Vector Search
Eine hochleistungsfähige Vektordatenbank mit integrierter Governance

Erschließen Sie das volle Potenzial generativer KI – mit Databricks Vector Search
Vector Search ist eine serverlose Vektordatenbank,
die nahtlos in die Data-Intelligence-Platftorm integriert ist
Anders als andere Datenbanken unterstützt Databricks Vector Search die automatische Datensynchronisierung von der Quelle bis zum Index, wodurch die komplexe und kostspielige Pipeline-Verwaltung entfällt. Es nutzt dabei genau diejenigen Sicherheits- und Data-Governance-Tools, die das Unternehmen bereits entwickelt hat. Damit entfallen jegliche Bedenken im Sicherheitsbereich. Dank seines serverlosen Designs lässt sich Databricks Vector Search problemlos skalieren und unterstützt Milliarden von Einbettungen sowie Tausende von Echtzeitabfragen pro Sekunde.
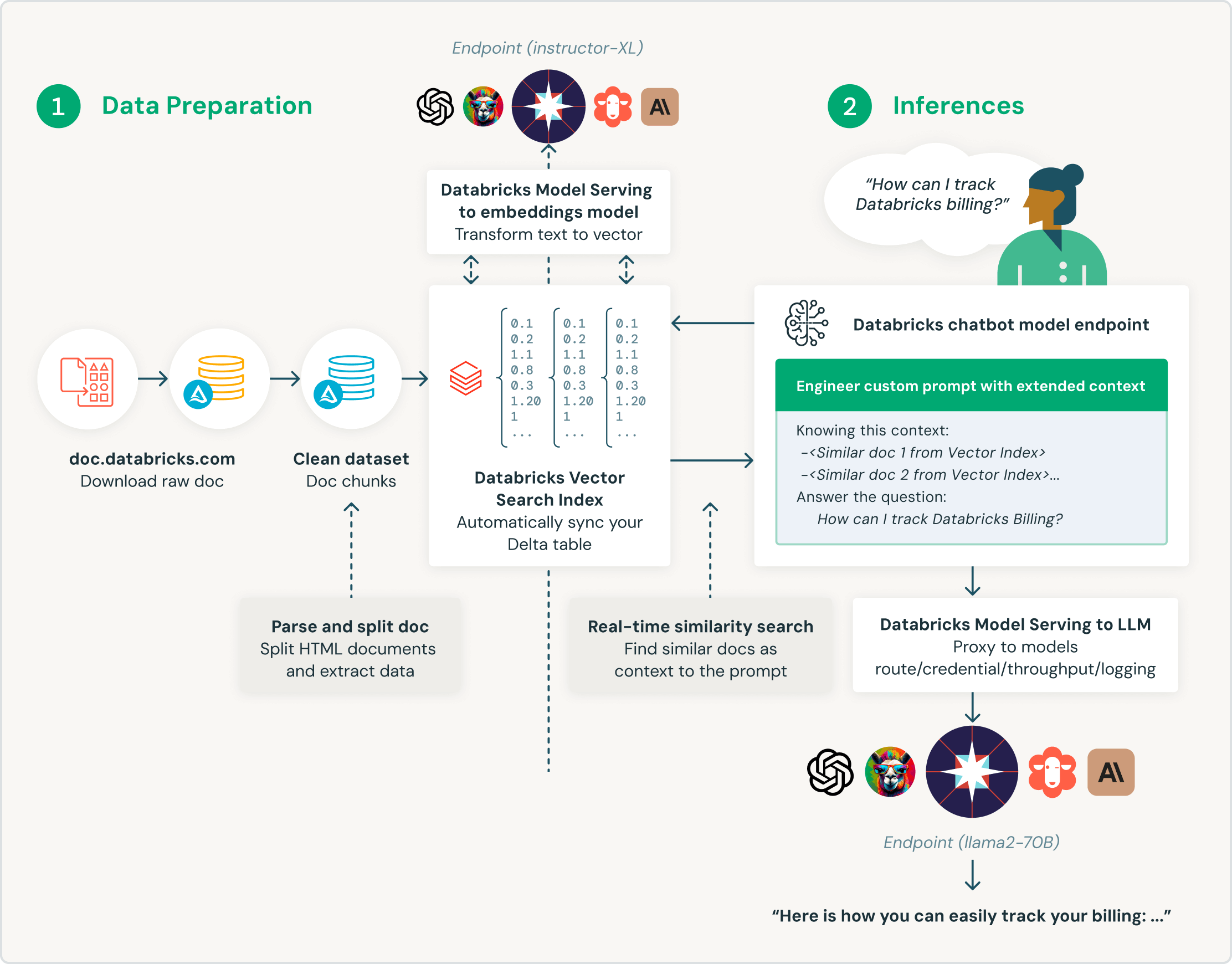
Entwickelt für Retrieval Augmented Generation (RAG)
Databricks Vector Search wurde speziell für Kunden entwickelt, die ihre Large Language Models (LLMs) mit Unternehmensdaten anreichern möchten. Databricks Vector Search wurde gezielt für RAG-Anwendungen (Retrieval Augmented Generation) gestaltet und liefert Ähnlichkeitssuchergebnisse, die LLM-Abfragen mit Kontext und Domänenwissen ergänzen und die Richtigkeit und Qualität der Ergebnisse verbessern.
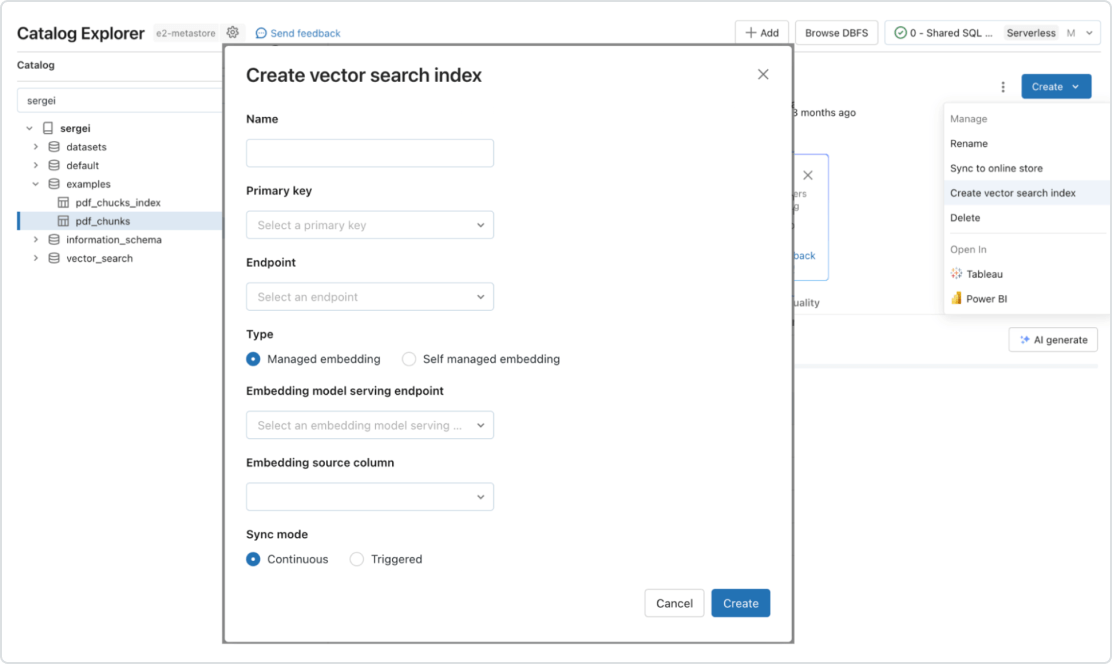
Automatisierte Echtzeit-Pipelines
Echtzeitsynchronisierung von Quelldaten durch automatische Aktualisierung des entsprechenden Vektorindexes, wenn neue Daten hinzugefügt, geändert oder entfernt werden. Im Hintergrund übernimmt Databricks die Generierung und Verwaltung von Einbettungsvektoren, verwaltet automatisch Ausfälle, behandelt Wiederholungsversuche, optimiert den Durchsatz und sorgt für eine automatische Anpassung der Stapelgröße sowie automatische Skalierung, ohne dass ein manueller Eingriff erforderlich wäre.
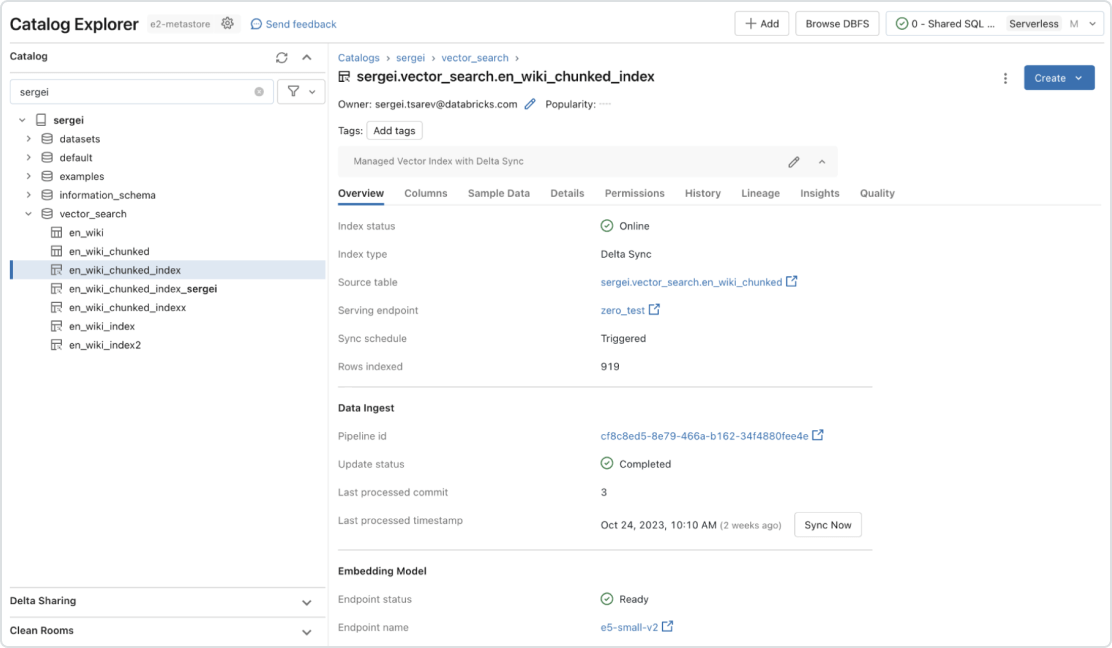
Integrierte Governance
Die einheitliche Schnittstelle definiert Richtlinien für Daten mit einer differenzierten Zugriffssteuerung für Einbettungen. Dank der vorhandenen Integration in Unity Catalog zeigt Vector Search Herkunft und Tracking von Daten automatisch an – zusätzliche Tools oder Sicherheitsrichtlinien sind nicht erforderlich. Dadurch wird gewährleistet, dass LLM-Modelle keine vertraulichen Daten an Benutzer weitergeben, die keinen Zugriff darauf haben sollten.
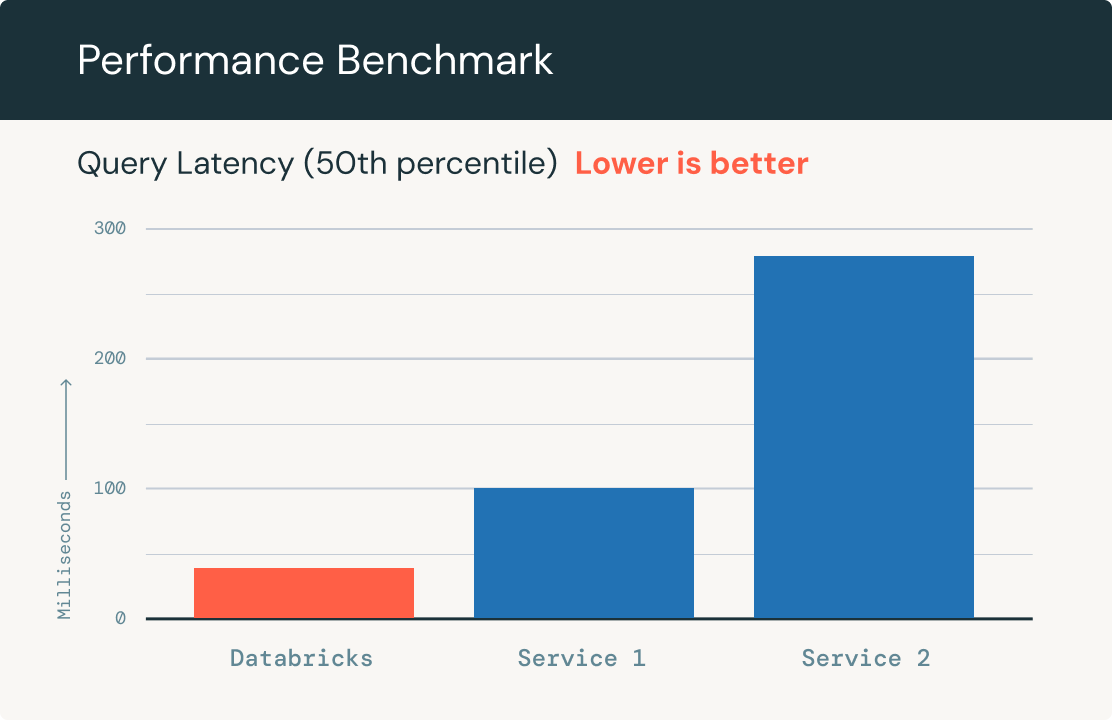
Rasante Abfragegeschwindigkeit
Skaliert automatisch, um auch Milliarden von Einbettungen in einem Index und Tausende von Abfragen pro Sekunde verarbeiten zu können. Erbringt eine im Vergleich zu anderen führenden Vektordatenbanken bis zu fünf Mal bessere Leistung bei maximal 1 Mio. OpenAI-Einbettungsdatensätzen.