실제 데이터로 위험에 처한 환자 탐지
의료 Delta Lake에 머신 러닝 런타임과 MLflow를 사용하여 환자 질병을 예측하는 방법

경제적인 유전체 서열 분석과 AI 지원 의료 이미지 영상이 등장하면서 정밀 의료에 대한 관심이 상당히 늘어났습니다. 정밀 의료에서는 데이터와 AI를 활용하여 최적의 치료 방법을 찾아내는 것을 목표로 합니다. 정밀 의료는 희귀 질병 및 암을 진단받은 환자의 치료 효과를 개선하지만, 환자가 아픈 후에야 적용이 가능한 성격의 방법입니다.
의료 서비스 지출과 효과의 경우, 당뇨, 심장병, 약물 중독 장애 등의 만성 질환을 예방함으로써 치료 비용을 낮추고 삶의 질을 개선할 수 있는 매우 큰 기회가 있습니다. 미국에서 사망자 10명 중 7명, 의료 서비스 지출의 85%가 만성 질환에서 발생하고, 유럽과 동남아시아에서도 유사한 흐름이 발견됩니다. 전염되지 않는 질병은 일반적으로 환자를 교육하고 만성 질환을 일으키는 근본 문제를 해결하면 예방할 수 있습니다. 이런 문제에는 기저 생물학적 위험 요소(예: 신경학적 질병을 일으키는 알려진 유전적 위험), 사회 경제적 요소(예: 환경 오염, 건강한 식품/예방적 관리에 대한 접근성 부족), 행동 위험(예: 흡연, 음주, 정적인 라이프스타일) 등이 포함됩니다.
정밀 예방은 데이터를 사용하여 질병이 발병할 위험이 큰 환자 집단을 찾아내서, 발병 위험을 낮추는 개입을 제공하는 데 초점을 맞춥니다. 개입에는 위험군 환자를 원격으로 모니터링하고 라이프스타일 및 치료 권고 사항을 제공하는 디지털 앱을 활용하거나, 질병 상태를 모니터링하거나, 보충적 치료를 제공하는 등이 포함됩니다. 그러나 이런 개입을 적용하려면 먼저 위험한 환자를 찾아야 합니다.
위험한 환자를 파악하는 가장 강력한 도구 중 하나는 실제 데이터(RWD)입니다. RWD란 입원 시설, 임상 기관, 약국, 의료 기관으로 구성된 의료 시스템 에코시스템에서 생성된 데이터(예: 전자 의료 기록(EMR), 의료 기록(EHR))를 총칭하는 용어이며, 요즈음 들어서는 유전체, 소셜 미디어, 웨어러블 등의 다른 소스에서 수집된 데이터까지 포함되고 있습니다. 지난 블로그에서는 EHR 데이터로부터 임상 데이터 레�이크를 구축하는 방법을 보여드렸습니다. 이 블로그에서는 임상 데이터 레이크를 더욱 발전시켜 Databricks Unified Data Analytics Platform으로 환자의 치료 여정을 추적하고 머신 러닝 모델을 만드는 방법을 설명합니다. 환자 진료 방문 기록과 인구 통계학적 정보를 입력하고 이 모델을 사용하면 특정 기간에 환자가 특정 질환을 앓을 위험을 평가할 수 있습니다. 이 예시에서는 약물 과용에 대해 살펴봅니다. 약물 과용이 중요한 주제인 이유는 약물 사용 장애가 있는 환자는 다양한 건강상의 문제가 발생하기 때문입니다. MLflow를 사용하여 모델을 추적하면 시간에 따라 모델이 변화하는 양상을 쉽게 추적할 수 있어, 환자 치료에 모델을 배포하는 과정을 보다 신뢰할 수 있습니다.
Databricks에서
머신 러닝을 사용한 질병 예측
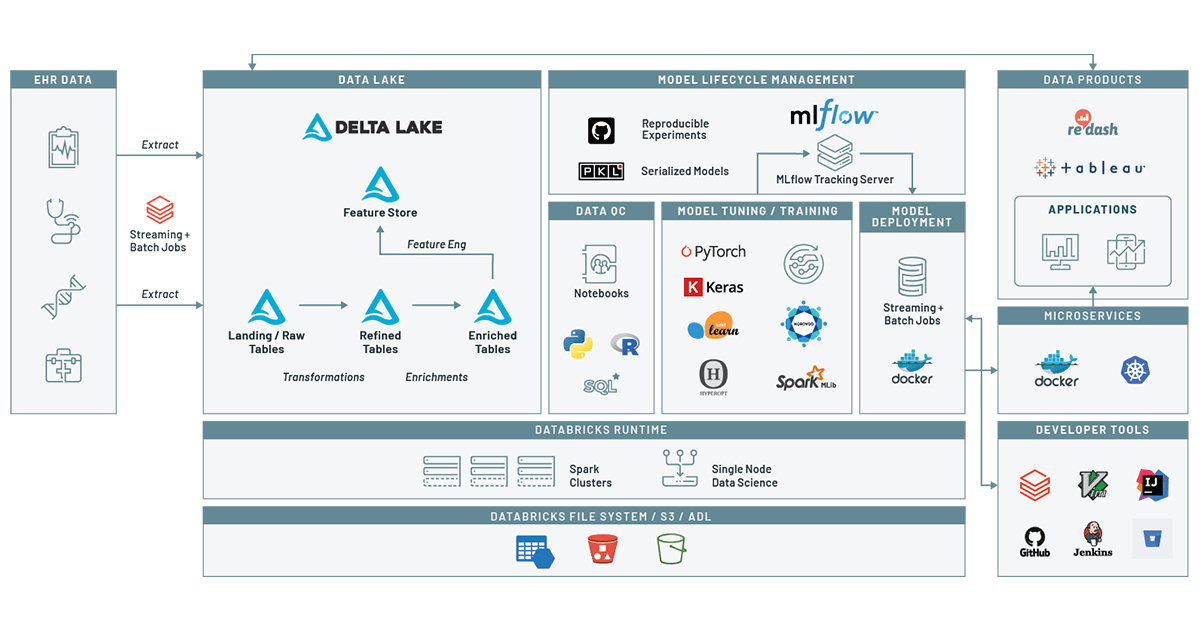
데이터 준비
특정 시점의 위험을 예측하는 모델을 훈련하려면 환자와 관련이 있는 인구 통계학적 정보(예: 진료 시점의 나이, 인종)가 담긴 데이터 세트와 환자의 진단 기록에 대한 시계열 데이터가 필요합니다. 이 데이터는 환자가 향후 어떤 질병을 진단받을 가능성에 영향을 미치는 진단 및 인구 통계학적 위험을 알아보기 위한 모델을 훈련하는 데 사용할 수 있습니다.
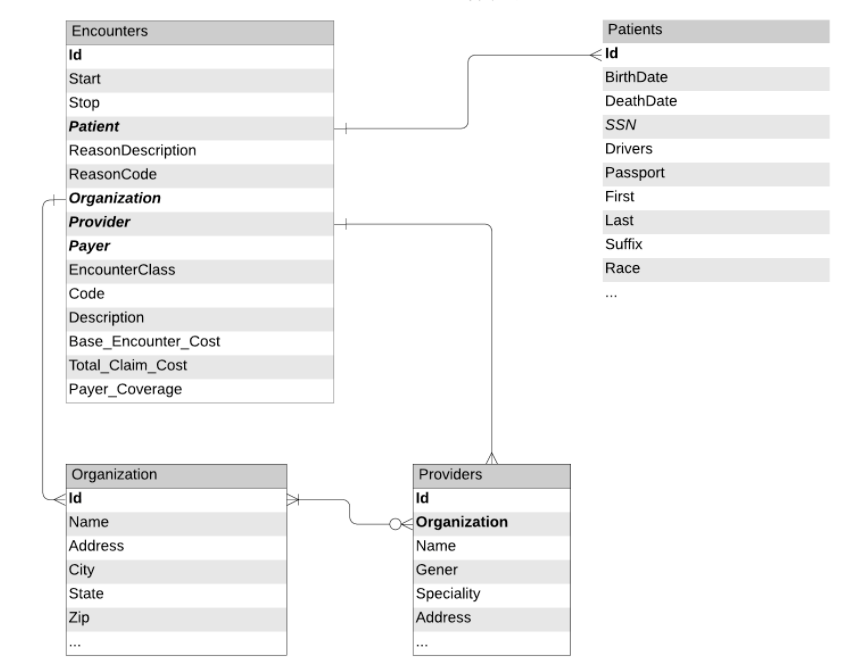
그림 1: 데이터 스키마와 EHR에서 추출한 테이블 간의 관계
이 모델을 훈련할 때 환자의 진료 기록과 인구 통계학적 정보를 활용할 수 있습니다. 이는 전자 의료 기록(EHR)의 형태로 제공됩니다. 그림 1은 워크플로에서 사용할 테이블을 나타냅니다. 이 테이블은 이전의 블로그에서 다룬 노트북을 사용하여 준비했습니다. 진료 방문, 조직 및 환자 데이터(PII 정보는 난수화)를 Delta Lake에서 로드한 후, 환자의 인구 통계학적 정보와 함께 모든 환자 진료 방문 데이터 프레임을 생성합니다.
표적 질환에 따라 훈련 데이터에 포함할 환자 세트도 선택합니다. 즉, 사례, 과거 진료 방문 시 1회 이상 해당 질병을 진단받은 환자, 동일한 숫자의 대조군, 발병 이력이 없는 환자를 포함합니다.
이제 연구에 포함할 환자로만 진료 방문 세트를 제한합니다.
필요한 기록을 가져왔으므로 특징점을 추가해야 합니��다. 이 예측 작업에서는 인구 통계학적 정보 외에도 해당 질병으로 진단을 받은 총 횟수 또는 알려진 동반 질환(동반 이환), 이전 진료 방문 횟수를 특정 진료 방문에 대한 과거 컨텍스트로 선택합니다.
대부분 질병의 경우 동반 질환에 대한 여러 가지 문헌이 있지만, 실제 데이터 세트에서의 데이터를 활용하여 표적 질환과 관련된 동반 질환을 알아낼 수 있습니다.
우리 코드에서는 노트북 위젯을 사용하여 포함할 동반 질환의 개수와 진료 전체에서 살펴볼 기간(일)을 지정합니다. 이 매개변수는 MLflow의 추적 API를 사용하여 로깅합니다.

이제 각 진료 방문에 동반 질환 특징점을 추가해야 합니다. 각 동반 질환에 대해 과거에 해당 질환이 관찰된 횟수를 나타내는 열을 추가합니다.
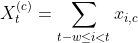
이런 특징점은
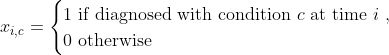
2단계에 걸쳐 추가합니다. 먼저, 동반 질환 지표 함수를 추가하는 함수를 정의합니다( xi,c).
그런 다음, Spark SQL의 강력한 window 함수 지원 기능을 사용하여 연속 기간(일)에 대해 지표 함수의 합계를 산출합니다.
동반 질환 특징점을 추가하고 나면 대상 변수를 추가해야 합니다. 대상 변수는 환자가 향후 특정 기간(예: 현재 진료 방문으로부터 1개월)에 표적 질환을 진단받을지를 나타냅니다. 이 작업의 로직은 이전 단계와 매우 비슷하지만, 미래의 이벤트를 기간으로 설정한다는 차이가 있습니다. 여기에서는 바이너리 레이블만 사용해서 미래에 그 질병을 진단받을지만 나타냅니다.
이 특징점을 Delta Lake의 특징점 스토어에 작성합니다. 재현성을 보장하기 위해서 mlflow 실험 ID와 실행 ID를 특징점 스토어의 열로 추가합니다. 이 방법을 사용하는 장점은 더 많은 데이터를 받아서, 특징점 스토어에 새로운 특징점을 추가하고 나중에 ��참고할 수 있다는 것입니다.
데이터에서 품질 문제 제어
훈련 작업을 시작하기 전에 데이터에서 클래스별로 레이블이 어떻게 분포되어 있는지 살펴보겠습니다. 바이너리 분류를 적용하는 경우 대부분 한 가지 클래스가 드물게 분포하기도 합니다. 예를 들어, 질병 예측과 같은 경우가 해당합니다. 이 클래스 불균형은 학습 프로세스에 부정적 영향을 미칩니다. 모델은 추정 과정에서 드문 이벤트 대신 주를 이루는 클래스에 집중하는 경향이 있습니다. 게다가 평가 프로세스도 악영향을 받습니다. 예를 들어, 0/1 레이블이 각각 95%, %5로 분포하는 불균형한 데이터 세트에서 항상 0을 예측하는 모델은 정확도가 95%입니다. 레이블에 불균형이 있다면 불균형한 데이터를 보정하기 위한 일반적인 기술 중 한 가지를 적용해야 합니다.
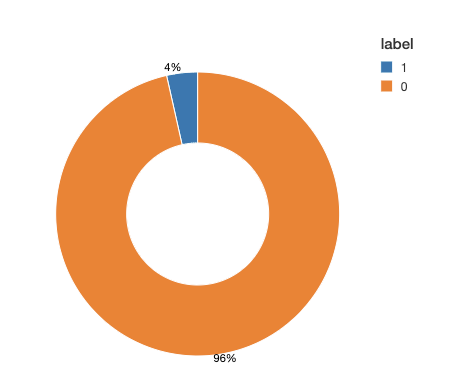
훈련 데이터를 보면 매우 불균형한 데이터 세트인 것을 알 수 있습니다(그림 2 참조). 관찰 시간의 95% 이상에서 진단의 증거가 보이지 않습니다. 불균형을 조정하려면 대조군 클래스 샘플을 줄이거나, 합성 샘플을 생성해야 합니다. 어느 쪽을 선택할지는 데이터 세트 크기와 특징점 개수에 따라 달라집니다. 이 예시에서는 다수 클래스의 샘플 수를 줄여서 데이터 세트의 균형을 맞춥니다. 다만, 실제에서는 여러 가지 방법을 ��결합할 수 있습니다. 예를 들어 다수 클래스의 샘플 수를 줄이는 동시에 훈련 알고리즘에 클래스 가중치를 할당하기도 합니다.
모델 훈련
모델을 훈련하기 위해 인구 통계학적 특징점과 동바 질환 특징점의 하위 집합으로 조건을 보강하고, 각 관찰에 레이블을 적용한 다음, 훈련 다운스트림을 위해 이 데이터를 모델에 전달했습니다. 예를 들어 진료 방문 클래스(예: 이 진료 방문이 예방적 치료를 위한 것인가, 응급실 방문인가?)와 진료 비용으로 최근 진단된 동반 질환을 강화했습니다. 인구 통계학적 정보의 경우, 인종, 성별, 우편번호, 진료 방문 시점 환자 나이를 선택했습니다.
대부분의 경우, 원래 임상 데이터를 합치면 테라바이트 규모의 용량이 되지만 포함/제외 기준에 따라 기록을 필터링하고 제한하면 한 대의 컴퓨터에서 훈련할 수 있는 데이터 세트가 나옵니다. spark 데이터 프레임을 손쉽게 pandas 데이터 프레임으로 변환하고 원하는 알고리즘으로 모델을 훈련할 수 있습니다. Databricks ML 런타임을 사용하면 다양한 오픈 ML 라이브러리를 바로 사용할 수 있습니다.
모든 머신 러닝 알고리즘은 매개변수 세트(하이퍼 매개변수)를 받는데, 입력 매개변수에 따라 점수가 변경될 수 있습니다. 또한 잘못된 매개변수나 알고리즘을 적용하면 오버피팅이 발생하기도 합니다. 모델이 우수한 성능을 발휘하도록 하이퍼 매개변수 튜닝을 사용하여 최적의 모델 아키텍처를 선택했습니다. 최종 모델은 이 단계에서 얻은 매개변수를 지정하여 훈련할 것입니다.
모델을 튜닝하려면 먼저 데이터를 사전 처리해야 합니다. 이 데이터 세트에는 숫자 특징점(예: 최근에 얻은 동반 질환 수)뿐만 아니라, 우리가 사용하고자 하는 범주별 인구 통계학적 데이터도 포함됩니다. 범주별 데이터의 경우, 원-핫-인코딩을 사용하는 것이 가장 좋습니다. 그 이유는 크게 두 가지가 있습니다. 첫째, 대부분 분류자(이 경우 논리적 회귀)는 숫자 특징점에 적용합니다. 둘째, 범주별 변수를 숫자 지수로 변환하기만 하면 데이터에 순서가 생깁니다. 가령 주 이름을 지수로 변환하는 경우 분류자를 오도할 수 있습니다. 예를 들어 캘리포니아주를 5로 변환하고 뉴욕주를 23으로 변환하면 뉴욕이 캘리포니아보다 "커집니다." 각 주 이름의 지수를 알파벳 순으로 작성된 목록에 반영하더라도 모델에서는 이 순서가 아무 의미가 없습니다. 원-핫-인코딩은 이런 효과를 제거합니다.
이 사례의 전처리 단계는 ��입력 매개변수를 받지 않고 하이퍼 매개변수는 전처리 부분이 아니라 분류자에만 영향을 미칩니다. 그러므로 전처리를 별도로 실행하고 그 결과로 얻은 데이터 세트를 모델 튜닝에 사용합니다.
이제 모델에 가장 적절한 매개변수를 선택하고자 합니다. 이 분류에서는 LogisticRegression과 탄력적 순 개인화를 사용합니다. 원-핫-인코딩을 적용한 후에는 해당 범주별 변수의 관계 수에 따라 여러 특징점이 나올 수 있고, 특징점의 개수가 샘플 수를 초과할 수 있습니다. 이런 문제에 대한 오버피팅을 피하기 위해 목적 함수에 페널티를 적용합니다. 탄력적 순 정규화의 장점으로, 두 가지 페널티 적용 기술(LASSO 및 능형 회귀)을 결합해서 하이퍼 매개변수 튜닝 시 하나의 변수로 두 기술의 수준을 제어할 수 있습니다.
모델을 개선하기 위해 hyperopt를 사용하여 하이퍼 매개변수 그리드를 검색하고 최적의 매개변수를 찾았습니다. 또한 hyperopt의 SparkTrials 모드를 사용하여 하이퍼 매개변수 검색을 동시에 실행했습니다. 이 과정에서는 Databricks의 관리형 MLflow를 활용하여 각 하이퍼 매개변수 실행에 대해 매개변수와 지표를 자동으로 로깅합니다. 각 매개변수 세트를 검증할 때는 F1 점수를 사용하는 k중 교차 검증을 사용하여 모델을 평가합니다. k중 교차 검증에서는 여러 값이 생성되므로, 점수의 최솟값(최악의 시나리오)을 선택하고 hyperopt를 사용할 때 극대화하고자 했습니다.

이 스페이스에 대한 검색을 개선하고자 logspace에서 매개변수 그리드를 선택하고 변환 함수를 정의하여 hyperopt로 추천 매개변수를 변환했습니다. 이 방법에 대해 자세히 살펴보고 이런 하이퍼 매개변수 스페이스를 정의하기로 한 이유를 알아보려면 Databricks에서 전체 ML 수명 주기를 관리하는 방법을 설명한 이 토크를 참조하세요.
이 실행의 결과는 교차 검증 시 F1 점수에 따라 평가한 최적의 매개변수가 됩니다.
��이제 MLflow 대시보드를 살펴보겠습니다. MLflow는 hyperopt의 모든 실행을 자동으로 그룹화합니다. 다양한 도표를 사용하여 손실 함수에서 각 하이퍼 매개변수가 미치는 영향을 검사할 수 있습니다. 그림 3을 참조하세요. 이는 모델의 동작과 하이퍼 매개변수의 효과를 더욱 명확히 이해하는 데 특히 중요합니다. 예를 들어 정규화의 역인 C에 대한 값이 작을수록 F1에 대한 값이 높아집니다.
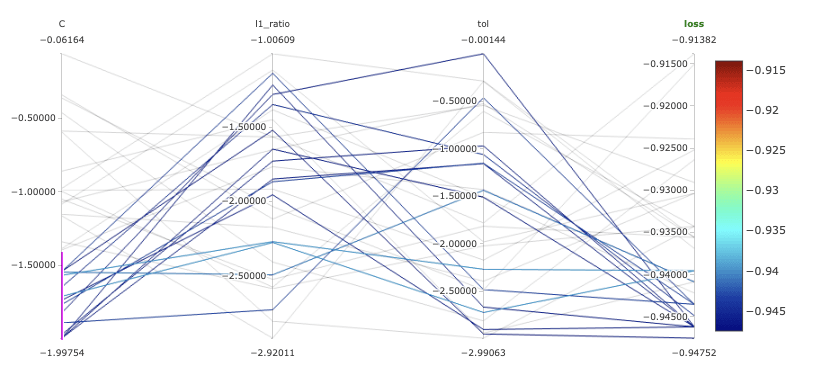
그림 3. MLflow의 모델 병렬 좌표 도표.
최적의 매개변수 조합을 찾은 후에 MLflow를 사용해서 최적의 하이퍼 매개변수로 바이너리 분류자를 훈련하고 모델을 로깅했습니다. MLflow의 model api를 사용하면 훈련에 어떤 기본 라이브러리를 사용했든 나중에 모델 평가 시 호출할 수 있는 python 함수로 모델을 저장할 수 있습니다. 모델을 쉽게 발견할 수 있도록 표적 질환(이 경우 "약물 과용")과 관련된 이름으로 모델을 로깅합니다.
이제 이전 단계에서 얻은 최적의 매개변수를 전달하여 모델을 훈련할 수 있습니다.
모델 훈련에서 sklearn 파이프라인에 전처리(원-핫-인코딩)를 포함하였고 인코더와 분류자를 하나의 모델로 로깅했습니다. 다음 단계에서는 환자 데이터에 모델을 호출해서 위험을 평가하기만 하면 됩니다.
모델 배포 및 프로덕션화
모델을 훈련해서 MLflow에 로깅하고 나면 모델을 사용해서 새 데이터를 평가할 차례입니다. MLflow에는 여러 가지 태그로 실험을 검색할 수 있는 기능이 있습니다. 예를 들어 이 사례에서는 모델 훈련 중에 지정한 실행 이름을 사용하여 훈련된 모델의 아티팩트 URI를 검색합니다. 그러면 주요 지표를 기준으로 검색된 실험의 순서를 정할 수 있습니다.
특정 모델을 선택한 후에는 모델 URI와 이름을 지정하여 모델을 로드할 수 있습니다.

또한, Databricks의 모델 레지스트리를 사용하여 모델 버전, 프로덕션 수명 주기를 관리하고 간편하게 모델을 제공할 수 있습니다.
질병 예측을 정밀 예방으로 변환
이 블로그에서는 만성 질환을 발병시키는 임상 및 인구 통계학적 공변인을 찾아내는 정밀 예방 시스템의 필요성을 살펴보았습니다. 그런 다음, EHR의 시뮬레이션된 데이터를 사용하여 약물 과용 위험이 있는 환자가 누구인지 알아내는 머신 러닝 워크플로를 전체적으로 설명했습니다. 이 워크플로가 끝나고 MLflow에서 훈련한 ML 모델을 내보내고 새로운 환자 데이터 스트림에 적용했습니다.
이 모델이 유용하기는 하지만 실제에 적용하기 전까지는 아무런 영향을 미칠 수 없습니다. 실제로도 여러 고객과 협력하여 이 모델 및 이와 유사한 시스템을 프로덕션에 배포했습니다. 예를 들어 Medical University of South Carolina는 EHR 데이터를 처리한 라이브 스트리밍 파이프라인을 배포하여 패혈증 위험이 있는 환자를 찾아냈습니다. 그 덕분에 패혈증과 관련된 환자를 미리 찾아내는 시간이 8시간으로 단축되었습니다. INTEGRIS Health에서 배포한 이와 유사한 시스템에서는 EHR 데이터를 모니터링하여 압박 궤양이 나타날 징후를 모니터링했습니다. 이 두 병원에서는 환자가 발견될 때마다 의료팀에게 상태를 알렸습니다. 의료 보험사의 경우, Optum과 협력하여 유사한 모델을 배포했습니다. 이들은 장단기 아키텍처에서 반복적 신경망을 사용한 질병 예측 엔진을 개발하여, 9가지 질병 영역에서 우수한 일반화로 질병 진행 상태를 알아냈습니다. 이 모델은 예방적 치료 경로와 환자를 일치시켜, 만성 질환 환자의 경과를 개선하고 치료 비용을 절감했습니다.
우리 블로그에서는 의료 환경에서 질병 예측 알고리즘을 사용하는 데 초점을 맞추었지만 제약 분야에서도 이 모델을 구축하여 배포할 좋은 기회가 있습니다. 질병 예측 모델은 시판 후 약물 사용 방식에 대한 인사이트를 제공할 수 있으며, 심지어 예전에는 미처 몰랐던 보호 효과를 발견해 레이블 확장 노력에 도움을 줄 수 있습니다. 또한 질병 예측 모델은 희귀 질환(또는 그 외에 진단되지 않은 질환)에 대한 임상 시험 등록을 살펴볼 때 유용할 수 있습니다. 오진 후에 희귀 질환을 진단받은 환자를 살펴보는 모델을 만들면 임상의에게 일반적인 오진 패턴을 알리는 교육 자료를 제작할 수 있습니다. 또한, 임상 포함 기준을 만들어 임상 등록과 효능을 높이는 효과를 기대할 수도 있습니다.
의료 Delta Lake에서
정밀 예방 시작하기
이 블로그에서는 실제 데이터에 머신 러닝을 사용하여 만성 질환의 위험이 있는 환자를 찾는 방법을 보여드렸습니다. Delta Lake를 사용해서 임상 데이터 세트를 저장하고 처리하는 방법에 대한 자세한 내용을 알아보려면 실제 임상 데이터 세트를 다루는 무료 eBook을 참조하세요. 또한 이 블로그의 환자 위험 평가 노트북을 사용해서 무료 평가판을 시작할 수도 있습니다.

