LakeFlow
Erfassen, transformieren und orchestrieren – mit einer durchgängigen Data-Engineering-Lösung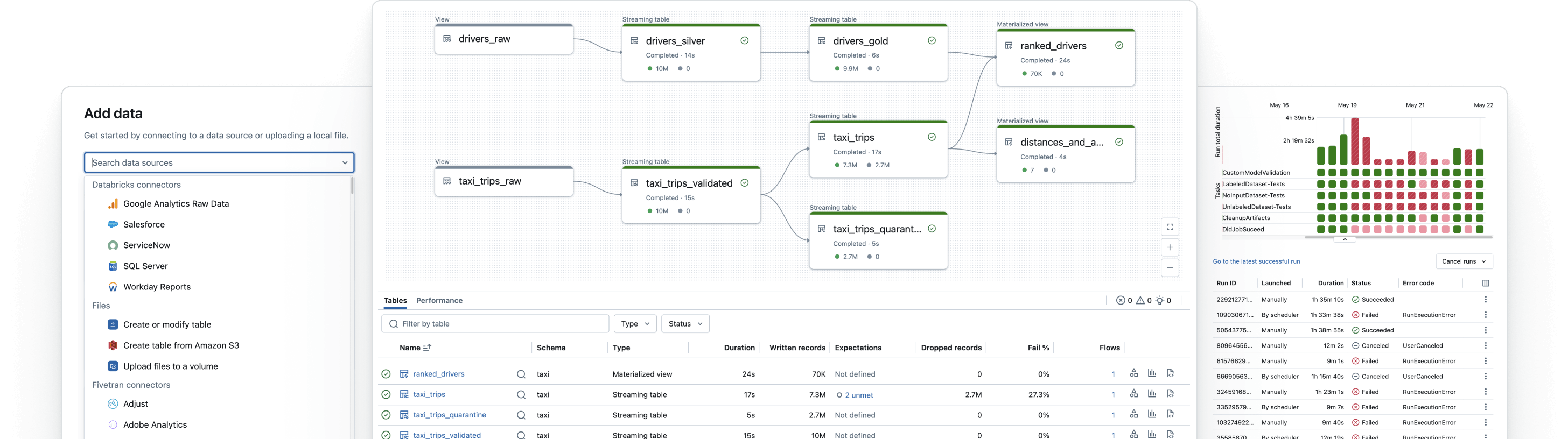
TOP-UNTERNEHMEN, DIE LAKEFLOW NUTZEN
Die End-to-End-Lösung für die Bereitstellung hochwertiger Daten
Tools, die es jedem Team erleichtern, zuverlässige Datenpipelines für Analytik und KI zu bauen.Konsolidierter Toolstack
Reduzieren Sie Kosten und Integrationsaufwand mit einer einzigen Lösung zur Erfassung und Bereinigung all Ihrer Daten. Behalten Sie die Kontrolle mit integrierter, einheitlicher Governance und durchgängiger Transparenz über die Datenherkunft.
Vereinfachte ETL-Entwicklung
Beschleunigen Sie die Arbeit aller Teams durch No-Code-Konnektoren, deklarative Transformationen und KI-gestütztes Coden.
Effiziente Datenverarbeitung
Eine leistungsstarke Engine im Hintergrund optimiert automatisch die Ressourcennutzung für ein besseres Preis-Leistungs-Verhältnis bei Batch- und Echtzeit-Anwendungen mit geringer Latenz.
85% schnellere Entwicklung
50% Kostenreduktion
99 % Reduzierung der Pipeline-Latenz
2.500 Jobläufe täglich
Corning verwendet Lakeflow, um die Datenorchestrierung zu vereinfachen und einen automatisierten, wiederholbaren Prozess für mehrere Teams in der gesamten Organisation zu schaffen. Diese automatisierten Workflows bewegen riesige Datenmengen durch eine Medaillon-Architektur von Bronze- zu Goldtabellen.
Konsolidierte Tools für Data Engineers

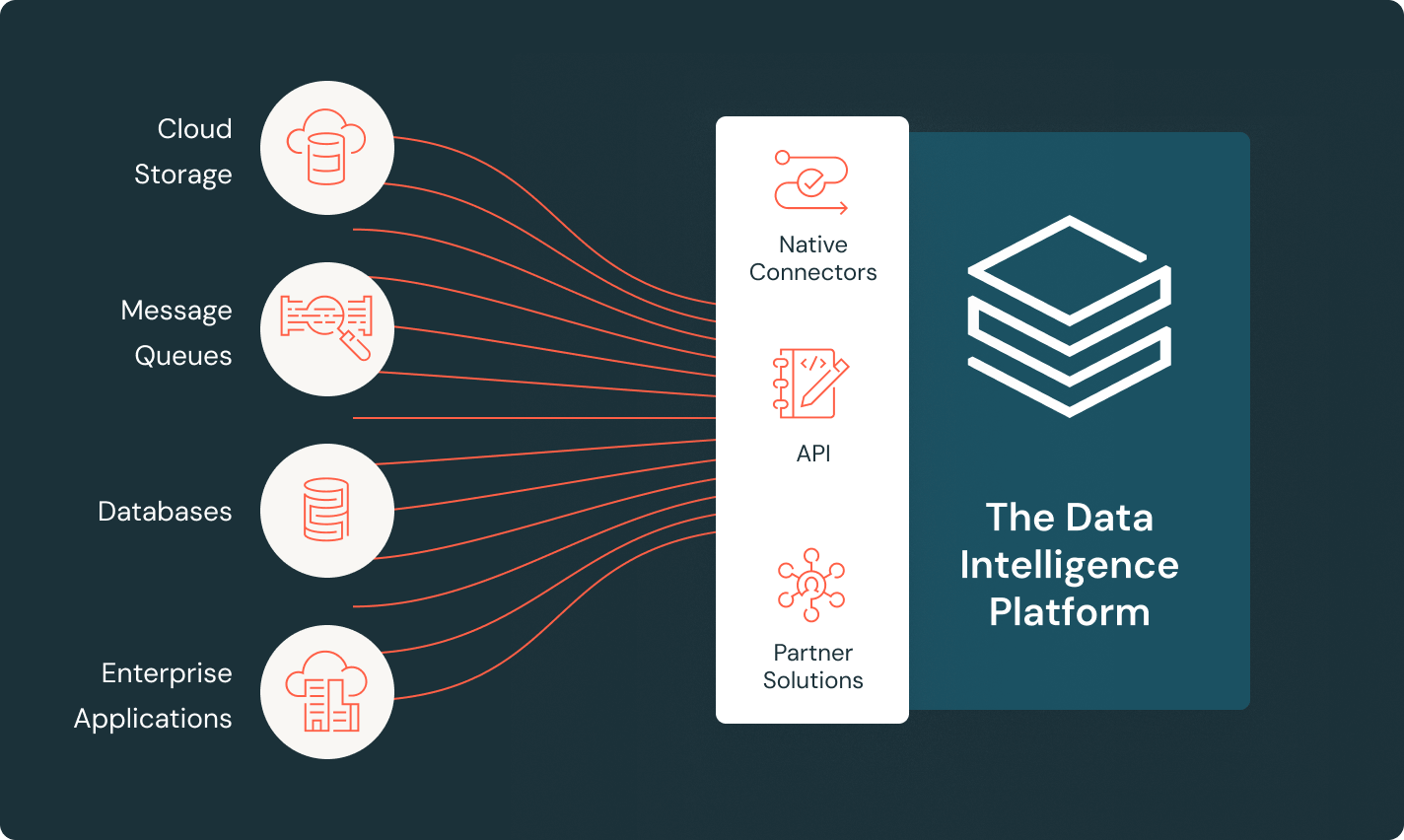
LakeFlow Connect
Effiziente Konnektoren für die Datenaufnahme und native Integration mit der Data Intelligence Platform erschließen einen einfachen Zugang zu Analytik und KI mit einheitlicher Governance.

Spark Declarative Pipelines
Vereinfachen Sie Batch- und Streaming-ETL mit automatisierter Datenqualität, Change Data Capture (CDC), Datenaufnahme, Transformation und einheitlicher Governance.

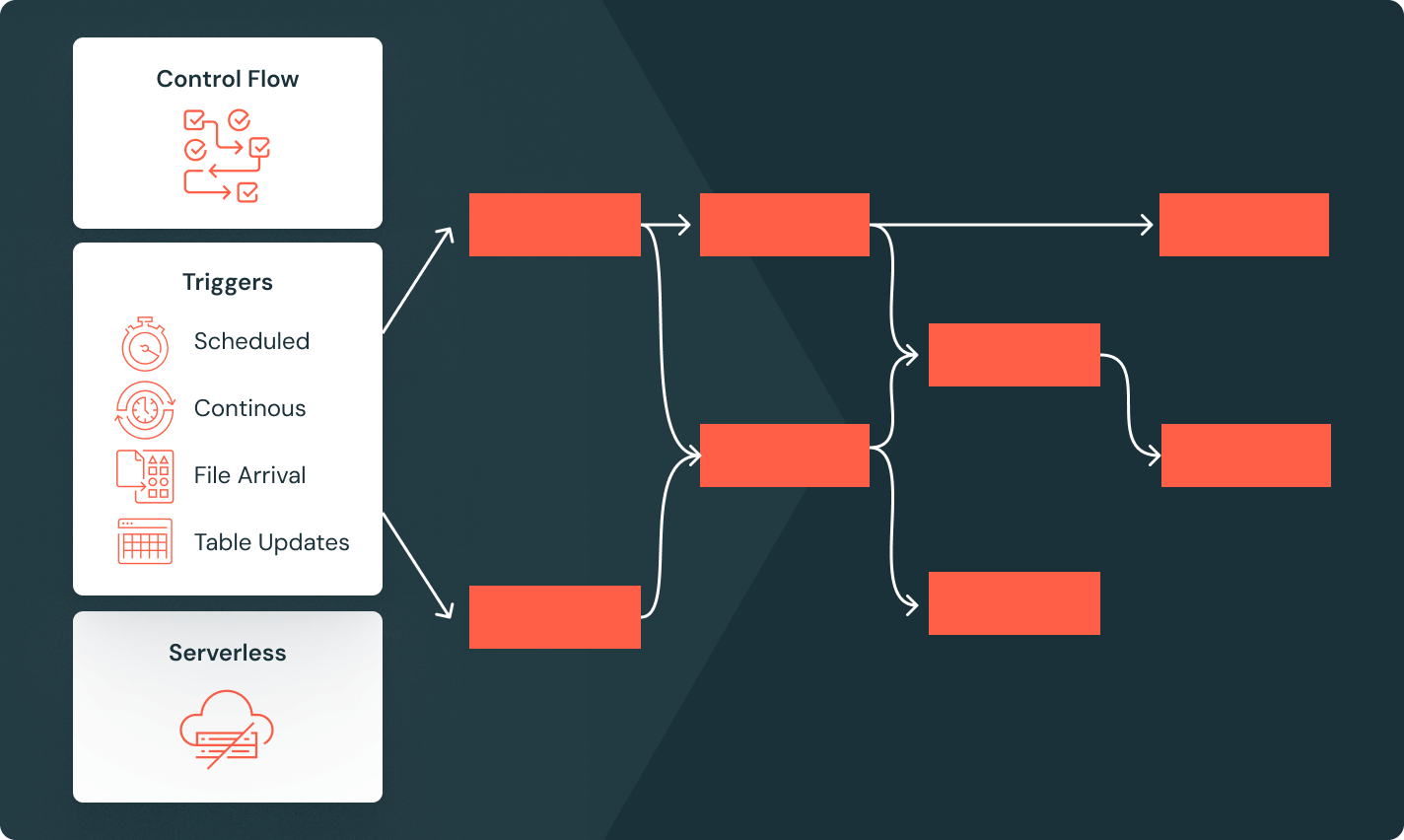
Lakeflow Jobs
Statten Sie Teams besser aus, um jeden ETL-, Analyse- und KI-Workflow mit tiefer Observability, hoher Zuverlässigkeit und breiter Unterstützung für verschiedene Aufgaben zu automatisieren und zu orchestrieren.

Unity Catalog
Regulieren Sie alle Ihre Datenressourcen nahtlos mit der branchenweit einzigen einheitlichen und offenen Governance-Lösung für Daten und KI, die in die Data Intelligence Platform von Databricks integriert ist.

Lakehouse-Speicherung
Vereinheitlichen Sie die Daten in Ihrem Lakehouse format- und typenübergreifend für alle Ihre Analytics- und KI-Workloads.
Data Intelligence Platform
Entdecken Sie die gesamte Bandbreite der auf der Databricks Data Intelligence Platform verfügbaren Tools zur nahtlosen Integration von Daten und KI in Ihrem Unternehmen.
Erstellen Sie zuverlässige Datenpipelines

Verwandeln Sie Rohdaten in hochwertige Goldtabellen
Implementieren Sie ETL-Pipelines, um Daten zu filtern, anzureichern, zu bereinigen und zu aggregieren, damit sie bereit für Analysen, KI und BI sind. Folgen Sie der Medaillon-Architektur, um Daten von Bronze- über Silber- bis zu Goldtabellen zu verarbeiten.

Wagen Sie den nächsten Schritt




FAQ zur Datenverarbeitung
Möchten Sie ein Daten- und KI-Unternehmen werden?
Machen Sie die ersten Schritte Ihrer Datentransformation