Delta Lake を深堀り:トランザクションログの解析

![]()
トランザクションログは、ACIDトランザクション、スケーラブルなメタデータ処理、タイムトラベルなど、Delta Lake の最も重要な機能の多くに共通する要素であるため、Delta Lake を理解するうえで重要な鍵となります。この記事では、Delta Lake のトランザクションログとは何か、ファイルレベルでどのように動作するのか、そして、複数の同時読み取りと書き込みの問題に対してどのようにエレガントなソリューションを提供するのかを探ります。
Delta Lake のトランザクションログとは
Delta Lakeトランザクションログ(DeltaLog とも呼ばれる)は、Delta Lake テーブルで実行された全てのトランザクションの記録で、その開始以来、順番に記録されています。
トランザクションログの目的
シングルソースオブトゥルース
Delta Lake は Apache Spark™ 上に構築されており、あるテーブルの複数のリーダーやライターが同時にテーブル上で作業することを可能にしています。ユーザーに常に正しいデータビューを見せるために、Delta Lake のトランザクションログは、ユーザーがテーブルに加えた全ての変更を追跡する中央リポジトリとして、単一の情報源として機能します。
ユーザーが Delta Lake のテーブルを初めて読み込むとき、または最後に読み込んだときから変更されたオープンなテーブルに対して新しいクエリを実行するとき、Spark はトランザクションログをチェックして、どの新しいトランザクションがテーブルに投稿されたかを確認し、それらの新しい変更でエンドユーザーのテーブルを更新します。これにより、ユーザーのテーブルのバージョンは、常に最新のクエリの時点でマスターレコードと同期され、ユーザーがテーブルに矛盾した変更を加えることができないようにします。
Delta Lake における原子性の実装
ACIDトランザクションの4つの特性の1つである原子性は、データレイクに対して行われる操作(INSERT や UPDATE など)が完全に完了するか、まったく完了しないかを保��証するものです。この性質がないと、ハードウェア障害やソフトウェアのバグによって、テーブルにデータが部分的にしか書き込まれず、結果としてデータが乱れたり破損したりすることがあります。
トランザクションログは、Delta Lake が原子性を保証するためのメカニズムです。トランザクションログに記録されていないことは、何も起きていないことを意味します。完全に実行されたトランザクションのみを記録し、その記録を単一の情報源として使用することで、Delta Lake のトランザクションログは、ユーザーがデータについて推論し、ペタバイトスケールでその基本的な信頼性について安心感を持つことができるようにします。
トランザクションログの仕組み
アトミックコミットへのトランザクションの分解
ユーザーがテーブルを変更する操作(INSERT、UPDATE、DELETEなど)を行うたびに、Delta Lakeはその操作を、以下の1つまたは複数のアクションからなる一連の個別のステップに分解しています。
- ファイルの追加:データファイルを追加
- ファイルの削除:データファイルを削除
- メタデータの更新:テーブルのメタデータを更新(例:テーブルの名前、スキーマ、パーティショニングの変更)
- トランザクションの設定:構造化ストリーミングジョブが与えられた ID でマイクロバッチをコミットしたことを記録
- プロトコルの変更:Delta Lake のトランザクションログを最新のソフトウェアプロトコルに切り替えることにより、新機能を有効にす��る
- コミット情報:コミットに関する情報、どの操作がいつ、どこから行われたか、などの情報を含む
これらのアクションは、コミットとして知られる順序付けられた原子単位として、トランザクションログに記録されます。
例えば、あるユーザーがテーブルに新しいカラムを追加し、さらにデータを追加するトランザクションを作成したとします。Delta Lake はそのトランザクションを構成要素に分解し、トランザクションが完了したら、それらを以下のコミットとしてトランザクションログに追加します。
- メタデータの更新:新しいカラムを含むようにスキーマを変更
- ファイルの追加:新しいファイルが追加されるたびに、ファイルを追加
ファイルレベルの Delta Lake トランザクションログ
ユーザーが Delta Lake のテーブルを作成すると、そのテーブルのトランザクションログは自動的に _delta_log サブディレクトリに作成されます。そのユーザーがテーブルに変更を加えると、それらの変更は、トランザクションログに順番に、アトミックなコミットとして記録されます。各コミットは 000000.json で始まる JSON ファイルとして書き出されます。テーブルへの追加の変更は、次のコミットが 000001.json、その次が 000002.json というように、数値の昇順で後続の JSON ファイルを生成するようになります。
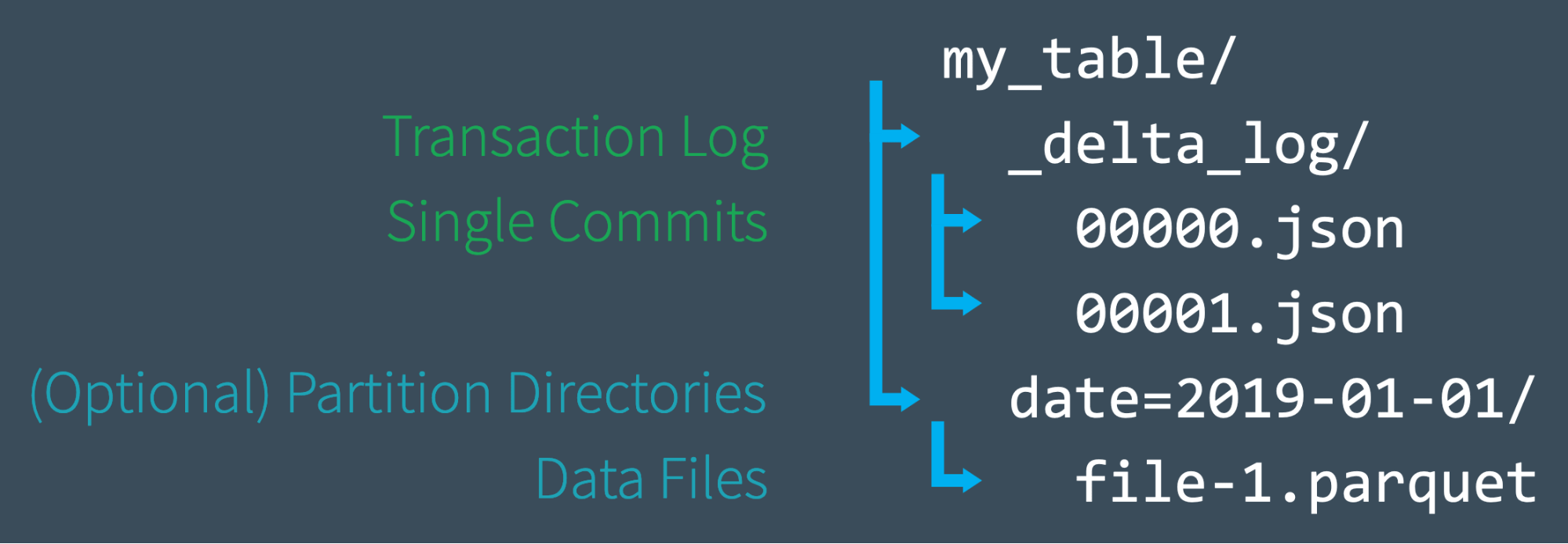
たとえば、データファイル 1.parquet と 2.parquet からテーブルにレコードを追加するとします。このトランザクションは自動的にトランザクションログに追加され、コミット 000000.json としてディスクに保存されます。その後、気が変わって、これらのファイルを削除し、代わりに新しいファイル(3.parquet)を追加することにするかもしれません。これらのアクションは、トランザクションログの次のコミットとして、以下のように 000001.json として記録されます。

1.parquet と 2.parquet は、もはや Delta Lake のテーブルの一部ではありませんが、それらの追加と削除は、最終的に互いにキャンセルされたにもかかわらず、我々のテーブル上で実行されたため、トランザクションログに記録されています。Delta Lake は、このようなアトミックコミットを保持することで、テーブルの監査や、ある時点でのテーブルの状態を確認するための「タイムトラベル」が必要な場合に、それを正確に実行できるようにします。
また、テーブルから基礎となるデータファイルを削除しても、Sparkはディスクからファイルを熱心に削除してくれません。ユーザーは、VACUUM を使用して、不要になったファイルを削除することができます。
チェックポイン�トファイルによる状態の迅速な再計算
トランザクションログに合計 10 回コミットしたら、Delta Lake は同じ_delta_log サブディレクトリにチェックポイントファイルを Parquet フォーマットで保存します。Delta Lake は、10 回のコミットごとに自動的にチェックポイントファイルを生成します。
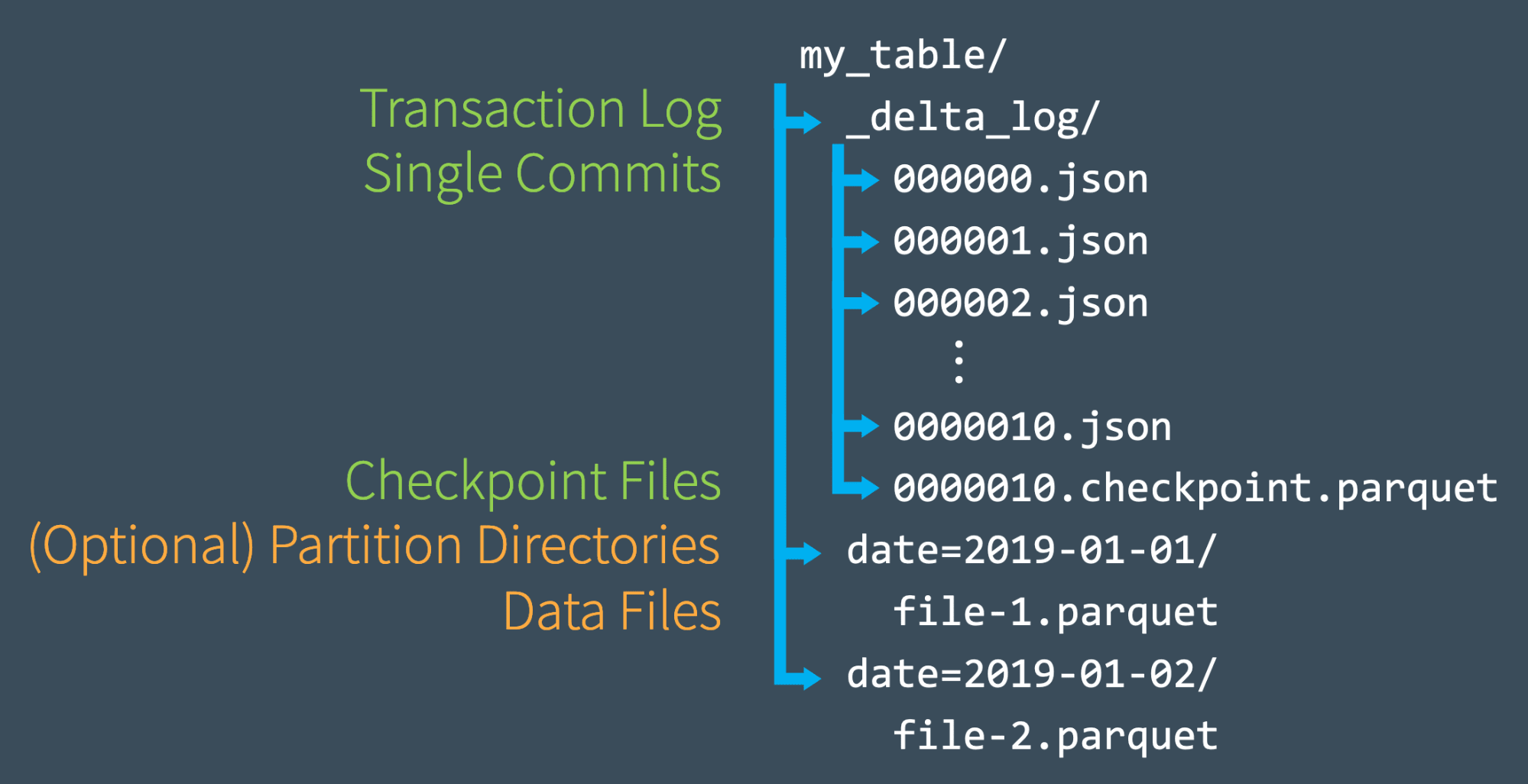
これらのチェックポイントファイルは、ある時点におけるテーブルの状態全体を、Spark が迅速かつ容易に読み込めるネイティブな Parquet フォーマットで保存します。言い換えれば、チェックポイントファイルはテーブルの状態を完全に再現するための一種の "ショートカット "であり、これによりSparkは何千もの小さく非効率な JSON ファイルの再処理を回避することができるのです。
スピードアップするために、Spark は listFrom オペレーションを実行して、トランザクションログ内の全てのファイルを表示し、最新のチェックポイントファイルに素早く飛ばし、最新のチェックポイントファイルが保存されてから行われた JSON コミットのみを処理することが可能です。
この仕組みを説明するために、下図のように 000007.json までのコミットを作成したとします。Sparkはこのコミットまで、最新バージョンのテーブルを自動的にメモリにキャッシュしており、スピードアップしています。しかし、その間に他のライター (おそらく熱心なチームメイト) がテーブルに新しいデータを書き込んで、0000012.json までのコミットを追加しています。
これらの新しいトランザクションを取り込み、テーブルの状態を更新するために、Spark は listFrom version 7 オペレーションを実行して、テーブルの新しい変更を確認することができます。

中間的な JSON ファイルを全て処理するのではなく、Spark は直近のチェックポイントファイルまでスキップすることができます。なぜなら、そのファイルにはコミット#10 時点でのテーブルの状態が全て含まれているからです。これにより、Spark は 0000011.json と 0000012.json の増分処理を行うだけで、テーブルの現在の状態を手に入れることができるのです。その後、Spark はテーブルのバージョン12をメモリにキャッシュします。このワークフローに従うことで、Delta Lake は Spark を使用して、効率的にテーブルの状態を常に更新することができるようになりました。
複数同時の読み書きの処理
Delta Lake のトランザクションログがどのように機能するかを高いレベルで理解したところで、並行処理について説明します。これまでの例では、ユーザーがトランザクションを線形に、あるいは少なくとも競合なくコミットするシナリオを主に取り上げてきました。しかし、Delta Lake が複数の同時読み取りや書き込みを処理する�場合はどうなるのでしょうか。
その答えは簡単です。Delta Lake は Apache Spark を搭載しているため、複数のユーザーが一度にテーブルを変更することは可能なだけでなく、想定されることなのです。このような状況に対処するために、Delta Lake は楽観的同時実行制御を採用しています。
楽観的同時実行性制御とは
楽観的同時実行制御とは、同時実行トランザクションの処理方法の一つで、異なるユーザーによるテーブルへのトランザクション(変更)が互いに衝突することなく完了することを想定しています。ペタバイト級のデータを扱う場合、ユーザーはデータの異なる部分を完全に操作する可能性が高いため、競合しないトランザクションを同時に完了させることができ、信じられないほど高速に処理することができます。
例えば、あなたと私が一緒にジグソーパズルを作っているとします。例えば、あなたは角の部分、私は端の部分というように、お互いが異なる部分を作業している限り、大きなパズルのそれぞれの部分を同時に作業して、2倍の速さでパズルを完成させることができない理由はないでしょう。同じピースを同時に必要とするときだけ、衝突が発生するのです。それが楽観的並行性制御です。
もちろん、楽観的な同時実行制御を行っても、ユーザーがデータの同じ部分を同時に変更しようとすることはあります。幸いなことに、Delta Lake にはそのためのプロトコルが用意されています。
競合を楽観的に解決する
ACIDトランザクションを提供するために、Delta Lake はコミットの順序(データベースにおけるシリアライザビリティの概念として知られています)を決定し、2 つ以上のコミットが同時に行われた場合にどうするかを決定するためのプロトコルを備えています。Delta Lake は、相互排除のルールを実装し、競合を楽観的に解決しようとすることで、これらのケースを処理します。このプロトコルにより、Delta Lake は ACID の原則である分離を実現し、複数の同時書き込みの後のテーブルの状態が、それらの書き込みが互いに分離して連続的に行われた場合と同じであることを保証します。
一般に、このプロセスは次のように進みます。
- 開始するテーブルのバージョンを記録
- 読み取り/書き込みを記録
- コミットを試みる
- 他の人がコミットした場合、自分が読んだ内容が変更されていないかを確認する
- これを繰り返す
これがリアルタイムでどのように行われるかを見るために、下の図を見て、コンフリクトが発生したときにDelta Lakeがどのように管理するのか見てみましょう。2人のユーザーが同じテーブルから読み込み、それぞれデータを追加しようとしたとします。

- Delta Lake は、変更を加える前に読み込まれるテーブルの開始バージョン(バージョン0)を記録します。
- ユーザー1 と 2 は、同時にテーブルに何らかのデータを追記��しようとします。ここで、次に来るコミットは1つだけで、000001.json として記録されるため、衝突が発生しました。
- Delta Lake はこの競合を「相互排除」という概念で処理します。つまり、1人のユーザーだけが 000001.json のコミットを成功させることができるのです。ユーザー1 のコミットは受け入れられ、ユーザー2 のコミットは拒否されます。
- Delta Lake はユーザー2 に対してエラーを投げるのではなく、この衝突を楽観的に処理することを好みます。テーブルに対して新しいコミットが行われたかどうかを確認し、その変更を反映するためにテーブルを静かに更新します。そして、新しく更新されたテーブルに対してユーザー2のコミットを単純に再試行し(データ処理なしで)、000002.json を正常にコミットします。
ほとんどの場合、このリコンサイルは静かに、シームレスに、そして成功裏に行われます。しかし、Delta Lakeが楽観的に解決できない問題が発生した場合(たとえば、ユーザー1がファイルを削除し、ユーザー2も削除した場合)、唯一の選択肢は、エラーを投げることです。
最後に、Delta Lake のテーブルで行われたトランザクションは全てディスクに直接保存されるため、この処理は ACID 特性の耐久性を満たしており、システム障害が発生した場合でも持続することを意味しています。
その他の使用例
タイムトラベル
全てのテーブルは、Delta Lake のトランザクションログに記録された全てのコミットの合計の結果であり、それ以上でも以下でもありません。トランザクションログは、テーブルの元の状態から現在の状態になるまでの正確な方法を、段階的に説明するガイドを提供します。
したがって、元のテーブルから始めて、その時点より前に行われたコミットのみを処理することで、任意の時点のテーブルの状態を再現することができるのです。この強力な能力は、「タイムトラベル」またはデータのバージョニングとして知られており、さまざまな状況での救世主となり得るものです。詳細については、ブログ:Introducing Delta Time Travel for Large Scale Data Lakes をご覧いただくか、Delta Lake のタイムトラベルドキュメントを参照してください。
データリネージとデバッグ
Delta Lake のトランザクションログは、テーブルに加えられた全ての変更の決定的な記録であり、ガバナンス、監査、コンプライアンスに有効な検証可能なデータリネージをユーザーに提供します。また、不注意による変更やパイプラインのバグの原因を、その原因となったアクションに遡って追跡することも可能です。DESCRIBE HISTORY を実行すると、行われた変更に関するメタデータを確認することができます。
Delta Lakeトランザクションログの概要
今回のブログでは、Delta Lake のトランザクションログの仕組みについて、以下�のような詳細を掘り下げてみました。
- トランザクションログとは何か、どのような構造になっているか、コミットがどのようにディスク上のファイルとして保存されるか。
- トランザクションログはどのように真実の単一ソースとして機能し、Delta Lake が原子性の原則を実装することを可能にしているのか。
- Delta Lake が各テーブルの状態を計算する方法 - 最新のチェックポイントから追いつくためにトランザクションログを使用する方法を含む。
- 楽観的同時実行制御を使用し、テーブルが変更されても、複数の同時読み取りと書き込みを可能にする。
- Delta Lake は、相互排除を使用してコミットが適切にシリアル化されるようにし、競合が発生した場合に静かに再試行する方法。
Delta Lake のオンラインハブで詳細をご覧いただけます。最新のコードをダウンロードし、Delta Lake コミュニティに参加することができます。
関連リソース
このシリーズのブログ:
Delta Lake を深堀り#1:トランザクションログの解析
Delta Lake を深堀り#2:Delta Lake でのスキーマ(schema)DB の適用・展開とは
Delta Leke を深堀り#3:DML 内部(更新、削除、マージ)
関連記事:

