Iceberg 호환성을 제공하는 Delta Lake Universal Format (UniForm)의 정식 출시(GA)
하나의 레이크, 모든 포맷: Delta Lake UniForm은 모든 요구 사항에 대한 데이터 관리를 간소화합니다

Delta Lake는 수년 동안 가장 인기 있고 가장 빠른 레이크하우스 포맷으로 입증되었습니다. 이제 정식 출시된 Delta Lake Universal Format(UniForm)은 Delta Lake의 풍부한 커넥터 에코시스템을 기반으로 뛰어난 가격 대비 성능과 스택의 모든 툴에 대한 액세스를 결합한 것입니다. Delta Lake UniForm을 사용하면 데이터의 단일 복사본을 작성하여 리눅스 재단 Delta Lake, Apache Iceberg, Apache Hudi(곧 출시 예정) 등 주요 오픈 테이블 포맷을 지원하는 모든 엔진에서 사용할 수 있습니다: . 이 블로그에서는 다음 내용을 다룹니다:
- Delta Lake UniForm으로 오픈 데이터 레이크하우스 구축하기
- 모든 엔진에서 빠른 성능 확보
- Liquid Clustering과 같은 Delta Lake의 고급 기능을 Delta Lake UniForm과 함께 사용
오픈 레이크하우스 구축
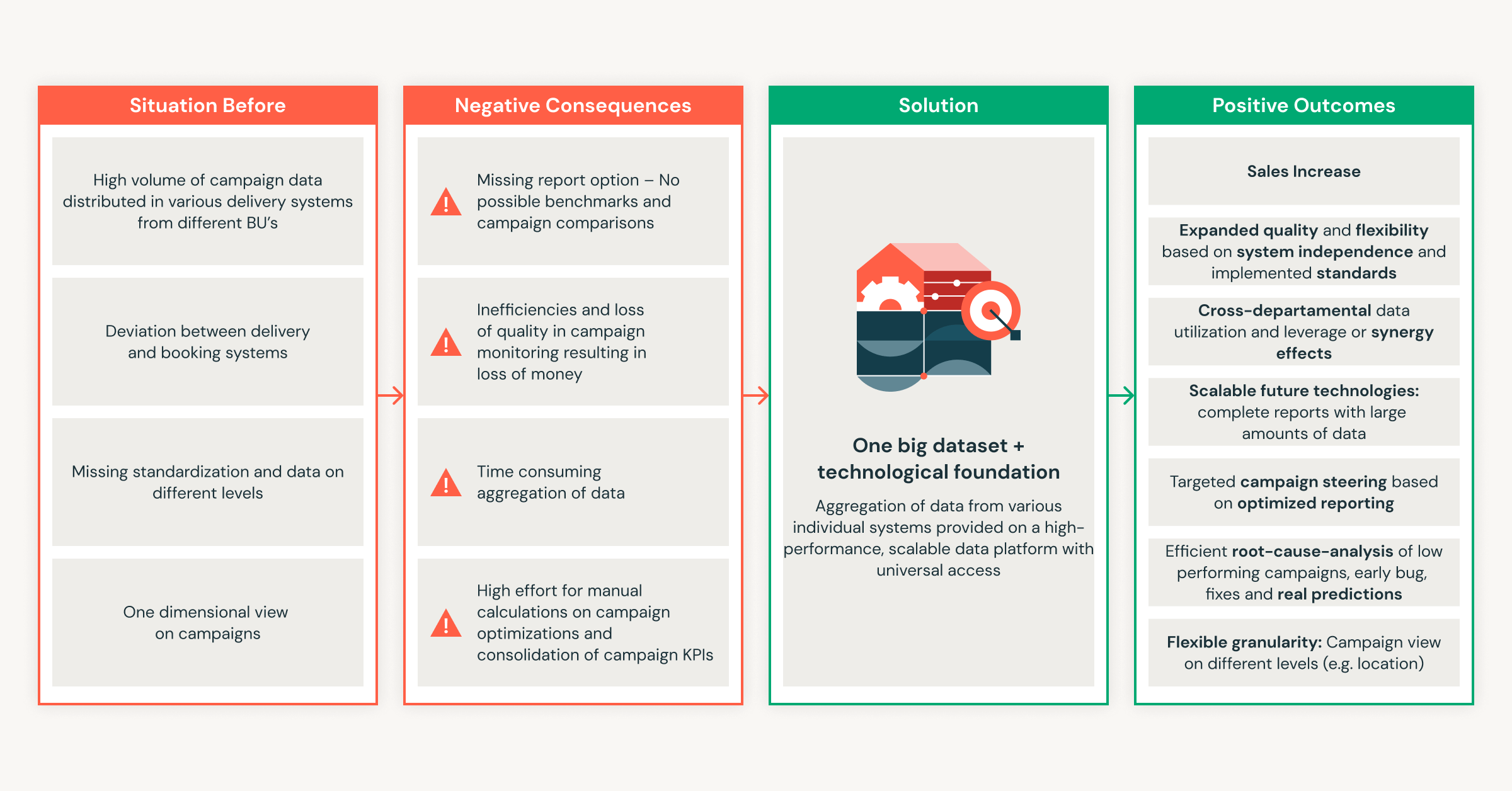
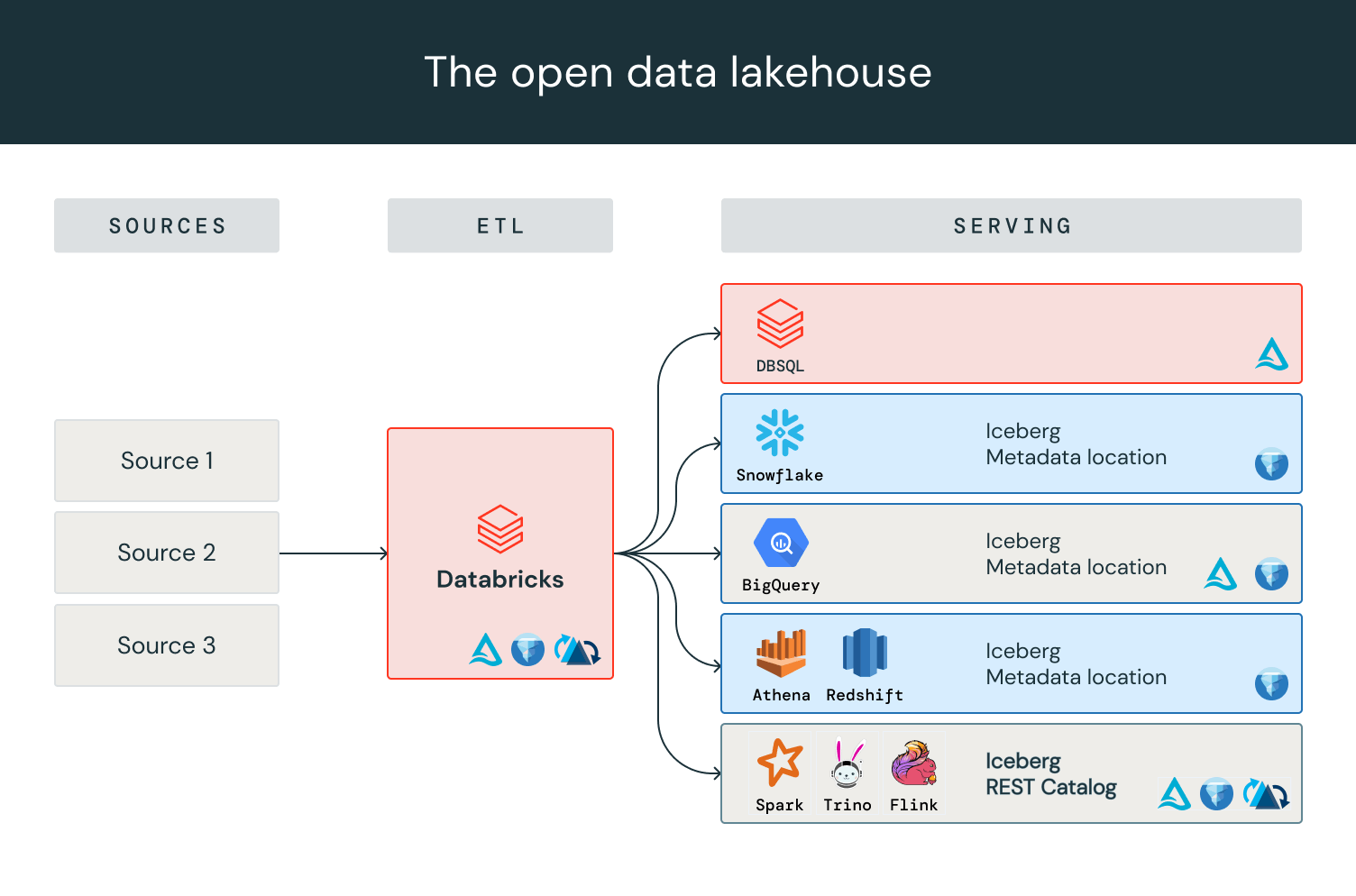
Delta Lake는 많은 인기 오픈 소스 프레임워크와 상용 엔진의 지원을 통해 활기찬 커넥터 에코시스템을 제공합니다. UniForm��은 세 가지 오픈 테이블 형식 간의 고유한 유사성을 활용하여 Delta Lake의 생태계를 확장합니다. Delta Lake, Iceberg, Hudi는 모두 Apache Parquet 파일 형식으로 데이터를 저장하지만, 추가 메타데이터를 저장하는 방식은 다릅니다. Delta Lake UniForm은 Parquet 파일의 단일 복사본을 유지하면서 Delta Lake와 함께 Iceberg 메타데이터를 생성합니다. Delta Lake UniForm에 한 번만 쓰면 개방형 포맷 중 하나를 지원하는 모든 엔진을 사용해 데이터에 액세스할 수 있습니다:
Delta Lake UniForm을 사용하면 워크로드에 가장 적합한 도구를 선택할 수 있습니다. Delta Lake UniForm을 사용하면 현재 또는 미래에 어떤 아키텍처를 선택하든 지원할 수 있는 데이터 유연성을 확보할 수 있습니다.
어디서나 빠른 성능 제공
개방형 테이블 형식을 수용하는 플랫폼이 늘어나면서 값비싼 데이터 복제 없이 더 광범위한 도구에 액세스할 수 있는 Delta Lake UniForm으로 데이터를 기록할 수 있습니다. 따라서 기존에 독점적인 포맷으로 저장된 데이터에 대한 유연성이 향상되고 비용도 절감됩니다. Delta Lake UniForm을 사용하면 데이터브릭스의 동급 최고의 수집 및 ETL 가격 대비 성능을 활용하고 스택에 있는 모든 데이터 웨어하우징 또는 BI 도구와 연결할 수 있습니다. 이러한 비용 절감은 다운스트림 쿼리 성능의 저하 없이 실현할 수 있습니다.
아래 벤치마크는 데이터브릭스를 사용하여 Parquet 파일을 Delta Lake UniForm으로 수집하는 성능과 Snowflake를 사용하여 Iceberg로 수집하는 성능을 비교한 것입니다.
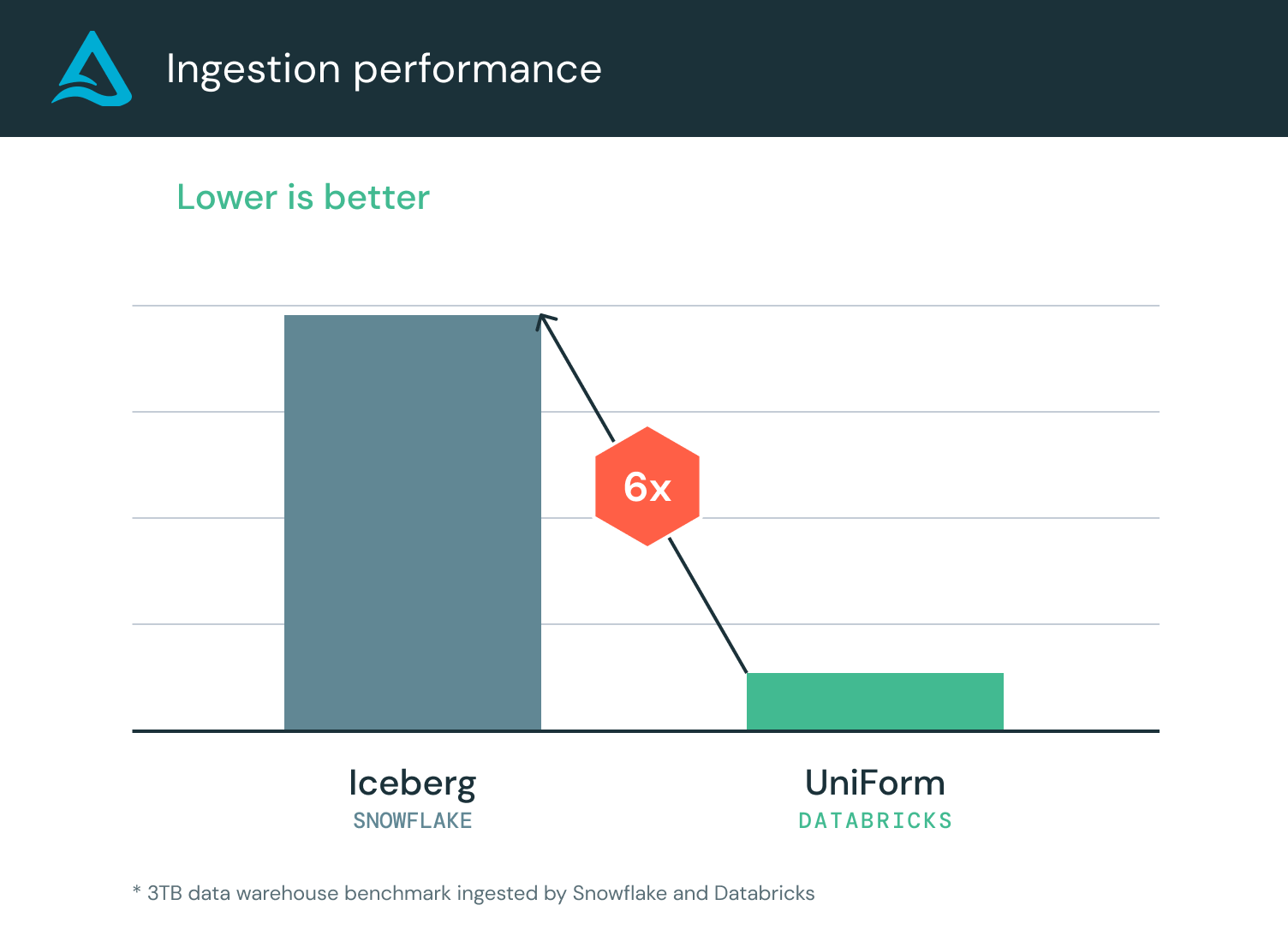
데이터브릭스는 Snowflake보다 6배 더 빠르게 Parquet 데이터를 수집했습니다. 또한 데이터브릭스는 Snowflake보다 90% 더 저렴했습니다. Delta Lake UniForm은 Delta 와 Iceberg 메타데이터를 모두 쓰기 때문에, 테이블은 Snowflake에서 계속 액세스할 수 있습니다. Snowflake에서는 Iceberg 카탈로그 통합을 사용하여 Delta Lake UniForm을 읽을 수 있습니다. 카탈로그 통합을 사용하면 외부 Iceberg 카탈로그 또는 객체 스토리지를 참조하여 Snowflake에서 Iceberg 테이블을 만들 수 있습니다. 벤치마크에 따르면 Delta Lake UniForm의 기본 제공 읽기 성능은 Snowflake 관리형 Iceberg와 비슷합니다:
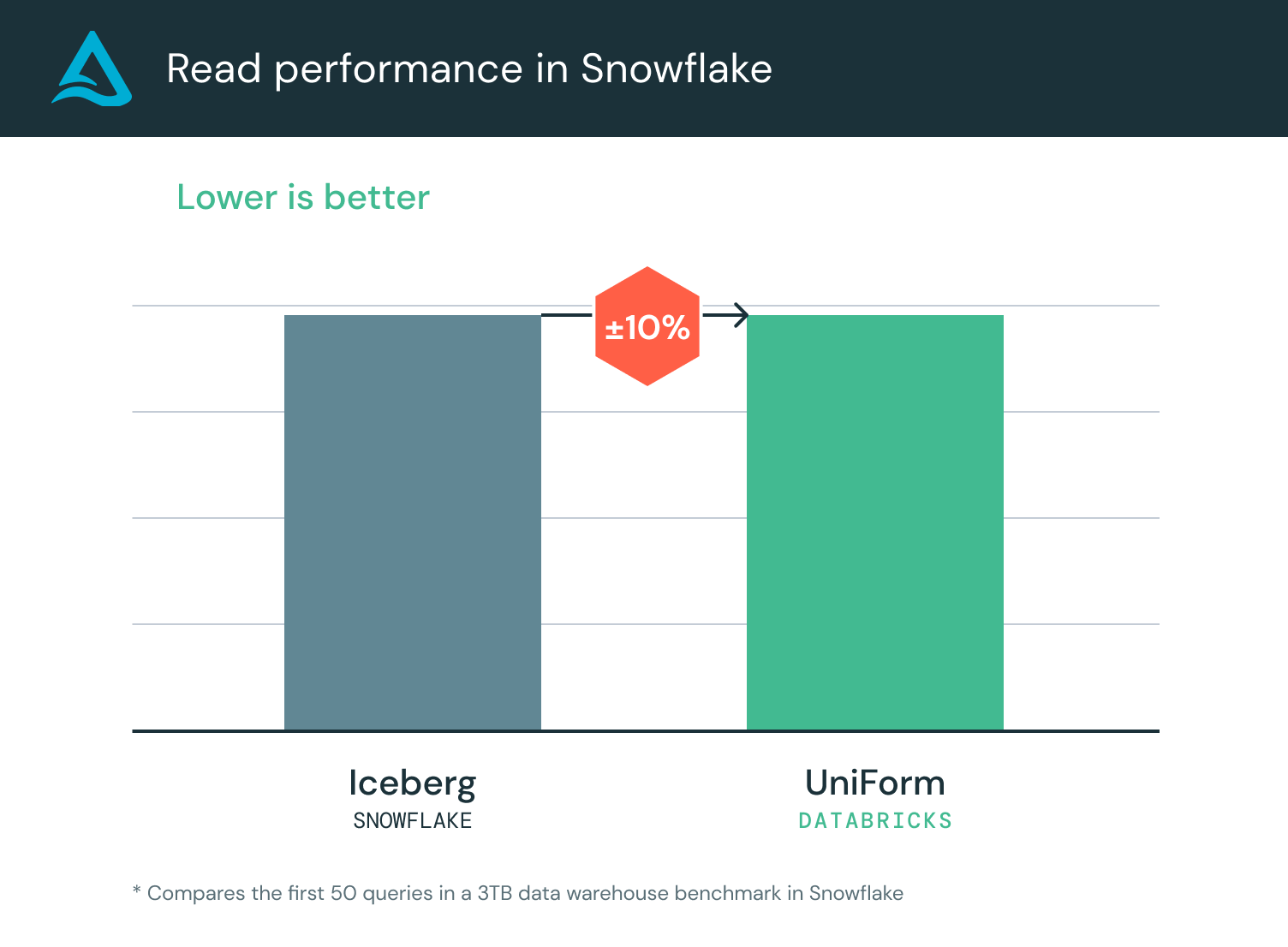
쿼리 성능의 차이는 거의 제로에 가깝습니다! Delta Lake UniForm을 사용하면 자체 스토리지 버킷에 있는 단일 데이터 사본에서 가장 빠른 성능과 범용 연결성을 모두 누릴 수 있습니다!
모든 형식의 장점을 누릴 수 있는 Delta Lake UniForm
Delta Lake UniForm을 작성할 때, Delta Lake의 고급 테이블 기능을 계속 활용할 수 있습니다. 예를 들어, 이제 공개 미리 보기에서 사용할 수 있는 새로운 기능인 Liquid Clustering을 사용해 Delta Lake UniForm을 델타 테이블에서 활성화할 수 있습니다. Liquid Clustering은 델타 테이블을 동적으로 클러스터링하는 지능형 데이터 관리 기법으로, 분석 요구 사항에 따라 데이터 레이아웃을 발전시킬 수 있습니다.
Delta Lake UniForm과 Liquid Clustering은 함께 사용되어 Iceberg나 Hudi 엔진에서 읽을 때에도 빠른 쿼리 성능을 제공합니다. 이는 Liquid Clustering이 물리적 데이터 레이아웃을 최적화할 때, Delta Lake와 Iceberg 메타데이터 모두에 이러한 개선 사항을 반영하기 때문에 가능합니다. Delta Lake UniForm은 추가 메타데이터만 쓰기 때문에 쓰기 오버헤드는 미미합니다. 또한, 수집 중에 새로운 데이터를 자동으로 클러스터링하므로 시간이 지나도 쿼리 성능이 빠르게 유지됩니다.
고객들의 Delta Lake UniForm 사용 사례
공개 프리뷰 기간 동안, 조직들은 다양한 BI 및 분석 사용 사례에서 Snowflake, BigQuery, Redshift, Athena를 비롯한 인기 있는 Iceberg 리더 클라이언트와의 호환성을 입증했습니다.
이제 Delta Lake UniForm이 정식 출시되어 프로덕션 워크로드에 사용할 수 있습니다. 데이터브릭스에서는 이미 고객들이 UniForm 사용의 이점을 체감하기 시작했습니다:
M Science에서 UniForm은 Delta 또는 Iceberg를 지원하는 모든 엔진에서 쿼리할 수 있는 단일 데이터 사본을 작성할 수 있는 유연성을 제공하며, 이는 비용 절감과 가치 실현 시간 단축의 핵심 요소입니다.
-- Ben Tallman, 최고 기술 책임자, M Science

고객과 상용 소프트웨어 공급업체가 단순성, 유연성, 저렴한 비용을 위해 개방형 레이크하우스 아키텍처를 선택하는 것을 보게 되어 기쁘게 생각합니다. GA 이후에도 사용자가 에코시스템의 모든 도구를 사용할 수 있도록 Delta Lake UniForm의 상호 운용성과 원활성을 높이기 위해 지속적으로 투자할 것입니다.
Delta Lake 3.2 릴리즈의 일부로 새로운 Delta Lake UniForm 기능을 사용할 수 있습니다. 데이터브릭스 고객은 데이터브릭스 런타임 버전 14.3으로 업그레이드하여 이러한 기능을 사용할 수 있습니다.
아래 링크에서 사용핫는 Iceberg 리더에서 Delta Lake UniForm을 읽는 방법에 대해 자세히 알아볼 수 있습니다:
- Snowflake (Push Method, Pull Method)
- BigQuery
- Apache Spark
- Trino
(번역: Youngkyong Ko) Original Post