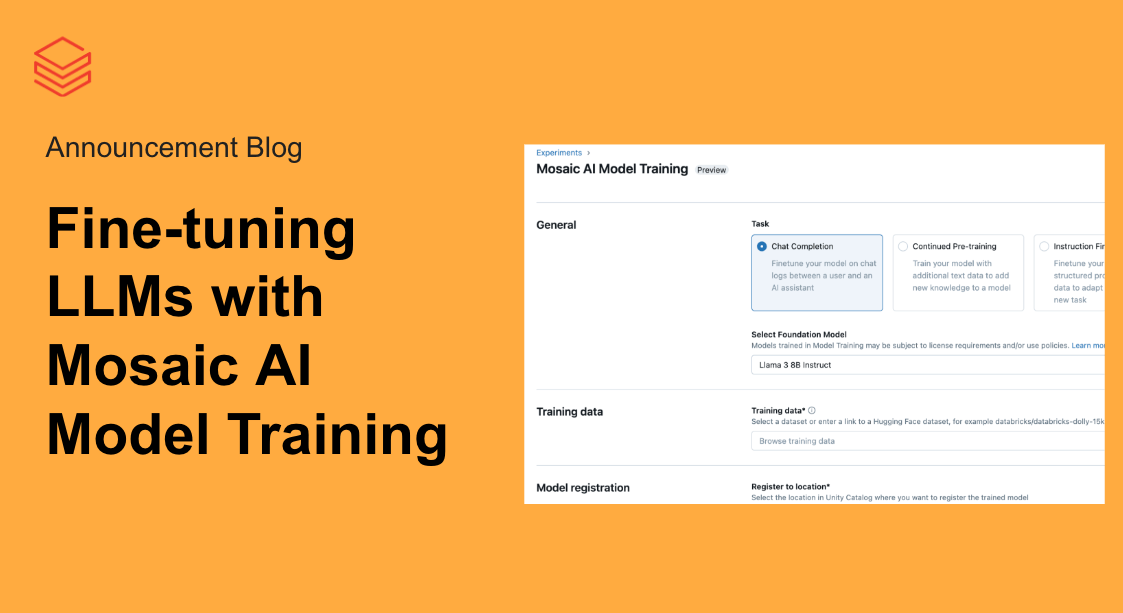
Hugging Face 트랜스포머 파이프라인을 사용한 NLP 시작하기

자연어 처리(NLP)의 발전은 기업이 텍스트 데이터에서 가치를 창출할 수 있는 전례 없는
기회를 열어주었습니다. 자연어 처리는 텍스트 요약, 명명된 엔터티 인식(예: 사람과 장소),
감정 분류, 텍스트 분류, 번역 및 질문 답변. 대부분의 경우 이전에 큰 텍스트 데이터 세트에서
학습된 머신 러닝 모델에서 고품질 결과를 얻을 수 있습니다. 이러한 사전 학습된 모델 중
다수는 오픈 소스에서 사용할 수 있으며 무료로 사용할 수 있습니다.
Hugging Face 는 이러한 모델의 훌륭한 소스 중 하나이며, Transformers 라이브러리는
모델을 적용하고 자신의 데이터에 적용할 수 있는 사용하기 쉬운 도구입니다.
자체 데이터에 대한 미세 조정을 사용하여 이러한 모델을 조정할 수도 있습니다.
예를 들어, 지원 팀이 있는 회사는 사전 학습된 모델을 사용하여 사람이 읽을 수 있는
텍스트 요약을 제공하여 직원이 지원 사례의 주요 문제를 신속하게 평가할 수 있도록
지원할 수 있습니다. 또한 이 회사는 쉽게 사용할 수 있는 기초 모델을 기반으로 세계적
수준의 분류 알고리즘을 쉽게 훈련하여 지원 데이터를 내부 분류로 자동 분류할 수 있습니다.
Databricks는 Hugging Face 트랜스포머를 실행하기 위한 훌륭한 플랫폼입니다.
이전 Databricks 기사에서는 사전 학습된 모델 추론 및 미세 조정을 위한 트랜스포머
사용에 대해 설명했지만, 이 문서에서는 레이크하우스에서 트랜스포머로 작업할 때
성능과 사용 편의성을 최적화하기 위해 이러한 모범 사례를 통합합니다.
이 문서에는 이러한 모범 사례에 대한 설명과 함께 인라인 코드 샘플이 포함되어 있으며,
Databricks는 미리 학습된 모델 추론 및 미세 조정을 위한 완전한 노트북 예제도 제공합니다.
사전 학습된 모델 사용
감정 분석 및 텍스트 요약과 같은 많은 애플리케이션의 경우 사전 학습된 모델은 추가 모델
학습 없이도 잘 작동합니다. 🤗 트랜스포머 파이프라인은 텍스트에 대한 추론에 필요한
다양한 구성 요소를 간단한 인터페이스로 래핑합니다.
많은 NLP 작업의 경우 이러한 구성 요소는 토크나이저와 모델로 구성됩니다.
파이프라인은 모범 사례를 인코딩하므로 쉽게 시작할 수 있습니다.
예를 들어 파이프라인을 사용하면 사용 가능한 경우 GPU를 쉽게 사용할 수 있으며
처리량을 높이기 위해 GPU로 전송된 항목을 배치할 수 있습니다.
Spark에서 유추를 배포하려면 Databricks는 pandas UDF에 파이프라인을
캡슐화하는 것이 좋습니다. Spark는 브로드캐스트를 사용하여 pandas UDF에
필요한 모든 개체를 작업자 노드로 효율적으로 전송합니다.
또한 Spark는 GPU를 작업자에 자동으로 재할당하므로
다중 GPU 다중 머신 clusters 원활하게 사용할 수 있습니다.
다음은 밴드 Energy Orchard에 대한 Wikipedia 기사의 스냅샷에 대한 샘플 요약입니다. Wikipedia 마크업을 요약자에 전달하기 전에 정리하지 않았습니다.


이 섹션에서는 Hugging Face Transformers를 사용하여 Databricks에서 대규모로 텍스트를 처리하는 것이 얼마나 쉬운지 보여주었습니다.
다음 섹션에서는 이러한 모델의 성능을 추가로 조정할 수 있는 방법에 대해 설명합니다.
튜닝 성능
UDF의 성능 조정에는 두 가지 주요 측면이 있습니다. 첫 번째는 각 GPU를
효과적으��로 사용하려고 한다는 것인데, 트랜스포머 파이프라인에서 GPU로
보내는 항목의 배치 크기를 변경하여 조정할 수 있습니다.
두 번째는 전체 clusters활용하기 위해 데이터 프레임이 잘 분할되어 있는지 확인하는 것입니다.
UDF는 1 배치 로 즉시 작동해야 합니다. 그러나 이는 작업자가 사용할 수 있는
리소스를 효율적으로 활용하지 못할 수 있습니다. 성능을 향상시키려면
사용 중인 모델 및 하드웨어에 맞게 배치 크기를 조정할 수 있습니다.
Databricks는 최상의 성능을 찾기 위해 clusters 의 파이프라인에 대해
다양한 배치 크기를 시도하는 것이 좋습니다. 파이프라인 배치 및
기타 성능 옵션 에 대한 자세한 내용은 Hugging Face 설명서를 참조하세요.
"GPU당 사용률" 또는 "GPU당 메모리 사용률(%)"과 같은 에 대한 라이브
메트릭을 확인하여 GPU 성능을 모니터링할 수 있습니다.clusters
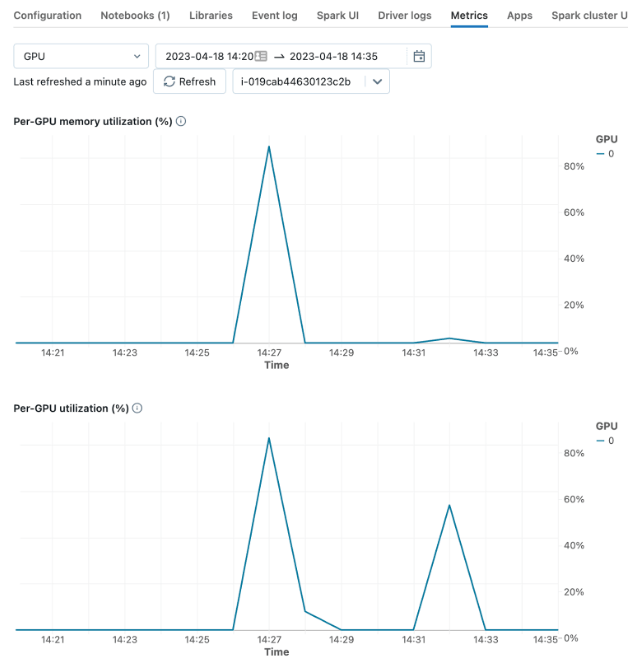
배치 크기를 튜닝하는 목표는 전체 GPU 사용률을 구동하지만 "CUDA 메모리 부족" 오류가
발생하지 않도록 충�분히 크게 설정하는 것입니다. clusters하드웨어를 잘 활용하려면
Spark DataFrame을 다시 분할해야 할 수 있습니다. 일반적으로 워커의 GPU 수
(GPU clusters의 경우) 또는 clusters 의 워커 전체의 코어 수(CPU clusters의 경우)의
배수가 실제로 잘 작동합니다. UDF를 사용하는 것은 Spark에서 다른 UDF를 사용하는 것과
동일합니다. 예를 들어 select 문에서 사용하여 모델 유추 결과가 포함된 열을 만들 수 있습니다.
미리 빌드된 모델을 MLflow 모델로 래핑
미리 학습된 모델을 MLflow 모델로 저장하면 배치 또는 실시간 유추를 위해
모델을 훨씬 더 쉽게 배포할 수 있습니다. 또한 Model Registry를 통해
모델 버전 관리를 허용하고 추론 워크로드에 대한 모델 로드 코드를 간소화합니다.
첫 번째 단계는 모델 로드, GPU 사용량 초기화 및 추론 함수를 캡슐화하는
파이프라인에 대한 사용자 지정 모델을 만드는 것입니다.
이 코드는 위에서 설명한 pandas_udf 만들고 사용하기 위한 코드와 매우 유사합니다.
한 가지 차이점은 파이프라인이 MLflow 모델의 컨텍스트에서 사용할 수 있는 파일에서
로드된다는 것입니다. 이는 모델을 로깅할 때 MLflow에 제공됩니다.
Hugging Face 트랜스포머 파이프라인을 사용하면 모델을 드라이버의 로컬 파일에
쉽게 저장할 수 있으며, 이 파일은 MLflow pyfunc 인터페이스의 log_model 함수로 전�달됩니다.
MLflow 모델을 사용한 배치 유추
MLflow는 기록되거나 등록된 모델을 Spark UDF에 로드하는 쉬운 인터페이스를 제공합니다. Model Registry 또는 로깅된 Experiment 실행 UI에서 모델 URI를 조회할 수 있습니다.
Transformers Trainer를 사용하여 🤗 단일 머신에서 모델 미세 조정
사전 학습된 모델이 즉시 요구 사항을 충족하지 못하는 경우가 있으며 자체 데이터에서 모델을
미세 조정해야 합니다. 예를 들어 지원 티켓을 지원 팀의 온톨로지로 분류하는 기초 모델을
기반으로 텍스트 분류자를 만들거나 데이터에 대한 사용자 지정 스팸 분류자를 만들 수 있습니다.
모델을 미세 조정하기 위해 Databricks를 종료할 필요가 없습니다. 적당한 크기의 데이터 세트의
경우 GPU를 지원하는 단일 컴퓨터에서 이 작업을 수행할 수 있습니다.
Hugging Face transformers Trainer 공공 설비/유틸리티를 사용하면
모델 훈련을 매우 쉽게 설정하고 수행할 수 있습니다.
더 큰 데이터 세트의 경우 Databricks는 분산 다중 머신 다중 GPU 딥 러닝도 지원합니다.
프로세스는 GPU를 지원하는 단일 머신 clusters 만들고,
데이터 세트를 준비하여 드라이버에 다운로드하고,
Trainer를 사용하여 모델 학습을 수행하고, 결과 모델을 MLflow에 기록하는 것입니다.
데이터 준비 및 다운로드
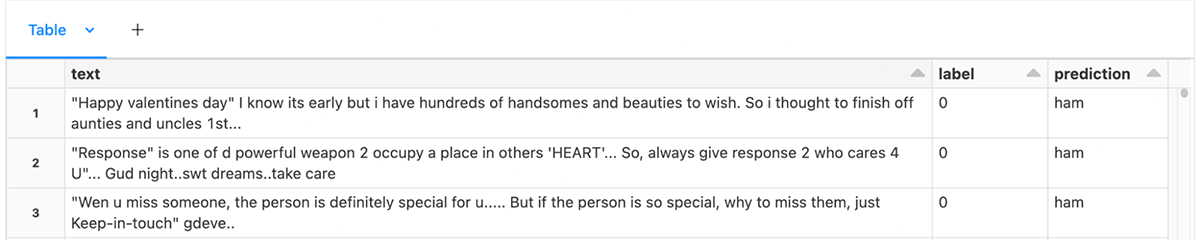
먼저 트레이너의 기대에 부응하는 테이블로 훈련 데이터를 형식화합니다.
텍스트 분류의 경우, 이 테이블은 두 개의 열, 즉 텍스트 열과 레이블 열이 있는
테이블입니다. 예제 노트북 에서는 일부 문자 메시지 스팸 데이터를 로드합니다.

Hugging Face 트랜스포머는 AutoModelForSequenceClassification을 텍스트
분류를 위한 모델 로더로 제공하며, 정수 ID를 범주 레이블로 예상합니다.
그러나 정수 레이블에서 문자열 레이블로, 또는 그 반대로 매핑도 지정해야 합니다.
문자열 레이블이 있는 DataFrame이 있는 경우 다음과 같이 이 정보를 수집할 수 있습니다.
그런 다음 정수 ID를 레이블 열로 만듭니다. pandas_udf:
데이터를 학습/테스트로 분할합니다.
그런 다음 데이터세트 공공 설비/유틸리티를 사용하여 교육 및 평가 데이터 세트를
만들 수 있습니다. DBFS 캐시 디렉터리를 지정하면 데이터 세트를 효율적으로
다운로드하여 나중에 다시 사용할 수 있습니다.
모델은 다운로드한 데이터의 텍스트가 아닌 토큰화된 입력을 예상합니다.
기본 모델과의 호환성을 보장하려면 기본 모델에서 로드된 AutoTokenizer를 사용합니다.
HuggingFace 데이터세트를 사용하면 토크나이저를 학습 및 테스트 데이터 모두에 일관되게 직접 적용할 수 있습니다.
트레이너 구성
Trainer 클래스에는 사용자가 메트릭, 기본 모델 및 학습 구성을 제공해야 합니다.
default트레이너는 손실을 compute 하고 메트릭으로 사용하는데, 이는 해석이
쉽지 않습니다. 다음은 모델 학습 중에 정확도를 추가로 compute 메트릭 함수를
만드는 예입니다.
텍스트 분류의 경우 AutoModelForSequenceClassification 을 사용하여 텍스트 분류를 위한
기본 모델을 불러옵니다. 여기서는 클래스 수와 레이블 매핑을 제공합니다.
마지막으로 학습 구성을 만들어야 합니다. 이 TrainingArguments 클래스를 사용하면
출력 디렉토리, 평가 전략, 학습률 및 기타 지정할 수 있습니다 parameter.
학습 및 평가 데이터 세트에서 데이터 대조기 배치 입력 사용Using a data collator 배치
input in training and evaluation dataset. DataCollatorWithPadding default 와
함께 사용하면 텍스트 분류에 대한 좋은 기준 성능을 얻을 수 있습니다.
이러한 parameter 모두 구성되었으므로 이제 트레이너를 만들 수 있습니다.
모델 학습 실행 및 로깅Running training and logging the model
Hugging Face는 MLflow와 원활하게 상호 작용하여 MLflowCallback을 사용하여
모델 학습 중에 메트릭을 자동으로 로깅합니다. 그러나 학습된 모델을 직접
기록해야 합니다. 위의 예제와 마찬가지로 Databricks는 학습된 모델을 변환기
파이프라인에 래핑하고 MLflow의 pyfunc log_model 기능을
사용하는 것이 좋습니다. 이렇게 하려면 사용자 지정 모델 클래스가 필요합니다.
mlflow 실행에서 학습을 래핑하고, 토크나이저 및 학습된 모델에서 변환기 파이프라인을
생성하고, 로컬 디스크에 씁니다. 마지막으로 MLflow에 모델을 기록합니다.
유추를 위해 모델을 로드하는 것은 MLflow 래핑된 미리 학습된 모델을 로드하는 것과 같습니다.
이 섹션에서는 Hugging Face Transformer Trainer APIs 직접 사용하여 새로운 텍스트
분류 문제에 맞게 모델을 미세 조정하는 방법을 설명했습니다. 광범위한 작업을 위해 더 많은
NLP 모델을 미세 조정할 수 있으며 자연어 처리를 위한 AutoModel 클래스 는 훌륭한
기반을 제공합니다.
결론
이 블로그 게시물에서는 몇 가지 모범 사례를 시연하고 Databricks에서 NLP 작업에
트랜스포머를 사용하는 것이 얼마나 쉬운지 보여주었습니다.
추론을 위해 회수해야 할 핵심 사항은 다음과 같습니다.
- 🤗 트랜스포머 파이프라인을 사용하면 트랜스포머 모델을 쉽게 사용할 수 있습니다.
- 전체 clusters활용하기 위해 필요한 경우 데이터를 다시 분할합니다.
- GPU를 효율적으로 사용하기 위해 배치 크기를 조정할 수 있습니다.
- Spark는 다중 머신 GPU clusters에서 GPU를 자동으로 할당합니다.
- Pandas UDF는 모델 브로드캐스팅 및 배치 데이터를 관리하고,
- 파이프라인은 MLflow에 대한 로깅 변환기 모델을 간소화합니다.
단일 머신 모델 학습에 대해 기억해야 할 핵심 사항:
- 🤗 트랜스포머 트레이너는 모델을 미세 조정할 수 있는 접근 가능한 방법을 제공합니다.
- Spark에서 데이터 세트를 준비하고, 모델링 작업에 필요한 경우 레이블을 id에 매핑하고,
토큰화는 Transformers에 🤗 맡깁니다. - 드라이버의 파일 시스템에서 데이터 세트를 사용할 수 있도록 합니다.
- AutoTokenizer를 사용하여 데이터세트를 토큰화하여 모델에 적합한
토크나이저를 로드합니다. - Trainer를 사용하�여 미세 조정을 수행하고,
- 토크나이저와 미세 조정된 모델에서 파이프라인을 구성하고,
- 파이프라인을 래핑하는 사용자 지정 모델을 사용하여 MLflow에 모델을 기록합니다.
Databricks는 Databricks에서 모델 학습 및 추론을 확장하는 더 간단한 방법에
계속 투자하고 있습니다. 데이터 로드, 분산 모델 학습, 트랜스포머 파이프라인 및
모델을 MLflow 모델로 저장🤗에 대한 개선 사항을 계속 지켜봐 주세요.
이러한 예제를 시작하려면 사전 학습된 모델을 사용하고
미세 조정하기 위해 이러한 노트북을 가져옵니다.