Apache Spark
Was ist Apache Spark?
Apache Spark ist eine Open-Source-Analyse-Engine, die für Big-Data-Workloads verwendet wird. Spark bewältigt Analysen und Datenverarbeitungsaufgaben sowohl im Batch-Verfahren als auch in Echtzeit. Seinen Anfang nahm es 2009 als Forschungsprojekt an der University of California, Berkeley in den USA. Wissenschaftler suchten damals nach einer Möglichkeit, die Verarbeitung von Jobs in Hadoop-Systemen zu beschleunigen. Spark basiert auf Hadoop MapReduce, erweitert das MapReduce-Modell jedoch, um es effizient für mehr Berechnungsarten wie etwa interaktive Abfragen und Stream-Verarbeitung zu nutzen. Spark stellt native Bindungen für die Programmiersprachen Java, Scala, Python und R bereit. Außerdem enthält es verschiedene Bibliotheken zur Unterstützung der Anwendungsentwicklung für Machine Learning [MLlib], Stream-Verarbeitung [Spark Streaming] und Graph-Verarbeitung [GraphX]. Apache Spark besteht aus Spark Core und einer Reihe von Bibliotheken. Spark Core ist das Herzstück von Apache Spark und für verteilte Aufgabenübertragung, Planung und E/A-Funktionen zuständig. Die Spark Core-Engine verwendet das Konzept eines Resilient Distributed Dataset (RDD) als Grunddatentyp. Das RDD ist so angelegt, dass es den größten Teil der Berechnungskomplexität vor den Benutzern verbirgt. Spark ist in Sachen Datenverarbeitung intelligent: Daten und Partitionen werden in einem Server-Cluster zusammengeführt. Dort werden sie dann berechnet und nachfolgend entweder in einen anderen Datenspeicher verschoben oder durch ein Analysemodell geleitet. Sie werden nicht aufgefordert, den Speicherort der Dateien oder die Rechenressourcen anzugeben, die zum Speichern oder Abrufen von Dateien verwendet werden sollen. 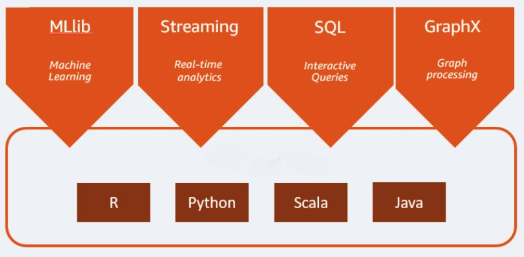
Ähnliche Themen erkunden



Welche Vorteile bietet Apache Spark?
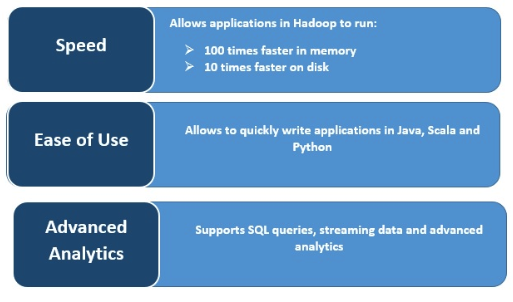
Geschwindigkeit
Die Ausführung erfolgt bei Spark rasend schnell, da die Daten für mehrere parallel stattfindende Operationen im Arbeitsspeicher zwischengespeichert werden. Das Hauptmerkmal von Spark ist seine In-Memory-Engine, die die Verarbeitungsgeschwindigkeit erhöht. Bei der In-Memory-Verarbeitung großer Datenmengen ist Spark bis zu hundertmal schneller als MapReduce, und auch bei der Verarbeitung auf Festplatte ist die Verarbeitungsgeschwindigkeit immer noch bis zu zehnmal höher. Spark ermöglicht all dies durch eine Reduzierung der Anzahl von Lese-/Schreibvorgängen auf der Festplatte.
Stream-Verarbeitung in Echtzeit
Apache Spark beherrscht Echtzeit-Streaming und kann auch weitere Frameworks integrieren. Die Datenaufnahme erfolgt bei Spark in „Mini-Batches“, an denen dann RDD-Transformationen durchgeführt werden.
Unterstützung mehrerer Workloads
Apache Spark kann mehrere Workloads ausführen. Dazu gehören interaktive Abfragen, Echtzeitanalysen, Machine Learning und Graph-Verarbeitung. Dabei kann eine Anwendung mehrere Workloads nahtlos kombinieren.
Höhere Benutzerfreundlichkeit
Die Fähigkeit, mehrere Programmiersprachen zu unterstützen, macht Spark sehr dynamisch. Sie können so schnell Anwendungen in Java, Scala, Python und R schreiben, d. h., Ihnen steht eine Vielzahl von Sprachen für die Erstellung Ihrer Anwendungen zur Verfügung.
Advanced Analytics
Spark unterstützt SQL-Abfragen, Machine Learning sowie Stream- und Graph-Verarbeitung.