Data Lake auf Azure
Vollständige und maßgebliche Datenquelle zur Stromversorgung Ihres Lakehouse
Was ist ein Data Lake?
Führen Sie Ihre Daten-, Analyse- und KI-Workloads auf einer einfachen, offenen und auf Zusammenarbeit ausgelegten Cloud-nativen Plattform aus, die sich problemlos in Ihre Sicherheits- und Verwaltungstools integrieren lässt und mit der Sie Ihre bestehenden Governance-Richtlinien erweitern können, um für mehr Sicherheit und Kontrolle zu sorgen.

Was ist ein Azure Data Lake?
Ein Azure Data Lake umfasst skalierbare Cloud Datenspeicherung und Analysedienste, insbesondere Analysendienste. Azure Data Lake Storage können Organisationen Daten beliebiger Größe, Formats und Geschwindigkeiten für eine breite Palette von Verarbeitungs-, Analyse- und Data Science Anwendungsfällen speichern. In Verbindung mit anderen Azure Diensten – etwa Azure Databricks – ist Azure Data Lake Storage eine weitaus kostengünstigere Möglichkeit, Daten in Ihrem gesamten Unternehmen zu speichern und abzurufen.
Unabhängig davon, ob Ihre Daten groß oder klein, schnell oder langsam, strukturiert oder unstrukturiert sind, lässt sich Azure Data Lake in die Identitäts-, Verwaltungs- und Sicherheitsfunktionen von Azure integrieren, um die Datenverwaltung und -kontrolle zu vereinfachen. Azure Storage verschlüsselt Ihre Daten automatisch und Azure Databricks bietet Tools zum Schutz der Daten, um die Sicherheits- und Compliance-Anforderungen Ihres Unternehmens zu erfüllen.

Warum benötigen Sie einen Azure Data Lake?
Data Lakes haben ein offenes Format, sodass Benutzer nicht an ein proprietäres System wie ein Data Warehouse gebunden sind. Offene Standards und Formate gewinnen in modernen Datenarchitekturen zunehmend an Bedeutung. Data Lakes sind aufgrund ihrer Scale und der Möglichkeit zur Nutzung von Objektspeichern außerdem äußerst langlebig und kostengünstig. Darüber hinaus zählen Advanced Analytics, deskriptive Analysen und maschinelles Lernen auf unstrukturierten Daten heute zu den wichtigsten strategischen Prioritäten für Unternehmen. Die einzigartige Fähigkeit, Rohdaten in einer Vielzahl von Formaten – strukturiert, unstrukturiert und halbstrukturiert – aufzunehmen, sowie die anderen genannten Vorteile machen einen Data Lake zur klaren Wahl für die Datenspeicherung.
Bei entsprechender Architektur bieten Data Lakes folgende Möglichkeiten:
- Power Data Science und maschinelles Lernen
- Zentralisieren, konsolidieren und katalogisieren Sie Ihre Daten
- Schnelle und nahtlose Integration unterschiedlicher Datenquellen und Formate
- Demokratisieren Sie Ihre Daten, indem Sie den Benutzern Self-Service-Tools anbieten
Was ist der Unterschied zwischen einem Azure Data Lake und einem Azure Data Warehouse?
Ein Data Lake ist ein zentraler Speicherort, der große Datenmengen in ihrem nativen Rohformat bereithält und die Möglichkeit bietet, große Mengen sehr unterschiedlicher Daten zu organisieren. Im Vergleich zu einem hierarchischen Data Warehouse, das Daten in Dateien oder Ordnern speichert, verwendet ein Data Lake eine flache Architektur zum Speichern der Daten. Data Lakes werden normalerweise auf Clustern skalierbarer Standardhardware konfiguriert. Dadurch können Sie Rohdaten im See speichern, falls Sie diese zu einem späteren Zeitpunkt benötigen – ohne sich Gedanken über Datenformat, Größe oder Speicherkapazität machen zu müssen.
Darüber hinaus können Data Lake clusters on-premises oder in der Cloud existieren. In der Vergangenheit wurde der Begriff „Data Lake“ häufig mit Hadoop-orientiertem Objektspeicher in Verbindung gebracht, heute bezieht sich der Begriff jedoch im Allgemeinen auf die breitere Kategorie des Objektspeichers. Der Objektspeicher speichert Daten mit Metadaten-Tags und einer eindeutigen Kennung, was das Auffinden und Abrufen von Daten in verschiedenen Regionen erleichtert und Performance verbessert. Die Databricks Lakehouse-Plattform macht alle Daten Ihres Data Lake für beliebig viele datengesteuerte Anwendungsfälle verfügbar.

Warum sollten Sie das Delta Lake-Format für Ihren Azure Data Lake verwenden?
Hier sind fünf Key Gründe für die Konvertierung von Data Lake von Apache Parquet, CSV, JSON und anderen Formaten in Delta Lake Format:
- Verhindern von Datenbeschädigungen
- Schnellere Abfragen
- Erhöhen Sie die Datenaktualität
- ML-Modelle reproduzieren
- Erreichen Sie Compliance
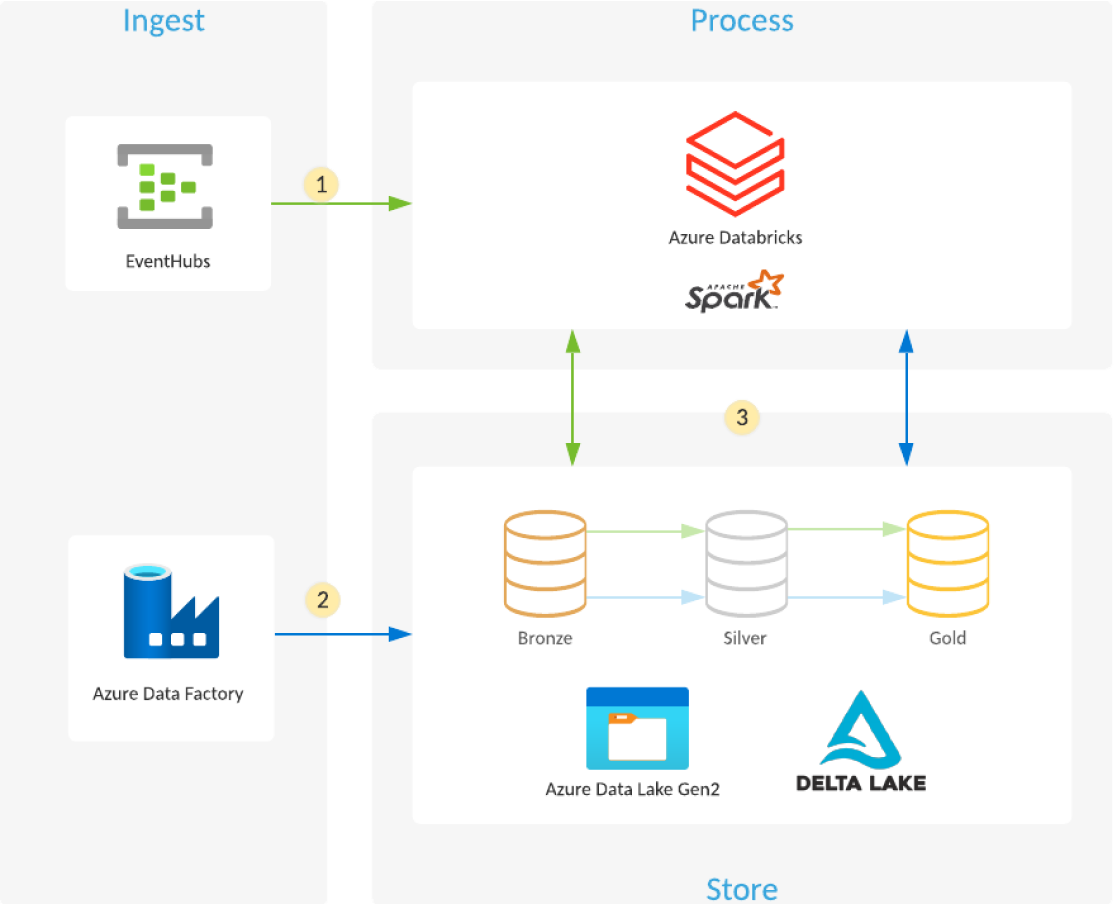
Wie erstellen Sie einen Data Lake mit Azure Databricks und Azure Data Lake Storage?
Managed Delta Lake in Azure Databricks bietet eine Zuverlässigkeitsebene, die es Ihnen ermöglicht, Ihren Data Lake in der Cloud zu kuratieren, zu analysieren und daraus Nutzen zu ziehen.
- Azure Databricks liest Streaming aus Ereigniswarteschlangen wie Azure Event Hubs, Azure IoT Hub oder Kafka und lädt die Rohereignisse in optimierte, komprimierte Delta Lake Tabellen und -Ordner (Bronze-Ebene), die in Azure Data Lake Storage gespeichert sind.
- Geplante oder ausgelöste Azure Data Factory Pipeline kopiert Daten aus verschiedenen Datenquellen in ihrem Rohformat in Azure Data Lake Storage. Der Auto Loader in Azure Databricks verarbeitet die Dateien beim Eintreffen und lädt sie in optimierte, komprimierte Delta Lake-Tabellen und -Ordner (Bronze-Ebene), die in Azure Data Lake Storage gespeichert sind.
- Streaming oder geplante/ausgelöste Azure Databricks -Jobs werden neue Transaktionen aus der Bronze-Ebene gelesen und anschließend Join, bereinigt, transformiert und aggregiert, bevor sie mithilfe von ACID-Transaktionen (INSERT, UPDATE, DELETE, MERGE) in kuratierte Datensätze (Silber- und Gold Ebenen) geladen werden, die in Delta Lake auf Azure Data Lake Storage gespeichert sind.
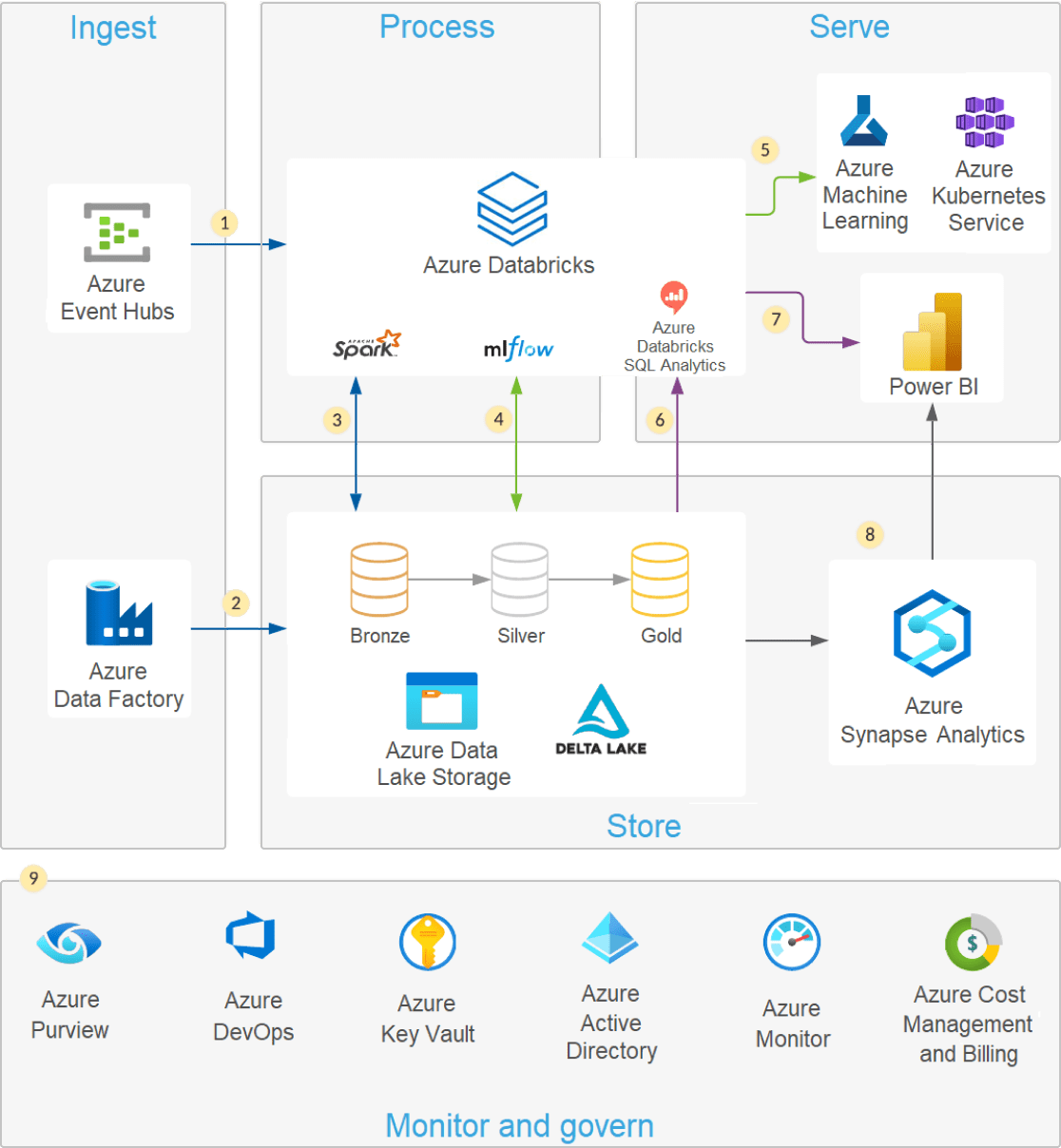
Moderne Data Lake-Architektur
Eine moderne Lakehouse -Architektur , die die Performance, Zuverlässigkeit und Datenintegrität eines Warehouse mit der Flexibilität, Scale und Unterstützung für unstrukturierte Daten kombiniert, die in einem Data Lake verfügbar sind.
Moderne Data Lakes nutzen die Elastizität Cloud , um praktisch unbegrenzte Datenmengen „so wie sie sind“ zu speichern, ohne dass ein Schema oder eine Struktur vorgegeben werden muss. Structured Query Language (SQL) ist eine leistungsstarke Abfragesprache zum Erkunden Ihrer Daten und zum Entdecken wertvoller Einblicke, Erkenntnisse, Informationen, Daten, Statistiken usw. je nach Kontext. Delta Lake ist eine Open Source Speicherschicht, die mit ACID-Transaktionen, skalierbarer Metadatenverarbeitung und einheitlicher Streaming und Batch -Datenverarbeitung Zuverlässigkeit in Data Lake bringt. Delta Lake ist vollständig kompatibel und bringt Zuverlässigkeit in Ihren vorhandenen Data Lake.
Sie können Ihren Data Lake problemlos mit SQL und Delta Lake mit Azure Databricks abfragen. Mit Delta Lake können Sie SQL-Abfragen sowohl auf Ihren Streaming- als auch auf Ihren Batch-Daten ausführen, ohne Ihre Daten zu verschieben oder zu kopieren. Azure Databricks bietet bei der Arbeit mit Delta Lake zusätzliche Vorteile, um Ihren Data Lake durch native Integration mit Cloud Dienst zu sichern, optimale Performance zu liefern und bei der Prüfung und Fehlerbehebung von Datenpipelines zu helfen.
- Delta Lake lässt sich in skalierbaren Cloud-Speicher oder HDFS integrieren, um Datensilos zu beseitigen
- Erkunden Sie Ihre Datenverwendungs- SQL Abfragen und eine ACID-kompatible Transaktionsschicht direkt auf Ihrem Data Lake
- Nutzen Sie Gold, Silber- und Bronze-Medaillontabellen zur Konsolidierung und Vereinfachung der Datenqualität für Ihre Datenpipeline und Analytics sowie zur Beschreibung von Analyse-Workflows
- Verwenden Sie die Zeitreise von Delta Lake, um zu sehen, wie sich Ihre Daten im Laufe der Zeit geändert haben
- Azure Databricks optimiert Performance mit Features wie Delta Cache, Dateikomprimierung und Datenüberspringen