Verstehen Sie, was RDDs sind und wie sie als unveränderliche, partitionierte Datensammlungen für die Parallelverarbeitung in Apache Spark dienen.
Lernen Sie die fünf wichtigsten Szenarien kennen, in denen RDDs die richtige Wahl sind, darunter unstrukturierte Daten und die Steuerung von Transformationen auf niedriger Ebene.
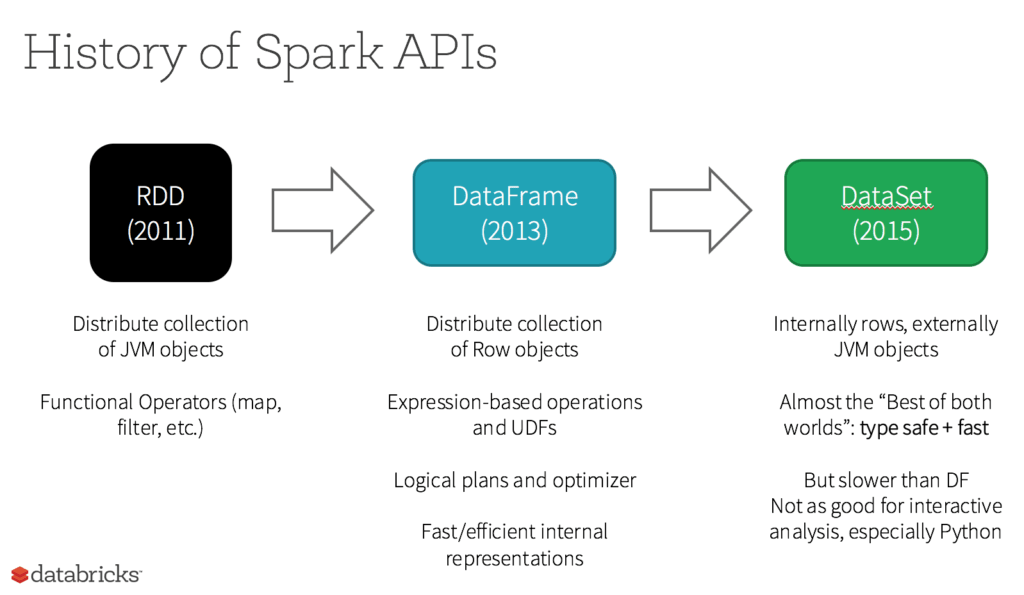
Erfahren Sie, wie RDDs mit DataFrames und Datasets zusammenhängen und wann Sie welche API verwenden sollten.
Bei RDD war von Anfang an die wichtigste benutzerorientierte API in Spark. Im Kern stellt ein RDD eine unveränderliche, verteilte Sammlung von Elementen Ihrer Daten dar, die auf die Knoten in Ihrem Cluster verteilt sind. Sie können parallel mit einer Low-Level-API eingesetzt werden, die Transformationen und Aktionen bietet.
Fünf Gründe, wann Sie RDDs verwenden sollten
Sie wollen Low-Level-Transformationen und -Aktionen durchführen und die Kontrolle über Ihren Datensatz behalten.
Ihre Daten sind unstrukturiert, wie z. B. Medienströme oder Textströme.
Sie möchten Ihre Daten lieber mit funktionalen Programmierkonstrukten als mit domänenspezifischen Ausdrücken bearbeiten
Es geht Ihnen nicht darum, bei der Verarbeitung oder beim Zugriff auf Datenattribute nach Namen oder Spalten ein Schema, wie z. B. ein Spaltenformat, vorzugeben.
Sie können auf einige Vorteile hinsichtlich Optimierung und Performance verzichten, die mit DataFrames und Datasets für strukturierte und halbstrukturierte Daten gegeben wären.
5-FACHER LEADER
Gartner®: Databricks als Leader für Cloud-Datenbanken
Werden RDDs zu Bürgern zweiter Klasse degradiert? Werden sie ausgemustert? Die Antwort lautet eindeutig NEIN! Außerdem können Sie nahtlos und nach Belieben zwischen DataFrame oder Dataset und RDDs wechseln – durch einfache API-Methodenaufrufe. Und: DataFrames und Datasets setzen auf RDDs auf.