깊이 알아보기: 행 수준 동시성이 어떻게 기본적으로 작동하는지
Liquid Clustering을 사용하여 자동 동시 충돌 해결을 사용하십시오
Summary
- Databricks 행 수준 동시성은 동시 쓰기와 유지 관리 작업이 있는 고객들에게 상자 밖에서 동시성 보장을 제공합니다.
- 전통적인 동시성 방법들, 예를 들어 재시도 루프와 파티셔닝은 사용하기 어렵고, 쿼리 시간과 비용을 증가시킬 수 있습니다.
- 오늘 Liquid Clustering을 사용하여 행 수준 동시성의 이점을 누리기 시작하십시오.
Liquid Clustering 은 데이터 레이아웃 관련 결정을 크게 단순화하는 혁신적인 데이터 관리 기법입니다. 당신은 단지 쿼리 접근 패턴에 기반한 클러스터링 키를 선택하면 됩니다. 수천명의 고객들이 Liquid Clustering을 통해 더 나은 쿼리 성능을 경험했고, 우리는 이제 월 활성 고객 3000명 이상 이 매월 200+ PB 데이터 를 Liquid 클러스터링된 테이블에 쓰는 것을 보고 있습니다.
여러 작성자를 관리하기 위해 아직도 파티셔닝을 사용하고 있다면, Liquid Clustering의 주요 기능인 행 수준 동시성을 놓치고 있는 것입니다.
이 블로그 포스트에서는 Databricks가 어떻게 사용자에게 동시성 보장을 제공하는지 그리고 테이블에 동시 수�정이 있는 고객들에게 이를 어떻게 제공하는지 설명하겠습니다. 행 수준 동시성을 사용하면 복잡한 데이터 레이아웃을 설계하거나 작업 부하를 조정할 필요 없이 비즈니스 인사이트를 추출하는 데 집중할 수 있습니다. 이는 코드와 데이터 파이프라인을 단순화합니다.
Liquid Clustering을 사용하면 행 수준 동시성이 자동으로 활성화됩니다. 또한 Databricks Runtime 14.2+를 사용할 때 삭제 벡터 와 함께 활성화됩니다. ConcurrentAppendException 또는 ConcurrentUpdateException으로 자주 실패하는 동시 수정이 있는 경우, 오늘 테이블에서 Liquid Clustering 또는 삭제 벡터를 활성화 하여 행 수준 충돌 감지를 하고 충돌을 줄이십시오. 시작하는 것은 간단합니다:
행 수준 동시성이 동일한 파일을 수정하는 동시 쓰기를 어떻게 자동으로 처리하는지에 대한 자세한 내용을 읽어보십시오.
전통적인 접근법: 관리하기 어렵고 오류가 발생하기 쉽습니다
동시 쓰기는 여러 프로세스, 작업, 또는 사용자가 동시에 같은 테이블에 쓰기를 수행할 때 발생합니다. 다중 스트림에서 지속적으로 쓰기가 이루어지는 경우, 다양한 파이프라인이 테이블에 데이터를 삽입하는 경우, 또는 GDPR 삭제와 같은 백그라운드 작업이 이루어지는 경우 등에서 이러한 상황이 흔하게 발생합니다. 유�지 관리 작업을 관리하는 것은 더욱 번거롭습니다 - 비즈니스 작업 부하 주변에 OPTIMIZE를 스케줄링해야 합니다.
Delta Lake는 낙관적 동시성 제어를 사용하여 이러한 작업 중 데이터 무결성을 보장합니다. 이는 쓰기 사이의 트랜잭션 보장을 제공합니다. 이는 두 쓰기가 충돌하면 하나만 성공하고 다른 하나는 커밋에 실패한다는 것을 의미합니다.
이 예를 고려해 보겠습니다: 두 개의 다른 출처에서 온 두 작성자, 예를 들어 미국과 영국의 판매,가 동시에 글로벌 판매 수량 테이블에 병합을 시도합니다. 이 테이블은 date 에 의해 파티션되어 있습니다 - 이는 대규모 데이터셋을 관리하는 고객들로부터 보이는 일반적인 파티셔닝 패턴입니다. 미국에서의 판매가 streamA로 테이블에 쓰여지고, 영국에서의 판매가 streamB로 쓰여진다고 가정해 봅시다.
여기서, streamA 가 먼저 커밋을 스테이징하고 streamB 가 같은 파티션을 수정하려고 시도하면, Delta Lake은 두 스트림이 실제로 다른 행을 수정하더라도 streamB의 쓰기를 커밋 시간에 동시 수정 예외로 거부합니다. 이는 파티션된 테이블에서 충돌이 파티션의 세분화 수준에서 감지되기 때문입니다. 결과적으로, streamB에서의 쓰기는 손실되고 많은 계산이 낭비됩니다.
이러한 충돌을 처리하기 위해, 고객들은 재시도 루프를 사용하여 작업 부하를 재설계할 수 있으며, 이는 streamB의 쓰기를 다시 시도합니다. 그러나, 재시도 로직은 커밋이 성공할 때까지 동일한 쓰기를 반복적으로 시도함으로써 작업 응답 시간과 계산 비용을 증가 시킬 수 있습니다. 적절한 균형을 찾는 것은 까다롭습니다—재시도 횟수가 너무 적으면 실패 위험이 있고, 너무 많으면 비효율성과 높은 비용을 초래합니다.
또 다른 접근법은 더 세밀한 파티셔닝이지만, 특히 여러 팀이 같은 테이블에 쓰기를 할 때, 더 세밀한 테이블 파티션을 관리하여 쓰기를 격리하는 것은 어렵습니다. 적절한 파티션 키를 선택하는 것은 어렵고, 모든 데이터 패턴에 대해 파티셔닝이 작동하지 않습니다. 게다가, 파티셔닝은 유연하지 않습니다 - 변화하는 작업 부하에 적응하기 위해 파티셔닝 키를 변경할 때 전체 테이블을 다시 작성해야 합니다.
이 예에서, 고객들은 테이블을 다시 작성하고 date 와 country 모두에 의해 파티션을 나눌 수 있지만, 이는 작은 파일 문제를 일으킬 수 있습니다. 이런 상황은 일부 국가에서 많은 양의 판매 데이터를 생성하는 반면, 다른 국가에서는 매우 적게 생성하는 데이터 패턴에서 흔하게 발생합니다.
Liquid Clustering 은 이러한 ��작은 파일 문제를 모두 피하면서, 행 수준 동시성은 행 수준에서 동시성을 보장하며, 이는 분할보다도 더 세밀하고 유연합니다. 행 수준 동시성이 어떻게 작동하는지 살펴보겠습니다!
행 수준 동시성이 어떻게 자동으로, 손쉽게 동시 충돌 해결을 제공하는지
행 수준 동시성은 Databricks 런타임에서 쓰기 충돌을 행 수준에서 감지하는 혁신적인 기술입니다. Liquid 클러스터링 테이블의 경우, 이 기능은 MERGE, UPDATE, DELETE와 같은 수정 작업 간의 충돌을 자동으로 해결합니다. 이 작업들이 동일한 행을 읽거나 수정하지 않는 한 말이죠.
또한, 삭제 벡터가 활성화된 모든 테이블 - Liquid 클러스터링 테이블을 포함하여, OPTIMIZE 및 REORG와 같은 유지 관리 작업 이 다른 쓰기 작업에 방해되지 않도록 보장합니다. 이제 더 이상 동시 쓰기 작업 부하를 설계하는 것에 대해 걱정할 필요가 없습니다. 이로 인해 Databricks에서의 작업 부하가 더욱 단순해집니다.
우리의 예를 사용하면, 행 수준 동시성을 사용하면 두 스트림 모두 판매 데이터에 대한 수정 사항을 커밋할 수 있습니다. 이는 동일한 행을 수정하지 않는 한, 행이 동일한 파일에 저장되어 있더라도 가능합니다.
행 수준 동시성의 비하인드: 작동 원리
이것은 어떻게 작동하나요? Databricks 런타임은 커밋 시간 동안 동시 수정을 자동으로 조정합니다. 이는 Delta Lake의 기능인 삭제 벡터 (DV)와 행 추적을 사용하여 각 트랜잭션에서 수행된 변경 사항을 추적하고 수정 사항을 효율적으로 조정합니다.
우리의 예시를 사용하면, 새로운 판매 데이터가 테이블에 쓰여질 때, 새로운 데이터는 새로운 데이터 파일에 삽입되며, 이전 행은 원본 파일을 다시 쓸 필요 없이 삭제 벡터를 사용하여 삭제로 표시됩니다. 파일 수준으로 확대하여, 행 수준 동시성이 삭제 벡터와 어떻게 작동하는지 살펴봅시다.
예를 들어, 우리는 네 개의 행, row 0 부터 row 3 까지 있는 file A 를 가지고 있습니다. Transaction 1 (T1)이 streamA 에서 row 3 를 file A에서 삭제하려고 합니다. Databricks Runtime은 file A 를 다시 작성하는 대신, file A의 삭제 벡터에서 row 3 를 삭제된 것으로 표시합니다. 이는 DV for A로 표시됩니다.
이제 트랜잭션 2 (T2)가 streamB에서 들어옵니다. 이 트랜잭션이 row 0을 삭제하려고 한다고 가정해 봅시다. 삭제 벡터를 사용하면, File A 는 변경되지 않습니다. 대신, 이제 A의 DV가 row 0 이 삭제되었다는 것을 추적합니다. 행 수준 동시성이 없다면, 이것은 트랜잭션 1과 충돌을 일으킬 것 입니다. 왜냐하면 둘 다 같은 파일이나 삭제 벡터를 수정하려고 시도하기 때문입니다.
행 수준 동시성을 사용하면, Databricks Runtime의 충돌 감지는 두 거래가 다른 행에 영향을 미친다는 것을 확인합니다. 논리적 충돌이 없으므로, Databricks Runtime은 두 거래에서의 삭제 벡터를 결합하여 같은 파일에서의 동시 수정을 조정할 수 있습니다.
이러한 모든 혁신으로 인해, Databricks는 열린 Delta Lake 형식에서 행 수준 동시성을 제공하는 유일한 레이크하우스 엔진을 가지고 있습니다. 다른 엔진들은 자체 형식에서 잠금을 채택하며, 이는 대기열 생성과 느린 쓰기 작업을 초래하거나, 동시 쓰기를 위해 번거로운 파티션 기반 동시성 방법에 의존해야 합니다.
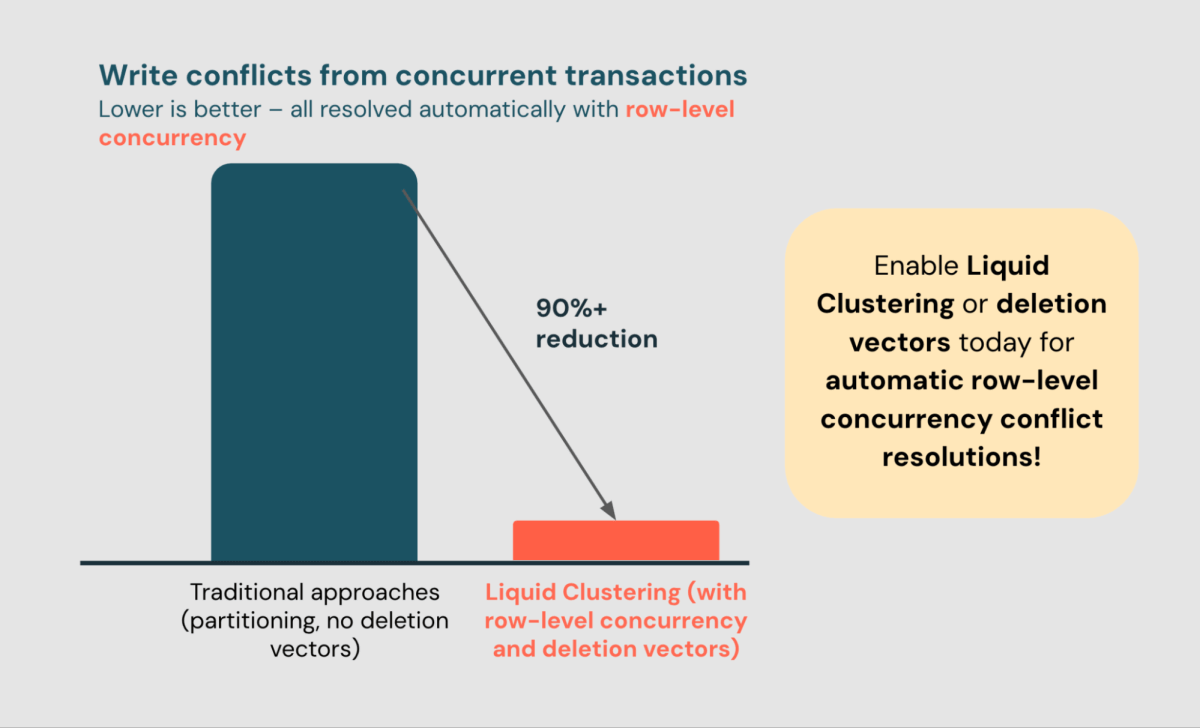
지난 해 동안, 행 수준 동시성은 6,500+ 고객들 이 110B+ 충돌 을 자동으로 해결하는 데 도움을 주었으며, 쓰기 충돌을 90% 이상 줄였습니다 (나머지 충돌은 같은 행을 건드리는 것에 의해 발생합니다).
지금 시작해 보세요!
행 수준 동시성은 Databricks Runtime 13.3+에서 Liquid Clustering 와 함께 자동으로 활성화됩니다. 별도의 설정이 필요 없습니다! Databricks Runtime 14.2+에서는 또한 삭제 벡터 가 활성화된 모든 비파티션 테이블에서 기본적으로 활성화됩니다.
만약 당신의 작업 부하가 이미 Liquid Clustering을 사용하고 있다면, 모든 것이 준비되어 있습니다! 그렇지 않다면, Liquid Clustering을 채택하거나, 행 수준 동시성의 이점을 활용하기 위해 파티션되지 않은 테이블에 삭제 벡터 를 활성화하세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)

