Effiziente Datenaufnahme in Ihr Lakehouse
Machen Sie den ersten Schritt, um Innovation mit Datenintelligenz freizuschalten.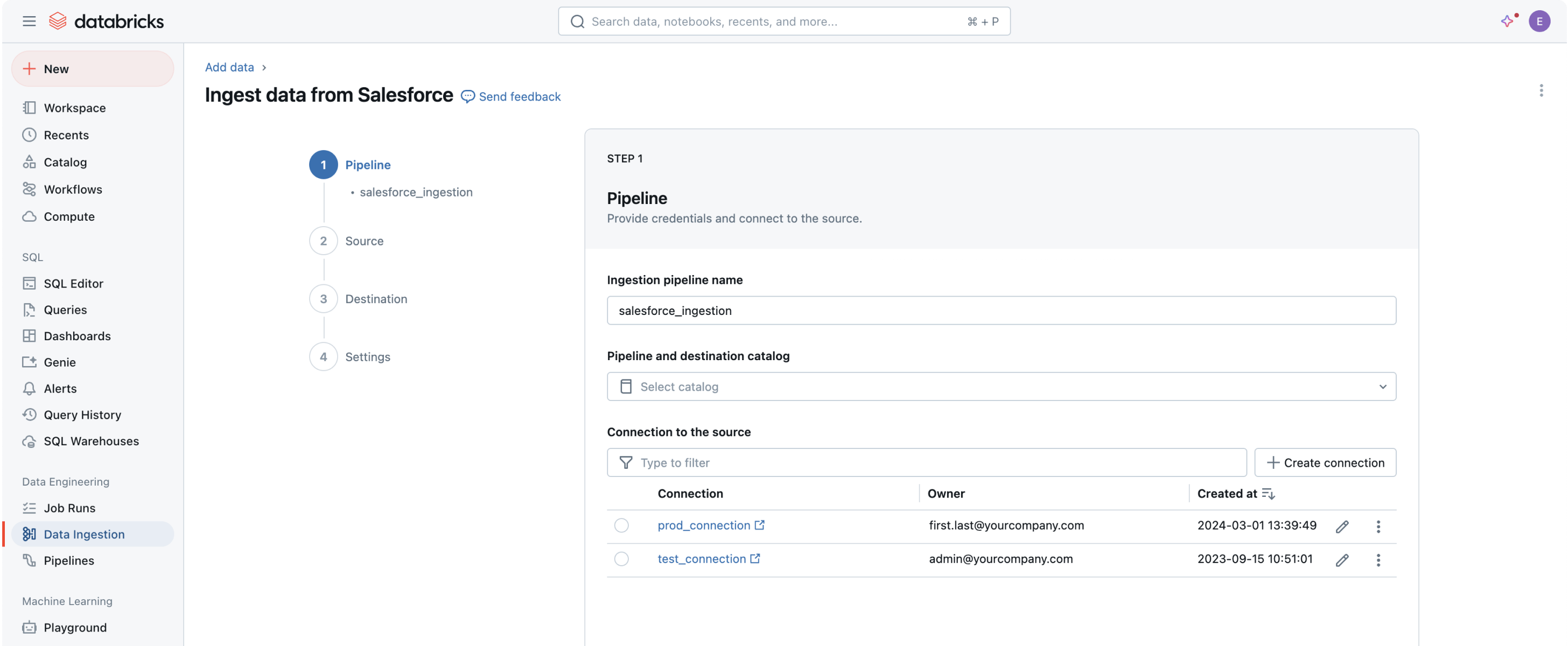
Schöpfen Sie Wert aus Ihren Daten in nur wenigen einfachen Schritten
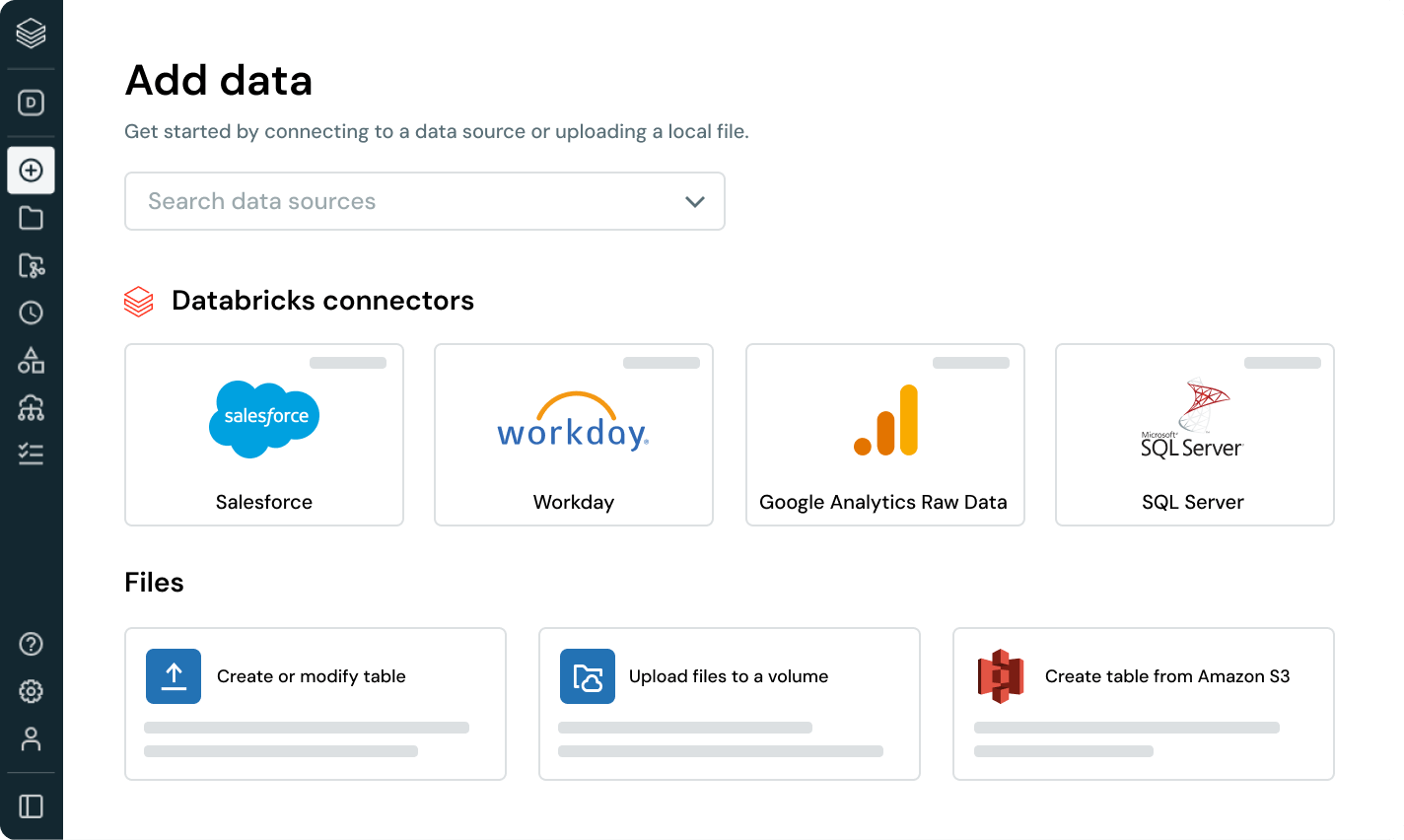
Eingebaute Datenverbindungen sind für beliebte Unternehmensanwendungen, Dateiquellen und Datenbanken verfügbar.Flexibel und einfach
Vollständig verwaltete Connectoren bieten eine einfache Benutzeroberfläche und API für eine einfache Einrichtung und demokratisieren den Datenzugriff. Automatisierte Funktionen helfen auch dabei, die Wartung von Pipelines mit minimalem Overhead zu vereinfachen.
Integrierte Connectoren
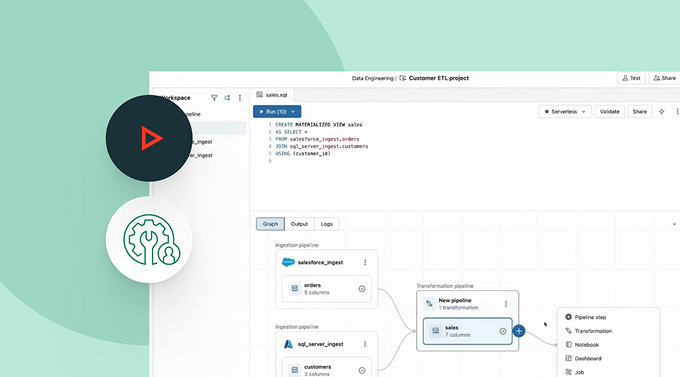
Die Datenübernahme ist vollständig in die Data Intelligence Plattform integriert. Erstellen Sie Ingestion-Pipelines mit Governance aus dem Unity-Katalog, Beobachtbarkeit aus dem Lakehouse-Monitoring und nahtloser Orchestrierung mit Workflows für Analytik, maschinelles Lernen und BI.
Effiziente Datenaufnahme
Steigern Sie die Effizienz und beschleunigen Sie die Zeit bis zum Wert. Optimierte inkrementelle Lese- und Schreibvorgänge sowie Datenverarbeitung helfen dabei, die Leistung und Zuverlässigkeit Ihrer Pipelines zu verbessern, Engpässe zu reduzieren und die Auswirkungen auf die Quelldaten für die Skalierbarkeit zu verringern.

Robuste Zuführungsfähigkeiten für beliebte Datenquellen
Alle Ihre Daten in die Data Intelligence Plattform zu bringen, ist der erste Schritt, um Wert zu extrahieren und die herausforderndsten Datenprobleme Ihrer Organisation zu lösen.Eine No-Code-Benutzeroberfläche (UI) oder eine einfache API ermöglicht es Datenprofis, sich selbst zu bedienen und spart Stunden an Programmierung.



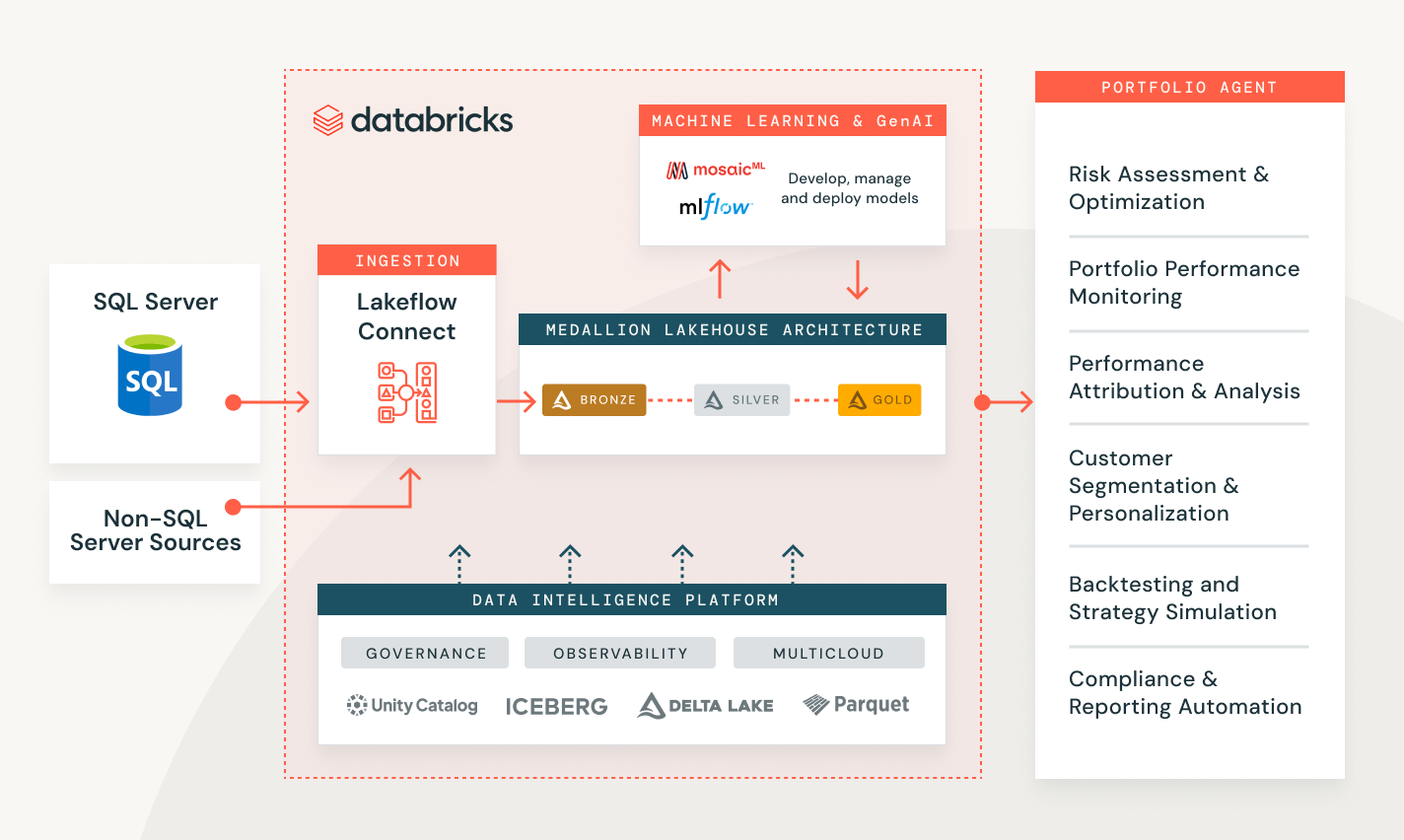
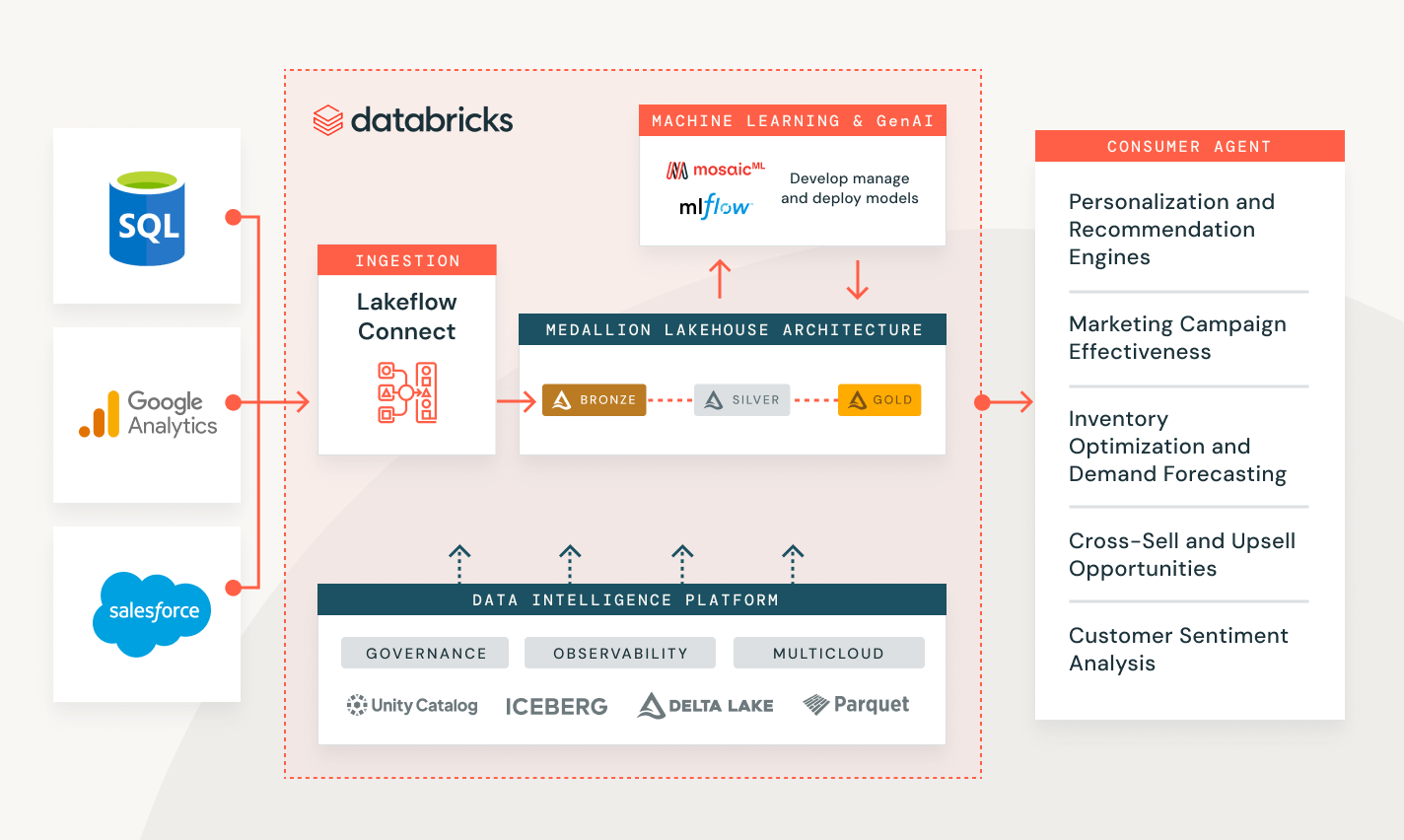
Datenaufnahme mit Databricks
Lösung von Kundenproblemen in einer Reihe von Branchen

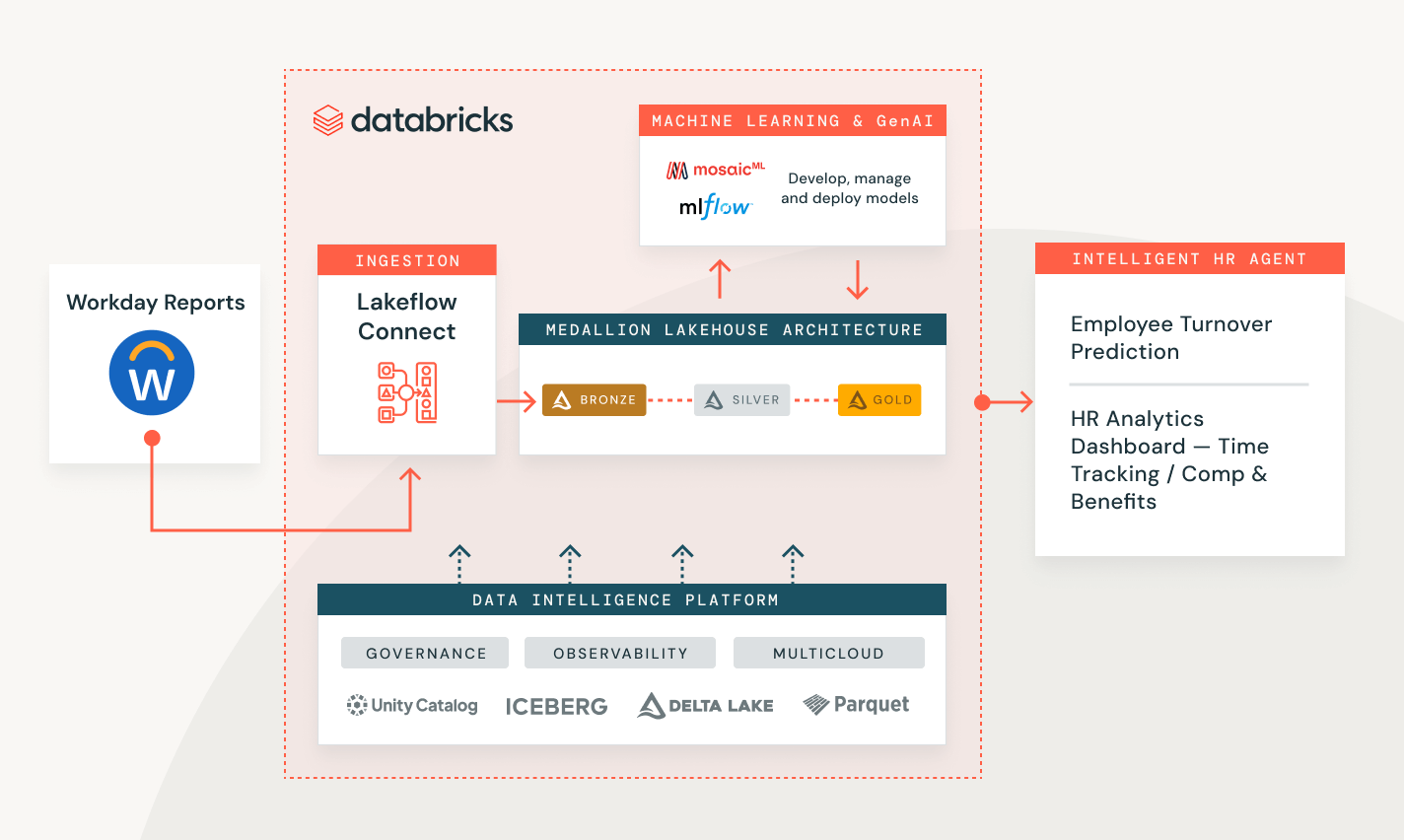
Messung der Kampagnenleistung und Kunden-Lead-Bewertung
Erstellen Sie eine End-to-End-Lösung, um Ihre Kundendaten zu transformieren, zu sichern und zu analysieren und zukünftiges Verhalten vorherzusagen.


Ausgaben im Griff dank nutzungsbasierter Abrechnung
Sie zahlen nur für die Produkte, die Sie tatsächlich nutzen – und das sekundengenau.Mehr entdecken
Entdecken Sie weitere integrierte, intelligente Angebote auf der Data Intelligence Platform.
Lakeflow Jobs
Statten Sie Teams besser aus, um jeden ETL-, Analyse- und KI-Workflow mit tiefer Observability, hoher Zuverlässigkeit und breiter Unterstützung für verschiedene Aufgaben zu automatisieren und zu orchestrieren.
Spark Declarative Pipelines
Vereinfachen Sie Batch- und Streaming-ETL mit automatisierter Datenqualität, Change Data Capture (CDC), Datenaufnahme, Transformation und einheitlicher Governance.

Unity Catalog
Regulieren Sie alle Ihre Datenressourcen nahtlos mit der branchenweit einzigen einheitlichen und offenen Governance-Lösung für Daten und KI, die in die Data Intelligence Platform von Databricks integriert ist.

Delta Lake
Vereinheitlichen Sie die Daten in Ihrem Lakehouse format- und typenübergreifend für alle Ihre Analytics- und KI-Workloads.
Erste Schritte
Erkunden Sie die Dokumentation zur Datenaufnahme
Nehmen Sie Daten aus verschiedenen Quellen auf, über verschiedene Clouds hinweg und über Lakeflow Connect.
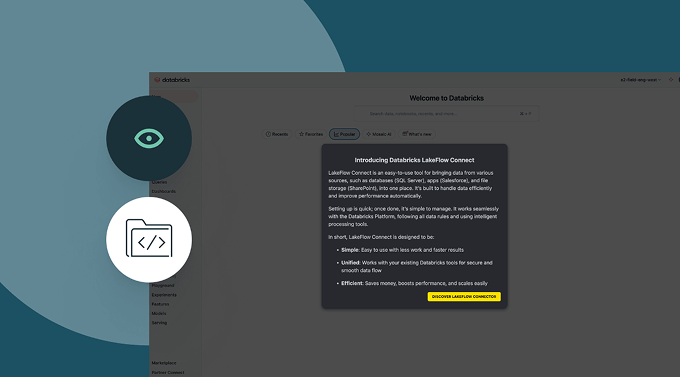
Tour Lakeflow Connect
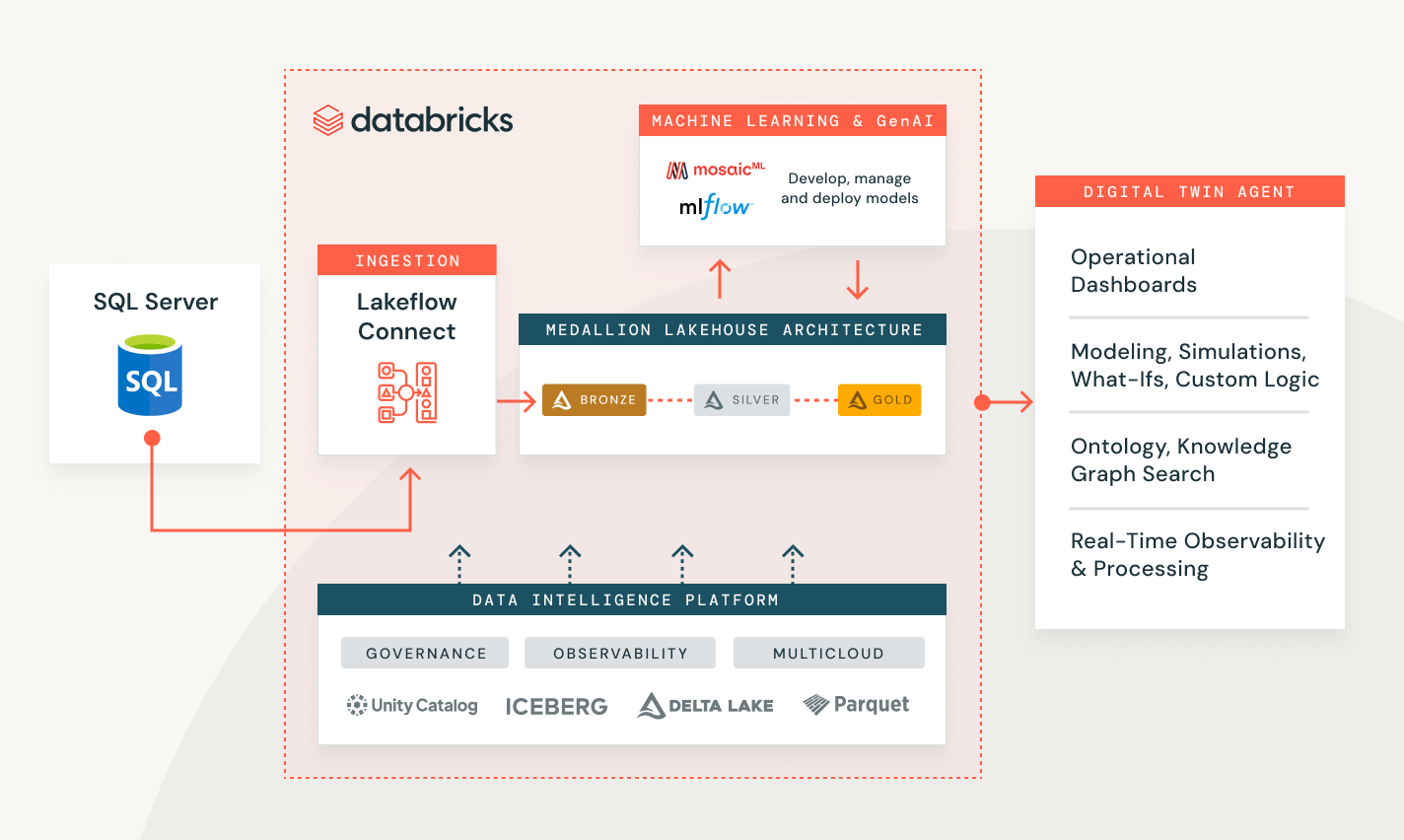
Lakeflow Connect ist jetzt allgemein verfügbar für Salesforce, Workday und SQL Server.
Für eine Vorschau auf andere Connectoren wenden Sie sich bitte an Ihr Databricks-Kontoteam.



FAQ zur Datenaufnahme
Möchten Sie ein Daten- und KI-Unternehmen werden?
Machen Sie die ersten Schritte Ihrer Datentransformation