Extract Transform Load (ETL)

Was ist ETL?
Da die Menge an Daten, Datenquellen und Datentypen in Unternehmen wächst, wird es immer wichtiger, diese Daten in Analytics-, Data-Science- und Machine-Learning-Initiativen zu nutzen, um geschäftliche Erkenntnisse abzuleiten. Die Notwendigkeit, diese Initiativen zu priorisieren, erhöht den Druck auf die Data-Engineering-Teams, da die Verarbeitung der ungeordneten Rohdaten in bereinigte, aktuelle und belastbare Daten ein entscheidender Schritt ist, bevor diese Initiativen weiterverfolgt werden können. Bei ETL (Extract, Transform, Load) werden Daten aus verschiedenen Quellen extrahiert, in nutzbare und vertrauenswürdige Ressourcen transformiert und dann in die Systeme geladen, auf die Endbenutzer zugreifen und die sie nachgelagert verwenden können, um geschäftliche Probleme zu lösen.
Ähnliche Themen erkunden



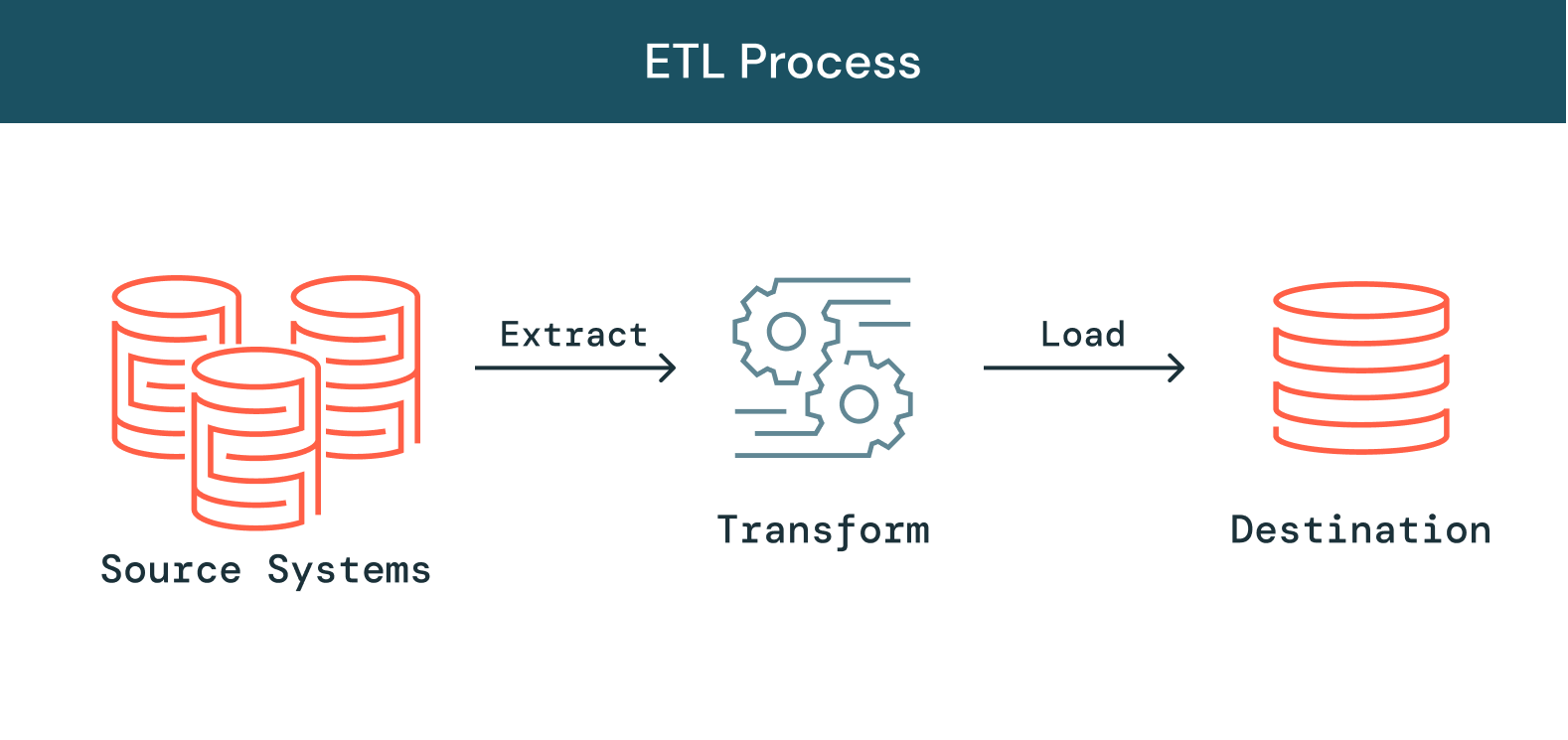
Wie funktioniert ETL?
Extrahieren
Der erste Schritt dieses Prozesses besteht darin, Daten aus den Zielquellen zu extrahieren, die normalerweise heterogen sind, z. B. Geschäftssysteme, APIs, Sensordaten, Marketingtools, Transaktionsdatenbanken usw. Wie Sie sehen, handelt es sich bei einigen dieser Datentypen wahrscheinlich um strukturierte Ausgaben weit verbreiteter Systeme, bei anderen hingegen um halbstrukturierte JSON-Serverprotokolle. Für die Durchführung der Extraktion gibt es verschiedene Möglichkeiten:
-
Teilextraktion: Der einfachste Weg, die Daten abzurufen, besteht darin, dass Sie sich vom Quellsystem benachrichtigen lassen, wenn ein Datensatz geändert wurde.
-
Teilextraktion (mit Update-Benachrichtigung): Zwar können nicht alle Systeme im Update-Fall Benachrichtigungen versenden, aber sie können auf die geänderten Datensätze verweisen und einen Auszug dieser Datensätze bereitstellen.
-
Vollständige Extraktion: Es gibt bestimmte Systeme, die überhaupt nicht erkennen, welche Daten geändert wurden. In diesem Fall ist eine vollständige Extraktion die einzige Möglichkeit, die Daten aus dem System zu extrahieren. Für diese Methode ist eine Kopie des letzten Auszugs im gleichen Format erforderlich, damit Sie die vorgenommenen Änderungen identifizieren können.
Transformieren
Der zweite Schritt besteht darin, die aus den Quellen extrahierten Rohdaten in ein Format zu transformieren, das von verschiedenen Anwendungen verwendet werden kann. In dieser Phase werden die Daten bereinigt, zugeordnet und transformiert, häufig in ein bestimmtes Schema, damit sie den betrieblichen Anforderungen entsprechen. Dieser Prozess umfasst mehrere Arten der Transformation, die die Qualität und Integrität der Daten sicherstellen. Daten werden normalerweise nicht direkt in die Zieldatenquelle geladen, sondern üblicherweise in eine Staging-Datenbank hochgeladen. Dieser Schritt gewährleistet ein schnelles Rollback für den Fall, dass etwas nicht wie geplant verläuft. In dieser Phase haben Sie die Möglichkeit, Prüfberichte zur Compliance mit gesetzlichen Vorschriften zu erstellen oder Datenprobleme zu diagnostizieren und zu beheben.
Laden
Bei der Ladefunktion handelt es sich um den Prozess des Schreibens konvertierter Daten aus einem Staging-Bereich in eine Zieldatenbank, unabhängig davon, ob diese zuvor vorhanden war oder nicht. Abhängig von den Anforderungen der Anwendung kann dieser Prozess entweder recht einfach oder kompliziert sein. Jeder dieser Schritte kann mit ETL-Tools oder benutzerdefiniertem Code durchgeführt werden.
Was ist eine ETL-Pipeline?
Eine ETL-Pipeline (oder Datenpipeline) bezeichnet den Mechanismus, nach dem ETL-Prozesse ablaufen. Datenpipelines sind eine Reihe von Tools und Aktivitäten zum Verschieben von Daten von einem System mit seiner Art der Datenspeicherung und -verarbeitung in ein anderes System, in dem sie anders gespeichert und verwaltet werden können. Darüber hinaus ermöglichen Pipelines das automatische Abrufen von Information aus vielen unterschiedlichen Quellen und deren anschließende Transformation und Konsolidierung in einem leistungsstarken Datenspeicher.
Herausforderungen bei ETL
Während ETL unerlässlich ist, ist das Erstellen und Verwalten zuverlässiger Datenpipelines angesichts dieser exponentiellen Zunahme von Datenquellen und -typen zu einem der anspruchsvolleren Teile des Data Engineering geworden. Das Erstellen von Pipelines, die Datenzuverlässigkeit gewährleistet, ist von Anfang an langsam und schwierig. Datenpipelines werden mit komplexem Code und eingeschränkter Wiederverwendbarkeit erstellt. Eine in eine Umgebung integrierte Pipeline kann nicht in einer anderen verwendet werden, selbst wenn der zugrunde liegende Code sehr ähnlich ist, was bedeutet, dass Data Engineers oft der Engpass sind und das Rad jedes Mal neu erfinden müssen. Über die Pipelineentwicklung hinaus ist die Verwaltung der Datenqualität in immer komplexeren Pipeline-Architekturen schwierig. Oftmals wird zugelassen, dass fehlerhafte Daten unentdeckt durch eine Pipeline fließen, wodurch das gesamte Dataset entwertet wird. Um die Qualität aufrechtzuerhalten und die Gewinnung zuverlässige Informationen sicherzustellen, müssen Data Engineers umfangreichen benutzerdefinierten Code schreiben, um Qualitätsprüfungen und Validierungen in jedem Schritt der Pipeline durchzuführen. Mit zunehmender Größe und Komplexität der Pipelines steigt auch die operative Belastung der Unternehmen bei der Verwaltung der Pipelines, was die Aufrechterhaltung der Datenzuverlässigkeit unglaublich schwierig macht. Die Datenverarbeitungsinfrastruktur muss eingerichtet, skaliert, neu gestartet, gepatcht und aktualisiert werden – was zu erhöhtem Zeit- und Kostenaufwand führt. Pipelineausfälle sind schwer zu erkennen und noch schwieriger zu beheben – aufgrund mangelnder Transparenz und fehlender Tools. Unabhängig von all diesen Herausforderungen ist zuverlässiges ETL ein absolut entscheidender Prozess für jedes Unternehmen, das Erkenntnisse gewinnen möchte. Ohne ETL-Tools, die einen Standard an Datenzuverlässigkeit aufrechterhalten, müssen Teams im gesamten Unternehmen blind Entscheidungen ohne verlässliche Metriken oder Berichte treffen. Um weiter zu skalieren, benötigen Data Engineers Tools zur Rationalisierung und Demokratisierung von ETL, die den ETL-Lebenszyklus vereinfachen und es Datenteams ermöglichen, ihre eigenen Datenpipelines zu erstellen und zu nutzen, um schneller zu Erkenntnissen zu gelangen.
Automatisieren zuverlässiger ETL-Vorgänge in Delta Lake
Delta Live Tables (DLT) reduziert den Entwicklungs- und Verwaltungsaufwand zuverlässiger Datenpipelines, die hochwertige Daten in Delta Lake bereitstellen. DLT unterstützt Data-Engineering-Teams bei der Vereinfachung der ETL-Entwicklung und -Verwaltung mit deklarativer Pipelineentwicklung, automatischen Datentests und umfassenden Einblicken in Monitoring und Wiederherstellung.
