Leitfaden für die Implementierung eines Data-Vault-Modells auf der Databricks Lakehouse-Plattform

Es gibt viele verschiedene Datenmodelle, die Sie beim Entwurf eines Analysesystems verwenden können, wie z. B. branchenspezifische Domänenmodelle und die Kimball-, Inmon- und Data-Vault-Methoden. Abhängig von Ihren individuellen Anforderungen können Sie diese verschiedenen Modellierungstechniken beim Entwerfen eines Lakehouse verwenden. Sie alle haben ihre Stärken, und jede kann für unterschiedliche Anwendungsfälle gut geeignet sein.
Letztendlich ist ein Datenmodell nichts anderes als ein Konstrukt, das verschiedene Tabellen mit definierten Eins-zu-eins-, Eins-zu-viele- und Viele-zu-viele-Beziehungen definiert. Datenplattformen müssen Best Practices für die Physisierung des Datenmodells bereitstellen, um einen einfacheren Informationsabruf und eine bessere Performance zu ermöglichen.
In einem früheren Artikel haben wir Fünf einfache Schritte zur Implementierung eines Sternschemas in Databricks mit Delta Lake behandelt. In diesem Artikel erklären wir, was ein Data Vault ist, wie er in der Bronze-, Silber- und Gold-Schicht implementiert wird und wie Sie mit der Databricks Lakehouse Platform die beste Performance des Data Vaults erzielen.
Data-Vault-Modellierung definiert
Das Ziel der Data-Vault-Modellierung besteht darin, sich an schnell ändernde Geschäftsanforderungen anzupassen und die schnellere und agile Entwicklung von Data Warehouses designbedingt zu unterst�ützen. Ein Data Vault eignet sich gut für die Lakehouse-Methodik, da das Datenmodell mit seinem Hub-, Link- und Satelliten-Design leicht erweiterbar und granular ist, sodass Design- und ETL-Änderungen einfach implementiert werden können.
Sehen wir uns einige Bausteine für einen Data Vault an. Im Allgemeinen hat ein Data-Vault-Modell drei Arten von Entitäten:
- Hubs – Ein Hub stellt eine zentrale Geschäftseinheit dar, z. B. Kunden, Produkte, Bestellungen usw. Analysten verwenden die natürlichen/geschäftlichen Schlüssel, um Information über einen Hub abzurufen. Der Primär-Key von Hub-Tabellen wird in der Regel aus einer Kombination von Geschäftskonzept-ID, Ladedatum und anderen Metadaten-Informationen abgeleitet.
- Links: Links stellen die Beziehung zwischen Hub-Entitäten dar. Es enthält nur die Join-Schlüssel. Es ist wie eine Factless Fact-Tabelle im dimensionalen Modell. Keine Attribute – nur Join-Schlüssel.
- Satelliten – Satellitentabellen enthalten die Attribute der Entitäten im Hub oder in den Links. Sie enthalten beschreibende Informationen über Kerngeschäftseinheiten. Sie ähneln einer normalisierten Version einer Dimensionstabelle. Ein Kunden-Hub kann beispielsweise viele Satellitentabellen haben, z. B. geografische Kundenattribute, Kundenbonität, Kunden-Treuestufen usw.
Einer der Hauptvorteile der Verwendung der Data-Vault-Methodik besteht darin, dass bestehende ETL-Jobs bei Änderungen am Datenmodell deutlich weniger Refactoring erfordern. Data Vault ist ein "schreiboptimierter" Modellierungsstil, der agile Entwicklungsansätze unterstützt und sich hervorragend für Data Lakes und den lakehouse-Ansatz eignet.
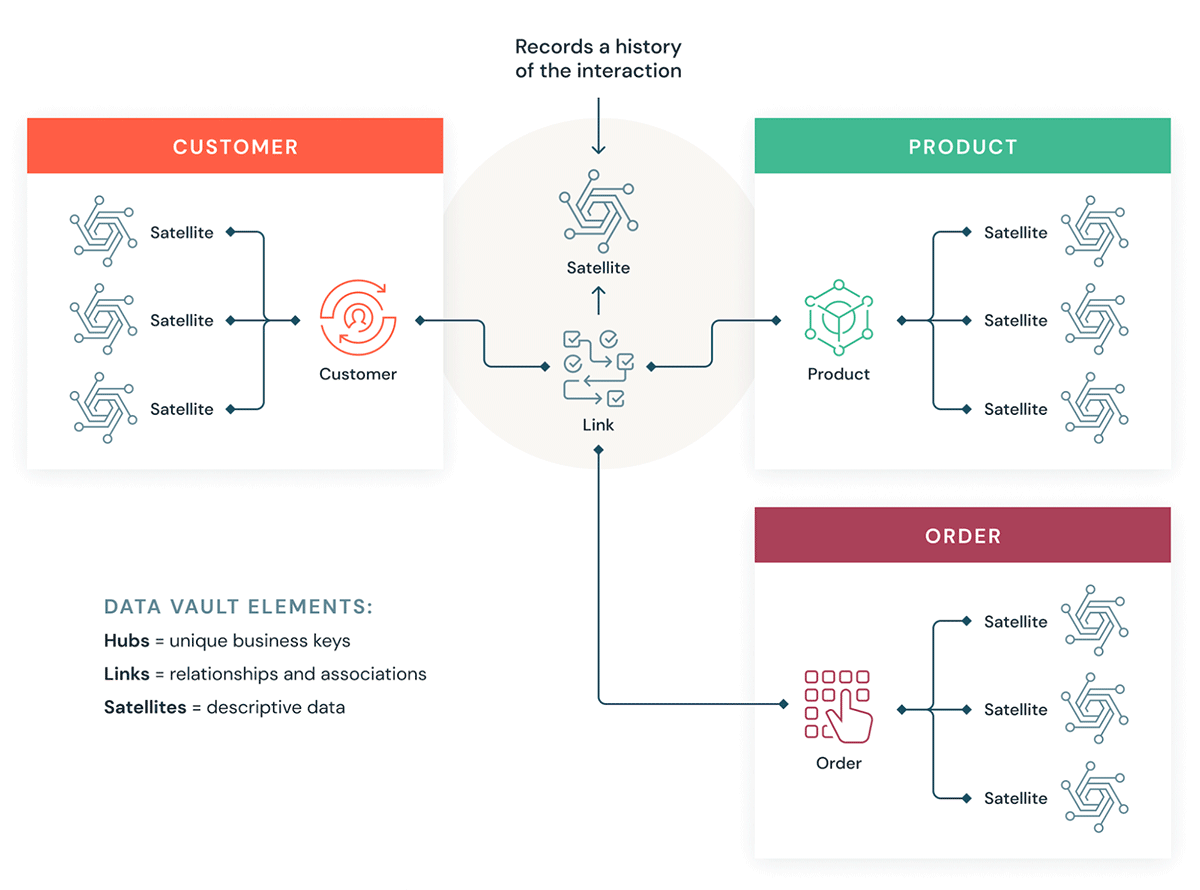
Wie Data Vault in ein Lakehouse passt
Sehen wir uns an, wie einige unserer Kunden die Data-Vault-Modellierung in einer Databricks Lakehouse-Architektur verwenden:
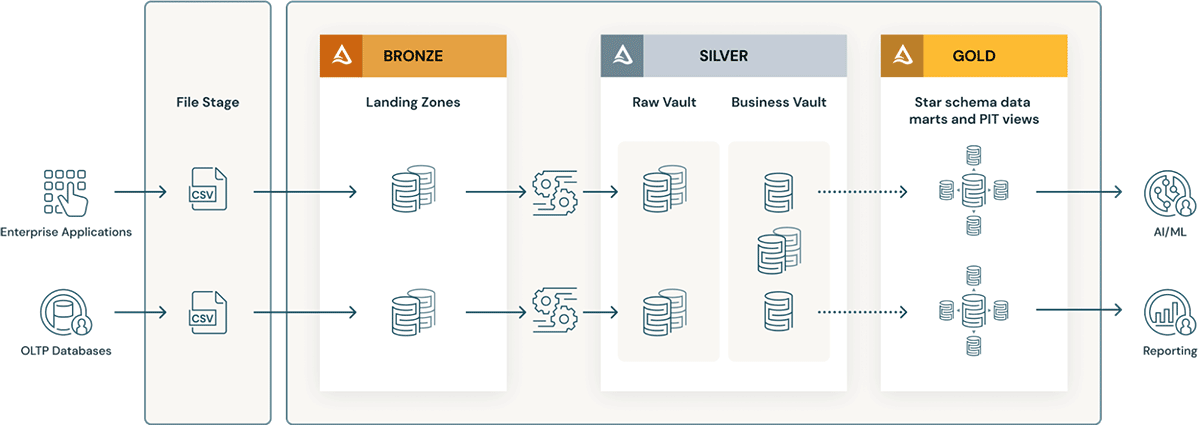
Überlegungen zur Implementierung eines Data-Vault-Modells im Databricks Lakehouse
- Die Data-Vault-Modellierung empfiehlt die Verwendung eines Hashes von Business-Keys als Primärschlüssel. Databricks unterstützt standardmäßig die Funktionen Hash, MD5 und SHA zur Unterstützung von Business Keys.
- Data-Vault-Schichten kennen das Konzept einer Landing Zone (und manchmal einer Staging Zone). Diese beiden physischen Schichten passen natürlich zur Bronze-Schicht des Data Lakehouse. Wenn die Daten der Landing-Zone in Formaten wie Avro, CSV, Parquet, XML und JSON ankommen, werden sie in der Staging-Zone in Tabellen im Delta-Format konvertiert, sodass der nachfolgende ETL-Prozess hochperformant ist.
- Der Raw Vault wird aus der Landing- oder Staging-Zone erstellt. Die Daten werden im Rohdaten-Vault als Hub-, Link- und Satellitentabellen modelliert. Zusätzliche "Business"-ETL-Regeln werden beim Laden des Rohdaten-Vault in der Regel nicht angewendet.
- Alle ETL-Geschäftsregeln, Datenqualitätsregeln sowie Bereinigungs- und Konformitätsregeln werden zwischen dem Raw Vault und dem Business Vault angewendet. Business Vault-Tabellen können nach Datendomänen organisiert werden, die als unternehmensweites "zentrales Repository" für standardisierte und bereinigte Daten dienen. Data Stewards und SMEs sind für die Governance, Datenqualität und Geschäftsregeln in ihren Bereichen des Business Vaults verantwortlich.
- Für die Präsentationsschicht auf dem Business Vault werden Abfragehilfstabellen wie Point-in-Time- (PIT-) und Bridge-Tabellen erstellt. Die PIT-Tabellen verbessern die Abfrage-Performance, da einige Satelliten und Hubs vorab verknüpft sind und einige WHERE-Bedingungen mit „Point-in-Time“-Filterung bereitstellen. Bridge-Tabellen vorab Joins Hubs oder Entitäten, um abgeflachte Ansichten für Entitäten zu bieten, die einer "Dimensionstabelle" ähneln. Delta-Live-Tables sind genau wie materialisierte Sichten und können zur Erstellung von Point-in-Time-Tabellen sowie Bridge-Tabellen in der Gold-/Präsentationsschicht auf dem Business Data Vault verwendet werden.
- Wenn sich Geschäftsprozesse ändern und anpassen, kann das Data-Vault-Modell einfach erweitert werden, ohne dass wie bei dimensionalen Modellen ein umfangreiches Refactoring erforderlich ist. Zusätzliche Hubs (Themenbereiche) können einfach zu Links (reinen Join-Tabellen) hinzugefügt werden, und zusätzliche Satelliten (z. B. Kundensegmentierungen) können mit minimalen Änderungen zu einem Hub (Kunden) hinzugefügt werden.
- Außerdem wird das Laden eines dimensional modellierten Data Warehouse in der Gold-Schicht aus den folgenden Gründen einfacher:
- Hubs erleichtern das Schlüsselmanagement (natürliche Schlüssel aus Hubs können über Identitätsspalten in Surrogate Keys umgewandelt werden).
- Satelliten erleichtern das Laden von Dimensionen, da sie alle Attribute enthalten.
- Links machen das Laden von Faktentabellen recht einfach, da sie alle Beziehungen enthalten.
Tipps für die optimale Performance eines Data-Vault-Modells in Databricks Lakehouse
- Verwenden Sie Tabellen im Delta-Format für Raw Vault-, Business Vault- und Gold-Layer-Tabellen.
- Stellen Sie sicher, dass Sie OPTIMIZE- und Z-Order- Indizes für alle Join-Schlüssel von Hubs, Links und Satellites verwenden.
- Partitionieren Sie die Tabellen nicht übermäßig – insbesondere die kleineren Satellitentabellen. Verwenden Sie die Bloom-Filter-Indizierung für Datumsspalten, Current-Flag-Spalten und Prädikatsspalten, nach denen typischerweise gefiltert wird, um die beste Performance sicherzustellen – insbesondere, wenn Sie außer der Z-Order zusätzliche Indizes erstellen müssen.
- Delta-Live-Tables (materialisierte Sichten) machen das Erstellen und Verwalten von PIT-Tabellen sehr einfach.
- Reduzieren Sie
optimize.maxFileSizeauf einen niedrigeren Wert, z. B. 32–64 MB im Vergleich zum default von 1 GB. Indem Sie kleinere Dateien erstellen, können Sie vom File Pruning profitieren und die E/A für den Abruf der Daten, die Sie für den Join benötigen, minimieren. - Das Data-Vault-Modell hat vergleichsweise mehr Joins. Verwenden Sie daher die neueste Version von DBR. Sie stellt sicher, dass die Adaptive Query Execution standardmäßig aktiviert ist, sodass automatisch die beste Join-Strategie verwendet wird. Verwenden Sie Join-Hinweise nur bei Bedarf. (für fortgeschrittene Performance-Optimierung).
Erfahren Sie mehr über die Data-Vault-Modellierung bei der Data Vault Alliance.
Beginnen Sie mit dem Aufbau Ihres Data Vault im Lakehouse
Databricks kostenlos 14 Tage lang testen
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag

Produkt
September 12, 2024/7 min de leitura
Fünf einfache Schritte zum Implementieren eines Sternschemas in Databricks mit Delta Lake
Verpassen Sie keinen Beitrag von Databricks
Was kommt als Nächstes?

Produto
June 12, 2024/11 min de leitura
Apresentando o AI/BI: analítica inteligente para dados do mundo real
Produto
September 12, 2024/8 min de leitura