Was ist MLOps?
Praktiken und Werkzeuge für die Bereitstellung, Überwachung und Steuerung von ML-Modellen in der Produktion, die die Zusammenarbeit zwischen Entwicklung und Betrieb für zuverlässige, reproduzierbare ML-Systeme verbinden.
Summary
- Deckt den gesamten ML-Lebenszyklus ab, einschließlich Experimentverfolgung, Modellversionierung, Feature-Stores, automatisierten Tests, CI/CD-Pipelines, Containerisierung und Modellregistrierung für reproduzierbare Entwicklungs- und Bereitstellungsworkflows.
- Implementiert Überwachungssysteme zur Erfassung von Modellleistungsmetriken, Datenabweichungen, Vorhersagelatenz, Ressourcennutzung und geschäftlichen KPIs mit automatisierten Alarmierungs- und Retraining-Triggern zur Sicherstellung der Produktionsmodellqualität.
- Erfüllt Governance-Anforderungen durch Audit-Trails, Zugriffskontrollen, Nachverfolgung der Modellherkunft, Erklärbarkeitstools und Compliance-Dokumentation, um verantwortungsvolle KI-Praktiken und die Einhaltung regulatorischer Vorgaben zu ermöglichen.
Was ist MLOps?
MLOps (Machine Learning Operations) ist eine Kernfunktion des Machine Learning Engineering. Es legt den Schwerpunkt auf die Prozessoptimierung bei der Überführung von Machine-Learning-Modellen in die Produktion sowie auf deren anschließende Wartung und Überwachung. MLOps ist eine kollaborative Funktion, an der häufig Data Scientists, DevOps Engineers und die IT beteiligt sind.
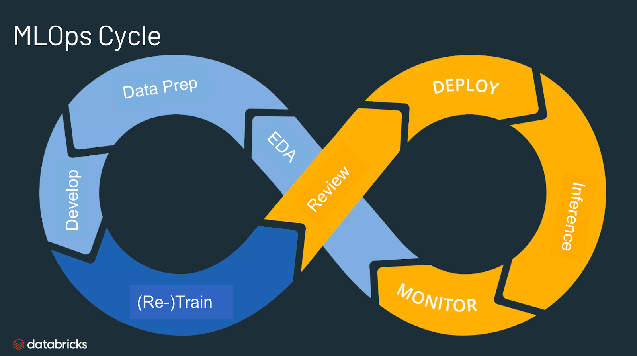
Welchen Nutzen bietet MLOps?
MLOps ist ein sinnvoller Ansatz für die Erstellung und Qualitätsprüfung von ML- und KI-Lösungen. Durch das Implementieren eines MLOps-Ansatzes können Data Scientists und ML Engineers gemeinsam durch die Kombination von CI/CD-Praktiken (Continuous Integration/Continuous Deployment) mit angemessenen Funktionen für Überwachung, Bewertung und Governance von ML-Modellen Modellentwicklung und -produktion beschleunigen.
Warum brauchen wir MLOps?
Es ist schwierig, maschinelles Lernen in die Produktion zu überführen. Ein ML-Lebenszyklus besteht aus vielen komplexen Komponenten wie Datenerfassung, Datenaufbereitung, Training, Modelloptimierung, Modellimplementierung, Überwachung, Erklärbarkeit und vielem mehr. Zudem erfordert er Zusammenarbeit und übergreifende Aufgabenverteilung mehrerer Teams – vom Data Engineering über Data Science bis hin zum ML Engineering. Ebenso ist eine betriebliche Konsequenz notwendig, um alle diese Prozesse zu synchronisieren und gemeinsam zu bearbeiten. MLOps umfasst das Experimentieren, Iterieren und fortlaufende Verbessern des ML-Lebenszyklus.
Worin bestehen die Vorteile von MLOps?
Die wesentlichen Vorteile von MLOps sind Effizienz, Skalierbarkeit und Risikominderung. Effizienz: MLOps ermöglicht Datenteams eine schnellere Modellentwicklung, die Bereitstellung hochwertigerer ML-Modelle sowie eine schnellere Implementierung und Produktion. Skalierbarkeit: MLOps bietet außerdem umfassende Skalierbarkeit und Verwaltung, sodass Tausende von CI/CD-Modellen beaufsichtigt, gesteuert, verwaltet und überwacht werden können. Insbesondere sorgt MLOps für die Reproduzierbarkeit von ML-Pipelines, wodurch eine engere Zusammenarbeit zwischen Datenteams ermöglicht, Konflikte mit Entwicklern und der IT reduziert und die Release-Geschwindigkeit beschleunigt werden. Risikominderung: ML-Modelle erfordern häufig eine behördliche Prüfung und Driftkontrolle. MLOps bietet mehr Transparenz, erlaubt eine schnellere Reaktion auf solche Anfragen und gewährleistet eine bessere Compliance im Hinblick auf Unternehmens- oder Branchenrichtlinien.
Woraus setzt sich MLOps zusammen?
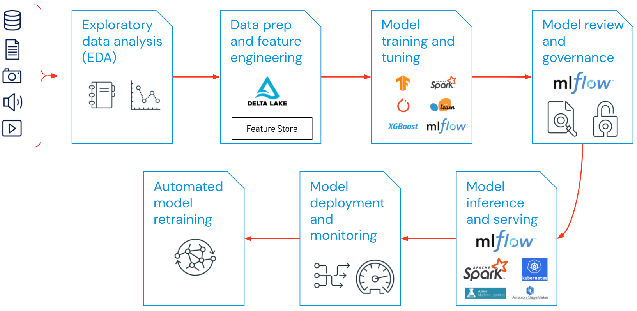
Das MLOps-Spektrum eines ML-Projekts kann so breit oder tief sein, wie es das Projekt erfordert. In bestimmten Fällen kann MLOps alles umfassen – von der Pipeline bis zur Modellproduktion –, während für andere Projekte vielleicht nur die MLOps-Implementierung des Modellbereitstellungsprozesses erforderlich ist. Die meisten Unternehmen wenden die MLOps-Prinzipien wie folgt an:
- EDA (Exploratory Data Analysis, explorative Datenanalyse)
- Datenaufbereitung und Feature Engineering
- Modelltraining und -optimierung
- Modellprüfung und Governance
- Modellinferenz und -bereitstellung
- Modellüberwachung
- Automatisiertes Neutrainieren des Modells
Gartner®: Databricks als Leader für Cloud-Datenbanken

Worin bestehen bewährte Verfahren für MLOps?
Die bewährten Verfahren für MLOps lassen sich anhand der Phase abgrenzen, in der sie jeweils angewendet werden.
- EDA(Explorative Data Analysis, explorative Datenanalyse): Erkunden, teilen und bereiten Sie Daten iterativ für den ML-Lebenszyklus auf. Zu diesem Zweck erstellen Sie Datasets, Tabellen und Visualisierungen, die reproduziert, bearbeitet und freigegeben werden können.
- Datenaufbereitung und Feature Engineering: Transformieren, aggregieren und deduplizieren Sie Daten iterativ, um besser abgestimmte Features zu erstellen. Am wichtigsten ist es, die Features über einen so genannten Feature Store für alle Datenteams sichtbar und gemeinsam nutzbar zu machen.
- Modelltraining und -optimierung: Nutzen Sie beliebte Open-Source-Bibliotheken wie scikit-learn und hyperopt, um die Modellperformance zu trainieren und zu optimieren. Eine einfachere Alternative wären automatisierte Tools für maschinelles Lernen wie AutoML, mit deren Hilfe Sie automatisch Testausführungen durchführen und überprüfbaren und implementierbaren Code erstellen können.
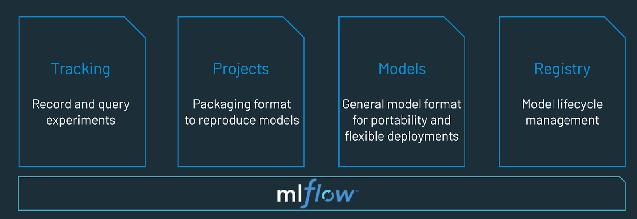
- Modellüberprüfung und Governance: Erfassen Sie Modellherkunft und Modellversionen und verwalten Sie Modellartefakte und -übergänge über den gesamten Lebenszyklus hinweg. Nutzen Sie eine Open-Source-Plattform für MLOps wie etwa MLflow, um ML-Modelle zu entdecken, zu teilen und gemeinsam zu bearbeiten.
- Modellinferenz und -bereitstellung: Ermitteln Sie die Refresh-Häufigkeit für das Modell, Inferenzbedarfszeiten und ähnliche Produktionsspezifika mithilfe von Tests und QA. Verwenden Sie CI/CD-Tools wie Repos und Orchestrators (unter Anwendung der DevOps-Prinzipien), um die Vorproduktions-Pipeline zu automatisieren.
- Modellbereitstellung und -überwachung: Automatisieren Sie das Erstellen von Berechtigungen und Clustern, um registrierte Modelle in die Produktion zu überführen. Aktivieren Sie REST-API-Modellendpunkte.
- Automatisiertes Neutrainieren von Modellen: Erstellen Sie Alerts und Automatisierungen, um Korrekturmaßnahmen zu ergreifen, wenn das Modell aufgrund von Unterschieden zwischen den Trainings- und den Inferenzdaten Abweichungen aufweist.
Worin besteht der Unterschied zwischen MLOps und DevOps?
MLOps ist eine Reihe von Entwicklungspraktiken, die speziell für ML-Projekte gelten und sich an den weiter verbreiteten DevOps-Prinzipien im Software-Engineering orientieren. Während DevOps einen schnellen, kontinuierlich iterativen Ansatz für die Auslieferung von Anwendungen vermittelt, nutzt MLOps dieselben Prinzipien, um ML-Modelle in die Produktion zu überführen. In beiden Fällen ist das Ergebnis eine höhere Softwarequalität, schnelleres Patching, beschleunigte Releases und eine höhere Kundenzufriedenheit.
Unterscheidet sich das Training von LLMs von herkömmlichem MLOps?
Zwar gelten viele MLOps-Konzepte nach wie vor, doch sind beim Training von Large-Language-Modellen (LLMs) wie Dolly andere Überlegungen zu berücksichtigen. Wir wollen einige der zentralen Aspekte abhandeln, in denen sich das LLM-Training vom herkömmlichen MLOps-Ansatz unterscheiden kann:
- Datenverarbeitungsressourcen: Training und Feinabstimmung von LLMs erfordern in der Regel um mehrere Größenordnungen umfangreichere Berechnungen mit großen Datasets. Zur Beschleunigung dieses Vorgangs wird spezielle Hardware wie GPUs für einen deutlich schnelleren datenparallelen Betrieb eingesetzt. Der Zugriff auf diese Datenverarbeitungsressourcen ist für das Training wie auch für die Implementierung von LLMs von entscheidender Bedeutung. Zudem können Inferenzkosten Komprimierungs- und Destillierverfahren für die Modelle wichtig machen.
- Transfer Learning: Anders als zahlreiche herkömmliche ML-Modelle, die von Grund auf neu erstellt oder trainiert werden, steht am Anfang eines LLM häufig ein Grundmodell, das dann mit neuen Daten verfeinert wird, um die Performance in einem ganz konkreten Bereich zu verbessern. Solche Feinabstimmungen ermöglichen für bestimmte Anwendungen eine Leistung nach dem Stand der Technik – mit weniger Daten und weniger Datenverarbeitungsressourcen.
- Menschliches Feedback: Eine der größten Verbesserungen beim Training von LLMs ist RLHF (Reinforcement Learning from Human Feedback, verstärkendes Lernen durch menschliches Feedback). Generell gilt: Da LLM-Aufgaben häufig ergebnisoffen sind, ist das menschliche Feedback der Endbenutzer Ihrer Anwendung oft entscheidend für die Bewertung der LLM-Performance. Die Integration einer solchen Feedbackschleife in Ihre LLMOps-Pipeline kann oft zu einer deutlichen Leistungssteigerung beim von Ihnen trainierten LLM beitragen.
- Hyperparameter-Tuning: Beim klassischen maschinellen Lernen geht es beim Hyperparameter-Tuning oft um die Senkung der Fehlerrate oder die Verbesserung anderer Metriken. Für LLMs ist das Tuning außerdem wichtig, um die Kosten und den Datenverarbeitungsbedarf für Training und Inferenz zu reduzieren. Beispielsweise kann die Optimierung von Batch-Größen und Lernraten einen dramatischen Einfluss auf Trainingsgeschwindigkeit und -kosten haben. Somit profitieren sowohl das klassische ML als auch LLMs von der Überwachung und Optimierung des Tunings, wenn auch mit unterschiedlichen Schwerpunkten.
- Performancemetriken: Herkömmliche ML-Modelle verfügen über sehr klar definierte Performancemetriken wie Fehlerfreiheit, AUC, F1-Score usw. Diese Metriken sind ziemlich einfach zu berechnen. Wenn es um die Bewertung von LLMs geht, gelten jedoch ganz andere Standardmetriken und -bewertungen, z. B. Bilingual Evaluation Understudy (BLEU) und Recall-Oriented Understudy for Gisting Evaluation (ROGUE), die bei der Implementierung einige zusätzliche Überlegungen erfordern.
Was ist eine MLOps-Plattform?
Eine MLOps-Plattform stellt eine kollaborative Umgebung bereit, die Data Scientists und Software Engineers iterative Datenexploration, Echtzeit-Kooperationsfunktionen für das Tracking von Experimenten, Feature-Engineering und Modellverwaltung sowie kontrollierte Modelltransition, -bereitstellung und -überwachung bietet. MLOps automatisiert die Betriebs- und Synchronisierungsaspekte des ML-Lebenszyklus.
Probieren Sie Databricks aus. Databricks ist eine vollständig verwaltete Umgebung für MLflow, die weltweit führende quelloffene MLOps-Plattform. https://www.databricks.com/try/databricks-free-ml