Die Datenbank, die Ihre KI-Agenten verdienen
Lakebase ist Ihr serverloses Postgres für skalierende Applikationen



Die Databricks
Data Intelligence-Plattform
Databricks bringt KI zu Ihren Daten – damit auch Sie KI in die Welt bringen können.Erfolg haben mit KI
Entwickeln Sie generative KI-Anwendungen für Ihre Daten, ohne dabei Datenschutz oder Kontrolle aufzugeben.
Erkenntnisse demokratisieren
Ermöglichen Sie es allen Angehörigen Ihres Unternehmens, Erkenntnisse aus Ihren Daten in natürlicher Sprache zu gewinnen.
Kostenreduzierung
Steigern Sie die Effizienz und reduzieren Sie die Komplexität, indem Sie Ihren Ansatz für Daten, KI und Governance vereinheitlichen.

Alle Ihre Daten + KI vereinheitlichen
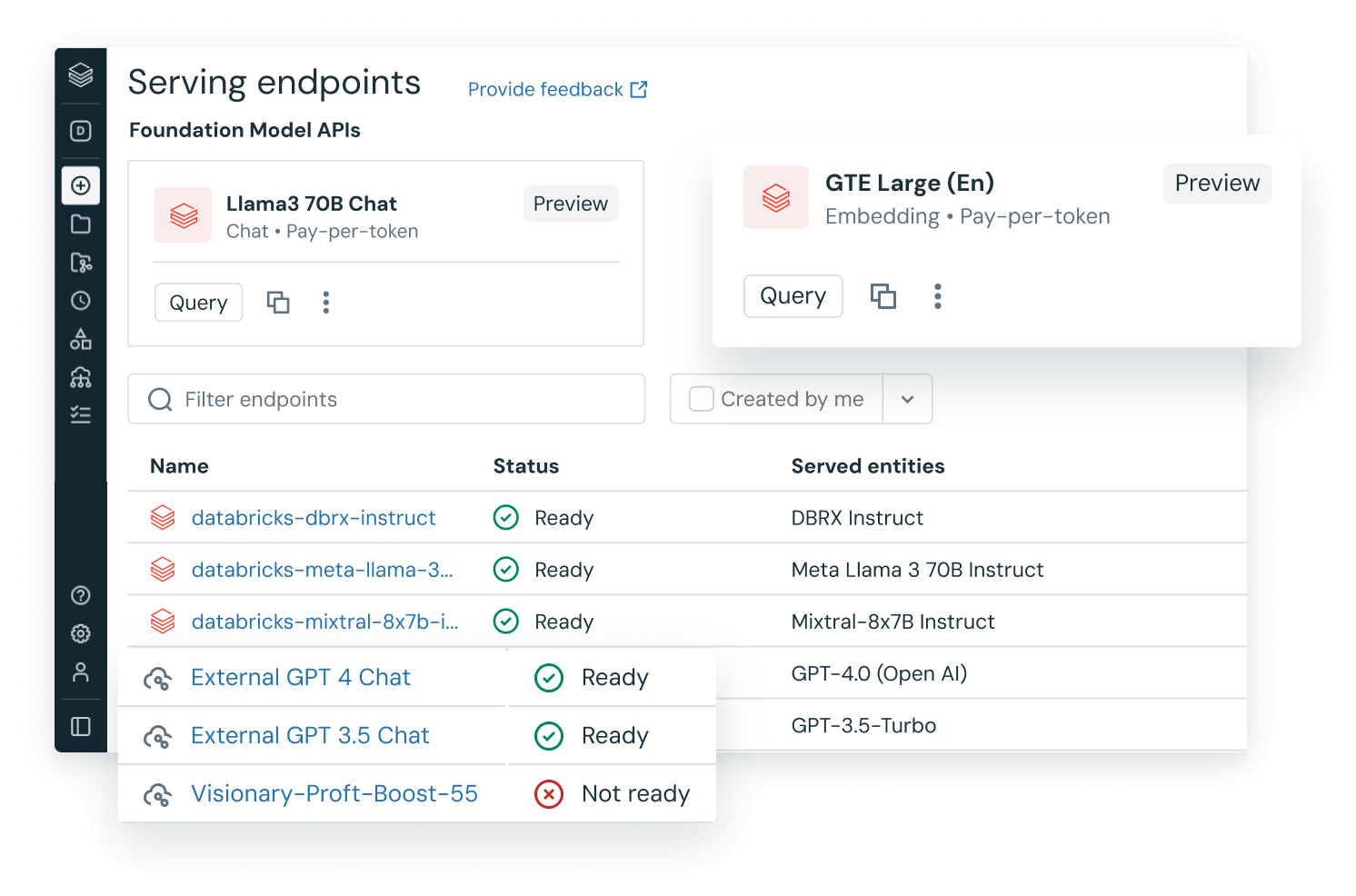
Mit einem datenorientierten Ansatz bessere KI entwickeln
Erstklassige Modelle werden mit erstklassigen Daten erstellt. Mit Databricks werden Herkunft, Qualität, Kontrolle und Datenschutz während des gesamten KI-Workflows aufrechterhalten. So bekommen Sie ein vollständiges Toolset für jeden KI-Anwendungsfall.
✔ Eigene generative KI-Modelle erstellen, abstimmen und anwenden
✔ Nachverfolgung und Governance von Experimenten automatisieren
✔ Modelle im großen Umfang implementieren und überwachen
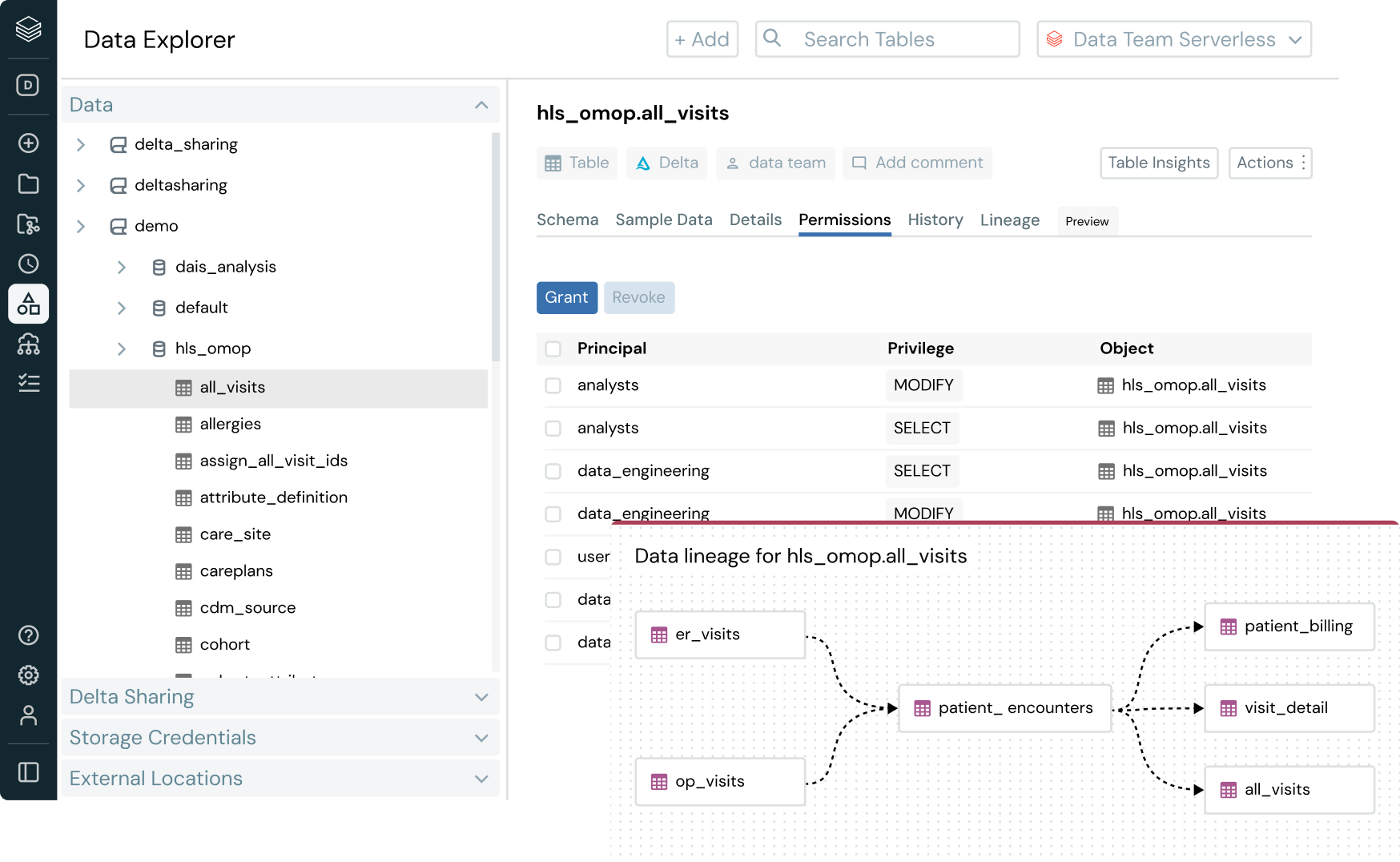
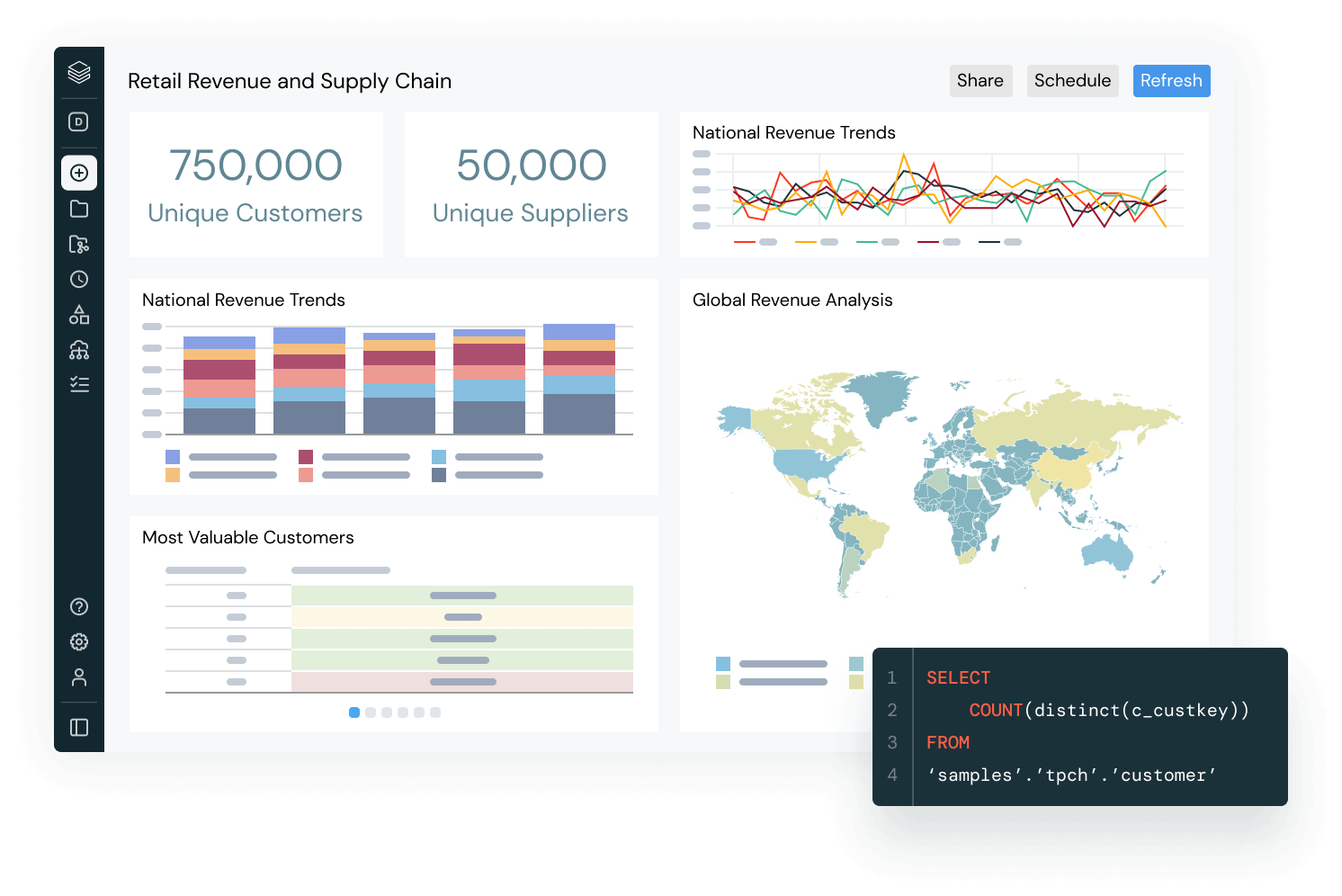
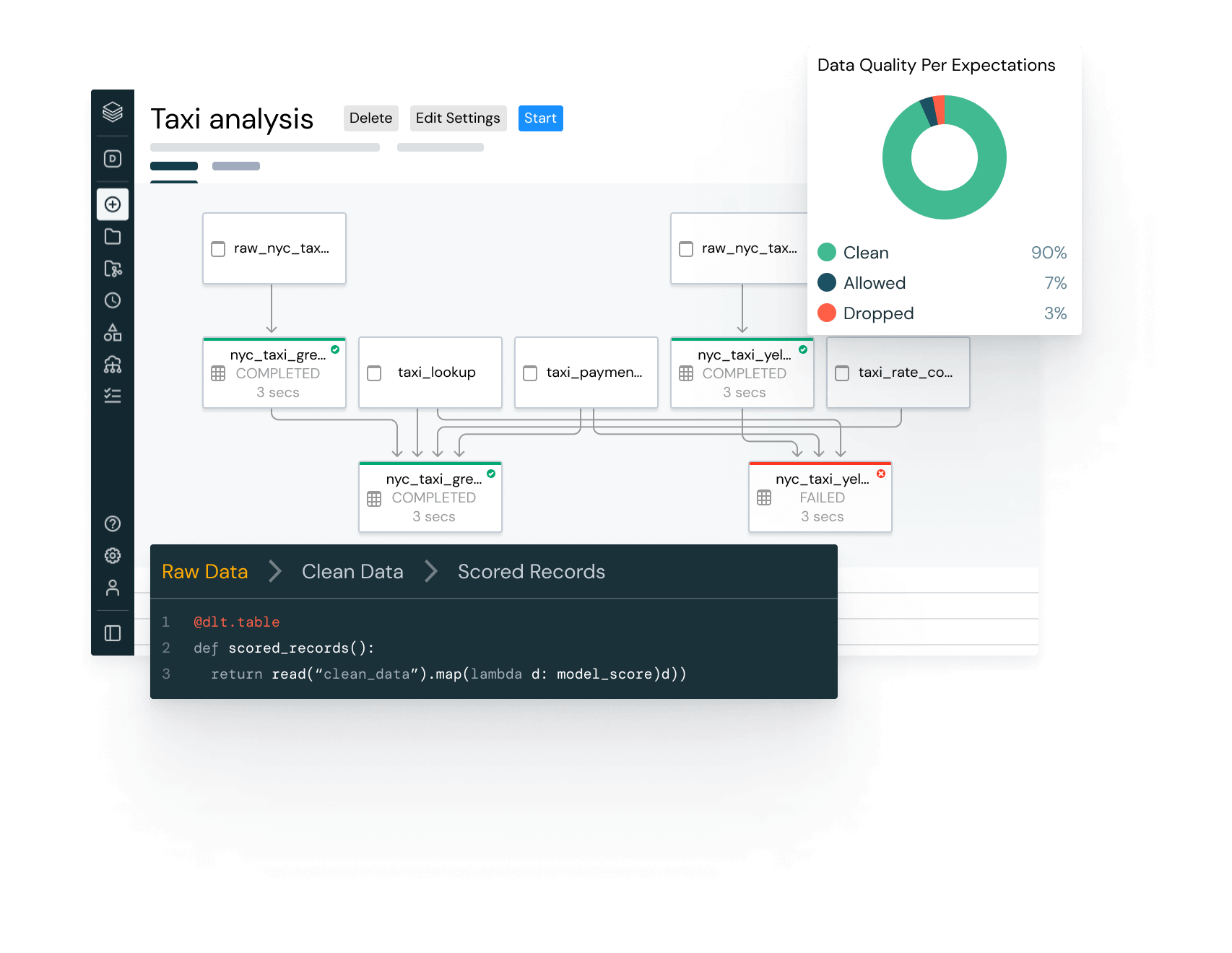
KI bietet einfach mehr
Hilfe erhalten
Alles, was Sie für den Erfolg mit Lakehouse brauchen
Das ist neu
Unsere aktuellen Ankündigungen, Expertenanalysen und Veranstaltungen
Im Rampenlicht



Möchten Sie ein Daten- und KI-Unternehmen werden?
Machen Sie die ersten Schritte Ihrer Transformation