State of Data + AI
Datenintelligenz und der Wettlauf um maßgeschneiderte LLMs

Daten- und KI-Strategie
Unternehmen drängen auf die Demokratisierung von Daten und KI
Jedes Unternehmen möchte von den transformativen Effekten seiner GenAI-Initiativen profitieren. Auch wollen sie die Macht der Data Intelligence in die Hände sämtlicher Mitarbeiter legen. Da jedoch die Informationen in Silos gebunden sind und die Datenverwaltung sich auf jede Menge Tools verteilt, fällt es den Teams häufig schwer, diese Projekte richtig in Gang zu bringen.
Die drängende Frage unter Wirtschaftsführern lautet daher zurzeit: Wie kann man KI am besten und schnellsten demokratisieren?
Der Bericht State of Data + AI liefert eine Momentaufnahme der Prioritäten, die Unternehmen bei Daten- und KI-Initiativen setzen. Durch Analyse anonymisierter Nutzungsdaten von 10.000 Kunden, die die Databricks Data Intelligence Platform heute bereits nutzen – darunter mehr als 300 der Fortune-500-Unternehmen –, sind wir in der Lage, einen konkurrenzlosen Einblick in den Stand der Bemühungen von Unternehmen, die Einführung von GenAI in den Betrieb zu beschleunigen, und in die Tools zu vermitteln, die ihnen dabei helfen sollen.
Finden Sie heraus, wie die innovativsten Unternehmen maschinelles Lernen erfolgreich einsetzen, GenAI implementieren und auf sich verändernde Governance-Anforderungen reagieren. Außerdem erfahren Sie, wie Ihr eigenes Unternehmen eine zur aufkommenden Ära der Unternehmens-KI passende Datenstrategie entwickelt.
Hier ist eine Zusammenfassung unserer Ergebnisse:
KI ist in der Produktion angekommen
11 Mal mehr KI-Modelle in die Produktion überführt
Seit Jahren experimentieren Unternehmen mit maschinellem Lernen (ML), einer maßgeblichen Komponente der KI. Dabei stehen sie häufig vor großen Hindernissen, wenn es darum geht, kontrollierte ML-Experimente in reale Produktionsanwendungen zu überführen – seien es Datensilos, komplexe Implementierungsabläufe oder Governance. Jetzt aber zeichnet sich immer häufiger Erfolg ab. Unternehmensübergreifend wurden in diesem Jahr 1.018 % mehr Modelle in die Produktion eingeführt als im Vorjahr. Das war das erste Mal im Rahmen unserer Untersuchungen, dass das Wachstum der registrierten Modelle das der protokollierten Experimente übertraf (welches seinerseits um 134 % zunahm).
Aber wenn es um maschinelles Lernen geht, hat jede Branche ihre eigenen Anforderungen und Ziele. Wir haben sechs Schlüsselbranchen analysiert und das Verhältnis der protokollierten zu den registrierten Modellen betrachtet, um diese Trends besser zu verstehen. Was haben wir herausgefunden? Dass in unseren drei effizientesten Branchen 25 % der Modelle in die Produktion gegangen sind.
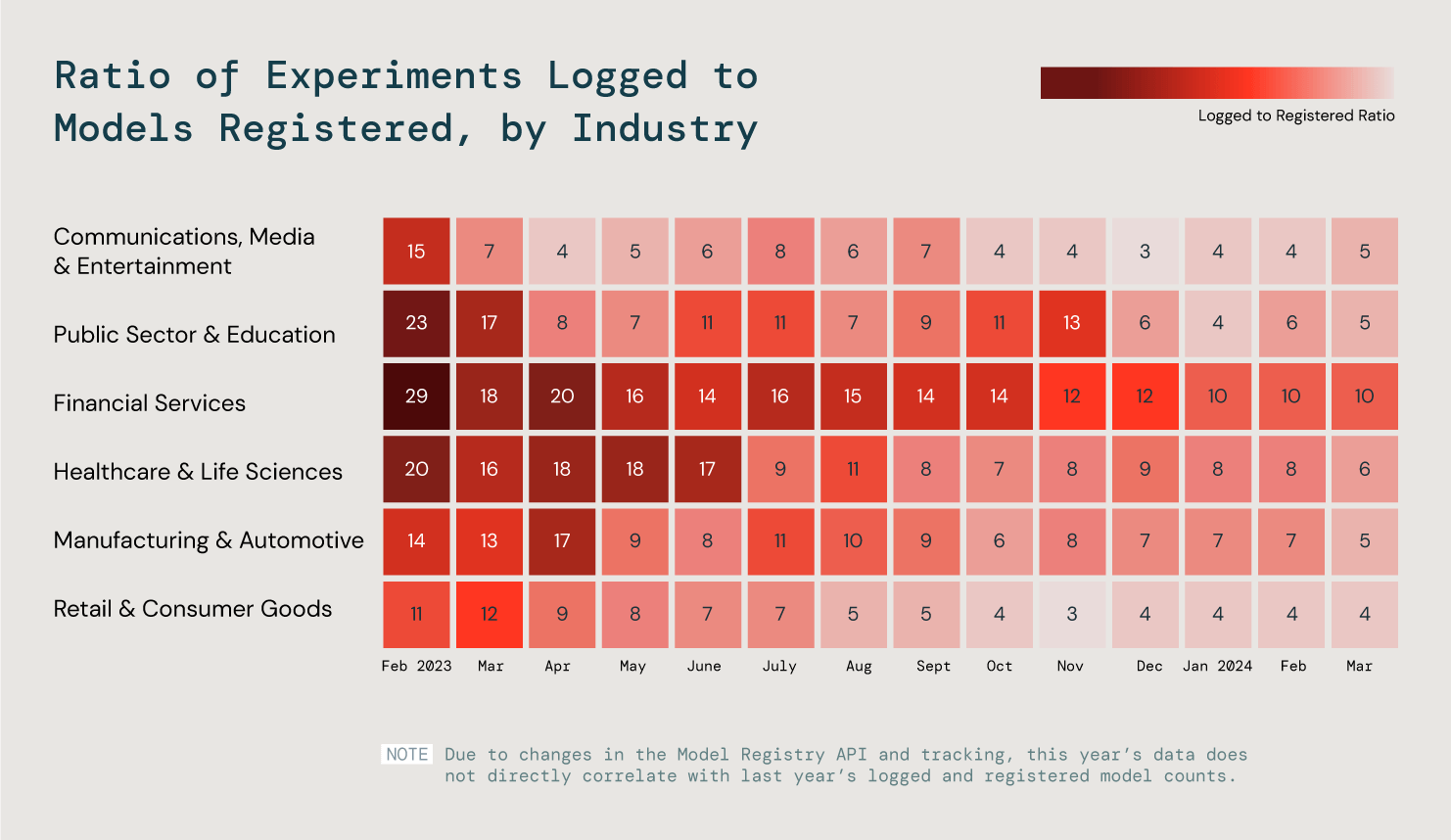
Wir haben das Verhältnis von protokollierten zu registrierten Modellen bei allen Kunden ausgewertet, um den Fortschritt von ML in der Produktion beurteilen zu können.
Erst in der Produktion kommt der wahre Wert der KI zum Tragen – ganz gleich, ob es sich um ein Produkt für Ihre internen Teams oder Ihre Kunden handelt. Wir prognostizieren, dass der wachsende Erfolg im Bereich ML den Weg zu einem noch größeren Erfolg bei der Entwicklung von GenAI-Anwendungen in Produktionsqualität ebnen wird.
LLM-Anpassung
Nutzung der Vektordatenbanken um 377 % gestiegen
Die Unternehmen gewinnen auf ihrem Weg zur GenAI immer stärker an Reife. Daher sind sie zunehmend bestrebt, bestehende LLMs auf ihre ganz konkreten Bedürfnisse zuzuschneiden – unter Verwendung ihrer eigenen privaten Daten.
Retrieval Augmented Generation (RAG) ist ein wichtiger Mechanismus für Unternehmen, um beim Einsatz von Open-Source- wie auch proprietären LLMs eine bessere Leistung zu erzielen. Bei RAG kommt eine Vektordatenbank zum Einsatz, um die zugrundeliegenden Modelle mit privaten Daten zu trainieren und so präzisere Ergebnisse zu generieren, die für die spezifischen Abläufe im Unternehmen maximal relevant sind.
Die Unternehmen setzen eine solche Anpassung offensiv um. Daher hat die Nutzung von Vektordatenbanken im vergangenen Jahr um 377 % zugenommen.
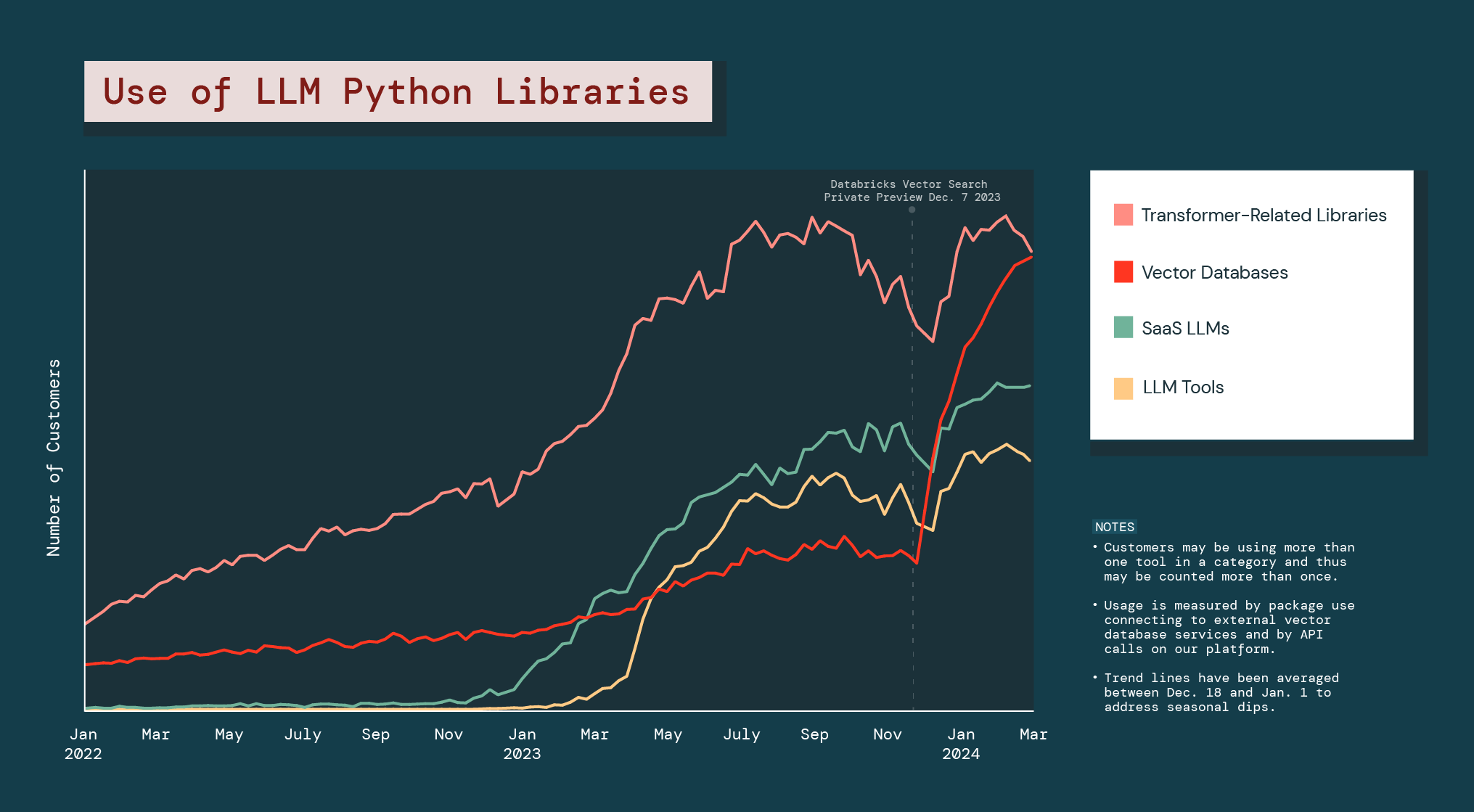
Seit dem Start der Public Preview von Databricks Vector Search ist die gesamte Kategorie der Vektordatenbanken um 186 % gewachsen – und damit deutlich stärker als alle anderen LLM-Python-Bibliotheken.
Die explosionsartige Zunahme bei den Vektordatenbanken verdeutlicht, dass Unternehmen nach GenAI-Alternativen suchen, die ihnen bei der Lösung von Problemen helfen oder Möglichkeiten eröffnen, die speziell auf ihr Geschäftsfeld zugeschnitten sind. Außerdem legt sie nahe, dass Unternehmen im Betrieb künftig wahrscheinlich auf eine Kombination aus verschiedenartigen GenAI-Modellen setzen werden.
Open-Source-LLMs
Unternehmen bevorzugen kleine Modelle
Einer der größten Vorteile von Open-Source-LLMs ist die Möglichkeit, sie für bestimmte Anwendungsfälle anzupassen – insbesondere im Unternehmensumfeld. In der Praxis probieren Kunden oft viele Modelle und Modellfamilien aus. Wir haben die Anwendung der Open-Source-Modelle von Meta Llama und Mistral, den beiden größten Playern, analysiert.
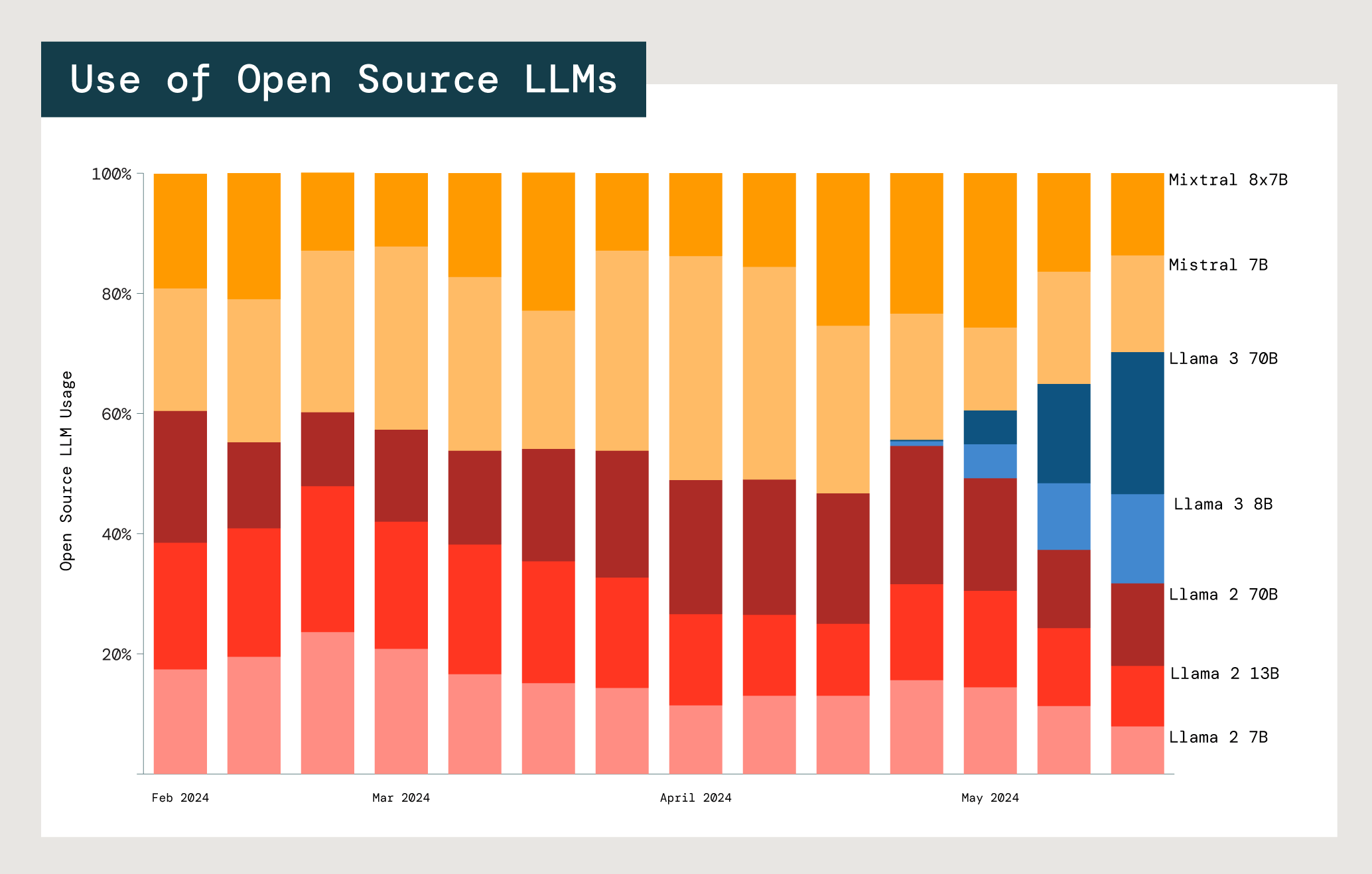
Relative Nutzung der Open-Source-Modelle Mistral und Meta Llama in Databricks-Foundation-Modell-APIs.
Jedes Modell erfordert einen Kompromiss zwischen Kosten, Latenz und Leistung. Die beiden kleinsten Meta Llama 2-Modelle (7B und 13B) werden deutlich häufiger verwendet als das größte Modell, Meta Llama 2 70B. 77% der Llama- und Mistral-Nutzer bevorzugen Modelle mit 13 Milliarden Parametern oder weniger. Das deutet darauf hin, dass Unternehmen bei Auswahl des passenden Modells für einen bestimmten Anwendungsfall Kosten und Nutzen der Modellgröße abwägen.
