Databricks Connect:ホスト型 Apache Spark™ をアプリ、マイクロサービスに

Databricks Connect は、ネイティブな Apache Spark API を任意の Notebook、IDE、カスタムアプリから利用可能にするための新たなライブラリです。今回はその概要をご説明します。
概要
ここ数年、Apache Spark 向けにさまざまなカスタムアプリケーションコネクタが開発されています。spark-submit、REST ジョブサーバー、Notebook ゲートウェイなどのツールなどが含まれます。しかし、これらのツールには多くの制限があります。以下はその一部です。
- 汎用的でなく、特定の IDE や Notebook でのみ動作するものが多い。
- アプリケーションを Spark クラスタ内でホストして実行することが必要な場合がある。
- Spark 上で別のプログラミングインターフェイスのセットと統合する必要がある。
- ライブラリの依存関係を変更するには、クラスタの再起動が必要である。
一方、SQL データベースサービスへの接続では、ライブラリをインポートしてサーバーに接続するだけです。
Spark の構造化データ API に相当するものは、以下のようになります。
Databricks Connect が開発される以前は、上記のスニペットは、シング�ルマシンの Spark クラスタのみでしか機能せず、spark-submit などの追加ツールがなければ、複数マシンやクラウドに容易にスケーリングできませんでした。
Databricks Connect クライアント
Databricks Connect は、普遍的な Spark クライアントライブラリを提供することで、Spark コネクタのストーリーを完成させます。これにより、Jupyter、Zeppelin、Colab などの Notebook アプリケーションや、Eclipse、PyCharm、Intellij、RStudio などの IDE、カスタム Python/Java アプリケーションから Spark ジョブを実行できるようになります。
これは、pyspark や org.apache.spark のインポートが可能な場所であれば、Databricks クラスタの大規模なジョブのシームレスな実行が可能になったことを意味します。例として、Databricks Connect を使用して Spark ジョブをリモートで実行する CoLab Notebook をご紹介します。ここで重要なのは、アプリケーション固有の統合はないことです。Databricks Connect ライブラリをインストールしてインポートするだけです。また、GCP から S3 データセットを読み込んでいます。これは、Spark クラスタ自体が AWS リージョンでホストされているため可能になります。
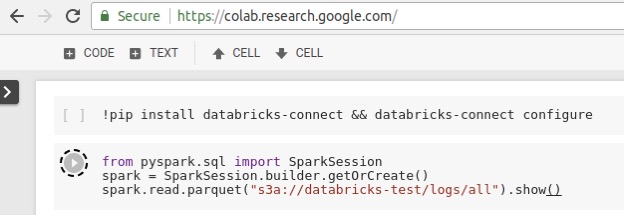
Databricks Connect から起動されたジョブは Databricks クラスタ上でリモートで実行され、分散コ�ンピューティングを活用します。また、Databricks Spark UI を使用して監視できます。

ガートナー®: Databricks、クラウドデータベースのリーダー

ユースケース
現在、100 社を超えるお客様に Databricks Connect をご利用いただいています。注目すべきユースケースには次のようなものがあります。
開発、CI/CD
- ローカル IDE を使用してコードをデバッグしながら、Databricks がホストするクラスタを操作します。
- CI/CD パイプラインにおける Spark アプリケーションの本番環境に対してテストを実施しています。
対話型分析
- 多くのユーザーが Databricks Connect を利用して、任意の Jupyter,、bash などのシェルや、RStudio などのスタジオ環境を��使用し、Databricks クラスタに対してインタラクティブなクエリを発行しています。
アプリケーション開発
- あるヘルスケア分野の大手顧客では、インタラクティブなユーザークエリを提供する Python ベースのマイクロサービスのデプロイに Databricks Connect を利用。このクエリサービスでは、Databricks Connect ライブラリを使用して、複数の Databricks クラスタに対して Spark ジョブをリモートで実行し、1 日に数千ものクエリを提供しています。
Databricks Connect の仕組み
普遍的なクライアントライブラリを構築するために、次の 2 つの要件を満たす必要がありました。
- アプリケーションの観点から見て、クライアントライブラリは Spark のフルバージョンと全く同じように動作しなければいけない。(つまり、SQL、DataFrames などを使用できる。)
- 物理的な計画や実行など、容量のある運用は、クラウドのサーバーで実行する必要がある。そうしないと、クライアントクラスタと共存していない場合に、広域ネットワークでのデータ読み取りに多くのオーバーヘッドが発生する可能性がある。
これらの要件を満たすために、アプリケーションが Spark API を使用する場合、Databricks Connect ライブラリでは、ジョブの計画を分析フェーズまで実行します。これにより、Databricks Connect ライブラリが Spark と同じ動作をすることを可能になり、要件 1 を満たします。要件 2 に対しては、ジョブの実行準備が整うと、 Databricks Connect は論理的なクエリプランをサーバーに送信し、そこで実際の物理的な実行と IO が行われるようにしました。
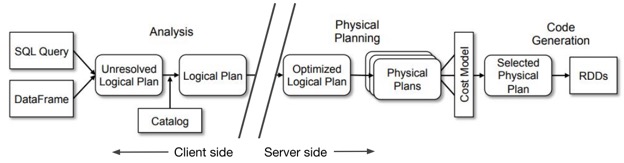
図 1:Databricks Connect では、Spark ジョブのライフタイムを、論理解析まで行うクライアントフェーズとリモートクラスタで実行するサーバーフェーズに分割します。
Databricks Connect クライアントは、さまざまなユースケースで適切に機能するように設計されています。REST 経由でサーバーと通信し、プラットフォームの API トークンを通じて認証と承認を容易にします。セッションは複数のユーザー間で隔離されるため、セキュアで同時アクセス性の高いクラスタの共有を実現します。結果は、効率的なバイナリ形式にストリームバックされ、高性能を実現します。使用されるプロトコルはステートレスであり、フォールトトレランスなアプリケーションの容易な構築が可能で、クラスタが再起動されても作業が失われることはありません。
利用
Databricks Connect は、DBR 5.4リリースから一般提供を開始し、Python、Scala、Java、および R のワークロードをサポートしています。複数言語対応の PyPI の「pip install databricks-connect」から入手いただけます。また、ドキュメントはこちらをご覧ください。