Modellierungstechniken im Data Warehousing und ihre Implementierung auf der Databricks Lakehouse-Plattform
Verwendung von Data Vaults und Sternschemata auf dem Lakehouse
Das Lakehouse ist ein neues Datenplattform-Paradigma, das die besten Features von Data Lakes und Data Warehouses kombiniert. Sie ist als groß angelegte Datenplattform auf Unternehmensebene konzipiert, die viele Anwendungsfälle und Datenprodukte aufnehmen kann. Es kann als einziges, einheitliches Unternehmensdaten-Repository für all Ihre folgenden Daten dienen:
- Datendomänen,
- Echtzeit-Streaming-Anwendungsfälle,
- Data-Marts,
- uneinheitliche Data Warehouses,
- Data-Science-Feature-Stores und Data-Science-Sandboxes und
- Self-Service-Analytics-Sandboxes für Abteilungen.
Angesichts der Vielfalt der Anwendungsfälle können für verschiedene Projekte in einem Lakehouse unterschiedliche Prinzipien zur Datenorganisation und Modellierungstechniken gelten. Technisch gesehen kann die Databricks Lakehouse Platform viele verschiedene Arten der Datenmodellierung unterstützen. In diesem Artikel erklären wir die Implementierung der Bronze-, Silber- und Gold-Datenorganisationsprinzipien des Lakehouse und wie verschiedene Datenmodellierungstechniken in die jeweilige Schicht passen.
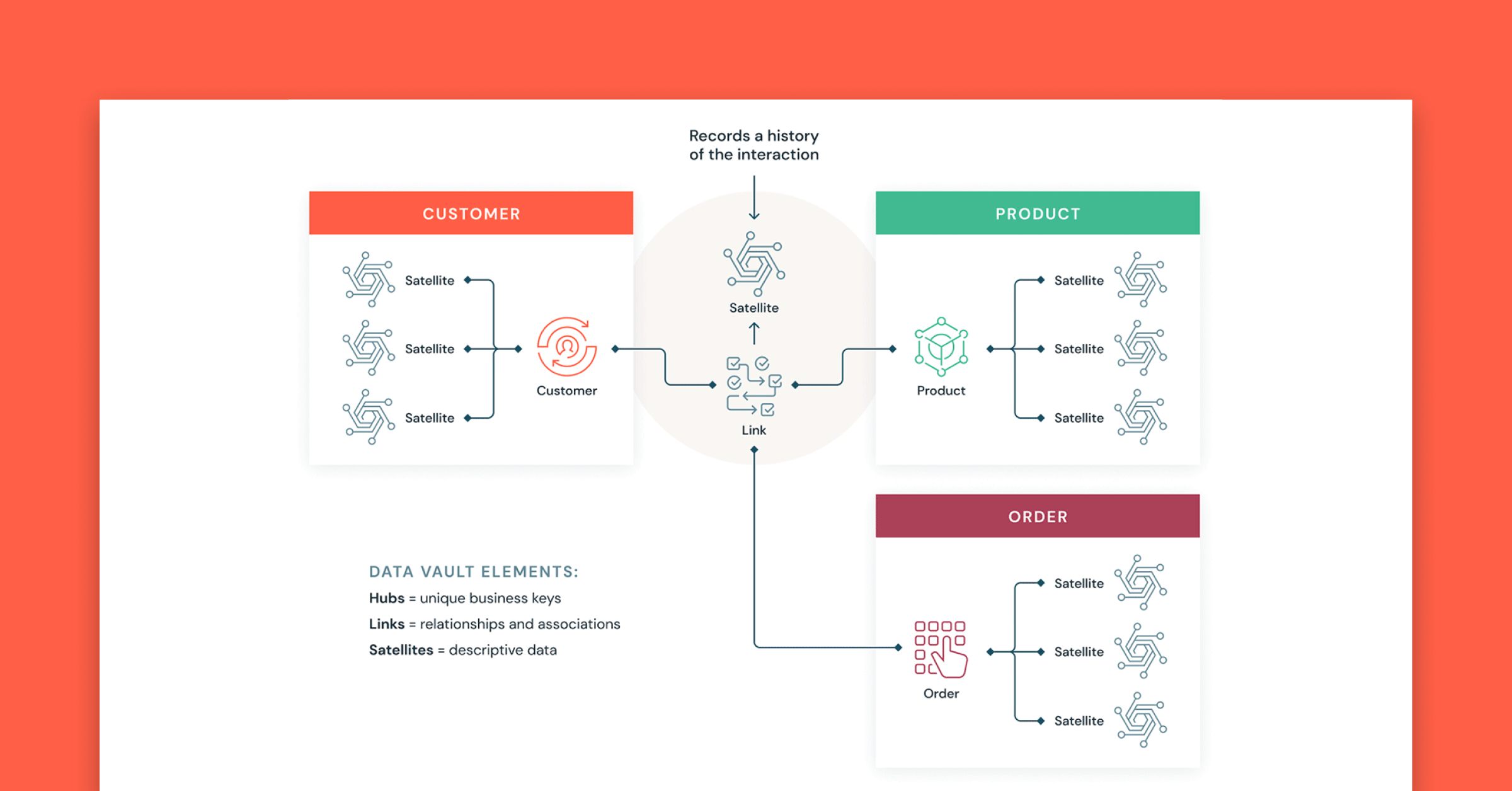
Was ist ein Data Vault?
Ein Data Vault ist im Vergleich zu den Methoden von Kimball und Inmon ein neueres Entwurfsmuster für die Datenmodellierung, das zum Erstellen von Data Warehouses für Analysen im Unternehmensmaßstab verwendet wird.
Data Vaults organisieren Daten in drei verschiedene Typen: Hubs, Links und Satelliten. Hubs stellen Kerngeschäftseinheiten dar, Links repräsentieren Beziehungen zwischen Hubs und Satelliten speichern Attribute über Hubs oder Links.
Data Vault konzentriert sich auf die agile Data-Warehouse-Entwicklung, bei der Skalierbarkeit, Datenintegration/ETL und Entwicklungsgeschwindigkeit wichtig sind. Die meisten Kunden haben eine Landing-Zone, eine Vault-Zone und eine Data-Mart-Zone, die den Organisationsparadigmen von Databricks für Bronze-, Silber- und Gold-Ebenen entsprechen. Der Data-Vault-Modellierungsstil mit Hub-, Link- und Satellitentabellen passt normalerweise gut in die Silver-Schicht des Databricks Lakehouse.
Erfahren Sie mehr über die Data-Vault-Modellierung bei der Data Vault Alliance.
Was ist dimensionale Modellierung?
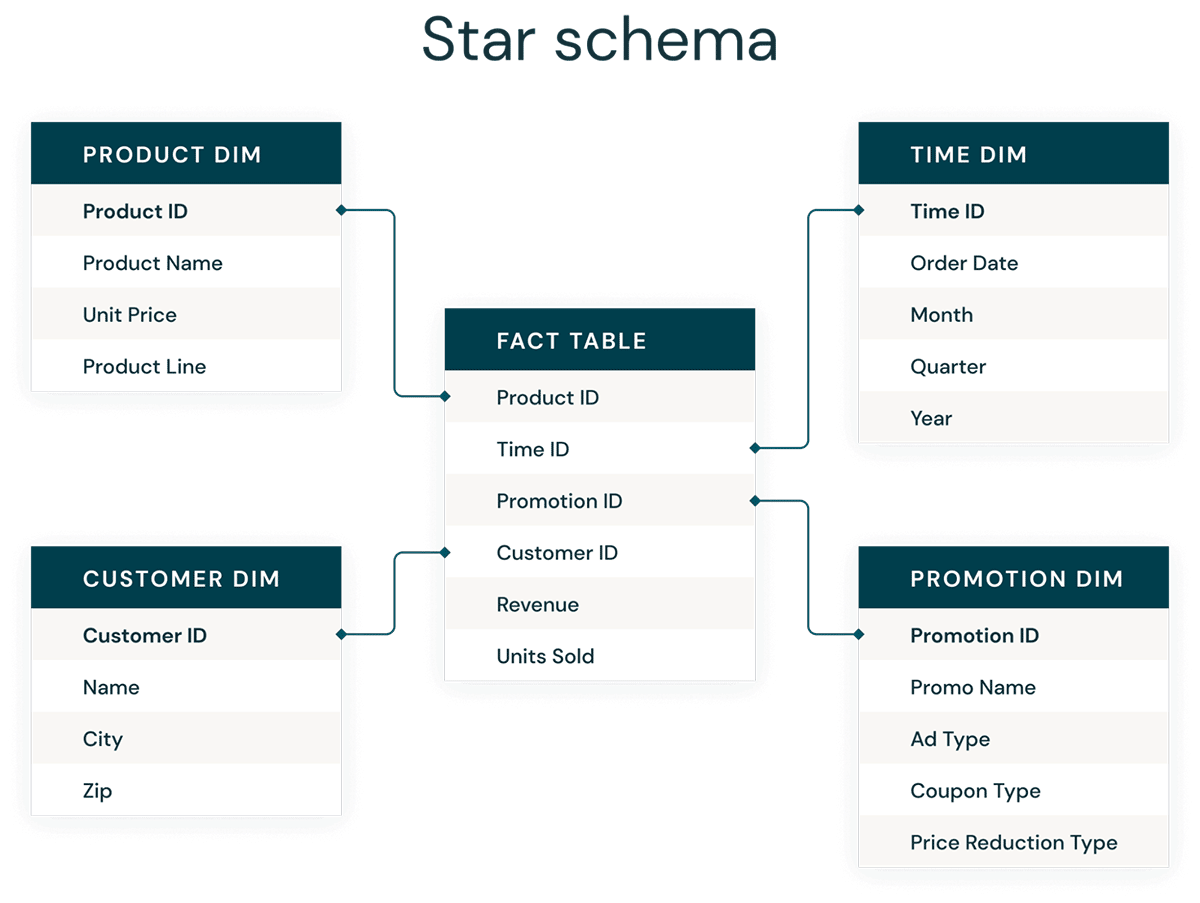
Die dimensionale Modellierung ist ein Bottom-up-Ansatz für das Design von Data Warehouses, um sie für Analytics zu optimieren. Dimensionale Modelle werden verwendet, um Geschäftsdaten in Dimensionen (wie Zeit und Produkt) und Fakten (wie Transaktionen in Beträgen und Mengen) zu denormalisieren. Verschiedene Themenbereiche sind über konforme Dimensionen verbunden, um zu verschiedenen Faktentabellen zu navigieren.
Die gebräuchlichste Form der dimensionalen Modellierung ist das Sternschema. Ein Sternschema ist ein mehrdimensionales Datenmodell, das zur Organisation von Daten verwendet wird, sodass diese leicht zu verstehen und zu analysieren sind und Berichte darauf sehr einfach und intuitiv ausgeführt werden können. Sternschemata oder dimensionale Modelle im Kimball-Stil sind so ziemlich der Goldstandard für die Präsentationsschicht in Data Warehouses und Data Marts und sogar für semantische und Reporting-Schichten. Das Sternschemadesign ist für die Abfrage großer Datenmengen optimiert.
Sowohl die normalisierte Data-Vault-Modellierung (schreiboptimiert) als auch denormalisierte dimensionale Modelle (leseoptimiert) haben ihren Platz im Databricks Lakehouse. Die Hubs und Satelliten des Data Vault im Silver-Layer werden verwendet, um die Dimensionen im Sternschema zu laden, und die Link-Tabellen des Data Vault dienen als Key-Tabellen zum Laden der Faktentabellen im Dimensionsmodell. Erfahren Sie mehr über die dimensionale Modellierung von der Kimball Group.
Prinzipien der Datenorganisation in jeder Schicht des Lakehouse
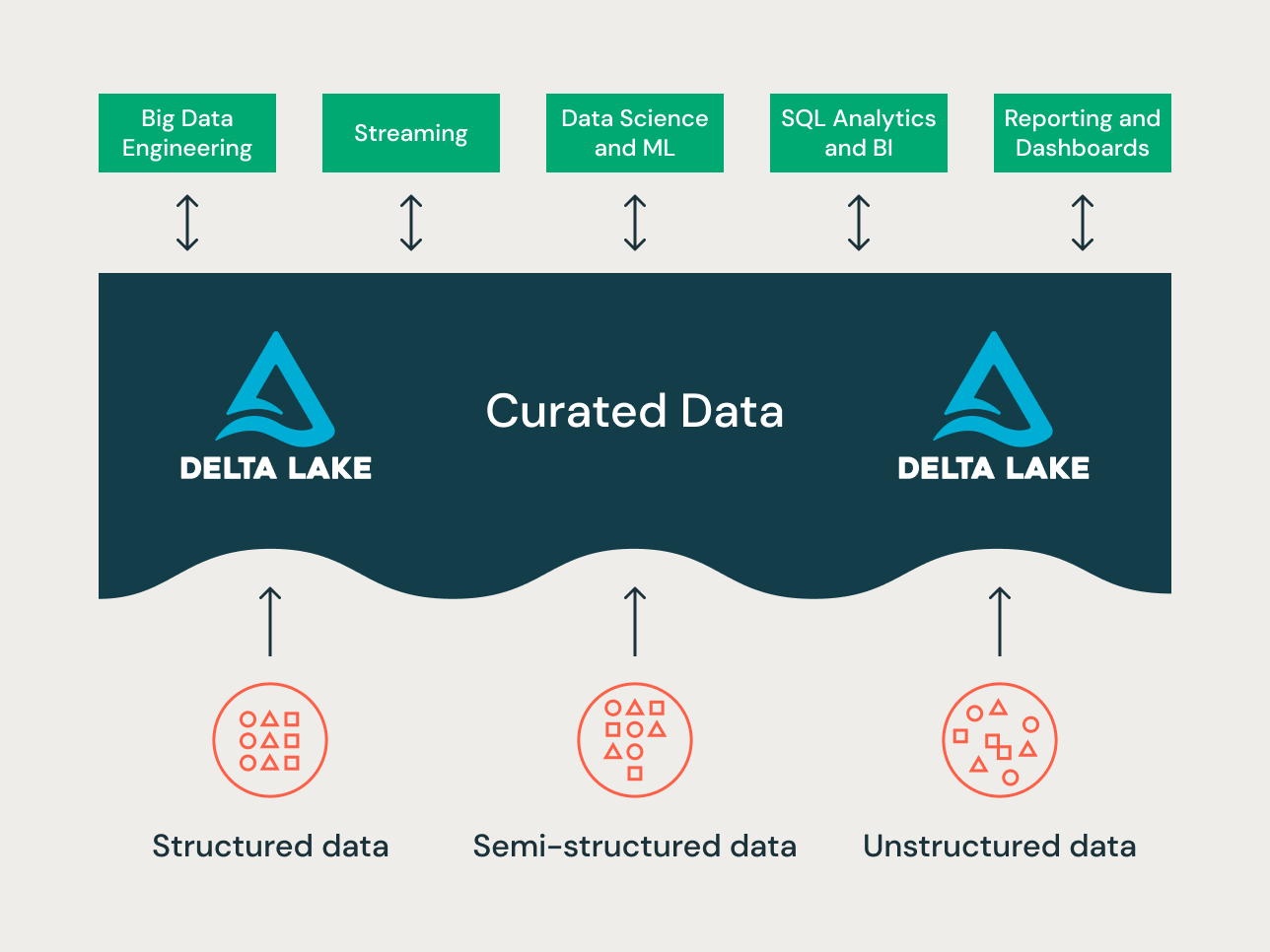
Ein modernes Lakehouse ist eine umfassende Datenplattform für Unternehmen. Es ist hoch skalierbar und leistungsstark für die verschiedensten Anwendungsfälle wie ETL, BI, Data Science und Streaming, die möglicherweise unterschiedliche Datenmodellierungsansätze erfordern. Schauen wir uns an, wie ein typisches Lakehouse aufgebaut ist:
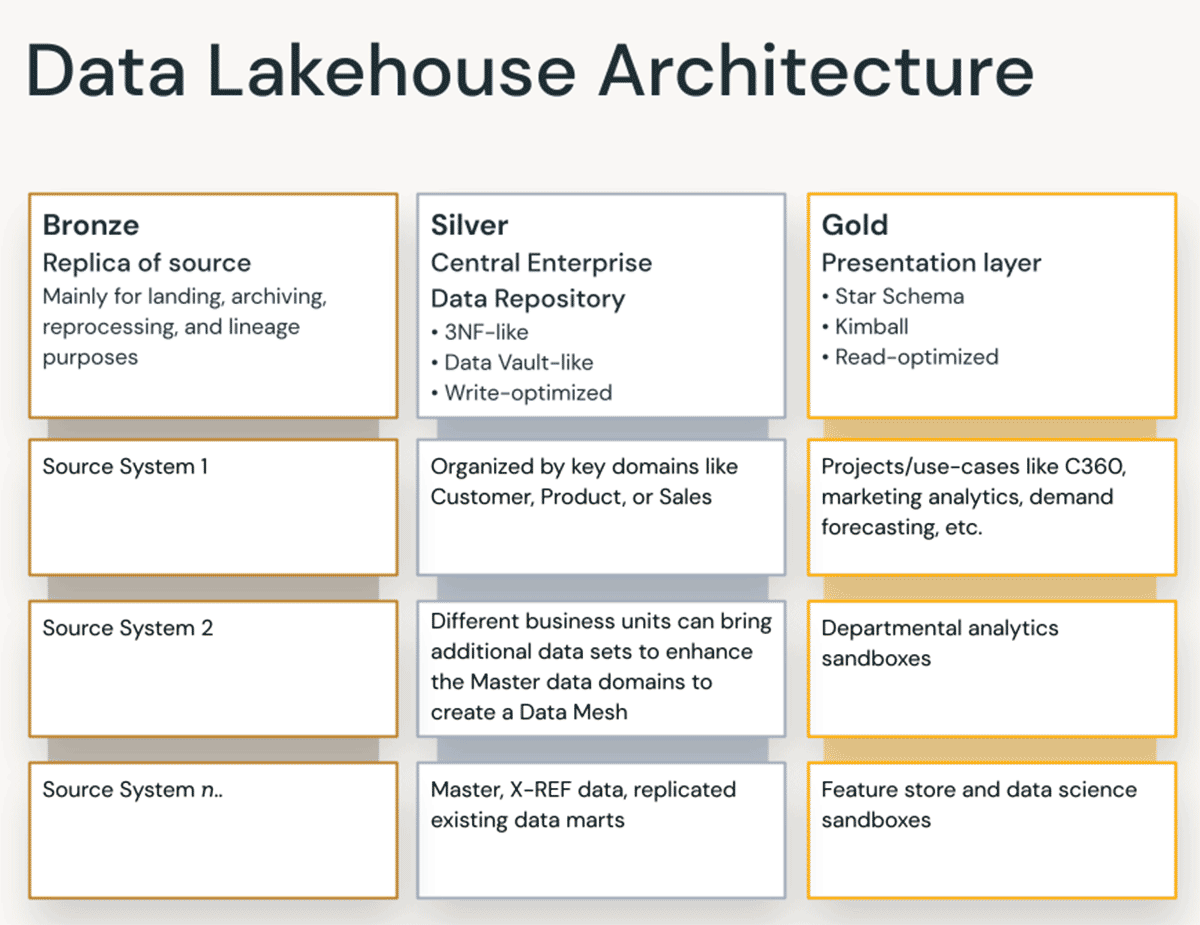
Bronze-Layer – die Landing-Zone
Auf der Bronzeschicht kommen alle Daten aus externen Quellsystemen an. Die Tabellenstrukturen in diesem Layer entsprechen den Tabellenstrukturen des Quellsystems "as-is", abgesehen von optionalen Metadatenspalten, die hinzugefügt werden können, um das Ladedatum/die Ladezeit, die Prozess-ID usw. zu erfassen. Der Schwerpunkt dieser Schicht liegt auf der schnellen Erfassung von Änderungsdaten und der Möglichkeit, ein historisches Archiv der Quelle (Cold Storage), die Datenherkunft, der Prüfbarkeit und die Neuverarbeitung bei Bedarf bereitzustellen, ohne die Daten erneut aus dem Quellsystem zu lesen.
In den meisten Fällen ist es eine gute Idee, die Daten in der Bronze-Schicht im Delta-Format zu speichern, damit nachfolgende Lesevorgänge aus der Bronze-Schicht für ETL performant sind – und damit Sie Aktualisierungen in der Bronze-Schicht durchführen können, um CDC-Änderungen zu schreiben. Manchmal, wenn Daten im JSON- oder XML-Format eintreffen, beobachten wir, dass Kunden sie im ursprünglichen Quelldatenformat speichern und sie dann durch die Umwandlung in das Delta-Format bereitstellen. Manchmal sehen wir also, wie Kunden den logischen Bronze-Layer in einer physischen Landing- und Staging-Zone umsetzen.
Das Speichern von Rohdaten im ursprünglichen Quelldatenformat in einer Landing-Zone trägt auch zur Konsistenz bei, wenn Sie Daten über Ingestion-Tools aufnehmen, die Delta nicht als nativen Sink unterstützen, oder wenn Quellsysteme Daten direkt in Objektspeichern ablegen. Dieses Muster passt auch gut zum Autoloader-Ingestion-Framework, bei dem Quellen die Daten in der Landing-Zone für Rohdateien ablegen und der Databricks AutoLoader die Daten dann in die Staging-Schicht im Delta-Format konvertiert.
Silver-Layer – das zentrale Unternehmens-Repository
In der Silberschicht des Lakehouse werden die Daten der Bronzeschicht abgeglichen, zusammengeführt, angepasst und bereinigt („gerade gut genug“), sodass die Silberschicht eine „Unternehmensansicht“ aller wichtigen Geschäftseinheiten, Konzepte und Transaktionen bereitstellen kann. Dies ähnelt einem Enterprise Operational Data Store (ODS), einem zentralen Repository oder den Datendomänen eines Data Mesh (z. B. Stammkunden, Filialen, nicht duplizierte Transaktionen und Querverweistabellen). Diese Unternehmensansicht führt die Daten aus verschiedenen Quellen zusammen und ermöglicht Self-Service-Analysen für Ad-hoc-Berichte, erweiterte Analysen und ML. Sie dient Abteilungsanalysten, Data Engineers und Data Scientists als Quelle für die weitere Erstellung von Projekten und Analysen zur Beantwortung von Geschäftsproblemen über Unternehmens- und Abteilungsdatenprojekte in der Goldschicht.
Im Lakehouse-Data-Engineering-Paradigma wird typischerweise die ELT-Methodik (Extract-Load-Transform) anstelle der herkömmlichen ETL-Methodik (Extract-Transform-Load) verwendet. Der ELT-Ansatz bedeutet, dass beim Laden des Silver-Layers nur minimale oder "gerade ausreichende" Transformationen und Datenbereinigungsregeln angewendet werden. Alle Regeln auf "Unternehmensebene" werden im Silver-Layer angewendet, im Gegensatz zu projektspezifischen Transformationsregeln, die im Gold-Layer angewendet werden. Geschwindigkeit und Agilität bei der Erfassung und Bereitstellung der Daten im Lakehouse werden hier priorisiert.
Aus Sicht der Datenmodellierung weist die Silberschicht typischerweise Datenmodelle auf, die der 3. Normalform ähneln. In dieser Schicht können Data-Vault-ähnliche, schreibperformante Datenarchitekturen und Datenmodelle verwendet werden. Bei Verwendung einer Data-Vault-Methodik passen sowohl der Raw Data Vault als auch der Business Vault in die logische Silber-Ebene des Lake – und die Point-in-Time(PIT)-Präsentationsansichten oder materialisierten Ansichten werden in der Gold-Ebene dargestellt.
Gold-Layer – die Präsentationsschicht
In der Gold-Schicht können mehrere Data Marts / Data Warehouses mittels dimensionaler Modellierung / Kimball-Methodik erstellt werden. Wie bereits erläutert, ist die Gold-Schicht für das Reporting vorgesehen und verwendet stärker denormalisierte und leseoptimierte Datenmodelle mit weniger Joins im Vergleich zur Silver-Schicht. Manchmal können Tabellen in der Gold-Schicht vollständig denormalisiert werden, typischerweise, wenn Data Scientists dies benötigen, um ihre Algorithmen für das Feature-Engineering zu speisen.
ETL- und Datenqualitätsregeln, die „projektspezifisch“ sind, werden bei der Transformation von Daten vom Silver-Layer zum Gold-Layer angewendet. Finale Präsentations-Layer wie Data Warehouses, Data Marts oder Datenprodukte wie Kundenanalysen, Produkt-/Qualitätsanalysen, Bestandsanalysen, Kundensegmentierung, Produktempfehlungen, Marketing-/Vertriebsanalysen usw. werden in diesem Layer bereitgestellt. Datenmodelle auf Basis von Sternschemen im Kimball-Stil oder Data Marts im Inmon-Stil passen in diesen Gold-Layer des Lakehouse. Data-Science-Labore und abteilungsspezifische Sandboxes für Self-Service-Analytics gehören ebenfalls in den Gold-Layer.
Das Paradigma der Lakehouse-Datenorganisation
Zusammenfassend lässt sich sagen, dass Daten kuratiert werden, während sie die verschiedenen Schichten eines Lakehouse durchlaufen.
- Die Bronze-Schicht verwendet die Datenmodelle der Quellsysteme. Wenn Daten in Rohformaten landen, werden sie in diesem Layer in das DeltaLake-Format konvertiert.
- Die Silver-Schicht führt erstmals die Daten aus verschiedenen Quellen zusammen und passt sie an, um eine unternehmensweite Sicht auf die Daten zu erstellen — wobei typischerweise stärker normalisierte, schreiboptimierte Datenmodelle verwendet werden, die der 3. Normalform oder Data Vault ähneln.
- Der Gold-Layer ist die Präsentationsschicht mit stärker denormalisierten oder abgeflachten Datenmodellen als der Silver-Layer, wobei typischerweise dimensionale Modelle im Kimball-Stil oder Sternschemata verwendet werden. Der Gold-Layer beherbergt auch Sandboxes für Fachbereiche und Data Science, um Self-Service-Analytics und Data Science im gesamten Unternehmen zu ermöglichen. Die Bereitstellung dieser Sandboxes und ihrer eigenen, separaten Compute-Clusters verhindert, dass die Business-Teams ihre eigenen Datenkopien außerhalb des Lakehouse erstellen.
Dieser Lakehouse-Ansatz zur Datenorganisation soll Datensilos aufbrechen, Teams zusammenbringen und sie befähigen, ETL, Streaming sowie BI und KI auf einer einzigen Plattform mit ordnungsgemäßer Governance durchzuführen. Zentrale Datenteams sollten die Wegbereiter für Innovationen im Unternehmen sein und das Onboarding neuer Self-Dienst-Benutzer sowie die parallele Entwicklung vieler Datenprojekte beschleunigen – anstatt dass der Datenmodellierungsprozess zum Engpass wird. Der Databricks Unity Catalog bietet Funktionen für Suche und Ermittlung, Governance und Datenherkunft auf dem Lakehouse, um eine gute Data-Governance-Kadenz sicherzustellen.
Erstellen Sie noch heute Ihre Data Vaults und Star-Schema-Data-Warehouses mit Databricks SQL.
Weiterführende Lektüre:
- Fünf einfache Schritte zum Implementieren eines Sternschemas in Databricks mit Delta Lake
- Best Practices zur Implementierung eines Data-Vault-Modells in Databricks Lakehouse
- Bewährte Methoden und Implementierung für dimensionale Modellierung in einem modernen Lakehouse
- Identitätsspalten zur Generierung von Ersatzschlüsseln sind jetzt in einem Lakehouse in Ihrer Nähe verfügbar!
- Laden eines dimensionalen EDW-Modells in Echtzeit mit Databricks Lakehouse
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Verpassen Sie keinen Beitrag von Databricks
Was kommt als Nächstes?

Produto
June 12, 2024/11 min de leitura
Apresentando o AI/BI: analítica inteligente para dados do mundo real

Produto
September 12, 2024/8 min de leitura