Databricks 워크스페이스 관리 - 계정, 워크스페이스 및 메타스토어 관리자를 위한 모범 사례
세 명의 관리자 이야기
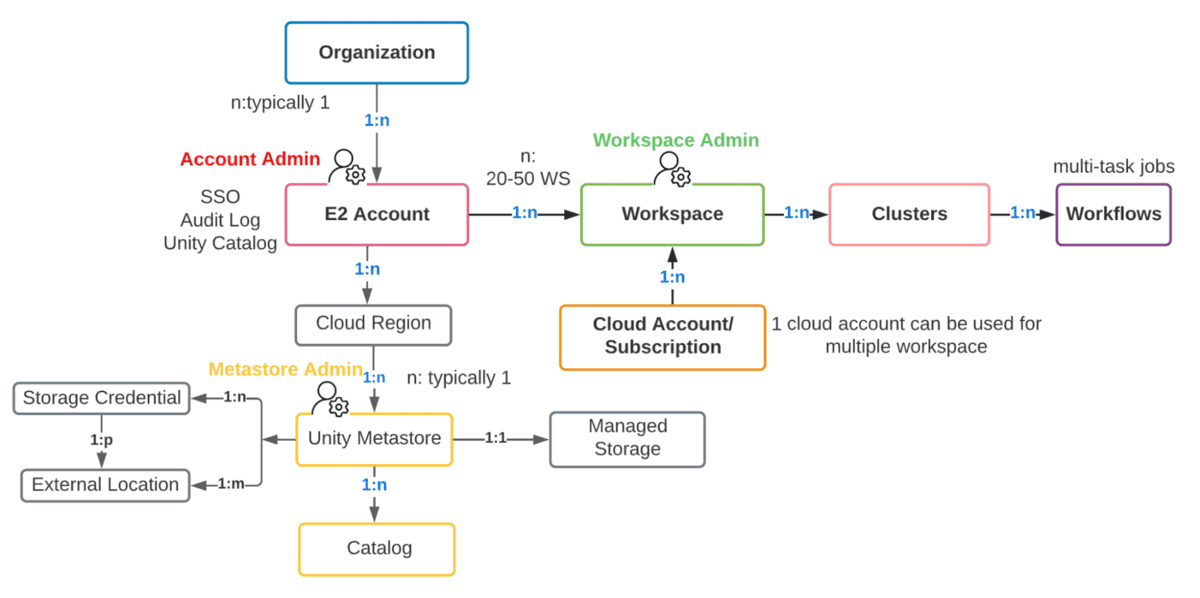
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
이 블로그는 우리의 Admin Essentials 시리즈의 일부로, Databricks 관리자에게 관련된 주제를 논의하는 곳입니다. 다른 블로그에는 Workspace Management Best Practices, Terraform을 이용한 DR 전략 등이 포함되어 있습니다! 더 많은 콘텐츠가 곧 제공될 예정이니 계속 주목해 주세요. 이전의 관리 중심 블로그에서는 DR, CI/CD, 시스템 건강 체크 등의 측면에서 upfront 디자인과 자동화를 통해 강력한 워크스페이스 조직을 구축하고 유지하는 방법에 대해 논의했습니다. 관리의 중요한 측면 중 하나는 Lakehouse 내에 존재할 수 있는 다양한 유형의 관리자 인물들을 고려할 때, 워크스페이스 내에서 어떻게 조직화하는지에 대한 것입니다. 이 블로그에서는 워크스페이스를 관리하는 관리적 고려사항에 대해 이야기하겠습니다, 예를 들어 어떻게:
- 새로운 사용자와 사용 사례의 온보딩을 미래에 대비하여 정책과 가드레일을 설정하십시오
- 리소스 사용 관리
- 허용 가능한 데이터 접근을 보장하십시오
- 투자의 가치를 극대화하기 위해 컴퓨팅 사용량을 최적화하십시오
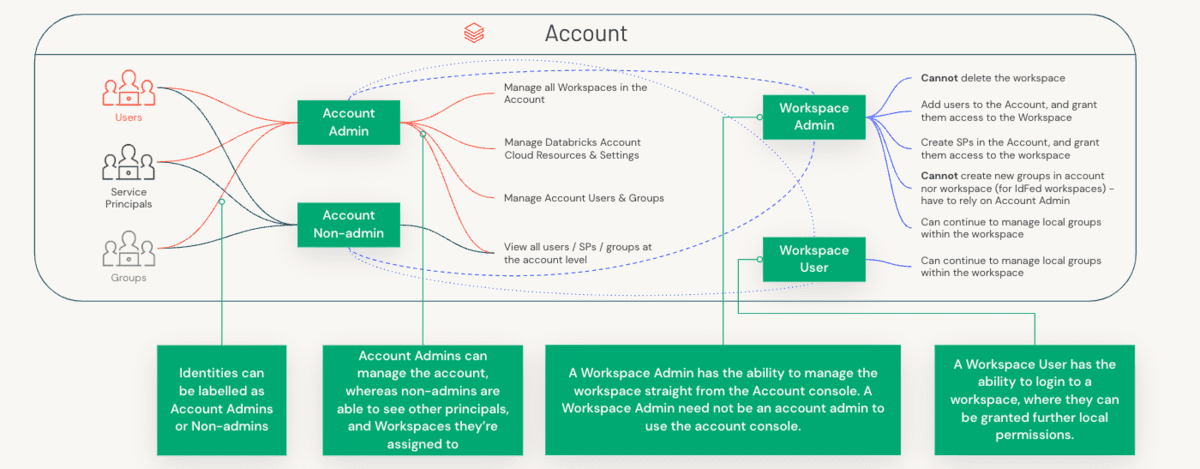
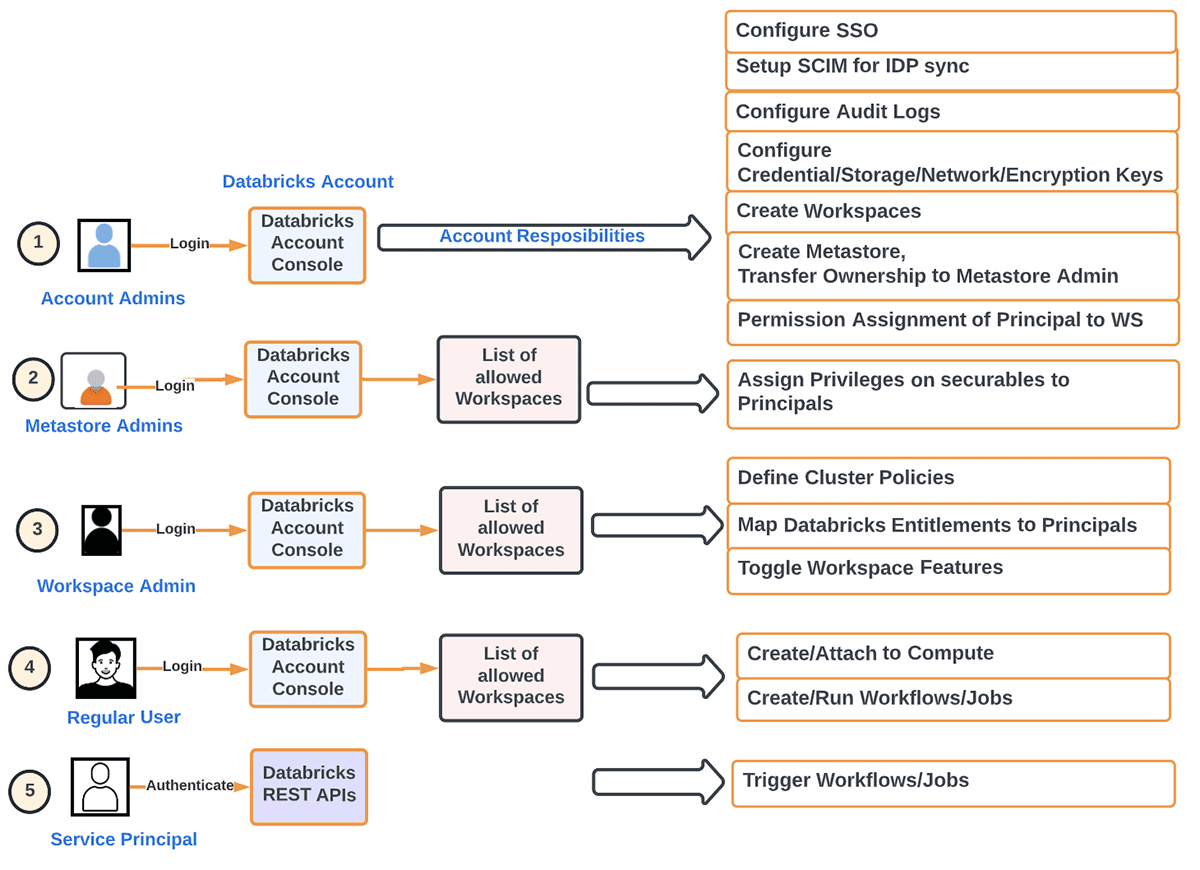
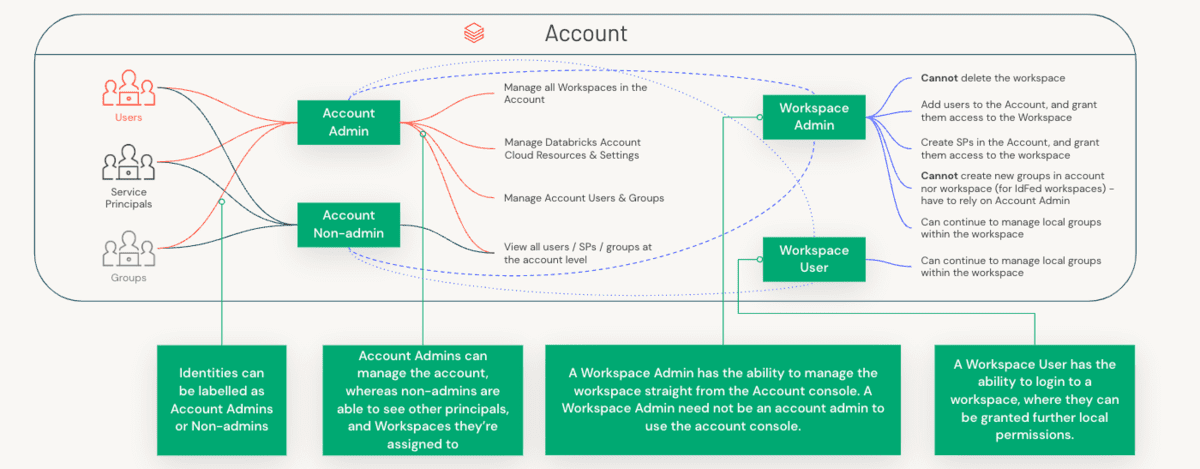
역할의 구분을 이해하기 위해서는 먼저 Account Administrator와 Workspace Administrator 사이의 차이점을 이해하고, 각 역할이 관리하는 특정 컴포넌트를 이해해야 합니다.
계정 관리자 Vs 작업 공간 관리자 Vs 메타스토어 관리자
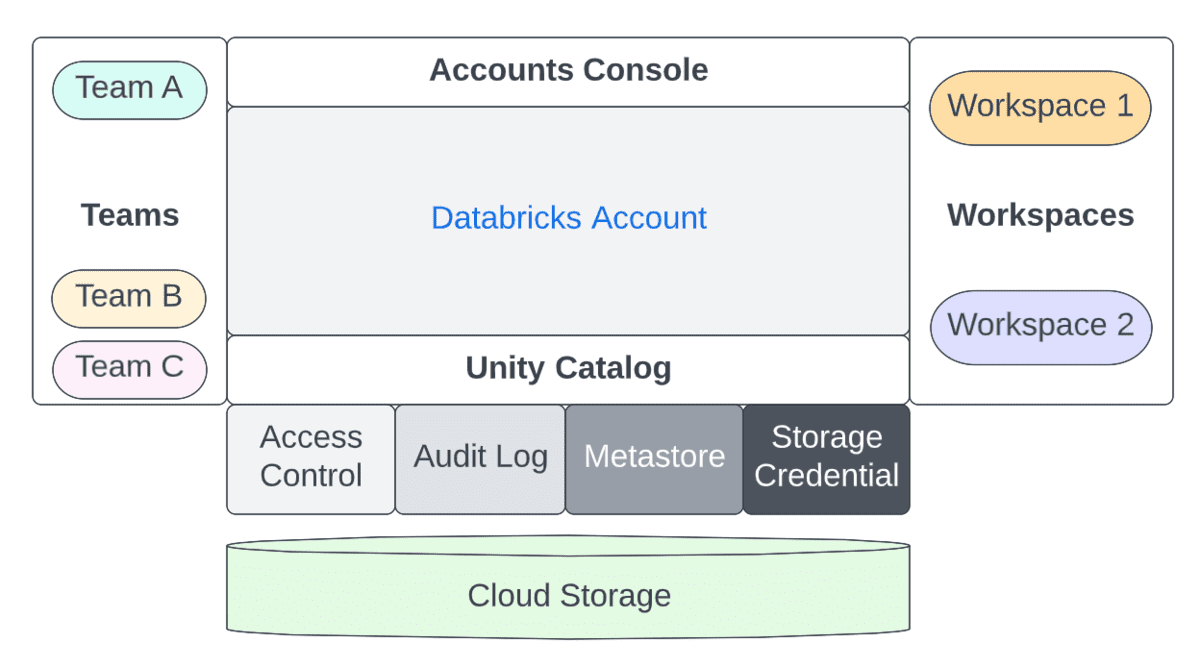
관리적 고려사항은 계정(대개 조직과 1:1로 매핑되는 고수준 구조)과 워크스페이스(LOB에 따라 다양한 방식으로 매핑할 수 있는 더 세분화된 격리 수준) 모두에 걸쳐 분할됩니다. 이 세 가지 역할 간의 업무 분리를 살펴봅시다.
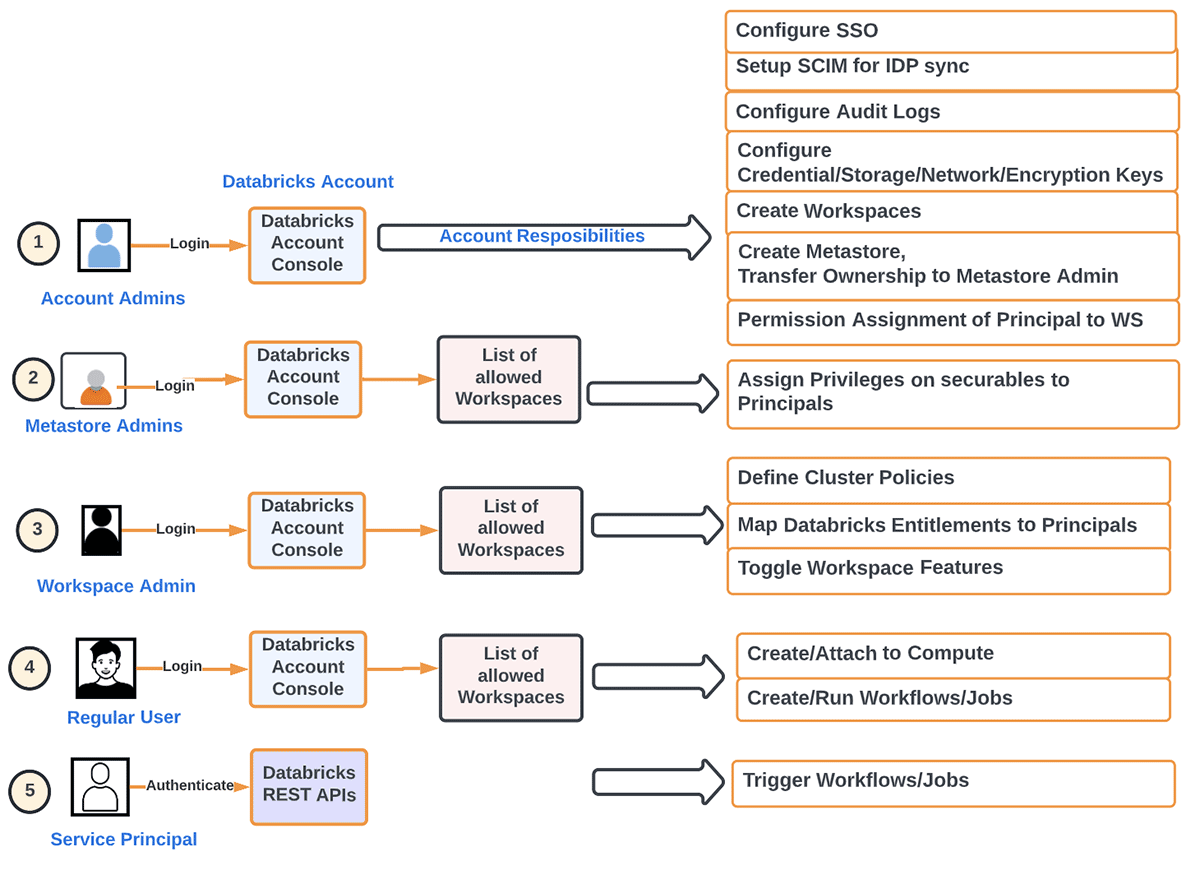
다르게 말하면, 계정 관리자 의 주요 책임을 다음과 같이 나눌 수 있습니다:
- 계정 수준에서의 주체(그룹/사용자/서비스) 제공 및 SSO. 아이덴티티 연합 은 계정에서 직접 작업 공간에 계정 레벨 아이덴티티에 접근 권한을 부여하는 것을 의미합니다.
- 메타스토어 설정
- 감사 로그 설정
- 계정 수준에서의 사용량 모니터링 (DBU, 청구)
- 원하는 조직 방법에 따라 워크스페이스 생성
- 다른 워크스페이스 수준 객체 관리 (저장소, 자격 증명, 네트워크 등)
- IaaC를 사용하여 개발 작업 부하를 자동화하여 프로덕션 작업 부하에서 인간 요소를 제거
- 서버리스 작업 부하, 델타 공유 등 계정 수준에서 기능을 켜고/끄기
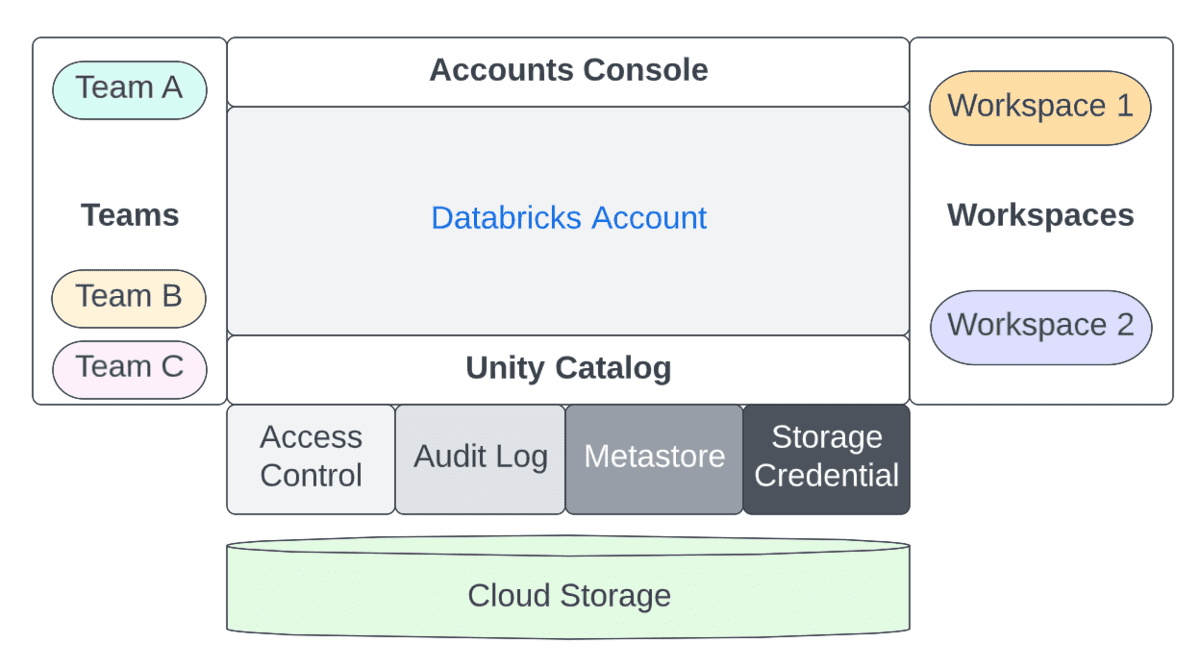
반면에, 작업 공간 관리자 의 주요 관심사는 다음과 같습니다:
- 작업 공간 수준에서 적절한 역할 (사용자/관리자)을 주체에 할당하십시오
- 적절한 권한 (ACLs)을 워크스페이스 수준에서 주체에게 할당
- 워크스페이스 수준에서 선택적으로 SSO 설정
- Principal들에게 권한을 부여하기 위해 Cluster Policies를 정의하는 방법
- 컴퓨팅 리소스 (클러스터/웨어하우스/풀) 정의
- 오케스트레이션 정의 (작업/파이프라인/워크플로우)
- 워크스페이스 수준에서 기능을 켜고/끄기
- 권한을 주체에게 할당
- 데이터 접근 (내부/외부 하이브 메타스토어를 사용할 때)
- 주요 �사용자들의 컴퓨팅 리소스 접근 권한 관리
- Repos와 같은 기능을 위한 외부 URL 관리 (허용 목록 포함)
- 보안 및 데이터 보호 관리
- 팀 간의 실수로 인한 데이터 노출을 방지하기 위해 DBFS를 끄거나 제한
- 데이터 유출을 방지하기 위해 결과 데이터(노트북/DBSQL에서)의 다운로드를 방지하십시오
- 접근 제어 활성화 (워크스페이스 객체, 클러스터, 풀, 작업, 테이블 등)
- 클러스터 수준에서 로그 전달 정의 (즉, 클러스터 로그를 위한 저장소 설정, 이상적으로는 클러스터 정책을 통해)
계정과 워크스페이스 관리자 사이의 차이를 요약하면, 아래 표는 이 두 인물 사이의 몇 가지 주요 차원에 대한 구분을 보여줍니다:
| 계정 관리자 | 메타스토어 관리자 | 워크스페이스 관리자 | |
|---|---|---|---|
| 작업 공간 관리 | - 워크스페이스 생성, 업데이트, 삭제 - 다른 관리자 추가 가능 | 해당 없음 | - 워크스페이스 내의 자산만 관리 |
| 사용자 관리 | - 사용자, 그룹 및 서비스 주체 생성 또는 IDP에서 데이터 동기화를 위해 SCIM 사용. - 권한 할당 API를 사용하여 주체에게 작업 공간 권한 부여 | 해당 없음 | - 모든 데이터 자산(securables)의 중앙 거버넌스를 위해 UC 사용을 권장합니다. Identity Federation은 Unity Catalog (UC) Metastore에 연결된 모든 워크스페이스에 대해 켜져 있을 것입니다. - Identity Federation이 활성화된 워크스페이스의 경우, 모든 Principal에 대해 Account Level에서 SCIM을 설정하고 Workspace Level에서 SCIM을 중지합니다. - UC가 아닌 워크스페이스의 경우, 워크스페이스 레벨에서 SCIM을 설정할 수 있습니다 (하지만 이 사용자들은 계정 레벨의 신원으로 승격될 것입니다). - 워크스페이스 레벨에서 생성된 그룹은 "로컬" 워크스페이스 레벨 그룹으로 간주되며 Unity Catalog에 접근할 수 없습니다 |
| 데이터 접근 및 관리 | - 메타스토어 생성 - 작업 공간을 메타스토어에 연결 - 메타스토어의 소유권을 메타스토어 관리자/그룹에게 이전 | Unity 카탈로그를 사용하여: - 메타스토어의 모든 보안 가능 항목(카탈로그, 스키마, 테이블, 뷰)에 ��대한 권한 관리 - 데이터 스튜어드/소유자에게 카탈로그, 스키마(데이터베이스), 테이블, 뷰, 외부 위치 및 저장소 자격 증명에 대한 접근 권한을 부여(GRANT) | - 오늘날 Hive-metastore(s)를 사용하는 고객들은 AWS의 Instance Profiles, Azure의 Service Principals, Table ACLs, Credential Passthrough 등 다양한 구조를 사용하여 데이터 접근을 보호합니다. -Unity Catalog에서는 이것이 계정 레벨에서 정의되며, ANSI GRANTS는 모든 securables에 대해 ACL을 사용할 것입니다 |
| 클러스터 관리 | 해당 없음 | 해당 없음 | - DE/ML/SQL 사용자를 위한 다양한 인물/크기의 클러스터 생성 - 기본 사용자 그룹에서 클러스터 생성 허용 권한 제거. - 클러스터 정책 생성, 적절한 그룹에 정책 접근 권한 부여 - SQL 웨어하우스에 대한 Can_Use 권한을 그룹에 부여 |
| 워크플로우 관리 | 해당 없음 | 해당 없음 | - 작업/DLT/다목적 클러스터 정책이 존재하고 그룹이 이에 접근할 수 있도록 보장합니다 - 사용자가 재시작할 수 있는 app-purpose 클러스터를 미리 생성합니다 |
| 예산 관리 | - 워크스페이스/스키/클러스터 태그 별로 예산 설정 - 계정 콘솔에서 태그별로 사용량 모니터링 (로드맵) - DBSQL을 통해 쿼리할 수 있는 청구 가능한 사용량 시스템 테이블 (로드맵) | 해당 없음 | 해당 없음 |
| 최적화 / 조정 | 해당 없음 | 해당 없음 | - 최대한의 컴퓨팅 활용; 최신 DBR 사용; Photon 사용 - 인프라 투자를 최대한 활용하고 최적화하기 위해 사업부/엑셀런스 센터 팀과 협력하여 최선의 방법을 따르십시오 |
피크 컴퓨팅 요구를 충족시키기 위해 워크스페이스 크기 조정
클러스터 노드의 최대 수 (간접적으로 가장 큰 작업 또는 동시에 실행할 수 있는 작업의 최대 수)는 VPC에서 사용 가능한 IP의 최대 수에 의해 결정되므로, VPC의 적절한 크기를 결정하는 것은 중요한 설계 고려사항입니다. 각 노드는 2개의 IP를 사용합니다 (Azure, AWS에서). 여기에 선택한 클라우드에 대한 관련 세부 정보가 있습니다: AWS, Azure, GCP. 이를 설명하기 위해 Databricks에서 AWS를 ��예로 들겠습니다. 이것 을 사용하여 CIDR을 IP로 매핑하십시오. E2 작업 공간에 허용된 VPC CIDR 범위는 /25 - /16입니다. 적어도 2개의 다른 가용성 영역에 2개의 개인 서브넷이 구성되어야 합니다. 서브넷 마스크는 /16-/17 사이여야 합니다. VPC는 논리적 격리 단위이며, 2개의 VPC가 서로 통신할 필요가 없다면, 즉, 서로 피어링할 필요가 없다면 동일한 범위를 가질 수 있습니다. 그러나 그렇게 해야 한다면, IP 중복을 피하기 위해 주의해야 합니다. CIDR 범위가 /16인 VPC의 예를 들어 봅시다:
| VPC CIDR /16 | 이 VPC의 최대 # IP: 65,536 | 단일/다중 노드 클러스터가 서브넷에서 구동됩니다 |
| 2개의 AZs | 각 AZ가 /17인 경우 : => 32,768 * 2 = 65,536 IPs 다른 서브넷은 불가능 | 32,768 IP => 각 서브넷에서 최대 16,384 노드 |
| 각 AZ가 /23인 경우 대신: => 512 * 2 = 1,024 IPs 65,536 - 1,024 = 64, 512 IPs 남음 | 512 IP => 각 서브넷에서 최대 256 노드 | |
| 4 AZs | 각 AZ가 /18인 경우: 16,384 * 4 = 65,536 IP, 다른 서브넷은 불가능 | 16,384 IPs => 각 서브넷에서 최대 8192 노드 |
워크스페이스 관리자를 위한 균형잡힌 제어 & 민첩성
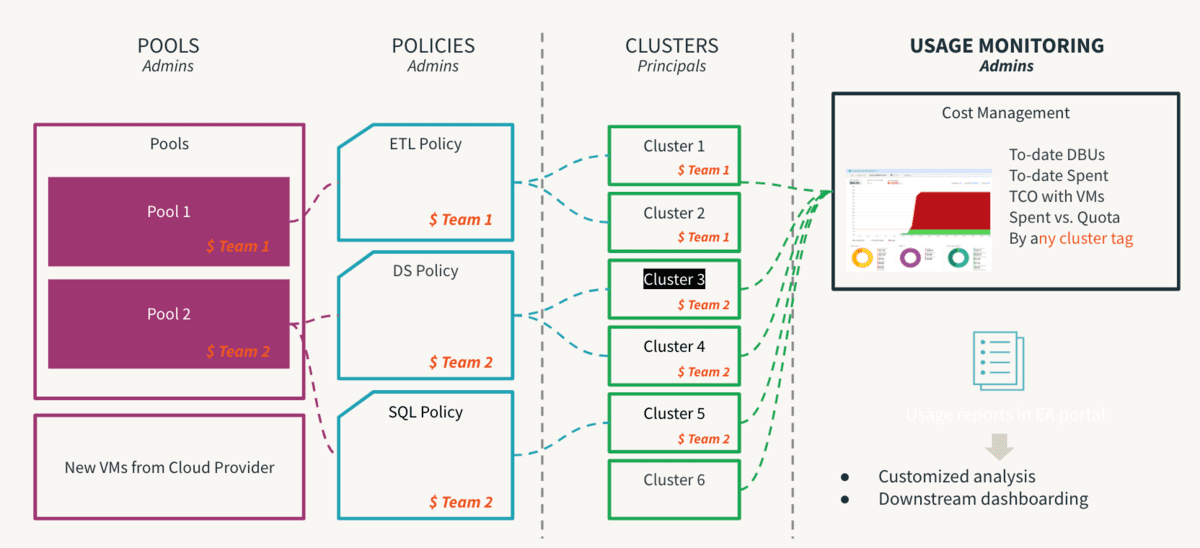
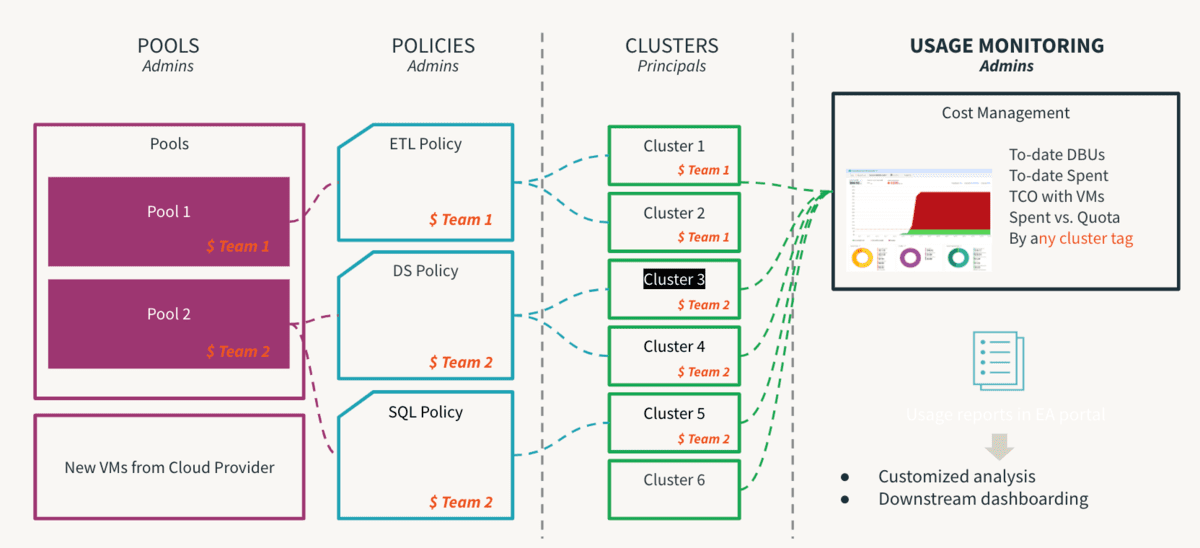
컴퓨팅은 어떤 클라우드 인프라스트럭처 투자에서 가장 비싼 구성 요소입니다. 데이터 민주화는 혁신을 이끌어내며, 자기 서비스를 촉진하는 것은 데이터 중심 문화를 가능하게 하는 첫 단계입니다. 그러나, 다중 테넌트 환경에서는 경험이 부족한 사용자나 실수로 인해 비용이 과도하게 증가하거나 노출될 수 있습니다. 제어가 너무 엄격하면 접근 병목 현상을 만들어 혁신을 억제할 수 있습니다. 그래서 관리자들은 내재된 위험 없이 자기 서비스를 허용할 수 있도록 가드레일을 설정해야 합니다. 또한, 이러한 제어의 준수를 모니터링할 수 있어야 합니다. 이는 클러스터 정책 이 유용하게 사용되는 곳이며, 여기서 규칙이 정의되고 권한이 매핑되어 사용자가 허용된 범위 내에서 작동하고 그들의 의사결정 과정이 크게 단순화됩니다. 정책이 과정에 의해 지원되어야만 진정으로 효과적이라는 점을 명심해야 하며, 일회성 예외는 불필요한 혼란을 피하기 위해 과정에 의해 관리될 수 있어야 합니다. 이 과정의 중요한 단계 중 하나는 사용자가 클러스터 정책에 의해 관리되는 컴퓨팅만을 이용할 수 있도록 기본 사용자 그룹에서 클러스터 생성 허용 권한을 제거하는 것입니다. 다음은 클러스터 정책 모범 사례 의 주요 추천 사항들이며, 아래와 같이 요약할 수 있습니다:
- 표준 클러스터 템플릿을 제공하기 위해 T-셔츠 사이즈 사용
- 작업 부하 크기별로 (소, 중, 대)
- 역할별 (DE/ ML/ BI)
- 숙련도에 따라 (일반 사용자/ 고급 사용자)
- #을 사용하여 거버넌스 관리
- 태그 : 팀, 사용자, 사용 사례별 속성
- 명명은 표준화되어야 합니다
- 일부 속성을 필수 로 설정하면 일관된 보고에 도움이 됩니다
- 태그 : 팀, 사용자, 사용 사례별 속성
- 제한을 통한 소비량 관리
- DBU 소모률 및 정책의 목적
- 자동 종료 시간 초과, 스케일링 최소/최대 크기
컴퓨팅 고려 사항
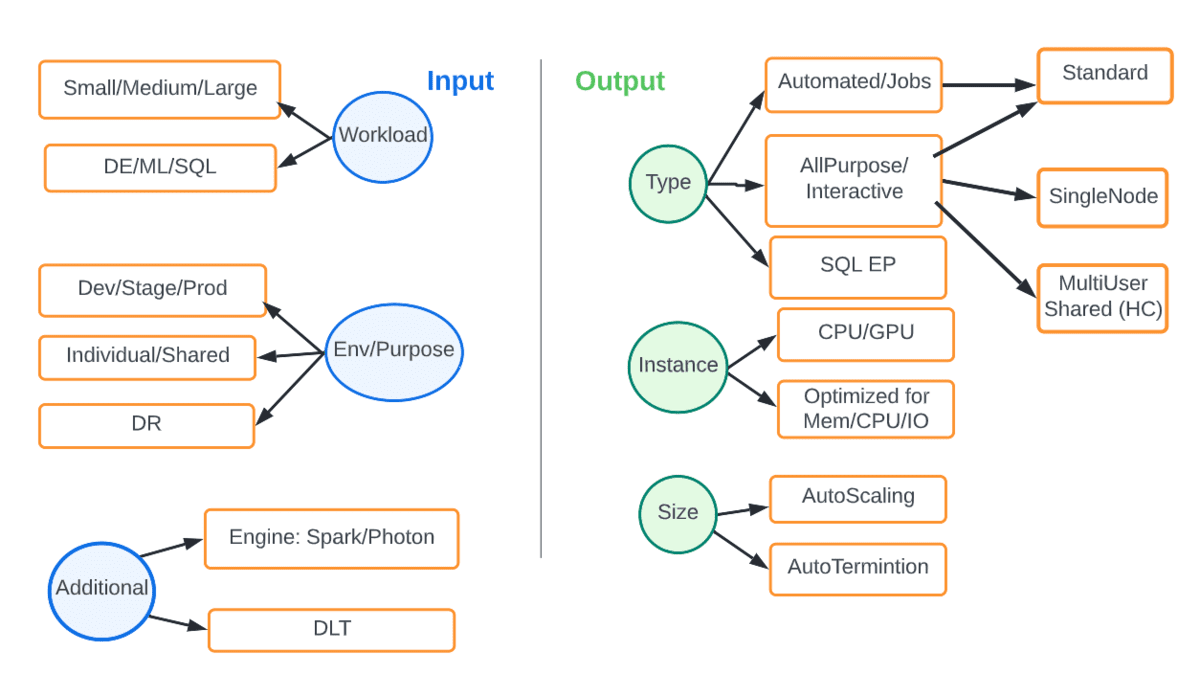
고정된 온프레미스 컴퓨팅 인프라와 달리, 클라우드는 우리에게 탄력성과 유연성을 제공하여 고려 중인 작업 및 SLA에 적합한 컴퓨팅을 매칭할 수 있습니다. 아래 다이어그램은 다양한 옵션을 보여줍니다. 입력값은 작업 유형이나 환경과 같은 매개변수이며 출력값은 가장 적합한 유형과 크기의 컴퓨팅입니다.
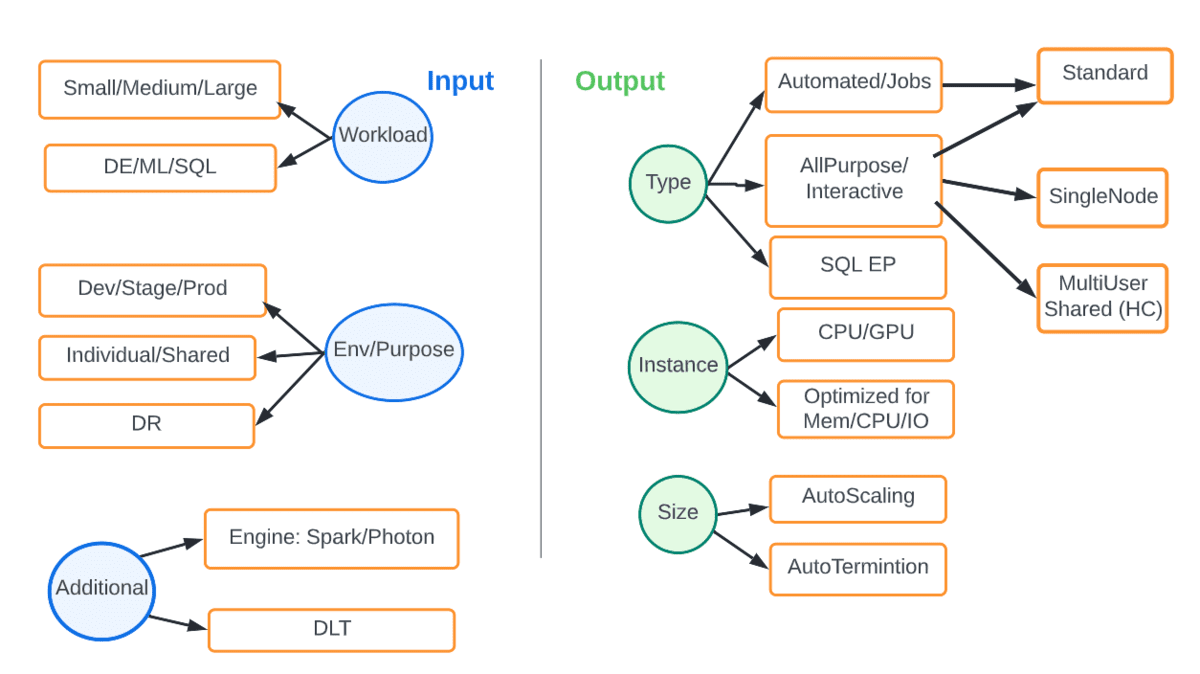
예를 들어, 생산 DE 작업은 항상 최신 DBR을 사용하고, 자동 스케일링을 사용하며, photon 엔진을 사용하는 자동화된 작업 클러스터에서 실행되어야 합니다. 아래 표는 일부 공통 시나리오를 보여줍니다.
워크플로우 고려사항
이제 컴퓨팅 요구 사항이 공식화되었으므로, 우리는 살펴봐야 합니다
- 워크플로우가 어떻게 정의되고 트리거될 것인지
- 작업이 재사용 하여 컴퓨팅을 공유하는 방법
- 작업 의존성이 어떻게 관리될 것인지
- 실패한 작업이 어떻게 재시도될 수 있는지
- 버전 업그레이드 (스파크, 라이브러리) 및 패치 가 적용되는 방법
이들은 사용 사례를 중심으로 한 데이터 엔지니어링 및 DevOps 고려사항이며, 일반적으로 관리자의 직접적인 관심사입니다. 모니터링할 수 있는 일부 위생 작업이 있습니다.
- 워크스페이스에는 구성된 작업의 총 수에 대한 최대 제한 이 있습니다. 그러나 이러한 작업들 중 많은 것들이 호출되지 않고, 실제 작업을 위한 공간을 만들기 위해 정리되어야 합니다. 관리자는 무효한 작업 목록을 결정하기 위해 검사를 실행할 수 있습니다.
- 모든 생산 작업은 서비스 주체 로 실행되어야 하며, 사용자의 생산 환경 접근은 매우 제한되어야 합니다. Jobs permissions을 검토하세요.
- 작업은 실패할 수 있으므로, 모든 작업은 실패 알림을 설정하고 선택적으로 재시도를 위해 설정해야 합니다. 여기에서 email_notifications, max_retries 및 기타 속성을 검토하십시오
- 모든 작업은 클러스터 정책과 함께 연결되어 있어야 하며, 적절하게 태그되어야 합니다.
DLT: 대규모 파이프라인을 안정적으로 관리하는 이상적인 프레임워크의 예
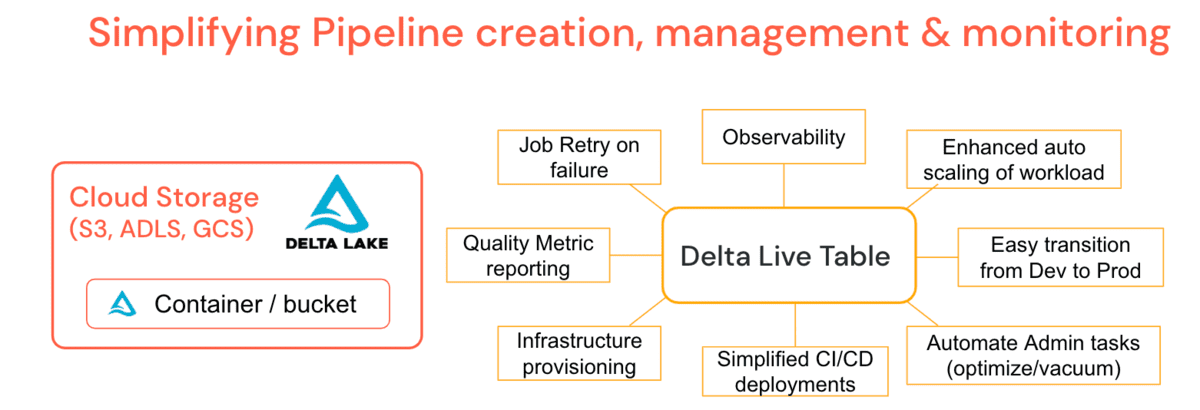
다양한 산업 분야의 수천 개의 크고 작은 고객들과 함께 작업하면서 개발 및 운영화에 대한 공통 데이터 문제가 명확해졌고, 이로 인해 Databricks는 Delta Live Tables (DLT)를 만들었습니다. 이것은 '무엇'을 지정하고 '어떻게'를 지정하지 않는 선언적 파이프라인을 생성할 수 있게 함으로써 ETL 작업 개발 및 유지 관리를 단순화하는 관리 플랫폼 제공입니다. 이것은 데이터 엔지니어의 작업을 단순화하며, 관리자에게 더 적은 지원 시나리오를 제공합니다.
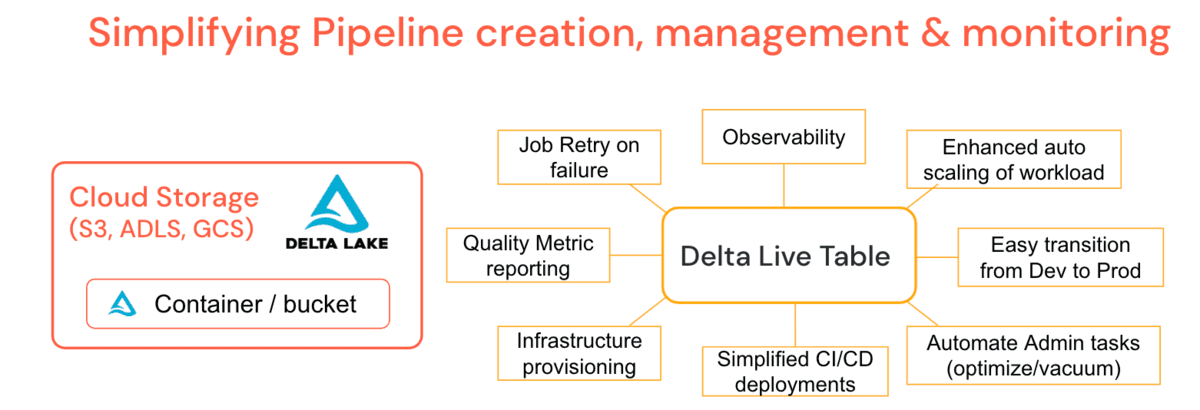
DLT는 주기적인 optimize 및 vacuum 작업과 같은 일반적인 관리 기능을 파이프라인 정의에 직접 통합하며, 추가적인 감독 없이 이들이 실행되도록 보장하는 유지 보수 작업을 포함합니다. DLT는 계보, 모니터링 및 데이터 품질 체크와 같은 간단한 작업을 위한 파이프라인에 대한 깊은 관찰 기능을 제공합니다. 예를 들어, 클러스터가 종료되면 플랫폼은 데이터 엔지니어가 명시적으로 프로비저닝했을 것이라는 가정에 의존하는 대신 자동 재시도 (프로덕션 모드에서)합니다. 향상된 자동 스케일링 은 클러스터의 크기를 늘리고 축소하는 데 필요한 갑작스러운 데이터 폭증을 처리할 수 있습니다. 다시 말해, 자동 클러스터 스케일링 & 파이프라인 장애 허용은 플랫폼 기능입니다. 턴테이블 지연 시간은 배치 또는 스트리밍에서 파이프라인을 실행하고, 구성을 관리함으로써 코드 대신 개발 파이프라인을 상대적으로 쉽게 생산으로 이동시킬 수 있게 해줍니다. DLT 특정 클러스터 정책을 활용하여 파이프라인의 비용을 제어할 수 있습니다. DLT는 또한 자동 업그레이드 를 통해 런타임 엔진을 업그레이드하므로, 관리자나 데이터 엔지니어의 책임을 제거하고 비즈니스 가치 생성에만 집중할 수 있게 합니다.
UC: 이상적인 데이터 거버넌스 프레임워크의 예
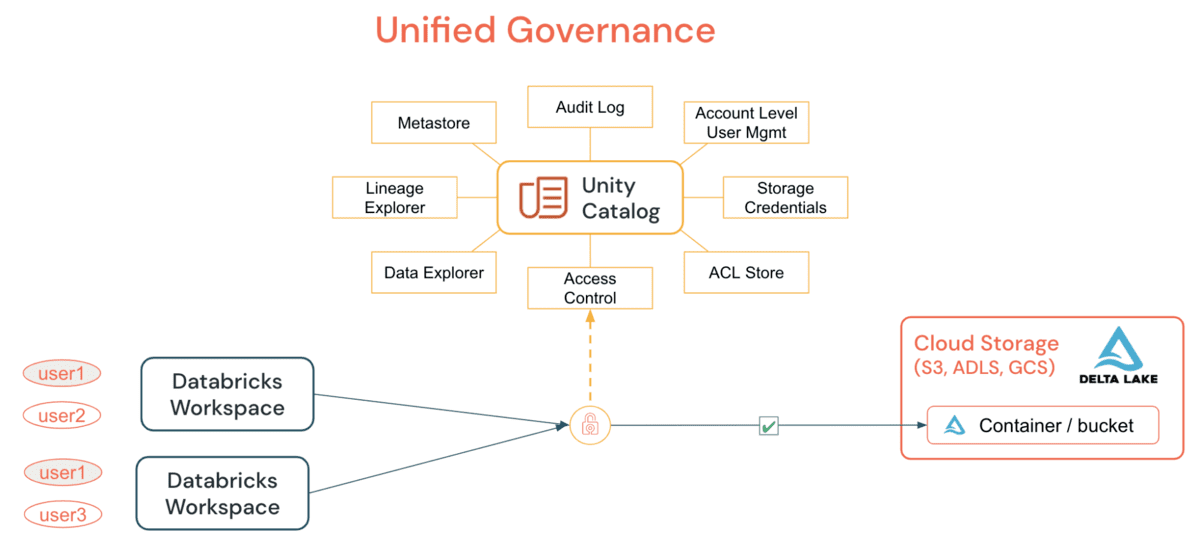
Unity Catalog (UC)는 단순한 GRANT 문을 통해 이전에 불가능했던 모든 워크스페이스에 대한 테이블과 파일에 대한 공통 보안 모델을 채택하는 조직을 가능하게 합니다. DE/DS 클러스터 또는 SQL 웨어하우스에서 데이터, 테이블/또는 파일에 대한 모든 접근을 부여하고 감사함으로써, 조직은 클라우드 기본 요소에 의존하지 않고 감사 및 모니터링 전략을 단순화할 수 있습니다. UC가 제공하는 주요 기능은 다음과 같습니다:
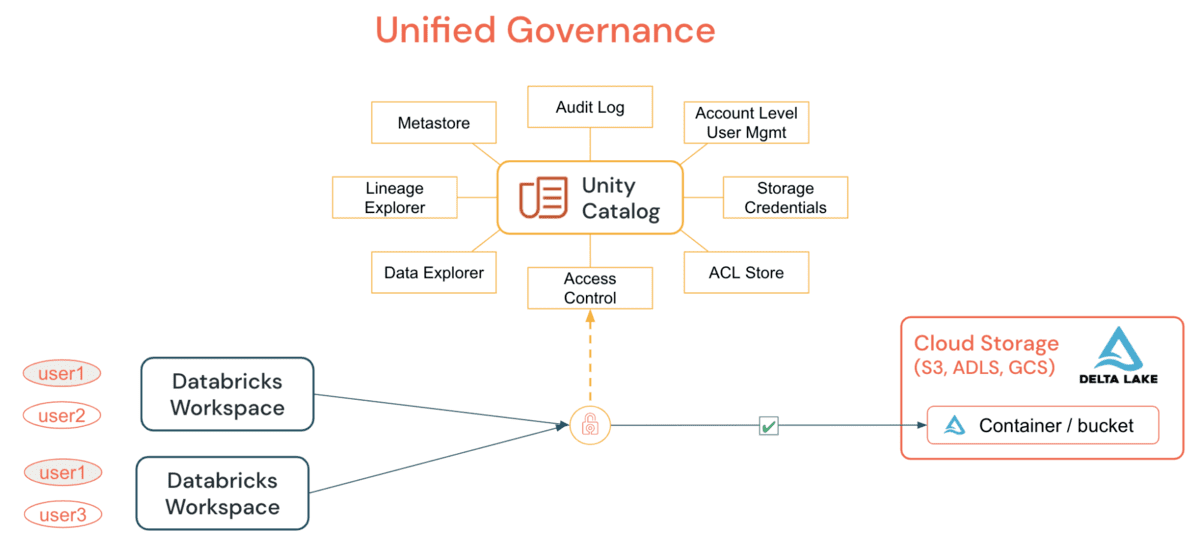
UC는 메타스토어 전반에 걸친 데이터의 정의, 모니터링, 검색 가능성을 중앙화함으로써 관리자(계정 및 워크스페이스 수준 모두)의 작업을 단순화하고, 워크스페이스의 수에 관계없이 데이터를 안전하게 공유하는 것을 쉽게 만듭니다. 한 번 정의하고, 어디서나 안전하게 모델을 활용하면, 사용자의 권한이 한 워크스페이스에서 잘못 표현되어 그들에게 의도하지 않은 데이터에 접근할 수 있는 후문을 제공하는 시나리오에서 실수로 데이터가 노출되는 것을 피할 수 있는 추가적인 이점이 있습니다. 이 모든 것은 계정 수준 신원 과 데이터 권한을 활용함으로써 쉽게 달성할 수 있습니다. UC 감사 로깅 은 모든 객체에 대한 모든 사용자의 모든 수준에서의 모든 행동에 대한 완전한 가시성을 제공하며, 자세한 감사 로깅을 설정하면, 노트북이나 Databricks SQL에서 실행된 각 명령이 캡처됩니다. 보안 가능한 항목에 대한 접근은 메타스토어 관리자, 객체의 소유자, 또는 객체를 포함하는 카탈로그 또는 스키마의 소유자에 의해 부여될 수 있습니다. 계정 수준 관리자가 메타스토어 역할을 위임하여 그룹을 메타스토어 관리자 로 지명하는 것이 권한 부여의 주요 목적이라는 것이 권장됩니다.
추천 사항 및 모범 사례
- 계정 관리자, 메타스토어 관리자 및 워크스페이스 관리자 의 역할과 책임은 잘 정의되어 있고 상호 보완적입니다. 자동화, 변경 요청, 에스컬레이션 등의 워크플로우는 LOB에 의해 설정되거나 중앙 우수성 센터에 의해 관리되는 작업 공간에 관계없이 적절한 소유자에게 흘러야 합니다.
- 계정 수준 신원 이 활성화되어야 합니��다. 이를 통해 모든 워크스페이스에 대한 중앙화된 주체 관리가 가능해져 관리가 단순화됩니다. 계정 수준에서 SSO, SCIM 및 감사 로그 와 같은 기능을 설정하는 것을 권장합니다. SSO 연합 기능이 사용 가능할 때까지 워크스페이스 수준 SSO가 여전히 필요합니다.
- 클러스터 정책 은 효과적인 자체 서비스를 위한 가이드라인을 제공하는 강력한 레버이며, 작업 공간 관리자의 역할을 크게 단순화합니다. 우리는 여기에서 일부 샘플 정책을 제공합니다. 계정 관리자는 주요 인물/티셔츠 크기를 기반으로 한 간단한 기본 정책을 제공해야 하며, 이상적으로는 테라폼과 같은 자동화를 통해 이를 수행해야 합니다. 작업 공간 관리자는 더 세밀한 제어를 위해 해당 목록에 추가할 수 있습니다. 적절한 프로세스와 결합하면, 모든 예외 시나리오를 원활하게 처리할 수 있습니다.
- 모든 워크스페이스에서 모든 작업 유형에 대한 진행 중인 사용량을 계정 관리자가 계정 콘솔을 통해 볼 수 있습니다. 모든 것이 중앙 클라우드 저장소로 전송되어 청구 및 분석을 위해 과금 사용 로그 전달 을 설정하는 것을 권장합니다. Budget API(미리 보기 중)는 계정 수준에서 구성되어야 하며, 이를 통해 계정 관리자는 작업 공간, SKU, 클러스터 태그 수준에서 임계값을 설정하고 소비에 대한 알림을 받을 수 있어, 할당된 예산 내에서 유지할 수 있는 적시 조치를 취할 수 있습니다. Overwatch 와 같은 도구를 사용하여 컴퓨팅 리소스의 활용에 대한 개선 영역을 파악하는 데 도움이 될 수 있도록 더욱 세밀한 수준에서 사용량을 추적합니다.
- Databricks 플랫폼은 계속해서 혁신하고 플랫폼에 일반적인 관리 기능을 추상화함으로써 다양한 데이터 역할의 작업을 단순화합니다. 새 파이프라인에 대해 델타 라이브 테이블 을 사용하고 모든 사용자 관리 및 데이터 접근 제어에 대해 유니티 카탈로그 를 사용하는 것이 우리의 추천입니다.
마지막으로, 이 블로그에서 언급하는 대부분의 것들, 실제로는 이러한 모범 사례 대부분에 대해, 조정과 팀워크는 성공에 있어 중요하다는 것을 주목하는 것이 중요합니다. 이론적으로는 계정 및 워크스페이스 관리자가 독립적으로 존재할 수 있지만, 이는 일반적인 Lakehouse 원칙에 어긋나며 관련된 모든 사람들에게 일을 더 어렵게 만듭니다. 이 글에서 가장 중요하게 가져가야 할 제안은 아마도 귀하의 조직 내에서 계정/작업공간 관리자 + 프로젝트/데이터 리드 + 사용자를 연결하는 것일 것입니다. 팀/슬랙 채널, 이메일 별칭, 주간 미팅 등의 메커니즘이 효과적으로 증명되었습니다. Databricks에서 가장 효과적인 조직은 기술뿐만 아니라 운영에서도 개방성을 받아들이는 조직입니다. 로깅 및 유출 권장 사항부터 관리에 초점을 맞춘 플랫폼 기능의 흥미로운 라운드업에 이르기까지, 곧 더 많은 관리자 중심의 블로그를 기대해 보세요.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}