Einheitliche und offene Governance für Daten und KI
Beseitigen Sie Silos, vereinfachen Sie die Governance und beschleunigen Sie Erkenntnisse im groß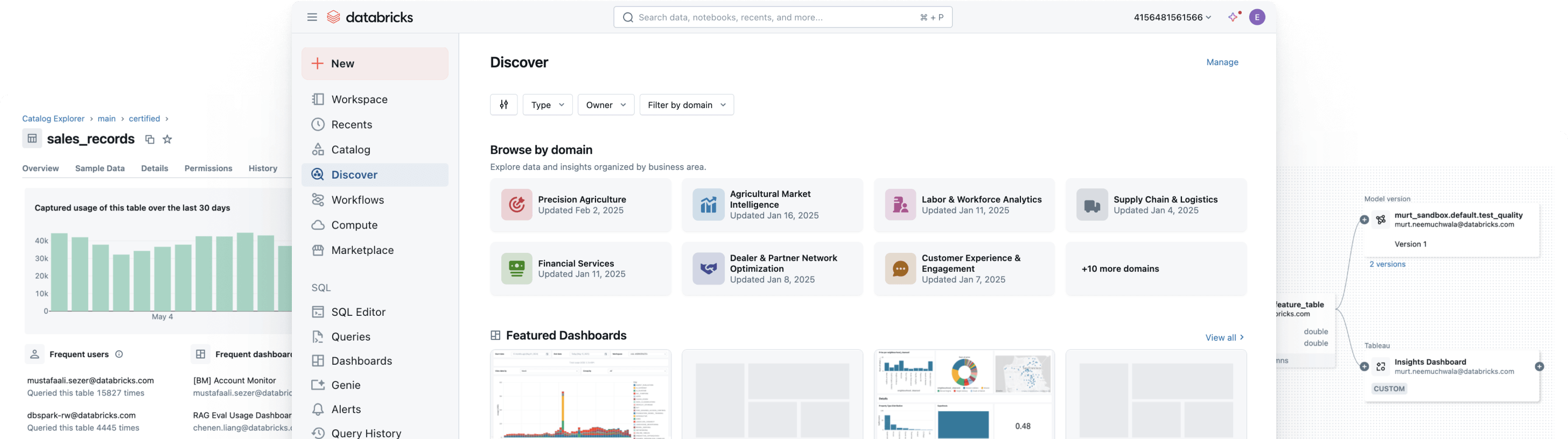
ERFOLGREICHE TEAMS SETZEN AUF EINHEITLICHE UND OFFENE GOVERNANCE
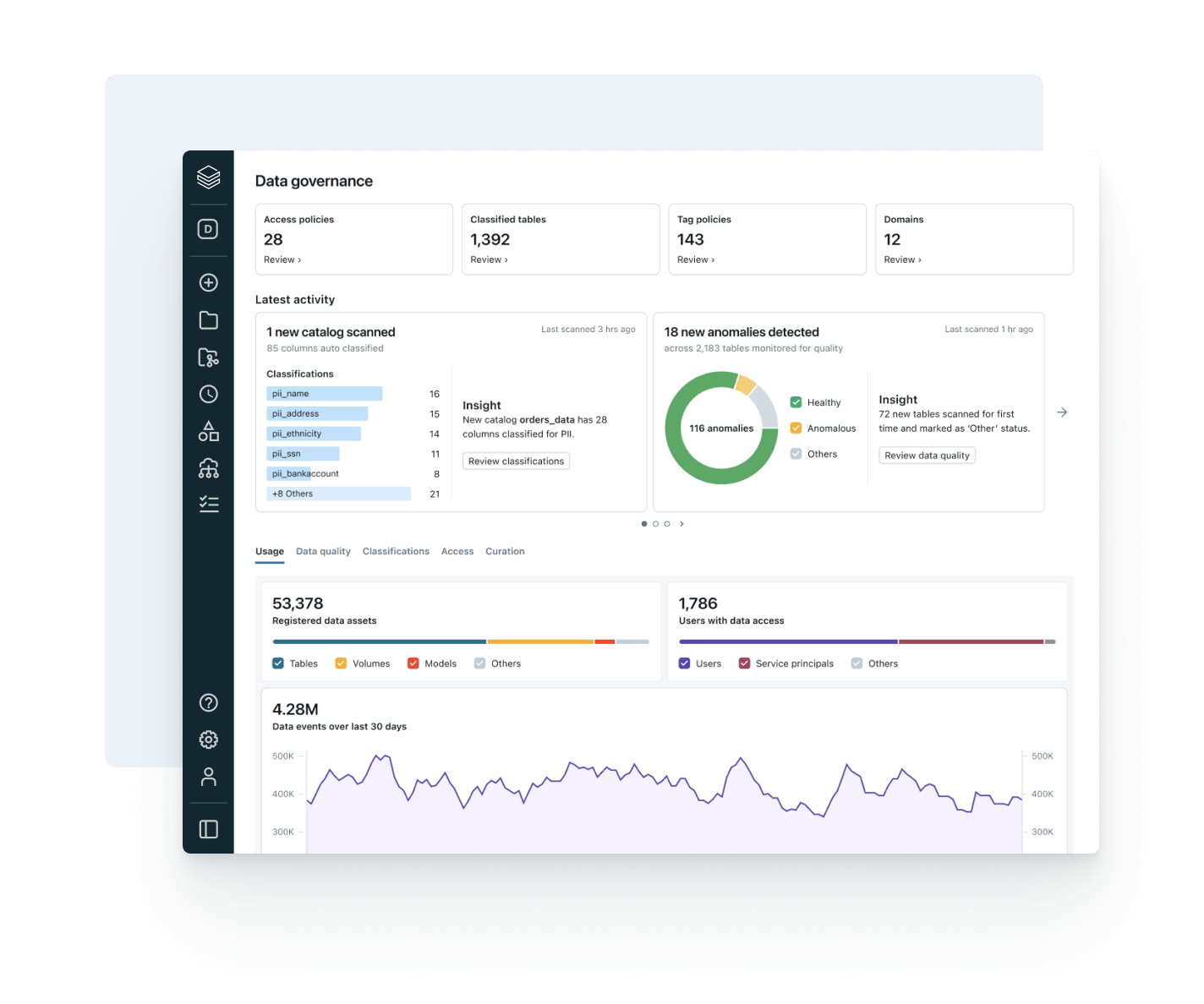
Steuern, entdecken, überwachen und teilen – alles an einem Ort
Vereinheitlichen Sie Ihre Datenlandschaft, optimieren Sie die Einhaltung von Vorschriften und erzielen Sie schnellere, vertrauenswürdige Erkenntnisse mit offener, intelligenter Governance über alle Daten- und KI-Ressourcen hinweg.Einheitliche Governance
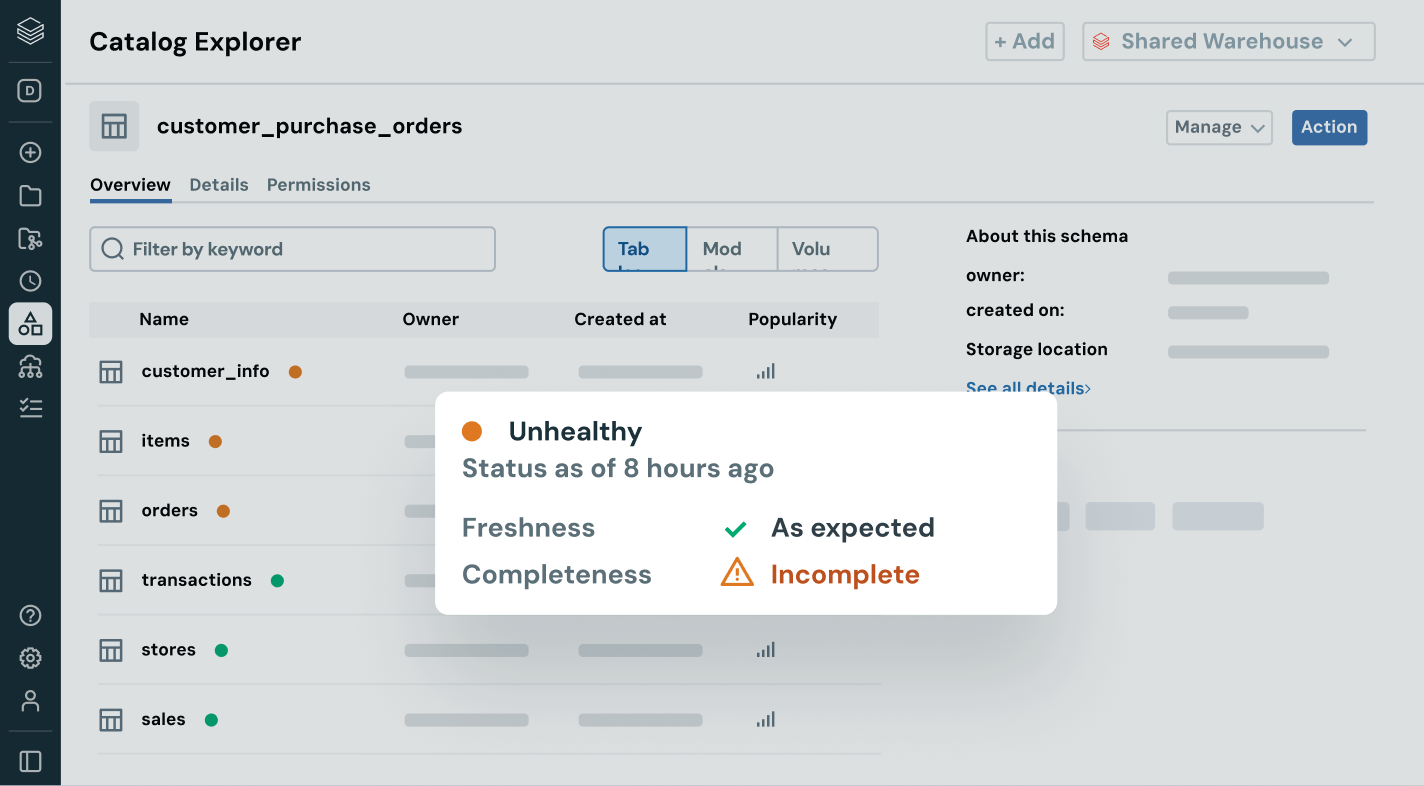
Setzen Sie konsistente Data Discovery, Zugriff, Qualitätsüberwachung und Compliance-Kontrollen über strukturierte und unstrukturierte Daten, ML-Modelle und Geschäftsmetriken hinweg durch – in jeder Cloud. Mit einheitlicher Governance können Sie Risiken reduzieren, Audits vereinfachen und den Datenzugriff beschleunigen, ohne die Kontrolle zu beeinträchtigen.
Offen
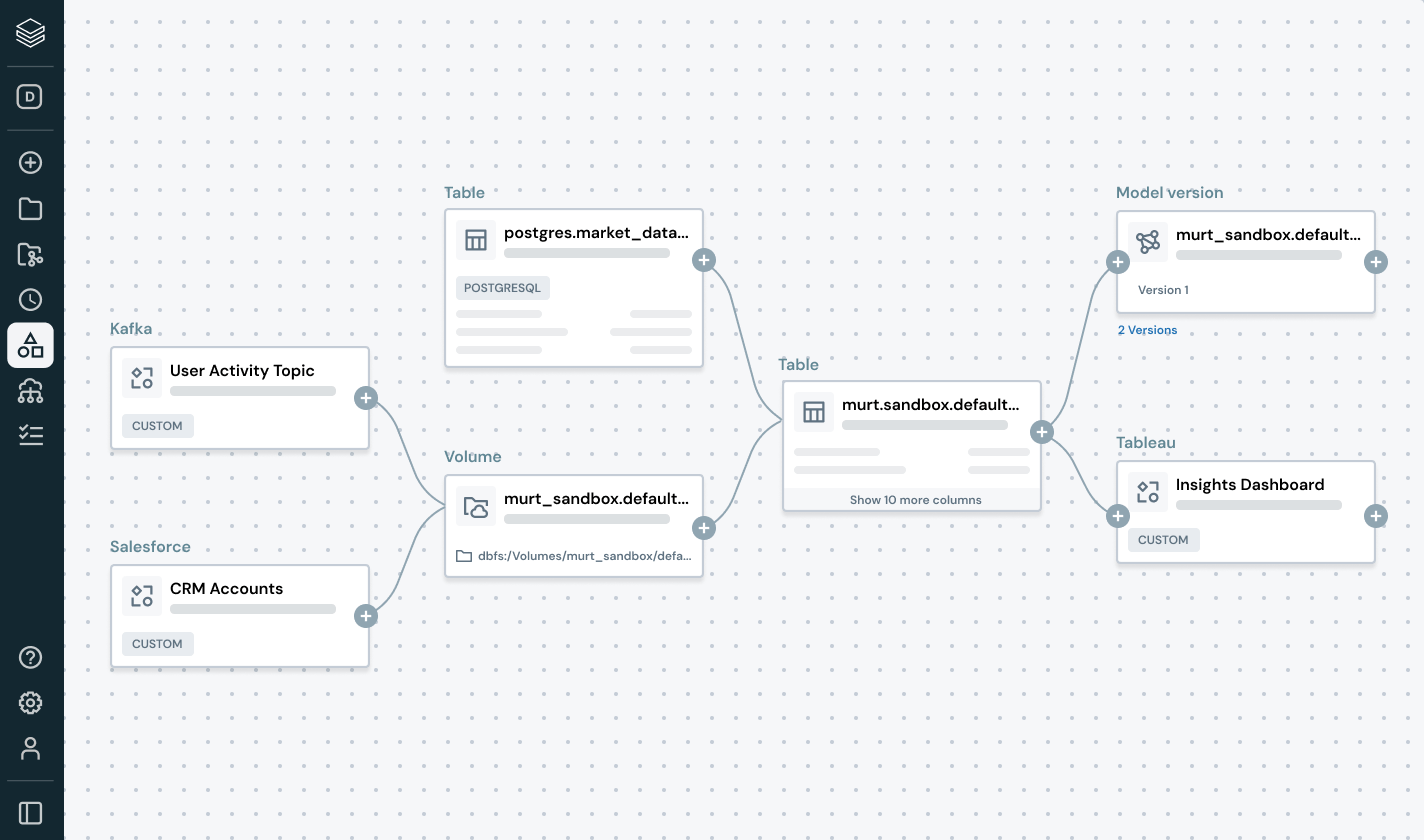
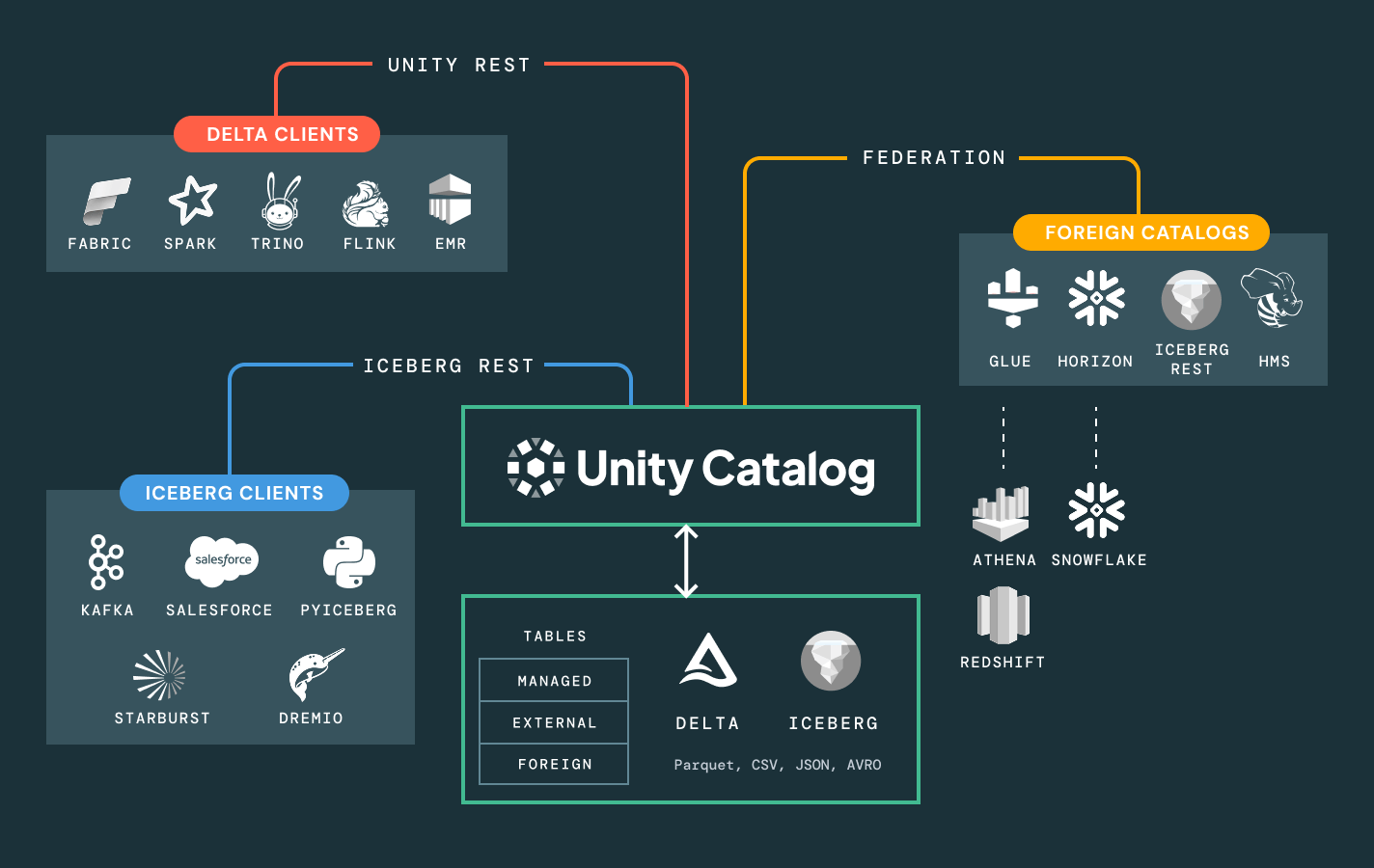
Keine Bindung an eine einzige Plattform mehr. Nutzen Sie beliebige offene Lakehouse-Formate (Delta, Apache Iceberg™, Hudi, Parquet) Ihrer Wahl, verbinden Sie sich ohne Migration mit externen Datenquellen und integrieren Sie Ihre bestehenden BI-, AI- und Katalogwerkzeuge über offene APIs. Ganz gleich, ob Sie Daten intern oder mit Partnern teilen – machen Sie die Zusammenarbeit sicher, skalierbar und auf offenen Standards basierend.
Integrierte Intelligenz
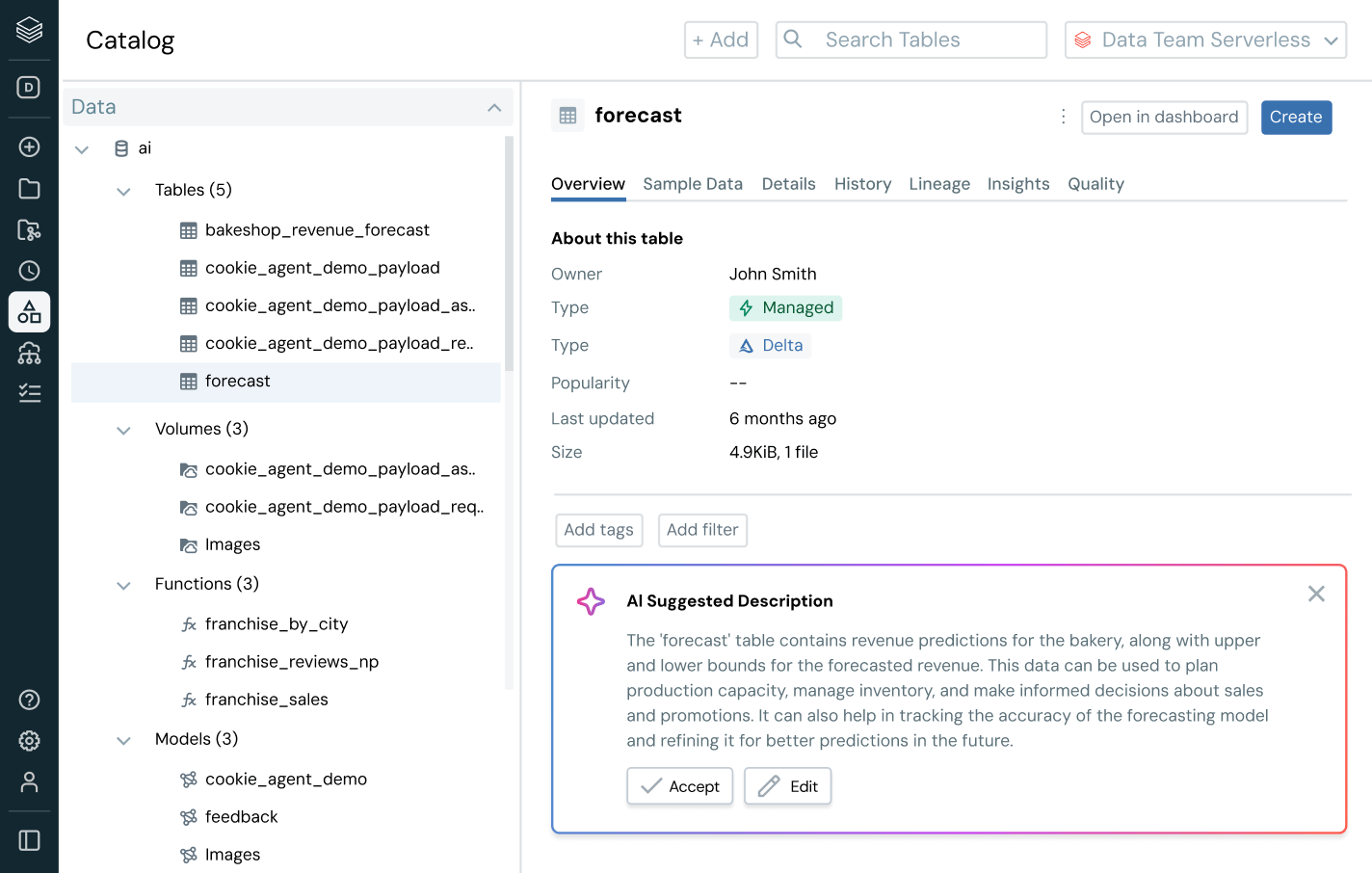
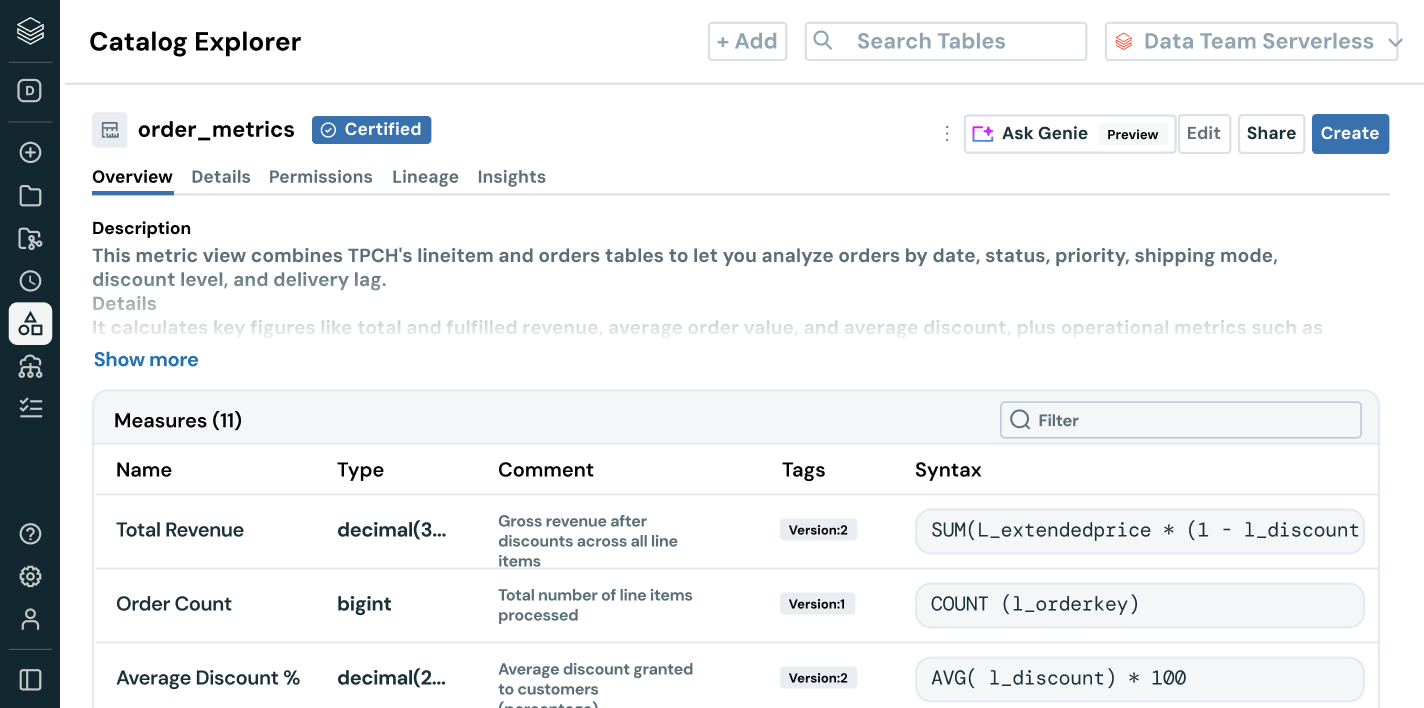
Gehen Sie über die Entdeckung und den Zugriffsmanagement von Daten hinaus – befähigen Sie Benutzer mit echtem Business-Kontext. Mit integrierter Herkunft, Nutzungseinblicken und Geschäftssemantiken können Benutzer Daten schneller finden, erkunden und verstehen. KI-gesteuerte Dokumentation, natürliche Sprachsuche und interaktive Dialogräume unterstützen Fach- und IT-Anwender dabei, schneller von Daten zu fundierten Entscheidungen und mit vollständigem Business-Kontext von Daten zu fundierten Entscheidungen zu gelangen.
Integrierte intelligente Governance
Vereinfachen Sie die Data Discovery, Compliance und Überwachung über Ihr gesamtes Daten- und KI-Portfolio hinweg mit intelligenter Governance.Einheitlicher Katalog für alle strukturierten Daten, unstrukturierten Daten, Geschäftskennzahlen und KI-Modelle über offene Datenformate wie Delta Lake, Apache Iceberg, Hudi, Parquet und mehr.

Weitere Funktionen
Maximieren Sie den Business Value Ihrer Daten durch konsistente, zentrale Governance.
Standardisieren Sie die Governance über alle Daten- und KI-Vermögenswerte und Benutzer - ohne Kompromisse.
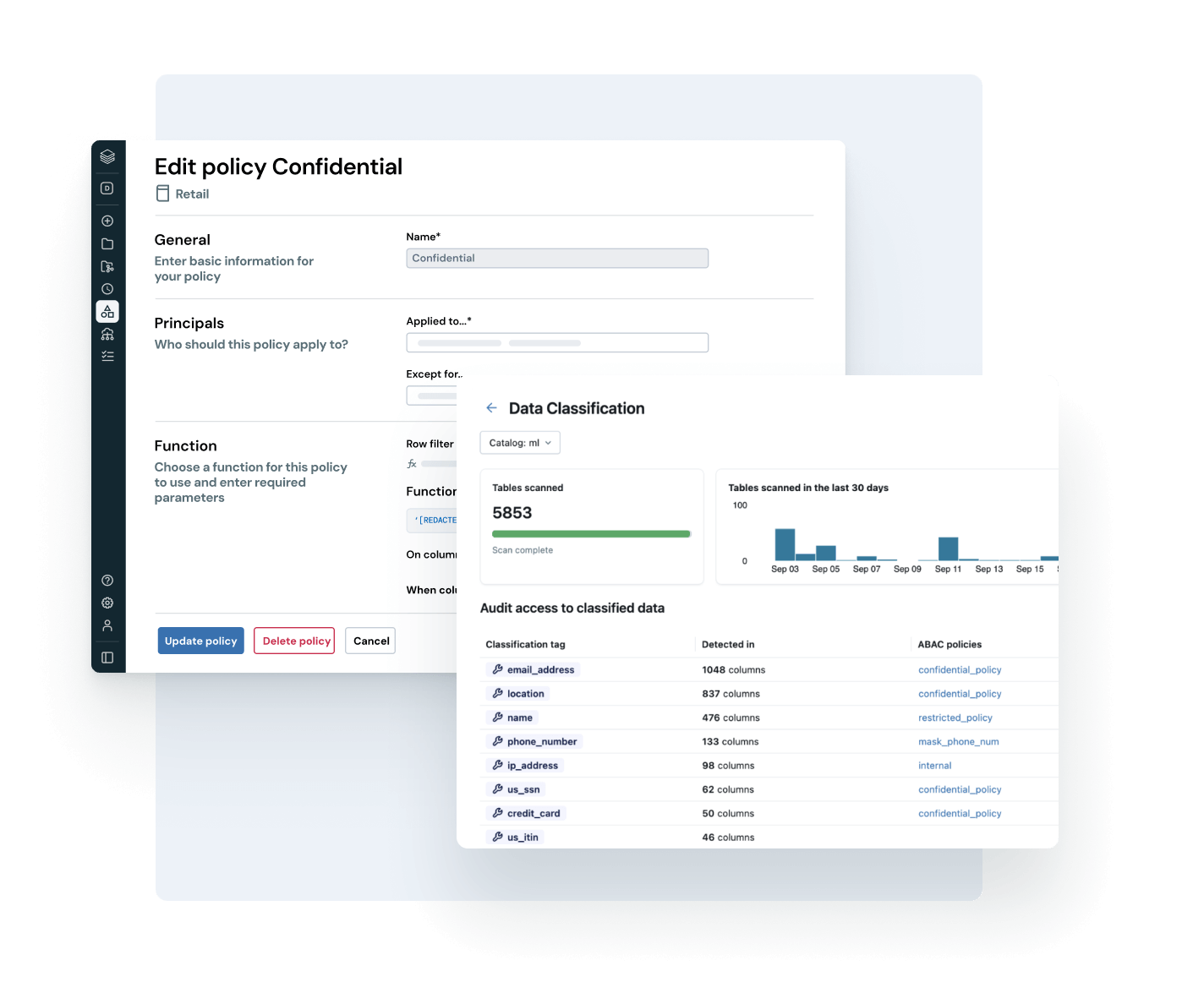
Vereinheitlichen Sie den Zugang, die Klassifizierung und die Compliance-Richtlinien über jede Geschäftseinheit, Plattform und jeden Datentyp hinweg.
- Sorgen Sie für konsistente Governance – egal ob strukturierte Daten, unstrukturierte Inhalte oder KI-Assets.
- Sensible Daten automatisch erkennen und taggen, um die Zugriffskontrolle mithilfe von Attributen und Automatisierung zu skalieren
- Verwalten Sie Richtlinien für Datenschutz, regulatorische Compliance und Risikominderung zentral.
- Reduzieren Sie den operativen Aufwand mit einer einzigen Oberfläche für die Durchsetzung von Richtlinien und Audits.
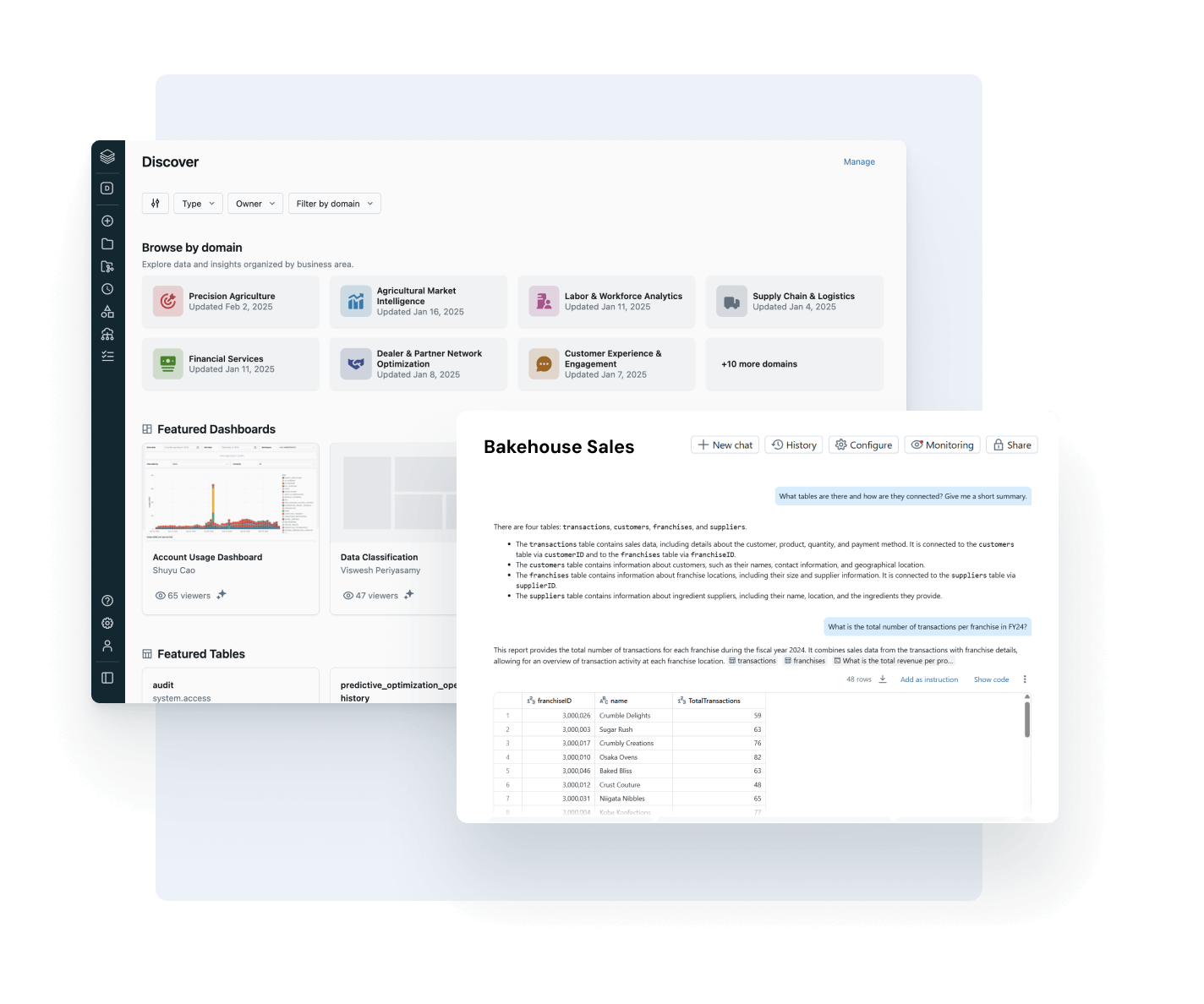
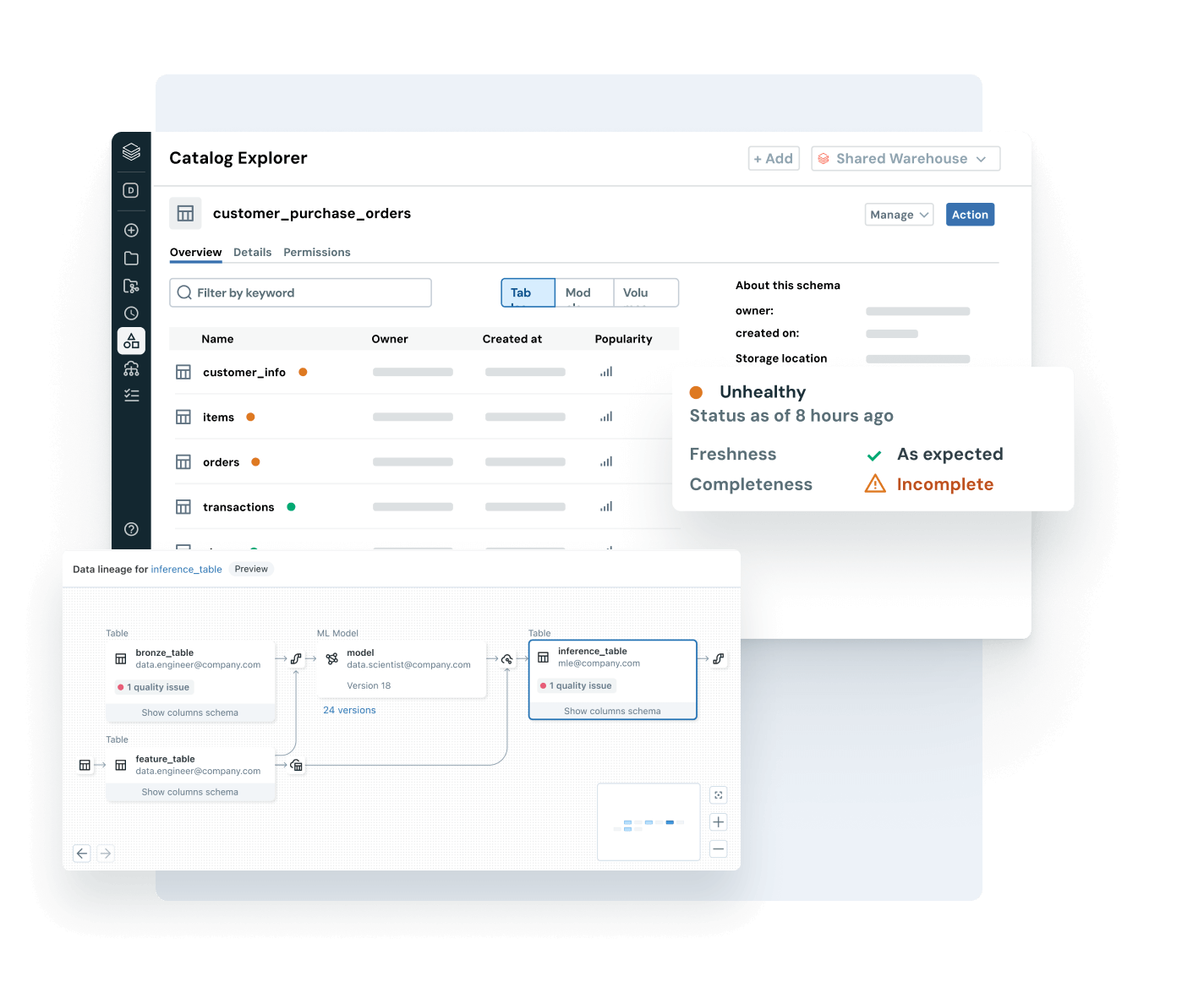
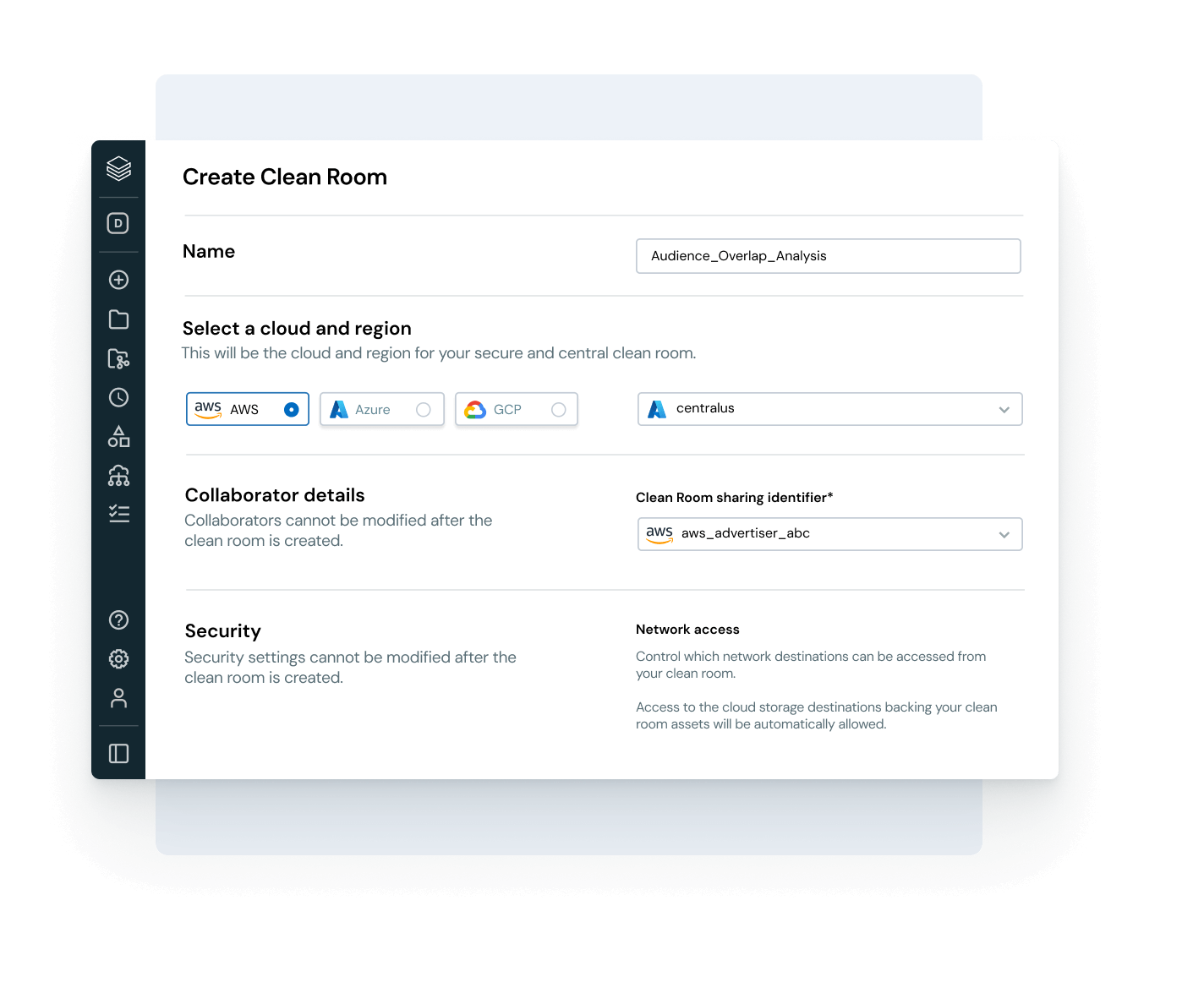
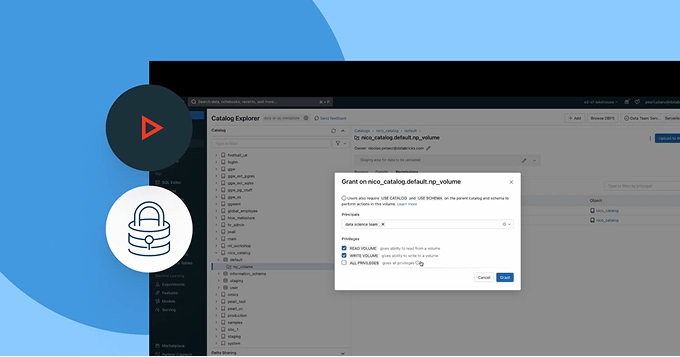
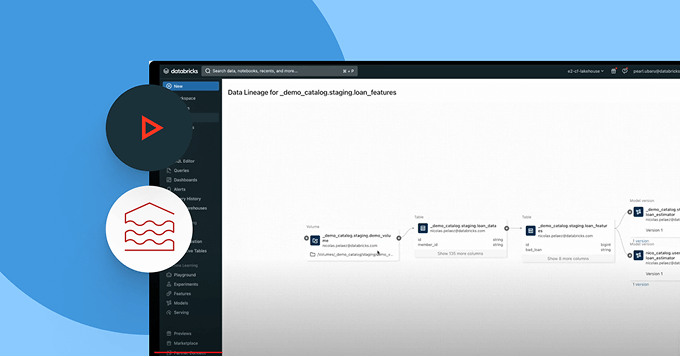
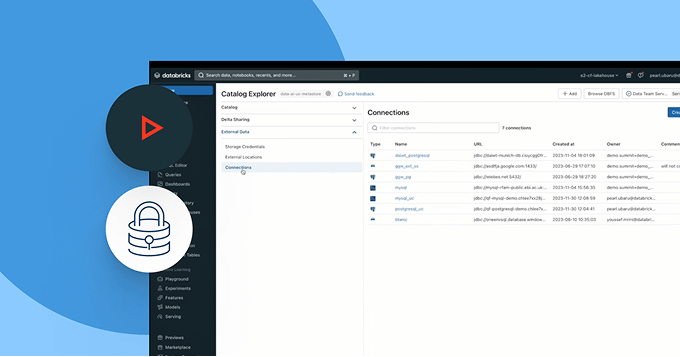
Erkunden Sie die Demos für Unity Catalog

Mehr entdecken
Erkunden Sie Produkte, die die Leistungsfähigkeit des Unity-Katalogs in den Bereichen Governance, Zusammenarbeit und Datenintelligenz erweitern.
Databricks Clean Rooms
Analysieren Sie von mehreren Parteien freigegebene Daten, ohne direkten Zugriff auf die Rohdaten zu gewähren.

Databricks Marketplace
Ein offener Marktplatz für Daten sowie KI- und Analyseressourcen wie ML-Modelle oder Notebooks.

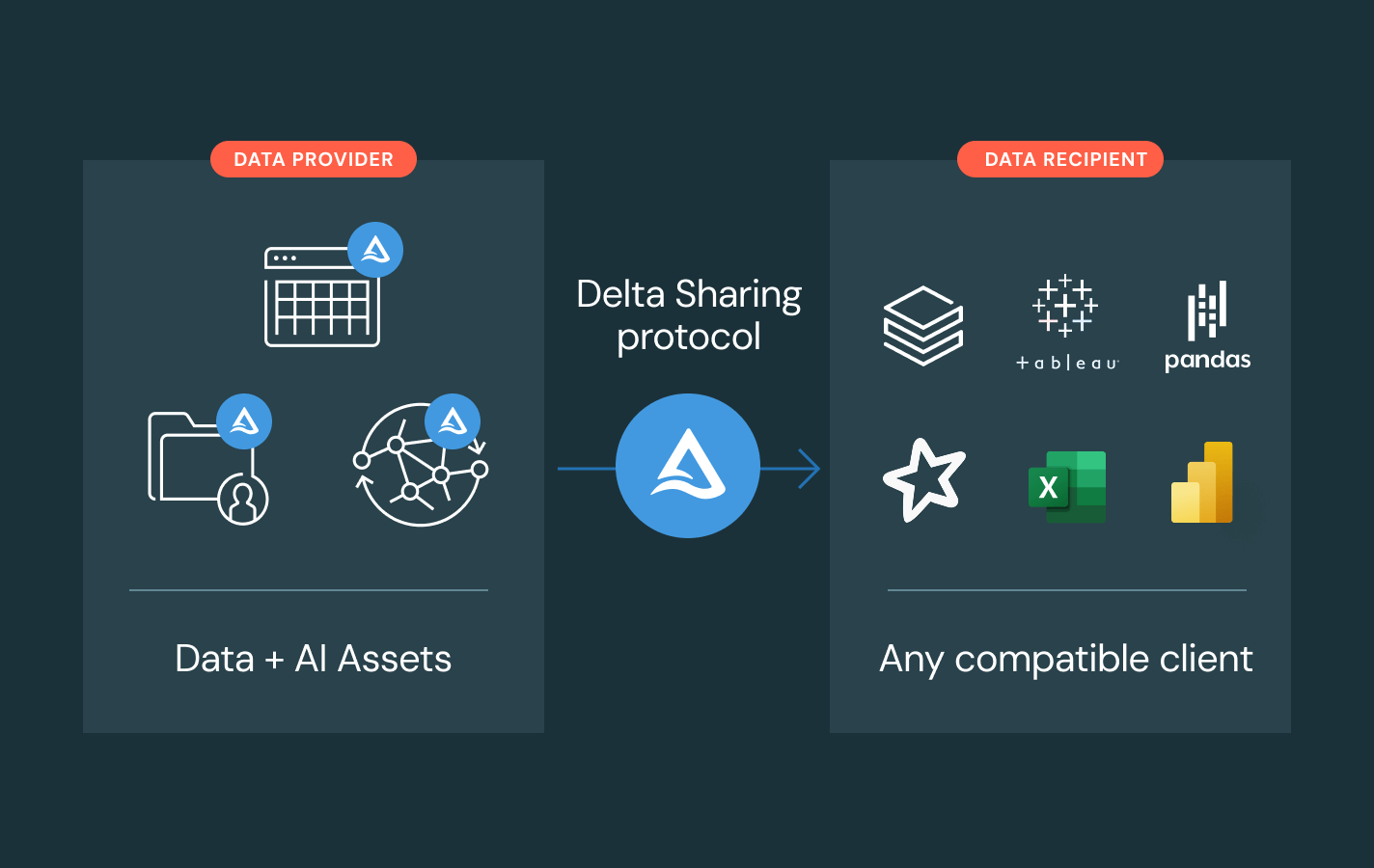
Delta-Freigabe
Ein Open-Source-Ansatz für die plattformübergreifende gemeinsame Daten- und KI-Nutzung. Geben Sie Livedaten mit zentralisierter Governance und ohne Replikation frei.

AI/BI Genie
Ein konversationelles Erlebnis, das von generativer KI gesteuert wird, das es Business-Teams ermöglicht, Daten in Echtzeit per natürlicher Sprache zu durchsuchen und eigenständig Insights abzurufen.

Databricks Assistant
Beschreiben Sie Ihre Aufgabe in natürlicher Sprache und lassen Sie Assistant SQL-Abfragen erstellen, komplexen Code erläutern und Fehler automatisch beheben.
Databricks Data Intelligence-Plattform
Entdecken Sie die gesamte Bandbreite der auf der Databricks Data Intelligence Platform verfügbaren Tools zur nahtlosen Integration von Daten und KI in Ihrem Unternehmen.
Wagen Sie den nächsten Schritt
Erkunden Sie die Dokumentation von Unity Catalog
Erhalten Sie detaillierte Anleitungen zu Funktionen, Einrichtung und Best Practices in der Unity Catalog-Dokumentation für AWS, Azure und GCP.
Erkunden Sie Produkt-Demos
Sehen Sie sich Demos zu Unity Catalog an, um zu erfahren, wie Sie Daten und AI-Assets in Ihrem gesamten Bestand steuern, entdecken und teilen können.




Unity Catalog FAQ
Möchten Sie ein Daten- und KI-Unternehmen werden?
Machen Sie die ersten Schritte Ihrer Datentransformation