Lebenszyklus von Machine Learning vereinfachen
Mit Databricks von organisatorischen und technologischen Silos zu einer offenen und einheitlichen Plattform für den gesamten Daten- und ML-Lebenszyklus gelangen

Das Erstellen von ML-Modellen ist schwierig. Noch schwieriger ist es, sie in die Produktion zu verlagern. Die Aufrechterhaltung der Datenqualität und Modellgenauigkeit über einen längeren Zeitraum sind nur einige der Herausforderungen. Databricks rationalisiert die ML-Entwicklung auf einzigartige Weise – von der Vorbereitung bis hin zum Training und zur Bereitstellung von Daten – und zwar im großen Umfang.
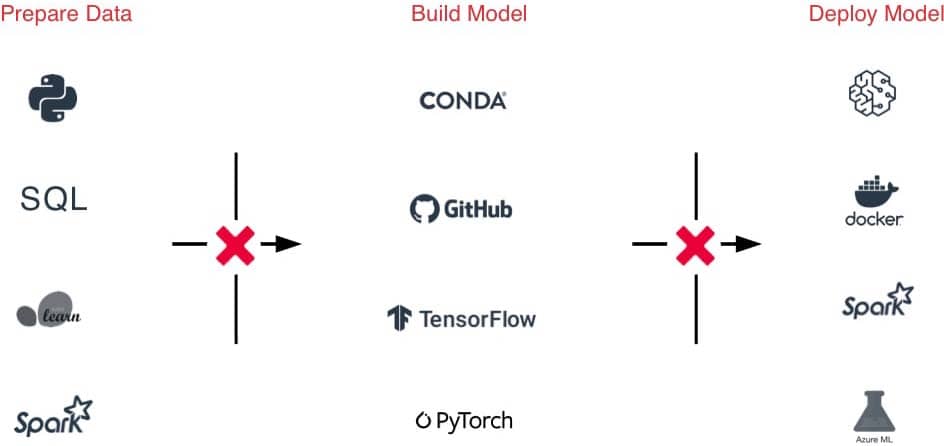
Die Herausforderung
Die schiere Vielfalt der ML-Frameworks erschwert die Verwaltung von ML-Umgebungen
Schwierige Übergaben zwischen Teams aufgrund unterschiedlicher Tools und Prozesse, von der Datenvorbereitung über Experimente bis hin zur Produktion
Schwer zu verfolgende Experimente, Modelle, Abhängigkeiten und Artefakte erschweren die Reproduktion der Ergebnisse
Sicherheits- und Compliance-Risiken
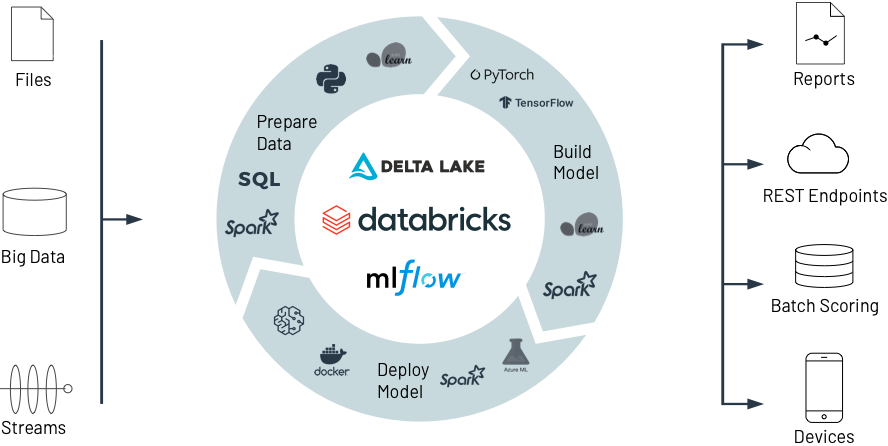
Die Lösung
Zugriff mit einem Klick auf gebrauchsfertige, optimierte und skalierbare ML-Umgebungen über den gesamten Lebenszyklus hinweg
Eine einzige Plattform für Datenaufnahme, Featurisierung, Modellerstellung, Optimierung und Produktion vereinfacht Übergaben
Experimente, Code, Ergebnisse und Artefakte können automatisch verfolgt und Modelle in einem zentralen Hub verwaltet werden
Erfüllen Sie Compliance-Anforderungen mit detailliert abgestimmter Zugriffskontrolle, Datenherkunft und Versionierung
Databricks für Machine Learning
Erfahren Sie, wie Databricks dabei hilft, gemeinsam Daten vorzubereiten, hochmoderne ML-Modelle zu erstellen, anzuwenden und zu verwalten – vom Experiment bis zur Produktion – und das in beispiellosem Umfang.
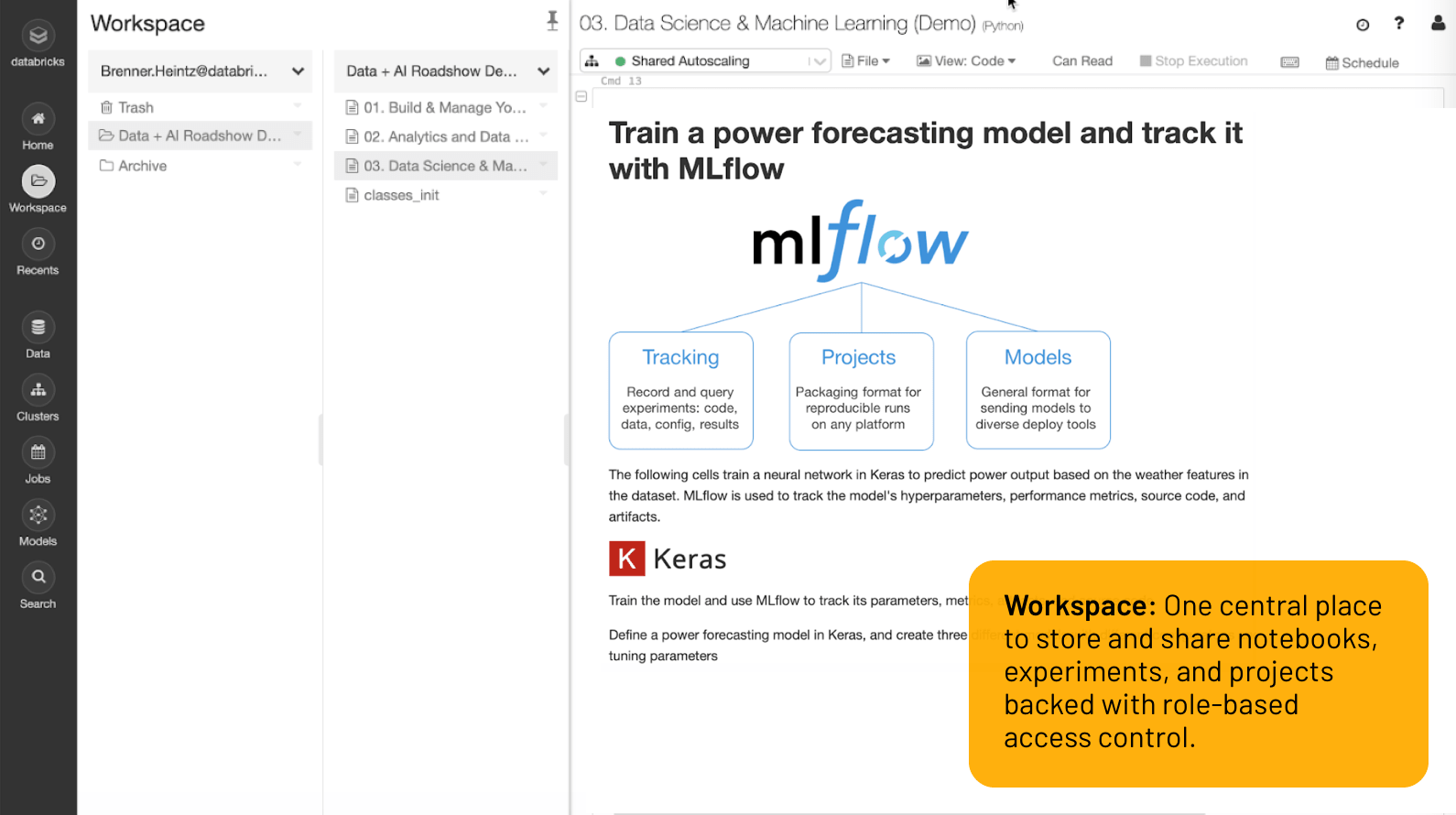
Workspace
Ein zentraler Ort zum Speichern und Teilen von Notebooks, Experimenten und Projekten mit rollenbasierter Zugriffssteuerung.
Vom Experimentieren zu Produktions-ML in unübertroffenem Umfang
Herausragende Entwicklerumgebung
Alles, was Sie zur Erledigung Ihres Jobs benötigen, ist im Workspace nur einen Klick entfernt: Datasets, ML-Umgebungen, Notebooks, Dateien, Experimente und Modelle sind alle sicher an einem Ort verfügbar.
Kollaborative Notebooks mit mehrsprachiger Unterstützung (Python, R, Scala, SQL) erleichtern die Arbeit im Team, während Co-Authoring, Git-Integration, Versionierung, rollenbasierte Zugriffssteuerung und mehr Ihnen dabei helfen, die Kontrolle zu behalten. Oder nutzen Sie einfach bekannte Tools wie Jupyter Lab, PyCharm, IntelliJ, RStudio mit Databricks, um von unbegrenzter Datenspeicherung und -verarbeitung zu profitieren.
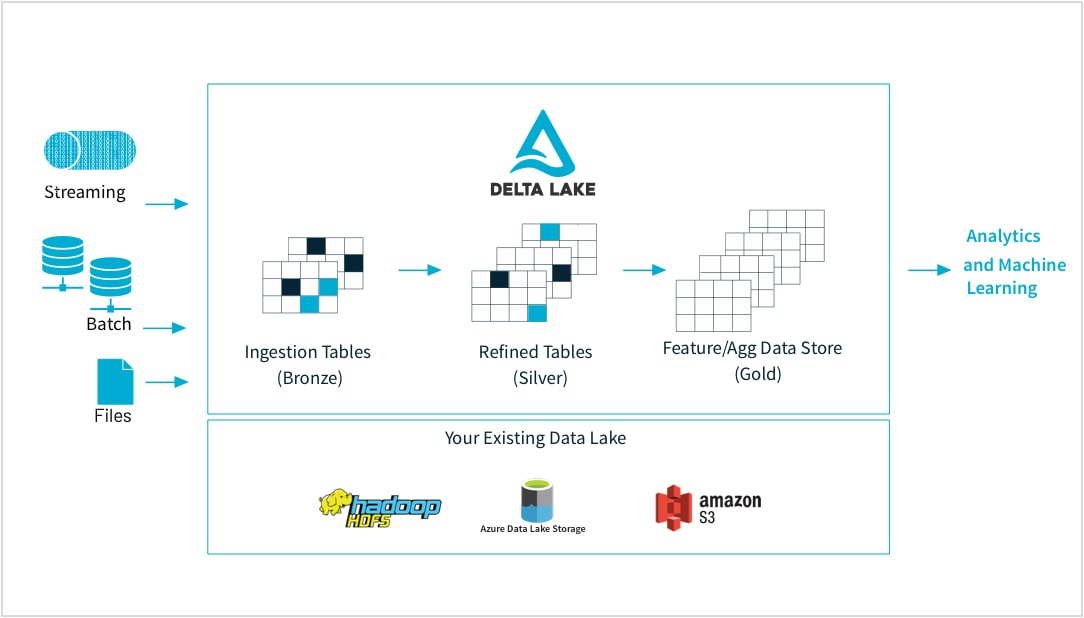
Von Rohdaten bis zum hochwertigen Feature Store
ML-Praktiker trainieren Modelle mit einer Vielzahl von Datenformen und -formaten: kleine oder große Datasets, DataFrames, Text, Bilder, Batch oder Streaming. Alle erfordern eine spezifische Pipeline und Transformationen.
Mit Databricks können Sie Rohdaten aus praktisch jeder Quelle aufnehmen, Batch- und Streaming-Daten zusammenführen, Transformationen planen, Tabellen versionieren und Qualitätsprüfungen durchführen, um sicherzustellen, dass die Daten makellos sind und für Analysen im gesamten Unternehmen bereitstehen. So können Sie jetzt je nach Bedarf nahtlos und zuverlässig an beliebigen Daten, CSV-Dateien oder umfangreichen Data-Lake-Aufnahmen arbeiten.

Der beste Ort zum Ausführen von scikit-learn, TensorFlow, PyTorch und mehr ...
ML-Frameworks entwickeln sich rasant weiter, was die Wartung von ML-Umgebungen zu einer Herausforderung macht. Databricks ML Runtime bietet gebrauchsfertige und optimierte ML-Umgebungen, einschließlich der beliebtesten ML-Frameworks (scikit-learn, TensorFlow usw.) sowie Conda-Unterstützung.
Integriertes AutoML wie Hyperparameter-Tuning hilft dabei, schneller zu Ergebnissen zu gelangen, und mit der vereinfachten Skalierung können Sie mühelos von kleinen Datenverarbeitungsjobs zu Big Data wechseln, sodass Sie nicht mehr durch die verfügbare Datenverarbeitungsleistung eingeschränkt werden. Trainieren Sie beispielsweise Deep-Learning-Modelle schneller, indem Sie die Datenverarbeitung mit HorovodRunner auf Ihre Cluster verteilen, und holen Sie mehr Performance aus jeder GPU in Ihren Clustern heraus, indem Sie die CUDA-optimierte Version von TensorFlow ausführen.
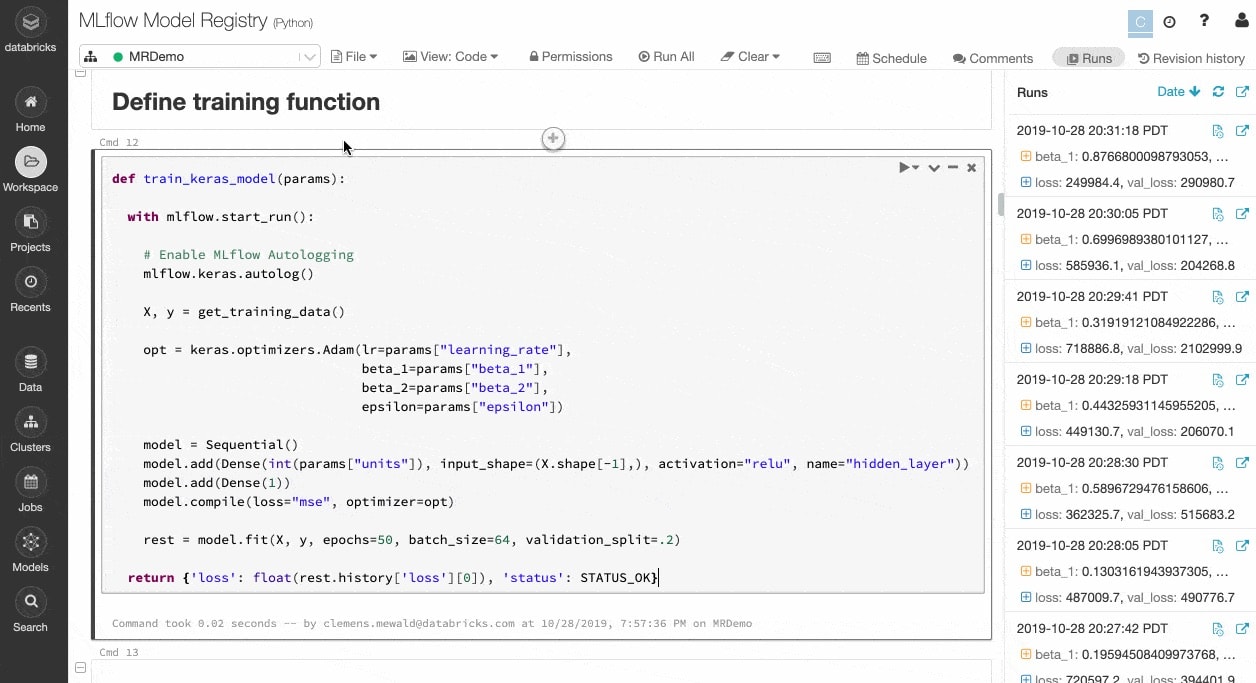
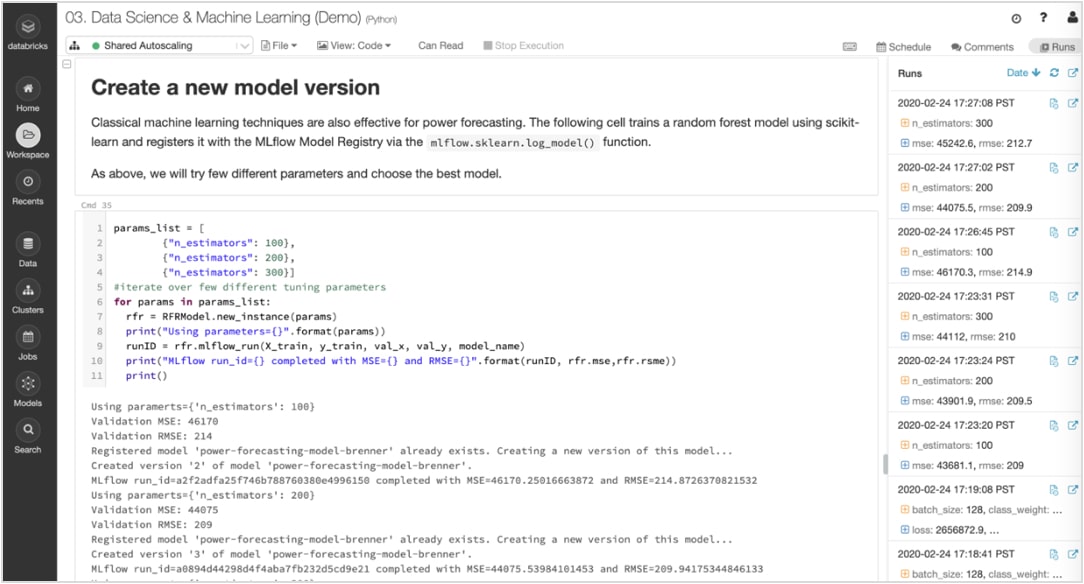
Experiment und Artefakte verfolgen, um die Ausführungen später zu reproduzieren
ML-Algorithmen verfügen über Dutzende konfigurierbarer Parameter, und unabhängig davon, ob sie alleine oder im Team arbeiten, ist es schwierig zu verfolgen, welche Parameter, Codes und Daten in jedes Experiment eingeflossen sind, um ein Modell zu erstellen.
MLflow verfolgt Ihr Experiment automatisch zusammen mit Artefakten wie Daten, Code, Parametern und Ergebnissen für jedes Training, das in Notebooks ausgeführt wird. So können Sie frühere Ausführungen schnell auf einen Blick einsehen, Ergebnisse vergleichen und bei Bedarf auf eine frühere Version Ihres Codes zurückgreifen. Sobald Sie die beste Version eines Modells für die Produktion ermittelt haben, registrieren Sie sie in einem zentralen Repository , um sie zur Bereitstellung einzureichen und Übergaben zu vereinfachen.
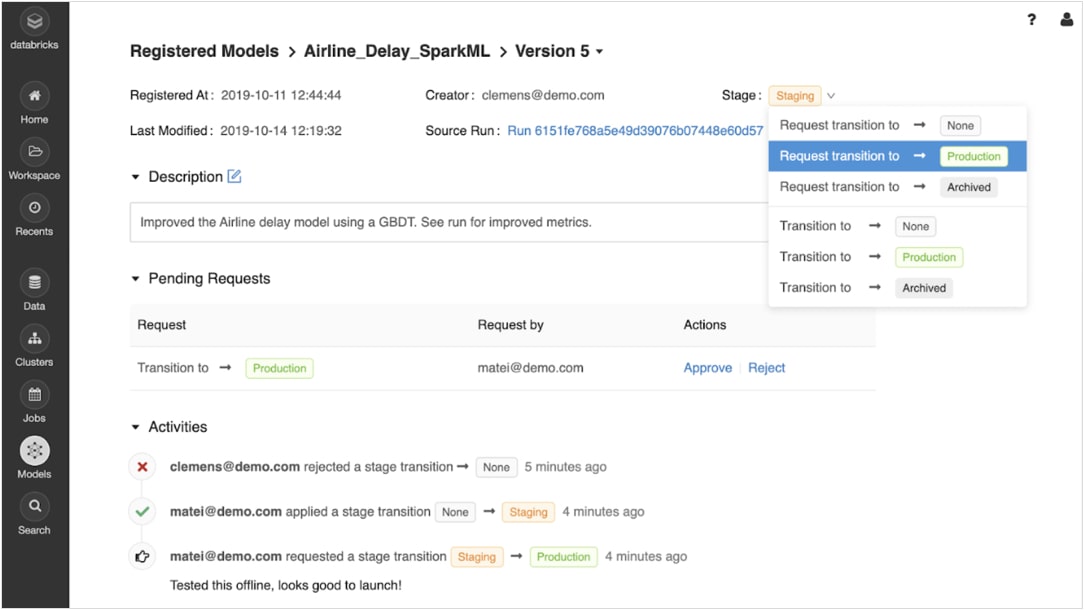
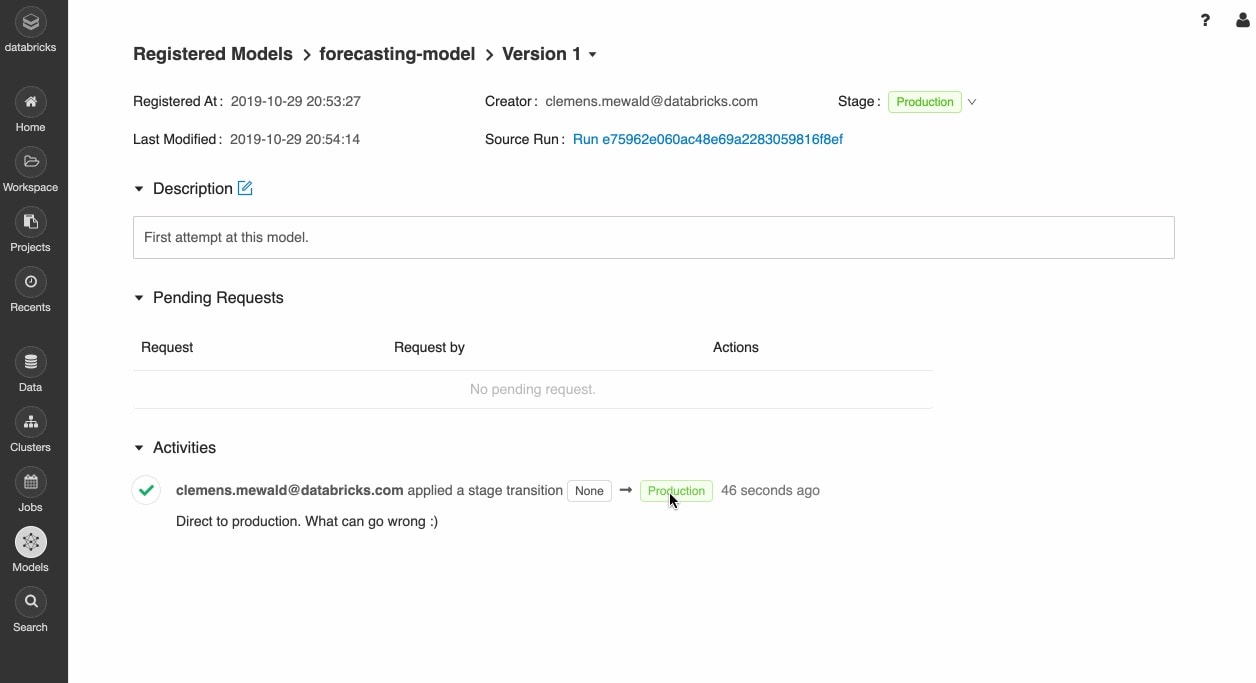
Sicher vom Prototyping zur Produktion übergehen
Nach der Registrierung der trainierten Modelle können Sie sie mit der MLflow-Modellregistrierung während des gesamten Lebenszyklus kollaborativ verwalten.
Modelle können versioniert werden und verschiedene Stadien durchlaufen, z. B. Experimentieren, Staging, Produktion und Archivierung. Beteiligte können Kommentare abgeben und Anträge zur Änderung der Phase einreichen. Das gesamte Lebenszyklusmanagement lässt sich in Genehmigungs- und Governance-Workflows mit rollenbasierten Zugriffskontrollen integrieren.
Modelle überall bereitstellen
Implementieren Sie schnell Produktionsmodelle für Batch-Inferenz auf Apache Spark™ oder als REST-APIs mithilfe der integrierten Integration mit Docker-Containern, Azure ML und Amazon SageMaker.
Operationalisieren Sie Produktionsmodelle mit dem Jobs Scheduler und automatisch verwalteten Clustern, um sie je nach Geschäftsanforderungen zu skalieren.
Bringen Sie die neuesten Versionen Ihrer Modelle schnell in die Produktion und überwachen Sie den Modelldrift mit Delta Lake und MLflow.
Ressourcen
Bericht

E-Book

E-Book

Ready to get started?