동적 시간 워핑 및 MLflow를 사용하여 검색 판매 / 영업 동향

Databricks에서 이 노트북 시리즈(DBC 형식)를 사용해 보세요.
이 블로그는 동적 시간 워핑 및 MLflow를 사용하여 판매/영업 추세 감지 2부작 시리즈의 2부입니다.
"다이나믹 타임 워핑"이라는 문구는 처음 읽었을 때 백 투 더 퓨처 시리즈에서 Marty McFly가 DeLorean을 시속 88마일로 운전하는 이미지를 연상시킬 수 있습니다. 안타깝게도 동적 시간 왜곡에는 시간 이동이 포함되지 않습니다. 대신 비교 데이터 포인트 간의 시간 인덱스가 완벽하게 동기화되지 않을 때 시계열 데이터를 동적으로 비교하는 데 사용되는 기술입니다.
아래에서 살펴보겠지만 동적 시간 왜곡의 가장 두드러진 용도 중 하나는 음성 인식으로, 한 구문이 비교보다 빠르거나 느리더라도 한 구문이 다른 구문과 일치하는지 여부를 결정합니다. 이것이 Google Home 또는 Amazon Alexa 장치를 활성화하는 데 사용되는 "깨우기 단어"를 식별하는 데 유용하다고 상상할 수 있습니다 �– 아직 매일 커피 한 잔을 마시지 않았기 때문에 말이 느린 경우에도 마찬가지입니다.
동적 시간 워핑은 다양한 도메인에 적용할 수 있는 유용하고 강력한 기술입니다. 동적 시간 왜곡의 개념을 이해하면 일상 생활에서의 적용 사례와 흥미로운 미래 응용 프로그램을 쉽게 볼 수 있습니다. 다음 용도를 고려하십시오.
- 금융 시장 – 비슷한 기간의 주식 거래 데이터가 완벽하게 일치하지 않더라도 비교합니다. 예를 들어 2월(28일)과 3월(31일)의 월별 거래 데이터를 비교합니다.
- 웨어러블 피트니스 트래커 – 시간이 지남에 따라 속도가 변하더라도 보행기의 속도와 걸음 수를 보다 정확하게 계산합니다.
- 경로 계산 – 운전자의 운전 습관에 대해 알고 있는 경우(예: 직선 도로에서는 빠르게 운전하지만 좌회전하는 데 평균보다 더 많은 시간이 걸리는 경우) 운전자의 ETA에 대한 보다 정확한 정보를 계산합니다.
데이터 사이언티스트, 데이터 애널리스트 및 시계열 데이터를 다루는 모든 사람은 완벽하게 정렬된 시계열 비교 데이터가 완벽하게 "깔끔한" 데이터만큼 드물 수 있다는 점을 감안할 때 이 기술에 익숙해져야 합니다.
이 블로그 시리즈에서는 다음을 살펴봅니다.
- 동적 시간 왜곡의 기본 원리
- 샘플 오디오 데이터에서 동적 시간 워핑 실행
- 샘플에서 동적 시간 워핑 실행 판매 / 영업 데이터 사용 MLflow
동적 시간 왜곡에 대한 자세한 내용은 이전 게시물 동적 시간 왜곡 이해를 참조하세요.
배경
3D 프린팅 제품을 만드는 �회사를 소유하고 있다고 상상해 보십시오. 작년에 드론 프로펠러가 매우 꾸준한 수요를 보이고 있다는 것을 알고 있었기 때문에 드론 프로펠러를 생산하고 판매했으며 그 전해에는 휴대폰 케이스를 판매했습니다. 새해가 곧 다가오고 있으며, 제조 팀과 함께 앉아서 회사가 내년에 무엇을 생산해야 하는지 파악하고 있습니다. 창고용 3D 프린터를 구입하면 빚을 많이 지게 되므로 프린터에 대한 지불을 위해 프린터가 항상 100% 용량 또는 거의 100% 용량으로 작동하는지 확인해야 합니다.
당신은 현명한 CEO이기 때문에 내년 동안 생산 능력이 썰물처럼 빠져나갈 것이라는 것을 알고 있습니다 - 생산 능력이 다른 주보다 높은 주가 있을 것입니다. 예를 들어, 여름철(계절 근로자를 고용할 때)에는 생산량이 더 높을 수 있고, 매월 3번째 주(3D 프린터 필라멘트 공급망 문제로 인해)에는 생산량이 더 낮을 수 있습니다. 아래 차트를 통해 귀사의 생산 능력 추정치를 확인하십시오.
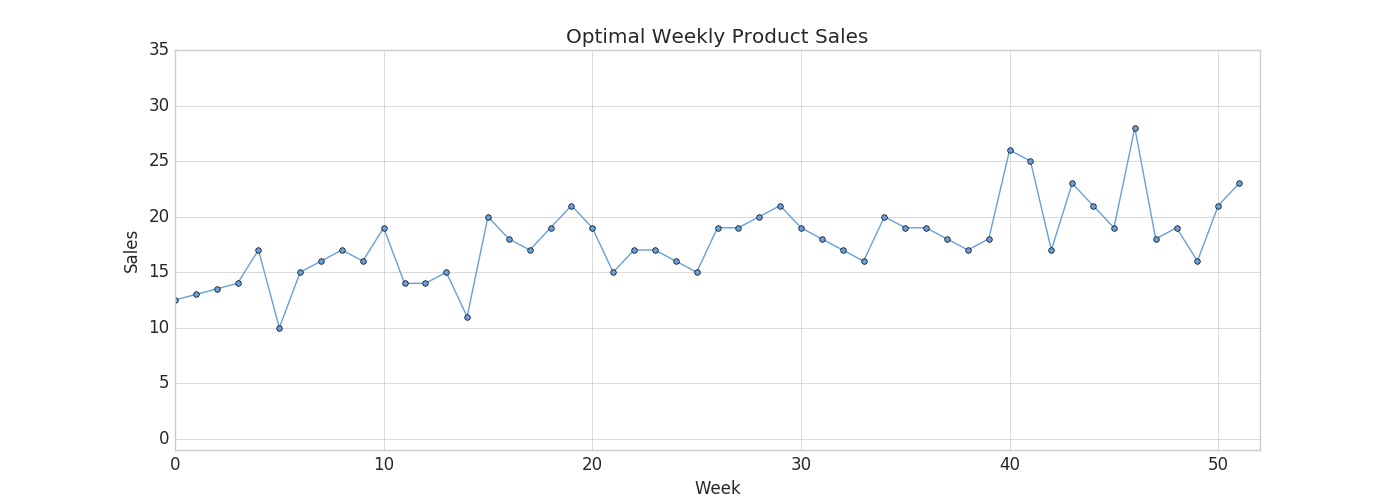
귀하의 작업은 주간 수요가 가능한 한 생산 능력에 가깝게 충족되는 제품을 선택하는 것입니다. 각 제품에 대한 작년의 판매/영업 번호가 포함된 제품 카탈로그를 살펴보고 있으며 올해의 판매/영업도 비슷할 것이라고 생각합니다.
주간 수요가 생산 능력을 초과하는 제품을 선택하면 고객 주문을 취소해야 하며 이는 비즈니스에 좋지 않습니다. 반면에 주간 수요가 충분하지 않은 제품을 선택하면 프린터를 최대 용량으로 계속 가동할 수 없으며 부채를 갚지 못할 수 있습니다.
동적 시간 왜곡이 여기서 작동하는 이유는 선택한 제품에 대한 수요와 공급이 약간 일치하지 않을 수 있기 때문입니다. 모든 수요를 충족시킬 수 있는 충분한 용량이 없는 몇 주가 있을 수 있지만, 매우 가깝고 전후 한두 주 동안 더 많은 제품을 생산하여 이를 만회할 수 있는 한 고객은 신경 쓰지 않을 것입니다. 유클리드 매칭(Euclidean Matching)을 사용하여 판매/판매 데이터와 생산 능력을 비교하는 것으로 제한하면 이를 고려하지 않은 제품을 선택하고 테이블에 돈을 남겨둘 수 있습니다. 대신 동적 시간 왜곡을 사용하여 올해 귀사에 적합한 제품을 선택합니다.
제품 판매 / 영업 데이터 세트 불러오기
UCI 데이터세트 리포지토리 에 있는 주간 판매/영업 거래 데이터 세트를 사용하여 판매/영업 기반 시계열 분석을 수행합니다. (출처 출처: James Tan, jamestansc '@' suss.edu.sg, 싱가포르 사회과학대학)
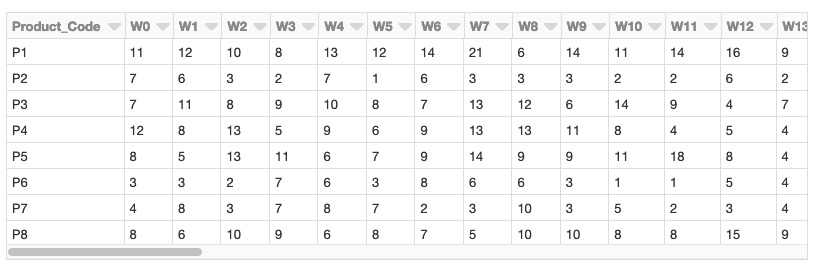
각 제품은 행으로 표시되고 연도의 각 주는 열로 표시됩니다. 값은 매주 판매되는 각 제품의 단위 수를 나타냅니다. 데이터 세트에는 811개의 제품이 있습니다.
제품 코드로 최적의 시계열까지의 거리 계산
계산된 동적 시간 워핑 '거리' 열을 사용하여 히스토그램에서 DTW 거리의 분포를 볼 수 있습니다.
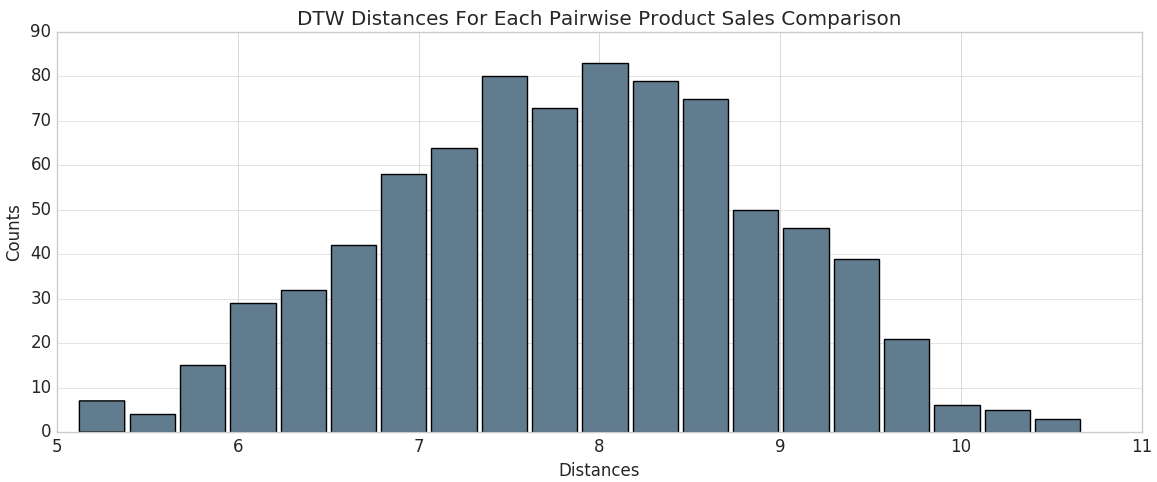
여기에서 최적의 판매/판매 추세에 가장 가까운 제품 코드(즉, 계산된 DTW 거리가 가장 작은 제품 코드)를 식별할 수 있습니다. Databricks를 사용하고 있으므로 SQL query사용하여 쉽게 선택할 수 있습니다. 가장 가까운 것을 표시해 봅시다.
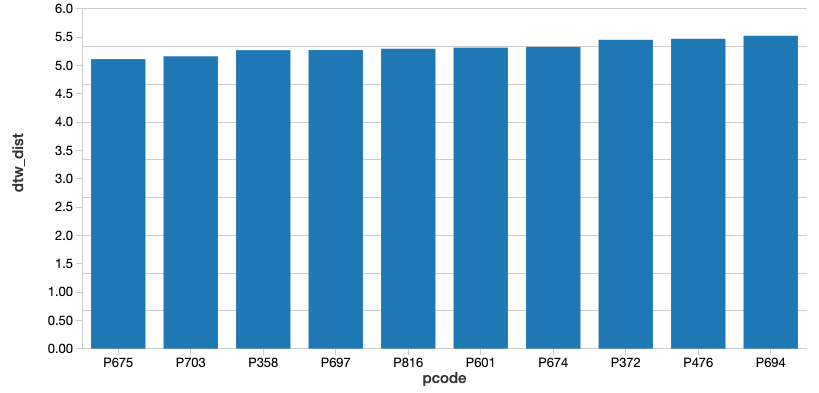
이 query실행 후 최적의 판매 / 영업 트렌드에서 가장 먼 제품 코드에 대한 해당 query 와 함께 트렌드에서 가장 가깝고 먼 2 개의 제품을 식별 할 수있었습니다. 이 두 제품을 모두 플로팅하고 어떻게 다른지 살펴보겠습니다.
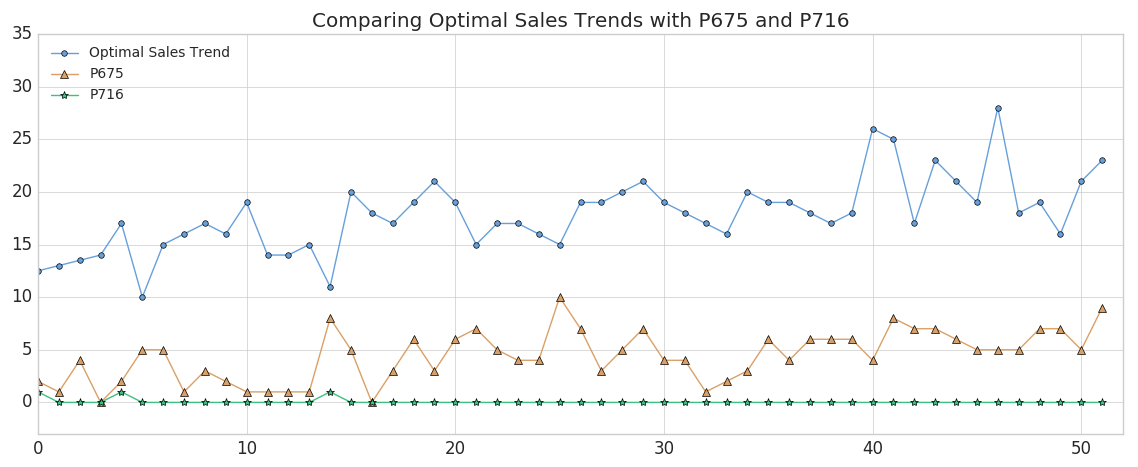
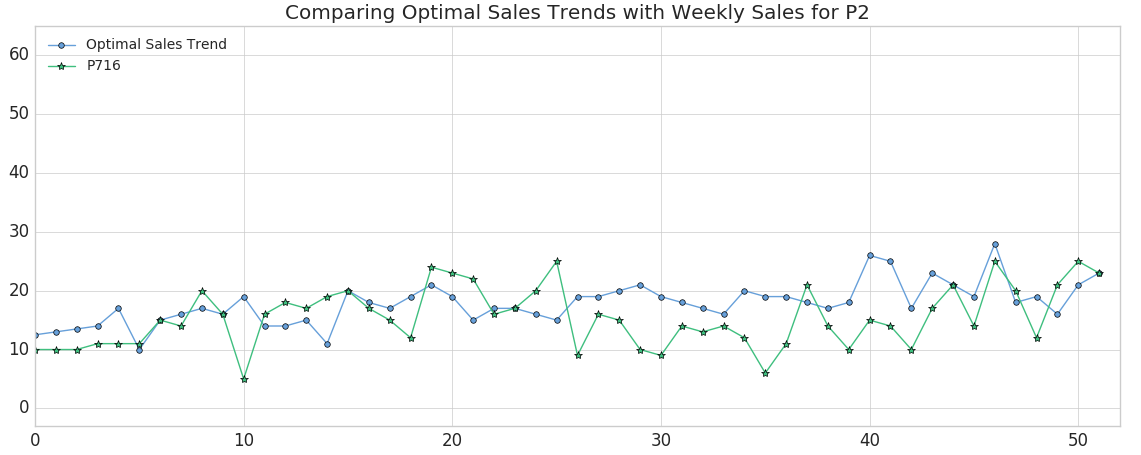
보시다시피 제품 #675(주황색 삼각형으로 표시)는 최적의 판매/영업 추세와 가장 잘 일치하지만 절대 주간 판매/영업은 원하는 것보다 낮습니다(나중에 수정하겠습니다). 이 결과는 DTW 거리가 가장 가까운 제품에 비교하는 메트릭을 어느 정도 반영하는 최고점과 최저점을 가질 것으로 예상하기 때문에 의미가 있습니다. (물론 제품의 정확한 시간 인덱스는 동적 시간 왜곡으로 인해 주별로 달라질 수 있습니다.) 반대로, 제품 #716(녹색 별표로 표시)은 변동성이 거의 없는 최악의 일치를 보이는 제품입니다.
최적의 제품 찾기: 작은 DTW 거리 및 유사한 절대 판매/영업 수
이제 공장의 예상 생산량("최적 판매/영업 추세")에 가장 가까운 제품 목록을 개발했으므로 DTW 거리가 작고 절대 판매/판매 수치가 유사한 제품으로 필터링할 수 있습니다. 한 가지 좋은 후보는 DTW 거리가 6.86이고 모집단 중앙값 거리가 7.89이고 최적 추세를 매우 밀접하게 추적하는 제품 #202입니다.
MLflow를 사용하여 아티팩트와 함께 최고 및 최악의 제품 추적
MLflow 는 실험, 재현 가능성 및 배포를 포함하여 머신 러닝 수명 주기를 관리하기 위한 오픈 소스 플랫폼입니다. Databricks 노트북은 완전히 통합된 MLflow 환경을 제공하므로 Experiment만들고, parameter 및 메트릭을 기록하고, 결과를 저장할 수 있습니다. MLflow를 시작하는 방법에 대한 자세한 내용은 훌륭한 설명서를 참조하세요.
MLflow의 설계는 체계적이고 재현 가능한 방식으로 수행하는 각 Experiment 의 모든 입력과 출력을 기록하는 기능을 중심으로 합니다. "실행"이라고 하는 데이터를 통과할 때마다 Experiment기록할 수 있습니다.
- parameter - 모델에 대한 입력입니다.
- 메트릭 - 모델의 출력 또는 모델의 성공에 대한 측정값입니다.
- 아티팩트 - 모델에서 만든 모든 파일(예: PNG 플롯 또는 CSV 데이터 출력)입니다.
- 모델 - 나중에 다시 로드하여 예측을 제공하는 데 사용할 수 있는 모델 자체입니다.
우리의 경우 이를 사용하여 시계열 데이터에 적용할 수 있는 최대 워프 양인 "스트레치 팩터"를 변경하면서 데이터에 대해 동적 시간 워핑 알고리즘을 여러 번 실행할 수 있습니다. MLflow Experiment시작하고 를 사용하여 mlflow.log_param()쉽게 로깅할 수 있도록 하려면 mlflow.log_metric(), mlflow.log_artifact(), 및 mlflow.log_model(), 우리는 다음을 사용하여 main 함수를 래핑합니다.
아래 축약된 코드와 같습니다.
데이터를 실행할 때마다 사용 중인 "스트레치 팩터" parameter 의 로그와 DTW 거리 메트릭의 Z-점수를 기반으로 이상치로 분류된 제품 로그를 만들었습니다. DTW 거리의 히스토그램의 아티팩트(파일)도 저장할 수 있었습니다. 이러한 실험적 실행은 Databricks에 로컬로 저장되며 나중에 Experiment 결과를 확인하려는 경우 나중에 계속 액세스할 수 있습니다.
이제 MLflow가 각 Experiment의 로그를 저장했으므로 돌아가서 결과를 검사할 수 있습니다. Databricks 노트북에서 오른쪽 위 모서리에 ![]() 있는 아이콘을 선택하여 각 실행의 결과를 보고 비교합니다.
있는 아이콘을 선택하여 각 실행의 결과를 보고 비교합니다.
https://www.youtube.com/watch?v=62PAPZo-2ZU
"스트레치 팩터"를 늘리면 거리 메트릭이 감소하는 것은 놀라운 일이 아닙니다. 직관적으로 이것은 이치에 맞습니다: 알고리즘에 시간 인덱스를 앞뒤로 왜곡할 수 있는 더 많은 유연성을 제공하면 데이터에 더 잘 맞는 것을 찾을 수 있습니다. 본질적으로, 우리는 약간의 편향을 분산과 맞바꿨습니다.
MLflow의 로깅 모델
MLflow에는 Experiment parameter, 메트릭 및 아티팩트(예: 플롯 또는 CSV 파일)를 기록할 수 있을 뿐만 아니라 머신 러닝 모델도 기록할 수 있습니다. MLflow 모델은 다른 MLflow 도구 및 기능과의 호환성을 보장하는 일관된 API를 준수하도록 구조화된 폴더입니다. 이 상호 운용성은 매우 강력하여 모든 Python 모델을 다양한 유형의 프로덕션 환경에 신속하게 배포할 수 있습니다.
MLflow에는 , Spark MLlib, PyTorch, TensorFlow 등을포함하여 가장 인기 있는 많은 MLlib(머신 러닝 라이브러리)에 대한 여러 가지 일반적인 모델 "버전"이 미리 로드되어 있습니다.Scikit-Learn 이러한 모델 버전을 사용하면 이 블로그 게시물에 설명된 대로 모델을 처음 구성한 후 간단하게 기록하고 다시 로드할 수 있습니다. 예를 들어 Scikit-Learn와 함께 MLflow를 사용하는 경우 모델 로깅은 Experiment내에서 다음 코드를 실행하는 것만큼 쉽습니다.
또한 MLflow는 타사 라이브러리(예: XGBoost 또는 spaCy)의 모든 모델 또는 간단한 Python 함수 자체를 MLflow 모델로 저장할 수 있는 "Python 함수" 버전을 제공합니다. Python 함수 버전을 사용하여 만든 모델은 동일한 에코시스템 내에 있으며 추론 API를 통해 다른 MLflow 도구와 상호 작용할 수 있습니다. 모든 사용 사례에 대해 계획하는 것은 불가능하지만 Python 함수 모델 버전은 가능한 한 보편적이고 유연하도록 설계되었습니다. 사용자 지정 처리 및 로직 평가가 가능하여 ETL 애플리케이션에 유용할 수 있습니다. 더 많은 "공식" 모델 버전이 온라인에 출시되더라도 일반 Python 함수 버전은 여전히 모든 종류의 Python 코드와 MLflow의 강력한 추적 도구 키트 간의 다리를 제공하는 중요한 "catchall" 역할을 합니다.
Python 함수 버전을 사용하여 모델을 로깅하는 것은 간단한 프로세스입니다. 모든 모델 또는 함수는 모델로 저장할 수 있으며 한 가지 요구 사항이 있습니다 : pandas Dataframe 을 입력으로 사용하고 DataFrame 또는 NumPy 배열을 반환해야합니다. 해당 요구 사항이 충족되면 함수를 MLflow 모델로 저장하려면 PythonModel에서 상속되는 Python 클래스를 정의하고 .predict() 여기에 설명된 대로 사용자 지정 함수를 사용하여 메서드를 사용할 수 있습니다.
실행 중 하나에서 기록된 모델 로드Loading a logged model from one of our runs
이제 여러 가지 스트레치 요소를 사용하여 데이터를 실행했으��므로 자연스러운 다음 단계는 결과를 검토하고 기록한 메트릭에 따라 특히 잘 수행된 모델을 찾는 것입니다. MLflow를 사용하면 기록된 모델을 쉽게 다시 로드하고 이를 사용하여 새 데이터에 대한 예측을 수행할 수 있습니다 다음 지침을 사용합니다.
- 모델을 로드하려는 실행에 대한 링크를 클릭합니다.
- '실행 ID'를 복사합니다.
- 모델이 저장된 폴더의 이름을 기록해 둡니다. 우리의 경우 단순히 "모델"이라고 합니다.
- 아래와 같이 모델 폴더 이름과 실행 ID를 입력합니다.
모델이 의도한 대로 작동하는지 보여주기 위해 이제 모델을 로드하고 변수 new_sales_units내에서 만든 두 개의 새 제품에 대한 DTW 거리를 측정하는 데 사용할 수 있습니다.
다음 단계
보시다시피 MLflow 모델은 새롭고 보이지 않는 값을 쉽게 예측합니다. 또한 Inference API를 준수하므로 모든 서비스 플랫폼(예: Microsoft Azure ML 또는 Amazon Sagemaker)에 모델을 배포하거나, 로컬 REST API 엔드포인트로 배포하거나, Spark-SQL과 함께 쉽게 사용할 수 있는 사용자 정의 함수(UDF)를 생성할 수 있습니다. 마지막으로 동적 시간 워핑을 사용하여 Databricks 사용하여 판매/영업 추세를 예측하는 방법을 시연했습니다 Unified Analytics Platform. 지금 바로 동적 시간 워핑 및 MLflow를 사용하여 예측 판매 / 영업 트렌드 노트북과 Databricks Runtime for Machine Learning 을 사용해 보세요.