Automation Bias
Was ist Automation Bias?
Als Automation Bias bezeichnet man ein übermäßiges Vertrauen in automatisierte Hilfsmittel und Systeme zur Entscheidungsfindung. Mit der zunehmenden Verfügbarkeit automatisierter Entscheidungshilfen werden diese immer häufiger in kritischen Entscheidungskontexten wie etwa auf Intensivstationen oder im Flugzeugcockpit eingesetzt. Menschen neigen dazu, den Weg des geringsten kognitiven Aufwands einzuschlagen und der „Automatisierung“ dabei tendenziell den Vorzug zu geben. Das gleiche Konzept lässt sich auf die grundlegende Funktionsweise von KI und Automatisierung übertragen, die hauptsächlich auf dem Lernen aus großen Datenmengen basiert. Diese Form der Berechnung geht davon aus, dass sich die Dinge in der Zukunft nicht grundlegend ändern werden. Ein weiterer zu berücksichtigender Aspekt ist das Risiko, dass bei der Verwendung fehlerhafter Trainingsdaten auch das Erlernte fehlerhaft ist.
Was ist Machine Bias?
Machine Bias bezieht sich darauf, wie Algorithmen die Voreingenommenheit des verwendeten Algorithmus oder der verwendeten Eingabedaten zeigen. Künstliche Intelligenz (KI) hilft uns heute, neue Erkenntnisse aus Daten zu gewinnen und die menschliche Entscheidungsfindung zu verbessern. Ein Beispiel dafür ist die Gesichtserkennung, mit deren Hilfe wir uns auf unseren Smartphones anmelden können. Unbeabsichtigte Verzerrungen können viele Ursachen haben (Wikipedia listet alleine 184 davon auf); die drei Wichtigsten sind:
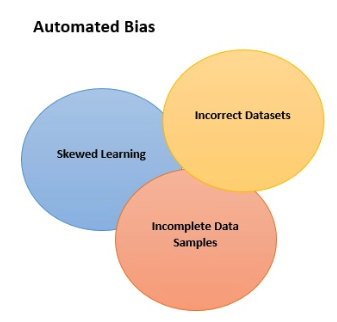
- Unvollständige Datenproben
- Fehlerhafte Datasets
- Lernverzerrungen, die im Laufe der Zeit durch Interaktionen entstehen (auch „Interaction Bias“ genannt)
 Wir können Automation Bias bei Daten verhindern, indem wir ein umfassendes und breites Dataset verwenden, das alle möglichen Edge-Anwendungsfälle widerspiegelt. Je umfassender das Dataset ist, desto genauer werden die KI-Vorhersagen sein. Werfen wir einen Blick auf einige Punkte, die Sie bei der Arbeit an Ihrer KI berücksichtigen sollten. Wählen Sie das richtige Lernmodell für das Problem. Es gibt wahrscheinlich kein allgemeingültiges Modell, dem Sie folgen können, um Bias vollständig zu vermeiden, aber es gibt Parameter, die Ihrem Team bei der Entwicklung helfen können. Sie müssen das beste Modell für die jeweilige Situation identifizieren und mögliche Fehler beheben, bevor Sie sich darauf festlegen. Wählen Sie einen repräsentativen Trainingsdatensatz. Stellen Sie sicher, dass Sie Trainingsdaten verwenden, die vielfältig sind und verschiedene Gruppen umfassen. Überwachen Sie die Performance anhand realer Daten. Beim Entwickeln von Algorithmen sollten Sie möglichst reale Anwendungen simulieren.
Wir können Automation Bias bei Daten verhindern, indem wir ein umfassendes und breites Dataset verwenden, das alle möglichen Edge-Anwendungsfälle widerspiegelt. Je umfassender das Dataset ist, desto genauer werden die KI-Vorhersagen sein. Werfen wir einen Blick auf einige Punkte, die Sie bei der Arbeit an Ihrer KI berücksichtigen sollten. Wählen Sie das richtige Lernmodell für das Problem. Es gibt wahrscheinlich kein allgemeingültiges Modell, dem Sie folgen können, um Bias vollständig zu vermeiden, aber es gibt Parameter, die Ihrem Team bei der Entwicklung helfen können. Sie müssen das beste Modell für die jeweilige Situation identifizieren und mögliche Fehler beheben, bevor Sie sich darauf festlegen. Wählen Sie einen repräsentativen Trainingsdatensatz. Stellen Sie sicher, dass Sie Trainingsdaten verwenden, die vielfältig sind und verschiedene Gruppen umfassen. Überwachen Sie die Performance anhand realer Daten. Beim Entwickeln von Algorithmen sollten Sie möglichst reale Anwendungen simulieren.