Photon
Die nächste Generation für das Lakehouse
Photon ist die Engine der nächsten Generation in der Databricks Lakehouse-Plattform, die eine extrem schnelle Abfrageleistung zu niedrigeren Kosten bietet – Dateneingabe, ETL, Streaming, Data Science und interaktive Abfragen – direkt in Ihrem Data Lake. Photon ist mit Apache Spark™-APIs kompatibel, sodass der Einstieg so einfach ist wie das Einschalten – keine Codeänderungen und keine Anbieterbindung.
Cheaper and faster
Built from the ground up for the fastest performance at lower cost, Photon provides up to 80% TCO savings while accelerating data and analytics workloads — up to 12x speedups.
Built for all use cases
Photon is the first engine that enables data teams to standardize on one set of APIs for all workloads — ETL, analytics and data science — in batch or streaming.
No code changes
Photon is an ANSI-compliant engine designed to be compatible with modern Apache Spark APIs and just works with your existing code — SQL, Python, R, Scala and Java — no rewrite required.
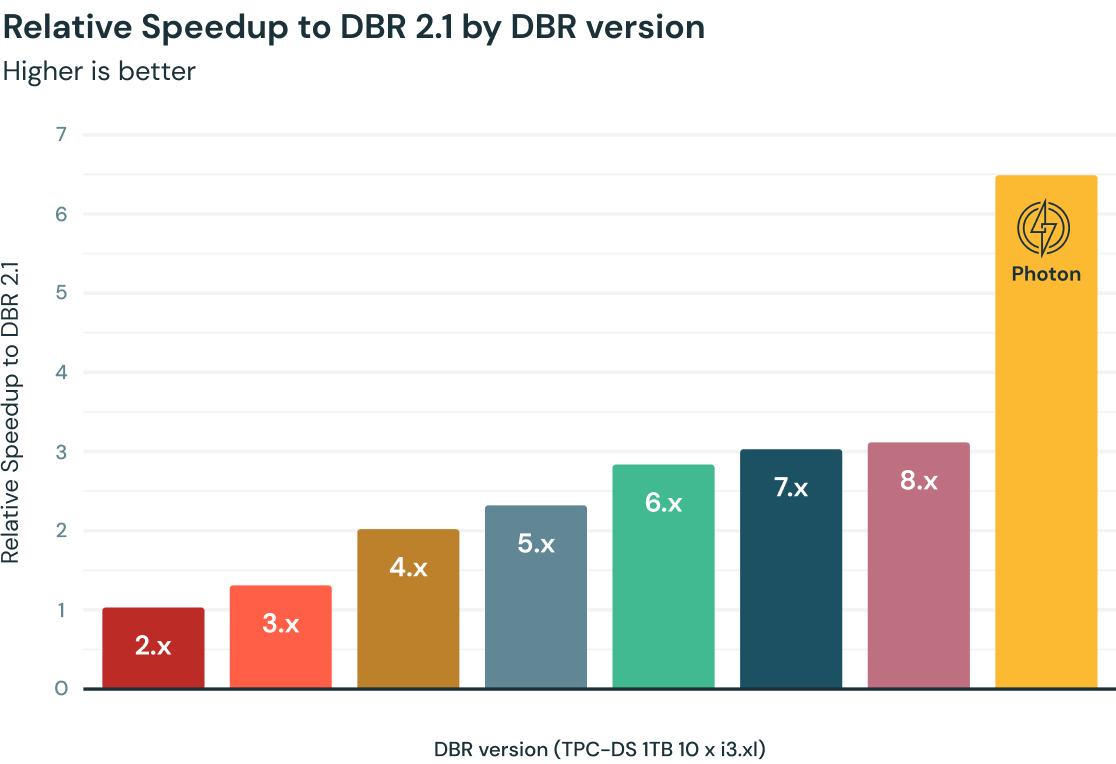
Warum Photon?
Die Abfrageleistung in Databricks hat sich im Laufe der Jahre stetig erhöht, unterstützt von Apache Spark und Tausenden von Optimierungen, die als Teil der Databricks Runtimes (DBR) bereitgestellt wurden. Photon, eine neue native vektorisierte Engine, die vollständig in C++ geschrieben ist, bietet eine zusätzliche 2-fache Beschleunigung pro TPC-DS-Benchmark (1 TB). Kunden haben basierend auf ihren Workloads im Vergleich zu den neuesten DBR-Versionen durchschnittlich 3- bis 8-fache Beschleunigungen beobachtet.
Anwendungsfälle

Production jobs
Accelerate large-scale production jobs on SQL and Spark DataFrames

IoT applications
Faster time-series analysis using Photon compared to Spark and traditional Databricks Runtime

Data privacy and compliance
Query petabyte-scale data sets to identify and delete records without duplicating data with Delta Lake, production jobs and Photon

Loading data into Delta Lake and Parquet
Photon’s vectorized I/O speeds up data loads for Delta Lake and Parquet tables, lowering overall runtime and the cost of data engineering jobs
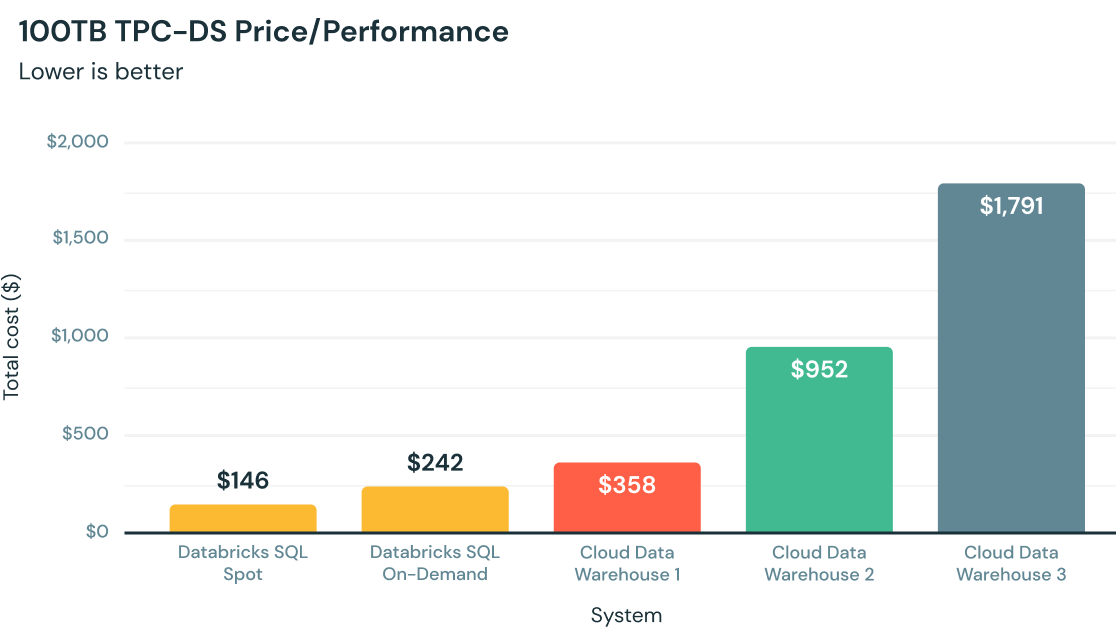
Wie funktioniert es?
Bestes Preis-Leistungs-Verhältnis bei Analysen in der Cloud
Von Grund auf in C++ geschrieben nutzt Photon moderne Hardware für schnellere Abfragen und bietet ein bis zu 12-mal besseres Preis-Leistungs-Verhältnis im Vergleich zu anderen Cloud Data Warehouses – alles nativ in Ihrem Data Lake.
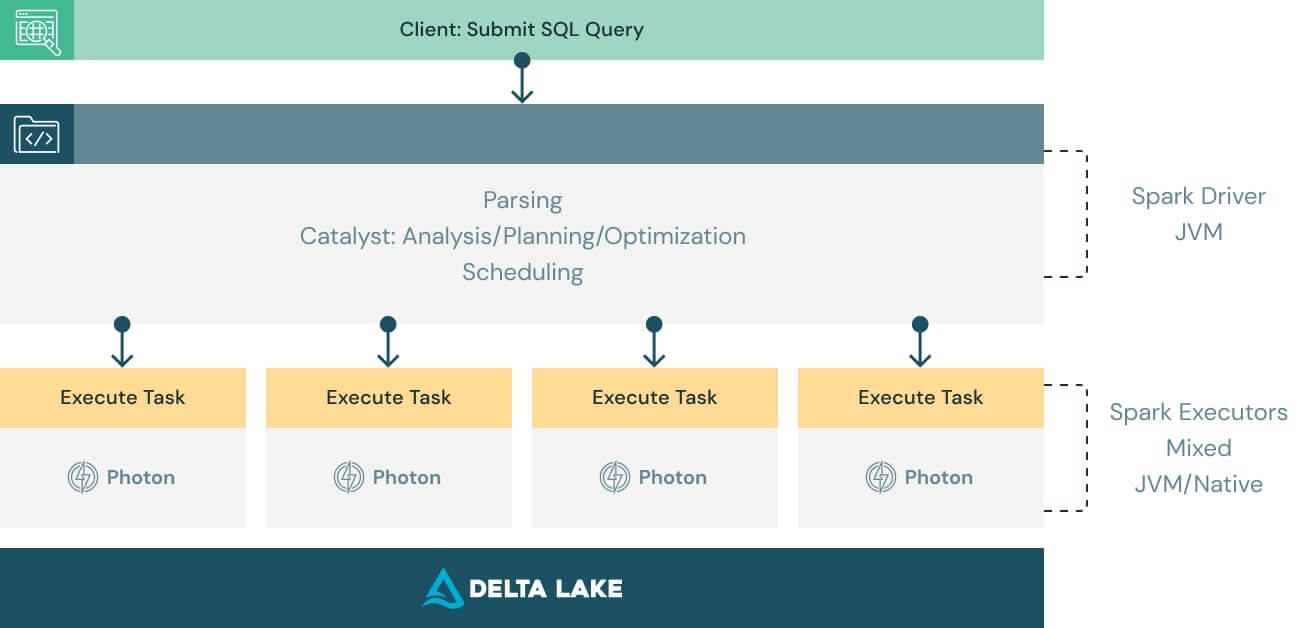
Funktioniert mit Ihrem vorhandenen Code und umgeht eine Anbieterbindung
Photon ist so konzipiert, dass es mit Apache Spark DataFrame und SQL-APIs kompatibel ist, um sicherzustellen, dass Workloads nahtlos und ohne Codeänderungen ausgeführt werden. Alles, was Sie tun müssen, um von Photon zu profitieren, ist die Engine einzuschalten. Photon wird Arbeit und Ressourcen nahtlos koordinieren und Teile Ihrer SQL- und Spark-Abfragen transparent beschleunigen. Keine Feinabstimmung und kein Benutzereingriff erforderlich.

Optimieren aller Datenanwendungsfälle und Workloads
Während wir uns zu Beginn mit Photon in erster Linie auf SQL konzentriert hatten, um unseren Kunden eine erstklassige Data-Warehousing-Leistung für ihre Data Lakes zu bieten, haben wir seither den Umfang der von Photon unterstützten Aufnahmequellen, Formate, APIs und Methoden erheblich erweitert. Infolgedessen haben Kunden mit Photon enorme Einsparungen bei den Infrastrukturkosten und Beschleunigungen in all ihren modernen Spark-Workloads (z. B. Spark SQL und DataFrame) festgestellt.
Ressourcen
Ressourcen
Forschungspapiere
Veranstaltungen
Blogs
Möchten Sie loslegen?