Was sind Spark-Anwendungen?
Erfahren Sie, wie Treiber- und Ausführungsprozesse zusammenarbeiten, um verteilte Berechnungen auf einem Cluster durchzuführen.

Summary
- Verstehen Sie die Architektur von Spark-Anwendungen, einschließlich der Funktionsweise von Treiberprozessen bei der Verwaltung der Anwendungslogik und der Koordination der Arbeit im Cluster.
- Lernen Sie, wie Executor-Prozesse zugewiesene Aufgaben ausführen und den Berechnungsstatus an den Treiber zurückmelden.
- Erfahren Sie, wie Cluster-Manager wie YARN, Mesos und Spark Standalone Ressourcen für mehrere gleichzeitig laufende Anwendungen zuweisen.
Spark-Anwendungen umfassen zwei Arten von Prozessen: einen Driver-Prozess und eine Reihe von Executor-Prozessen. Der Driver-Prozess führt Ihre main()-Funktion aus. Er befindet sich auf einem Knoten im Cluster und ist für dreierlei verantwortlich: die Verwaltung von Informationen über die Spark-Anwendung, die Beantwortung einer programm- oder benutzerseitigen Eingabe und die Analyse, Verteilung und zeitliche Planung der Arbeit für die Executors (die nur temporär definiert sind). Der Driver-Prozess ist dabei das unverzichtbare Herzstück der Spark-Anwendung: Er verwaltet während der gesamten Lebensdauer der Anwendung alle relevanten Informationen. Die Executors sind dagegen für die eigentliche Ausführung der Arbeit verantwortlich, die der Driver ihnen zuweist. Das bedeutet, dass jeder Executor nur zwei Aufgaben hat: die Ausführung des ihm vom Driver zugewiesenen Codes und die Rückmeldung des Status der Berechnung auf dem jeweiligen Executor an den Driver-Knoten.
Das Playbook für agentenbasierte KI für Unternehmen

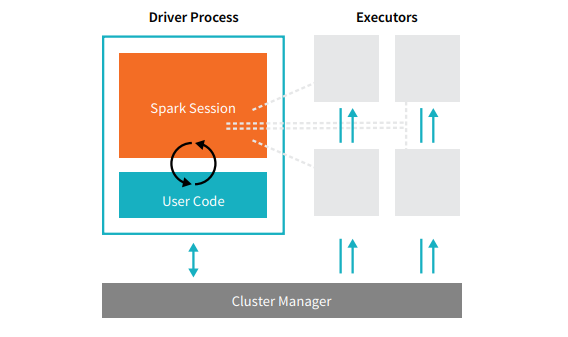
Der Clustermanager steuert die physischen Maschinen und weist den Spark-Anwendungen Ressourcen zu. Dabei sind mehrere zentrale Clustermanager wählbar: der Standalone-Clustermanager von Spark, YARN oder Mesos. Auf diese Weise können viele Spark-Anwendungen gleichzeitig auf einem Cluster ausgeführt werden. Wir werden die Clustermanager in Teil IV dieses Buches, „Produktionsanwendungen“, ausführlicher behandeln. Im obigen Diagramm sehen wir auf der linken Seite unseren Driver und rechts vier Executors. Das Konzept der Clusterknoten blieb bei dieser Darstellung unberücksichtigt. Der Benutzer kann über Konfigurationsoptionen festlegen, wie viele Executors jedem Knoten zugewiesen werden sollen. [glossary-cta]