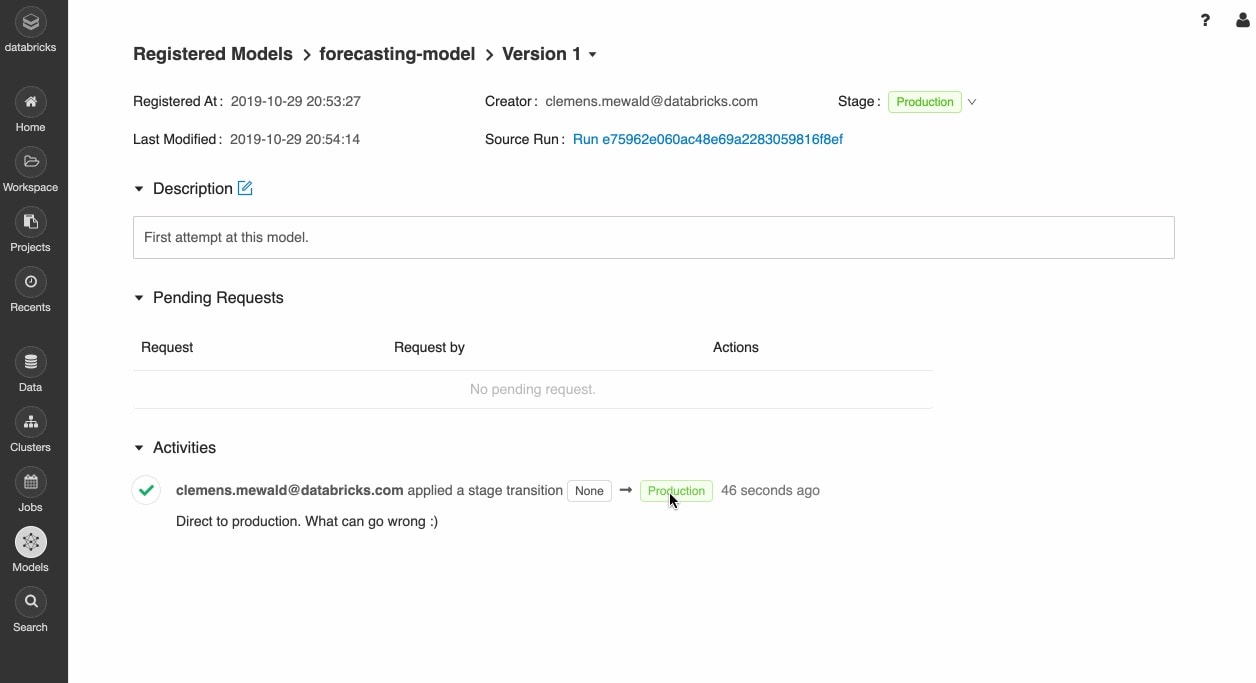
あらゆる場所でのモデル展開
本番モデルは、Apache Spark™ でバッチ推論を実行するために、または Docker コンテナ、Azure ML、Amazon SageMaker に統合されている組み込み機能を使用する REST API として、迅速にデプロイできます。
ジョブスケジューラや自動管理クラスタを利用した本稼働モデルを運用し、ビジネスニーズに応じてスケーリングします。
Delta Lake と MLflow を使用して、最新バージョンのモデルを本番環境に迅速にプッシュし、モデルのドリフトを監視することができます。
リソース
レポート

eBook

eBook

Ready to get started?