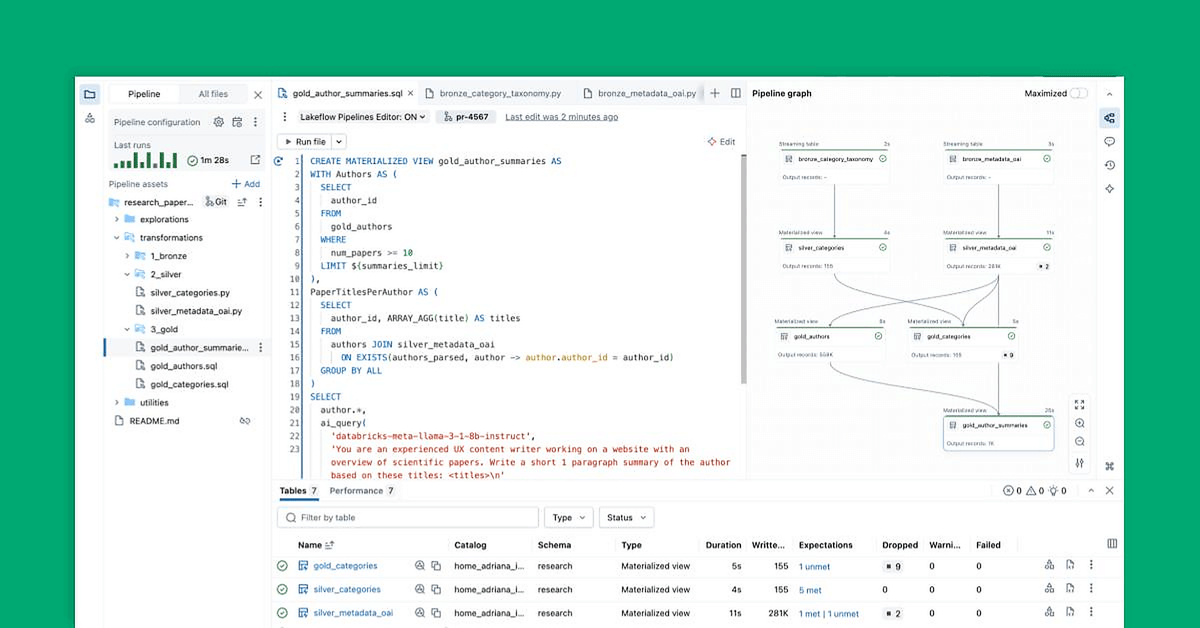
단일 DLT 파이프라인에서 여러 카탈로그와 스키마로 게시하기
구문을 단순화하고 비용을 최적화하며 운영 복잡성을 줄입니다

Summary
- 다중 스키마 & 카탈로그 지원: 단일 DLT 파이프라인에서 여러 스키마와 카탈로그로 게시합니다.
- 간��소화된 구문 & 비용 절감: LIVE 키워드를 제거하고 인프라 오버헤드를 줄입니다.
- 더 나은 관찰 가능성: 이벤트 로그를 Unity Catalog에 게시하고 SQL과 Python으로 여러 위치에 걸친 데이터를 관리합니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
DLT 는 Databricks 내에서 신뢰할 수 있고, 유지보수가 가능하며, 테스트 가능한 데이터 처리 파이프라인을 구축하기 위한 강력한 플랫폼을 제공합니다. 선언적 프레임워크를 활용하고 최적의 서버리스 컴퓨팅을 자동으로 프로비저닝함으로써, DLT는 스트리밍, 데이터 변환, 관리의 복잡성을 단순화하고, 현대 데이터 워크플로우에 대한 확장성과 효율성을 제공합니다.
우리는 많이 기다려온 향상된 기능을 발표하게 되어 기쁩니다: 단일 DLT 파이프라인 내에서 여러 스키마와 카탈로그에 테이블을 게시할 수 있는 기능. 이 기능은 운영 복잡성을 줄이고 비용을 낮추며, 메달리온 아키텍처(브론즈, 실버, 골드)를 단일 파이프라인으로 통합함으로써 데이터 관리를 간소화하고 조직 및 거버넌스의 모범 사례를 유지할 수 있게 해줍니다.
이 향상된 기능을 통해 다음을 수행할 수 있습니다:
- 파이프라인 구문 간소화 - 테이블 간의 종속성을 나타내기 위해
LIVE구문이 필요하지 않습니다. 완전하게 또는 부분적으로 지정된 테이블 이름이 지원되며, 표준 SQL에서처�럼USE SCHEMA와USE CATALOG명령어도 사용할 수 있습니다. - 운영 복잡성 줄이기 - 모든 테이블을 통합된 DLT 파이프라인 내에서 처리하고 게시하여 스키마 또는 카탈로그별로 별도의 파이프라인이 필요 없게 합니다.
- 비용 절감 - 여러 작업 부하를 단일 파이프라인으로 통합함으로써 인프라 오버헤드를 최소화합니다.
- 관찰 가능성 향상 - 향상된 모니터링 및 거버넌스를 위해 이벤트 로그를 Unity 카탈로그 메타스토어의 표준 테이블로 게시합니다.
"하나의 DLT 파이프라인에서 여러 카탈로그와 스키마로 게시할 수 있는 능력 - 더 이상 LIVE 키워드가 필요하지 않음 - 이것이 우리에게 파이프라인의 최적의 방법을 표준화하고, 개발 노력을 간소화하며, 대규모 기업에서 도구를 채택하는 일환으로 비-DLT 작업부터 DLT로 팀의 쉬운 전환을 촉진하는데 도움을 주었습니다." — 론 데프리타스, 주요 데이터 엔지니어, HealthVerity

시작하는 방법
파이프라인 생성
이제 UI에서 생성된 모든 파이프라인은 기본적으로 여러 카탈로그와 스키마를 지원합니다. UI, API 또는 Databricks Asset Bundles (DABs)를 통해 파이프라인 수준에서 기본 카탈로��그와 스키마를 설정할 수 있습니다.
UI에서:
- 평소처럼 새 파이프라인을 생성하세요.
- 파이프라인 설정에서 기본 카탈로그와 스키마를 설정합니다.
API에서:
프로그래밍 방식으로 파이프라인을 생성하는 경우, PipelineSettings 의 schema 필드를 지정함으로써 이 기능을 활성화할 수 있습니다. 이것은 기존의 target 필드를 대체하여, 데이터셋이 여러 카탈로그와 스키마에 걸쳐 게시될 수 있도록 합니다.
이 기능을 API를 통해 파이프라인을 생성하려면 이 코드 샘플을 따르십시오 (참고: 개인 액세스 토큰 인증이 작업 공간에 대해 활성화되어야 합니다):
schema 필드를 설정함으로써, 파이프라인은 LIVE 키워드를 필요로 하지 않고 여러 카탈로그와 스키마에 테이블을 자동으로 게시하는 것을 지원합니다.
DAB에서
- Databricks CLI가 버전 v0.230.0 이상인지 확인하세요. 그렇지 않다면, 문서를 따라 CLI를 업그레이드하세요.
- 문서를 따라 Databricks Asset Bundle (DAB) 환경을 설정하세요. 이 단계를 따르면, Databricks CLI에서 생성된 모든 구성 및 소스 코드 파일이 포함된 DAB 디렉토리를 가지게 됩니다.
- 다음 위치에서 DLT 파이프라인을 정의하는 YAML 파일을 찾으세요:
<your dab folder>/<resource>/<pipeline_name>_pipeline.yml - 파이프라인 YAML에서
schema필드를 설정하고, 존재하는 경우target필드를 제거하세요. - “
databricks bundle validate“를 실행하여 DAB 구성이 유효한지 확인합니다. - “
databricks bundle deploy -t <environment>“를 실행하여 첫 번째 DPM 파이프라인을 배포하세요!
“이 기능은 우리가 예상한 대로 작동합니다! 나는 DLT 내의 다른 데이터셋을 단일 파이프라인 내에서 우리의 스테이지, 코어 및 UDM 스키마(기본적으로 브론즈, 실버, 골드 설정)로 분할할 수 있었습니다.” — 플로리안 두메, Arvato의 데이터 소프트웨어 개발 전문가

여러 카탈로그와 스키마에 테이블 게시
파이프라인이 설정되면 SQL과 Python에서 완전히 또는 부분적으로 자격이 부여된 이름을 사용하여 테이블을 정의할 수 있습니다.
SQL 예제
Python 예시
데이터셋 읽기
완전하게 또는 부분적으로 자격을 갖춘 이름을 사용하여 데이터셋을 참조할 수 있으며, 이전 버전과의 호환성을 위해 LIVE 키워드는 선택 사항입니다.
SQL 예제
Python 예시
API 행동 변경
이 새로운 기능을 통해, 주요 API 메소드들이 여러 카탈로그와 스키마를 더욱 원활하게 지원하도록 업데이트되었습니다:
dlt.read() 그리고 dlt.read_stream()
이전에는 이러한 메소드들이 현재 파이프라인 내에서 정의된 데이터셋만 참조할 수 있었습니다. 이제, 필요에 따라 자동으로 종속성을 추적하면서 여러 카탈로그와 스키마에 걸쳐 데이터셋을 참조할 수 있습니다. 이를 통해 다른 위치에서 데이터를 통합하는 파이프라인을 더 쉽게 구축할 수 있습니다.
spark.read() 그리고 spark.readStream()
과거에는 이러한 방법들이 외부 데이터셋에 대한 명시적인 참조를 필요로 했으므로, 크로스 카탈로그 쿼리가 더욱 번거로웠습니다. 새로운 업데이트를 통해, 종속성은 이제 자동으로 추적되며, 더 이상 LIVE 스키마가 필요하지 않습니다. 이는 단일 파이프라인 내에서 여러 소스에서 데이터를 읽는 과정을 단순화합니다.
USE CATALOG와 USE SCHEMA 사용
Databricks SQL 구문은 이제 활성 카탈로그와 스키마를 동적으로 설정하는 것을 지원하여, 여러 위치에 걸쳐 데이터를 관리하는 것이 더 쉬워졌습니다.
SQL 예제
Python 예시
Unity 카탈로그에서 이벤트 로그 관리
이 기능을 사용하면 파이프라인 소유자가 Unity 카탈로그 메타스토어에 이벤트 로그를 게시하여 관찰성을 향상시킬 수 있습니다. 이를 활성화하려면, 파이프라인 설정 JSON에서 event_log 필드를 지정하십시오. 예를 들어, 다음과 같은 접근 방식이 있습니다.
이제 이벤트 로그 테이블에 대해 일반 테이블처럼 GRANTS를 발행할 수 있습니다:
또한 이벤트 로그 테이블에 대한 뷰를 생성할 수도 있습니다:
위의 모든 것 외에도, 이벤트 로그 테이블에서 스트림을 생성할 수도 있습니다:
다음은 무엇인가요?
앞으로 이러한 개선 사항들은 UI, API, 또는 Databricks Asset Bundles를 통해 생성된 모든 새로운 파이프라인에 대한 기본 설정이 될 것입니다. 또한, 기존 파이프라인을 새로운 게시 모델로 전환하는 데 도움이 될 마이그레이션 도구가 곧 제공될 예정입니다.
문서에서 더 자세히 알아보세요 여기.