Apache Spark의 새로운 프로그래밍 언어인 영어를 소개합니다

개요
우리는 Spark 환경을 더욱 풍부하게 만들어주는 혁신적인 도구인 Apache Spark용 영문 SDK를 공개하게 되어 기쁘게 생각합니다. 208개 국가 및 지역에서 연간 10억 건 이상의 다운로드를 기록하며 전 세계적으로 사랑받고 있는 Apache Spark™는 대규모 데이터 분석을 크게 발전시켰습니다. 생성형 AI의 혁신적인 적용을 통해, 저희 영문 SDK는 그 어느 때보다 사용자 친화적이고 접근하기 쉬운 Spark를 만들어 이 활기찬 커뮤니티를 확장하고자 합니다!
동기부여
GitHub Copilot은 AI 지원 코드 개발 분야에 혁명을 일으켰습니다. 강력하지만 사용자가 생성된 코드를 이해해야 커밋할 수 있습니다. 리뷰어 역시 코드를 이해해야만 리뷰할 수 있습니다. 이는 광범위한 채택을 제한하는 요인이 될 수 있습니다. 또한 특히 Spark 테이블 및 데이터프레임을 다룰 때 컨텍스트와 관련하여 어려움을 겪기도 합니다. 첨부된 GIF는 이 점을 잘 보여주는데, Copilot은 window specification을 제안하면서 존재하지 않는 'dept_id' 열을 참조하는데, 이를 이해하려면 약간의 전문 지식이 필요합니다.

AI를 부조종사(copilot)로 대하는 대신 AI를 운전기사로 삼고 우리는 고급스러운 뒷좌석에 앉는 건 어떨까요? 바로 여기에 영어 SDK가 등장합니다. 지난 10년 동안 API 문서, 오픈 소스 프로젝트, 질문과 답변, 튜토리얼, 서적 등 수많은 고품질의 공개 콘텐츠를 제공한 훌륭한 Spark 커뮤니티 덕분에 최첨단 대규모 언어 모델이 Spark를 잘 알고 있다는 것을 알게 되었습니다. 이제 우리는 Spark에 대한 생성형 AI의 전문 지식을 영어 SDK에 담았습니다. 복잡한 생성 코드를 이해할 필요 없이 많은 사람이 이해할 수 있는 간단한 영어 지침으로 결과를 얻을 수 있습니다:
Spark 테이블과 데이터프레임에 대한 이해를 갖춘 영어 SDK는 복잡성을 처리하여 데이터프레임을 직접 올바르게 반환합니다!
우리의 여정은 영어를 프로그래밍 언어로 사용한다는 비전에서 시작되었으며, 생성형 AI는 이러한 영어 instruction을 PySpark 및 SQL 코드로 컴파일합니다. 이 혁신적인 접근 방식은 프로그래밍의 장벽을 낮추고 learning curve을 단순화하도록 설계되었습니다. 이러한 비전이 영어 SDK의 원동력이며, 우리의 목표는 Spark의 범위를 넓혀 이 매우 성공적인 프로젝트를 더욱 성공적으로 만드는 것입니다.
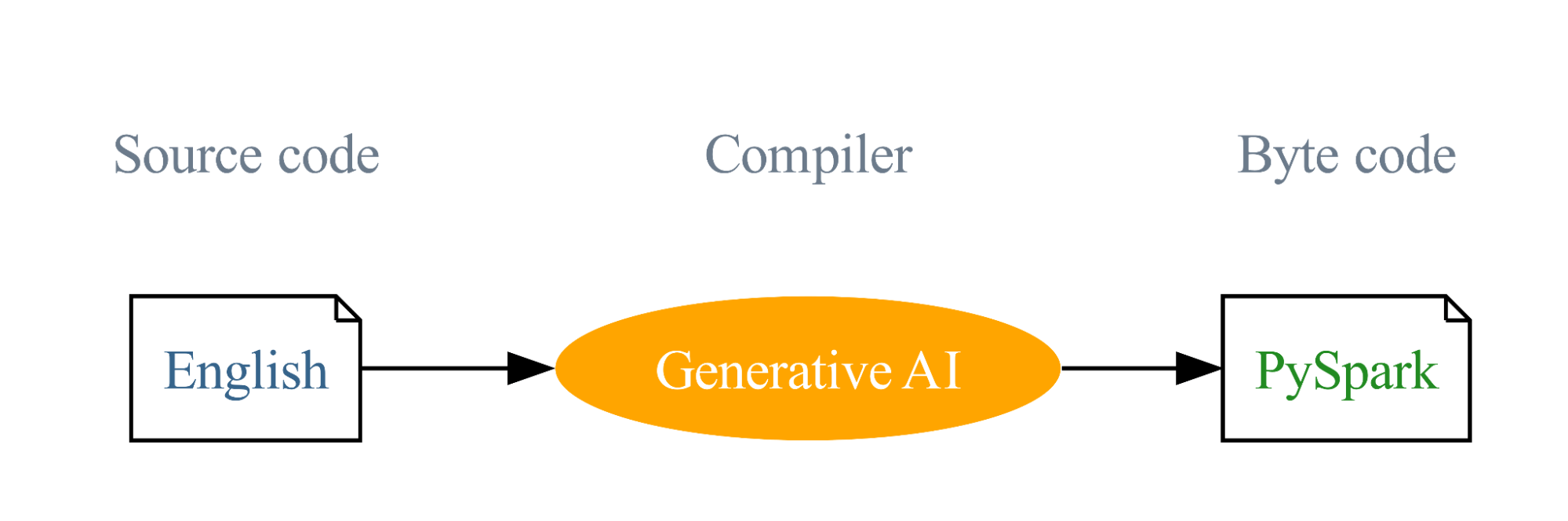
영어 SDK의 기능들
영문 SDK는 다음과 같은 주요 기능을 제공하여 Spark 개발 프로세스를 간소화합니다:
- 데이터 Ingestion: SDK는 제공된 설명을 사용하여 웹 검색을 수행하고, LLM을 활용하여 가장 적합한 결과를 결정한 다음, 선택한 웹 데이터를 Spark에 원활하게 통합할 수 있으며, 이 모든 과정을 한 번에 완료할 수 있습니다.
- 데이터프레임 작업: SDK는 주어진 데이터프레임에 대해 영어 설명을 기반으로 변환, 그래프 그리기 및 설명을 할 수 있는 기능을 제공합니다. 이러한 기능은 코드의 가독성과 효율성을 크게 향상시켜 데이터프레임에 대한 작업을 간단하고 직관적으로 만들어 줍니다.
- 사용자 정의 함수 (UDFs): SDK는 간소화된 UDF 생성 프로세스를 지원합니다. 간단한 데코레이터를 사용하면 문서 문자열만 제공하면 AI가 코드 완성을 처리합니다. 이 기능은 UDF 생성 프로세스를 간소화하여 사용자는 함수 정의에만 집중하고 나머지는 AI가 알아서 처리하도록 합니다.
- 캐싱: SDK는 캐싱을 통합하여 실행 속도를 높이고, 재현 가능한 결과를 만들고, 비용을 절감합니다.
예시
영어 SDK가 어떻게 사용되는지 알아보려면 다음의 예시를 함께 보시기 바랍니다:
데이터 Ingestion
만약 당신이 2022년 미국 전국 자동차 판매량을 수집해야 하는 데이터 과학자라면, 단 두 줄의 코드로 이 작업을 수행할 수 있습니다.:
데이터프레임 작업
데이터프레임 df가 주어지면 SDK를 사용하면 df.ai로 시작하는 메서드를 실행할 수 있습니다. 여기에는 변환, 그래프 그리기, 데이터프레임 설명 등이 포함됩니다.
PySpark 데이터프레임의 부분 함수를 활성화하기:
`auto_df`의 그래프를 보기:
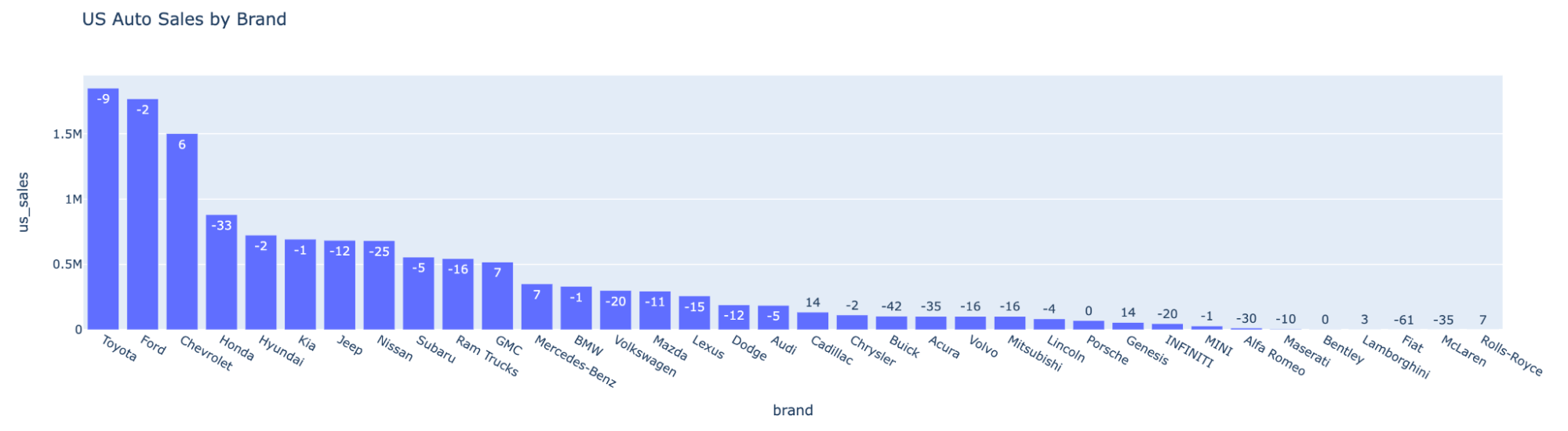
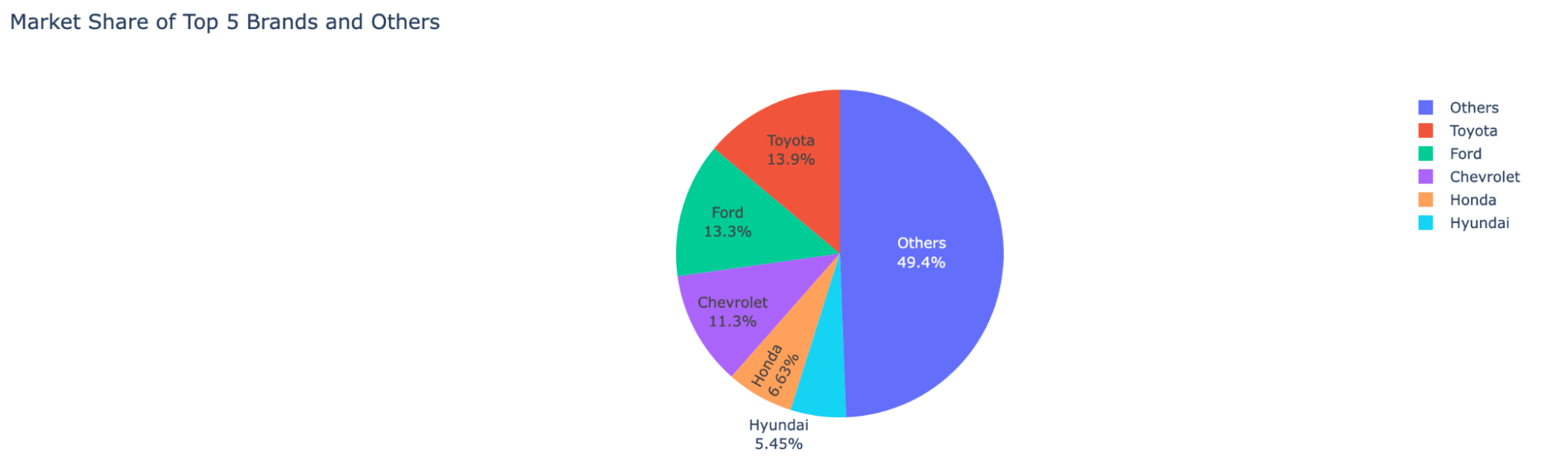
자동차 회사별 시장 점유율 분포 보기:
가장 높은 성장률을 기록한 브랜드 확인하기:
| brand |
us_sales_2022 |
sales_change_vs_2021 |
|
Cadillac |
134726 |
14 |
데이터프레임에 대한 설명 확인:
In summary, this DataFrame is retrieving the brand with the highest sales change in 2022 compared to 2021. It presents the results sorted by sales change in descending order and only returns the top result.
사용자 정의 함수 (UDFs)
SDK는 간단하고 깔끔한 UDF 생성 프로세스를 지원합니다. @spark_ai.udf 데코레이터를 사용하면 문서 문자열로 함수를 선언하기만 하면 SDK가 백그라운드에서 자동으로 코드를 생성합니다:
이제 여��러분은 SQL 쿼리나 데이터프레인에서 사용자 정의 함수를 사용할 수 있습니다
결론
Apache Spark용 영문 SDK는 개발 프로세스를 크게 향상시킬 수 있는 매우 간단하면서도 강력한 도구입니다. 복잡한 작업을 간소화하고, 필요한 코드의 양을 줄이며, 데이터에서 인사이트를 도출하는 데 더 집중할 수 있도록 설계되었습니다.
영어 SDK는 아직 개발 초기 단계에 있지만, 그 잠재력이 매우 기대됩니다. 이 혁신적인 도구를 살펴보고, 이점을 직접 경험하고, 프로젝트에 기여하는 것을 고려해 보시기 바랍니다. 혁명을 지켜보는 데 그치지 말고 혁명의 일부가 되어보세요. 지금 바로 pyspark.ai에서 영어 SDK의 강력한 기능을 살펴보고 활용하세요. 여러분의 인사이트와 참여는 영문 SDK를 개선하고 Apache Spark의 접근성을 확장하는 데 매우 귀중한 도움이 될 것입니다.

