MLflow モデルレジストリをエンタープライズ機能に拡張

Databricks の MLflow モデルレジストリにエンタープライズレベルの新機能が追加されました。Databricks の統合分析プラットフォームをご利用いただいている場合、MLflow モデルレジストリはデフォルトで有効になります。
このブログでは、モデル管理を一元化するハブとしての MLflow モデルレジストリのメリットをご紹介し、組織内のデータチームによるモデル共有やアクセス制御、モデルレジストリ API を活用した統合や検証について解説します。
MLflow によるハブの一元化が、モデルライフサイクル管理のコラボレーションを可能に
MLflow には、実験の一部としてのメトリクス、パラメータ、アーティファクトをトラッキングする機能、モデルや再現可能な ML プロジェクトをパッケージ化する機能、モデルをバッチやリアルタイムでサービングプラットフォームにデプロイする機能が備わっています。MLflow モデルレジストリは、これらの既存機能をベースとして、モデルのデプロイメントのライフサイクルを管理するための中央リポジトリを提供します。AWS、Azure との連携についてはそれぞれのページをご覧ください。
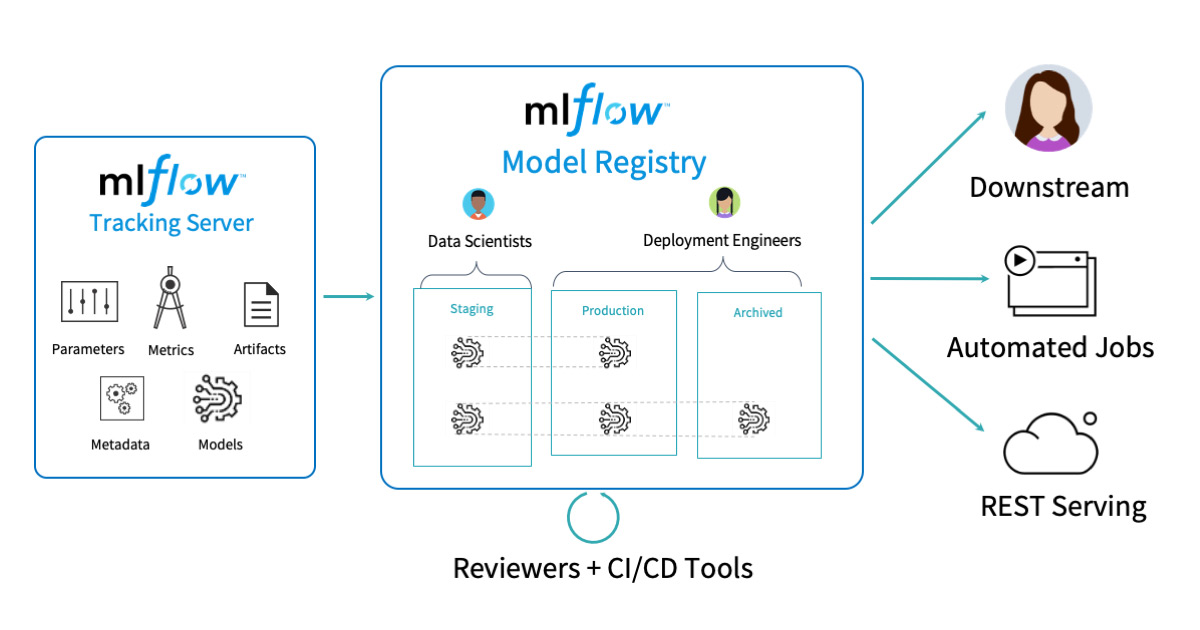
図1:モデル管理を目的とした MLflow 集中管理ハブの CI/CD ツール、アーキテクチャ、ワークフローの概要
大規模な組織に所属するデータサイエンティストが抱える主要課題の 1 つは、コラボレーションやコードの共有が可能で、モデルのデプロイメントステージの遷移やバージョン、履歴を管理する中央リポジトリがないことです。ML Model Registry のような組織内のモデルを一元管理できるレジストリがあれば、データチームでは以下のことができるようになります。
- 登録されたモデル、モデル開発の現在のステージ、実験のラン、登録されたモデルの関連コードの探索
- モデルのデプロイメントステージの遷移
- MLOps エンジニアによる多様なモデルバージョンでのデプロイ、テストの実施(登録されたモデルの異なるバージョンを、それぞれのステージでデプロイ可能になるため)
- 履歴保持を目的とした古いモデルのアーカイブ
- モデルライフサイクル全体でのアクティビティおよびアノテーションの詳細記録
- モデル登録、遷移、変更のきめ細かいアクセスおよび権限の制御
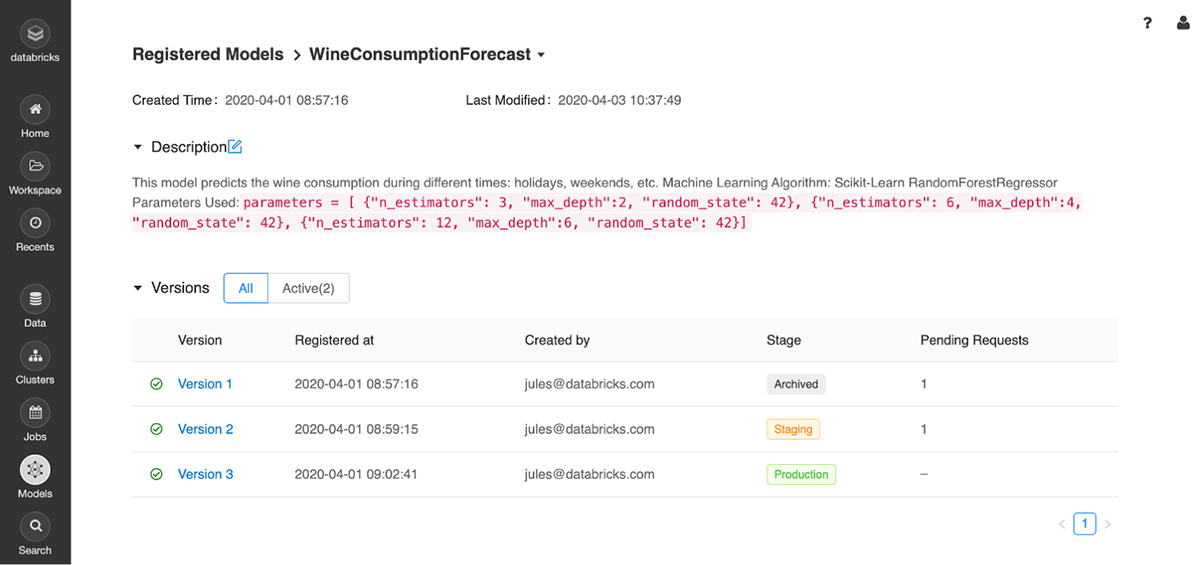
図2:モデルレジストリでは、ライフサイクル全体における各ステージの異なるバージョンを表示
アクセス制御によるモデルのステージ管理
データと機械学習のイノベーションが進んだ現在、モデルは貴重な資産となり、ビジネス戦略に欠かせないものとなっています。機械の故障予測、消費電力や業績の予測、不正や異常の検知、関連商品の購入を促す提案など、ビジネス上の問題を解決するソリューションの一部としてモデルが活用されています。
モデルのトレーニングやスコアリングには機密データが使用されることもあります。そのため、許可されたユーザーのみがモデルにアクセスできるようにするアクセス制御リスト(ACL)が必須です。ACL の設定により、モデルのライフサイクルを通じて、データチームの管理者がモデル操作にきめ細かなアクセス権を付与し、モデルの不適切な使用や、承認されていないモデルのプロダクションステージへの遷移を防ぐことができます。
Databricks の統合分析プラットフォームでは、一般的な Databricks のアクセス制御とアクセス権モデルに従って、登録された個々のモデルにアクセス権を設定(AWS、Azure)できるようになっています。
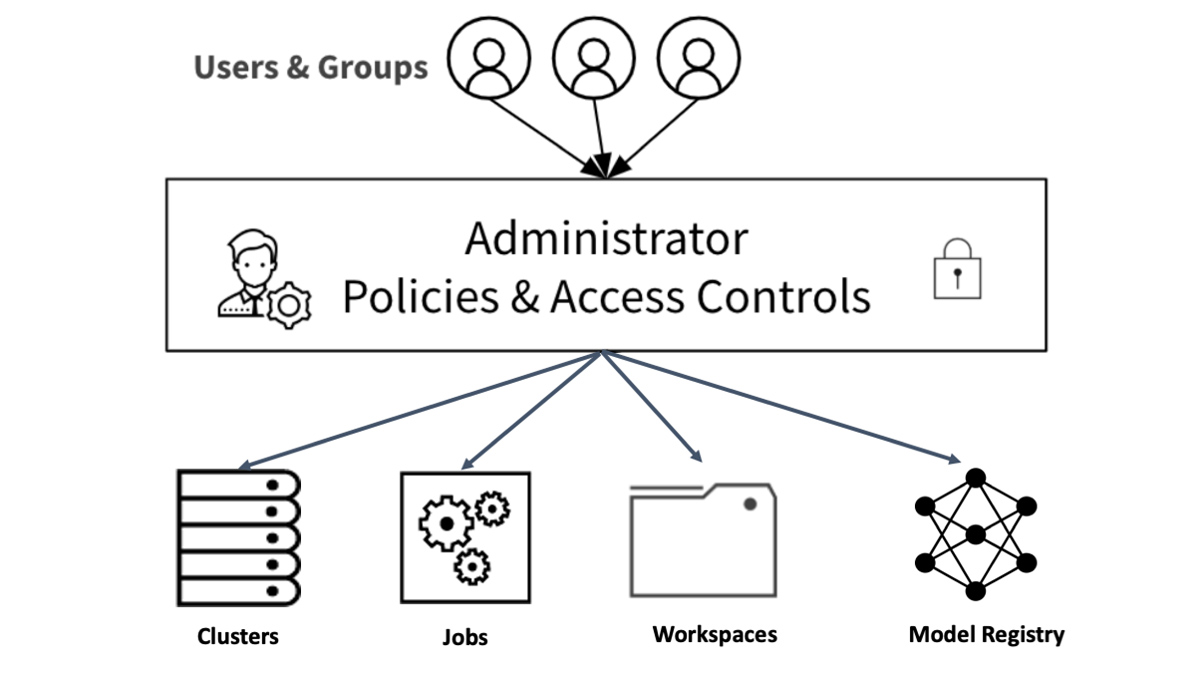
図3:Databricks アセットのアクセス制御ポリシー
Databricks ワークスペースのモデルレジストリ UI から、Notebook やクラスタと同様に、レジストリ内のモデルに対する適切な権限を指定して、ユーザーやグループを割り当てることが可能です。
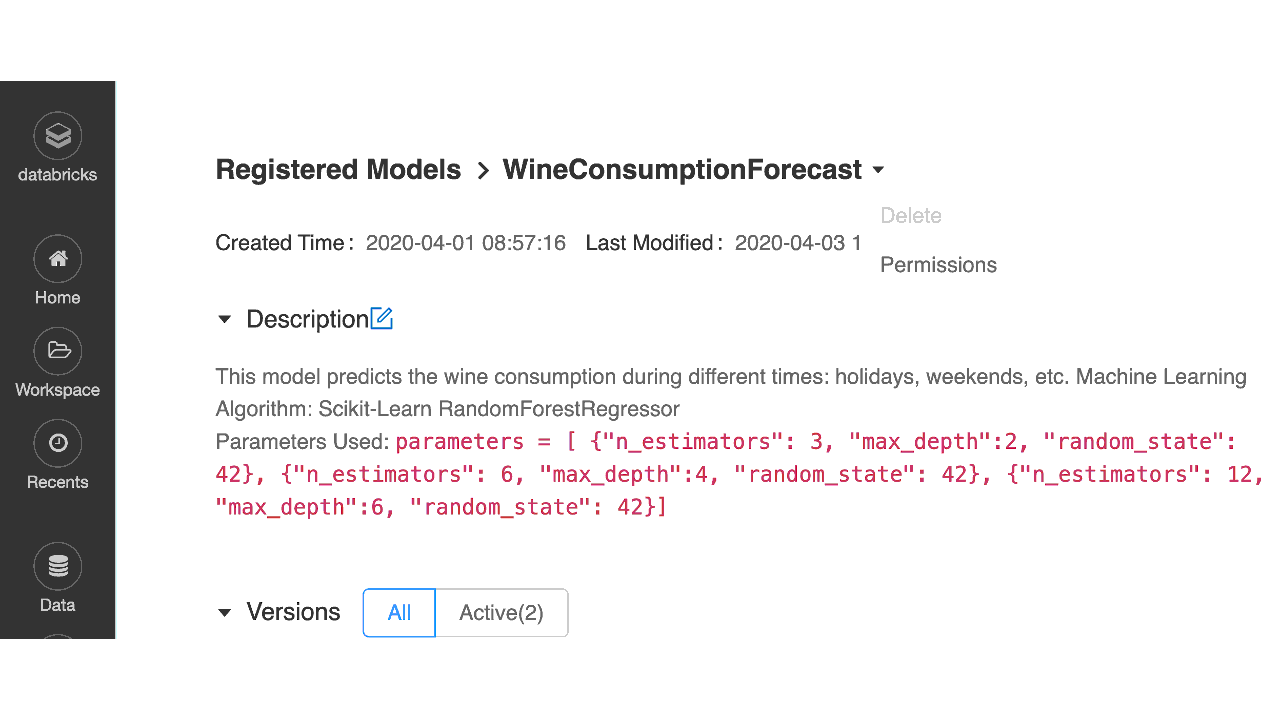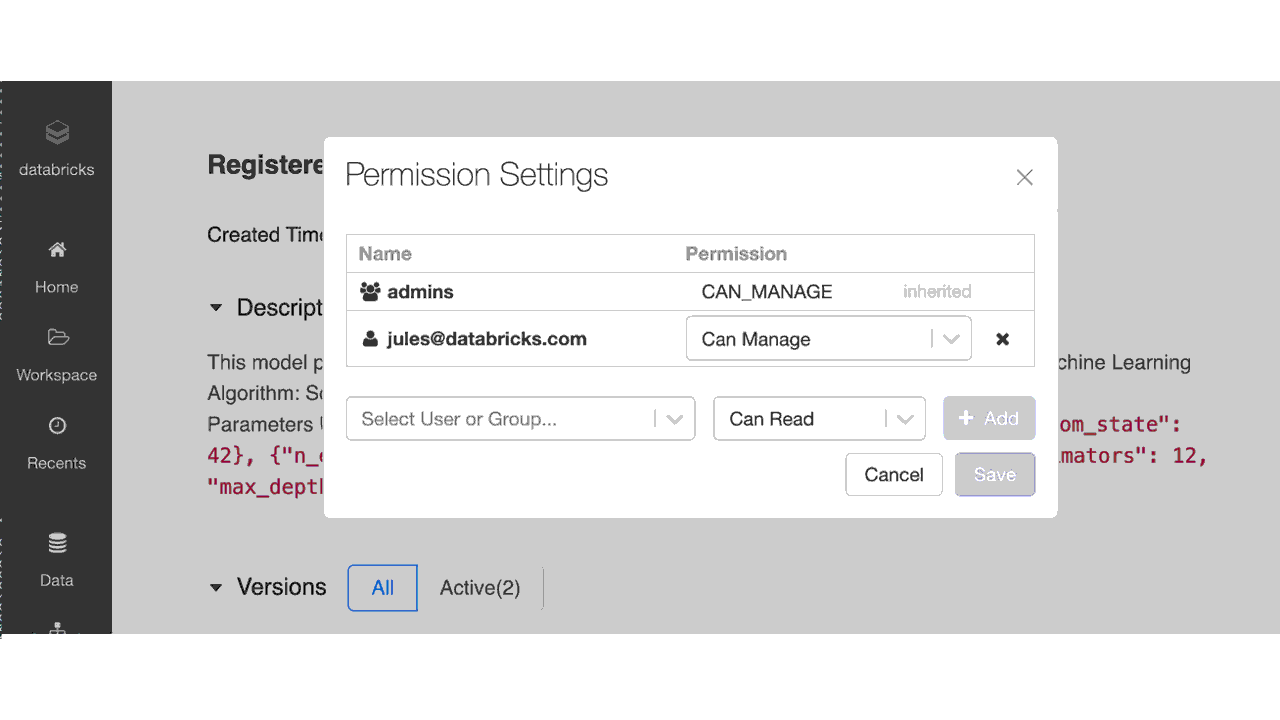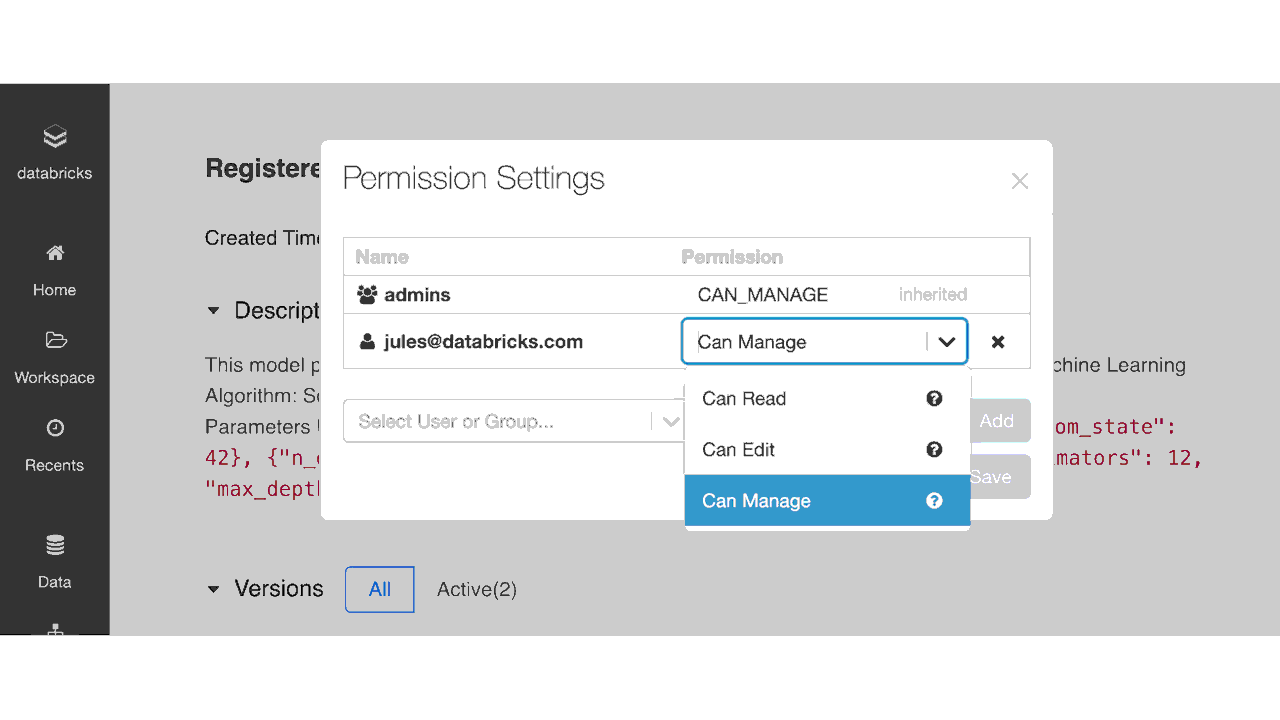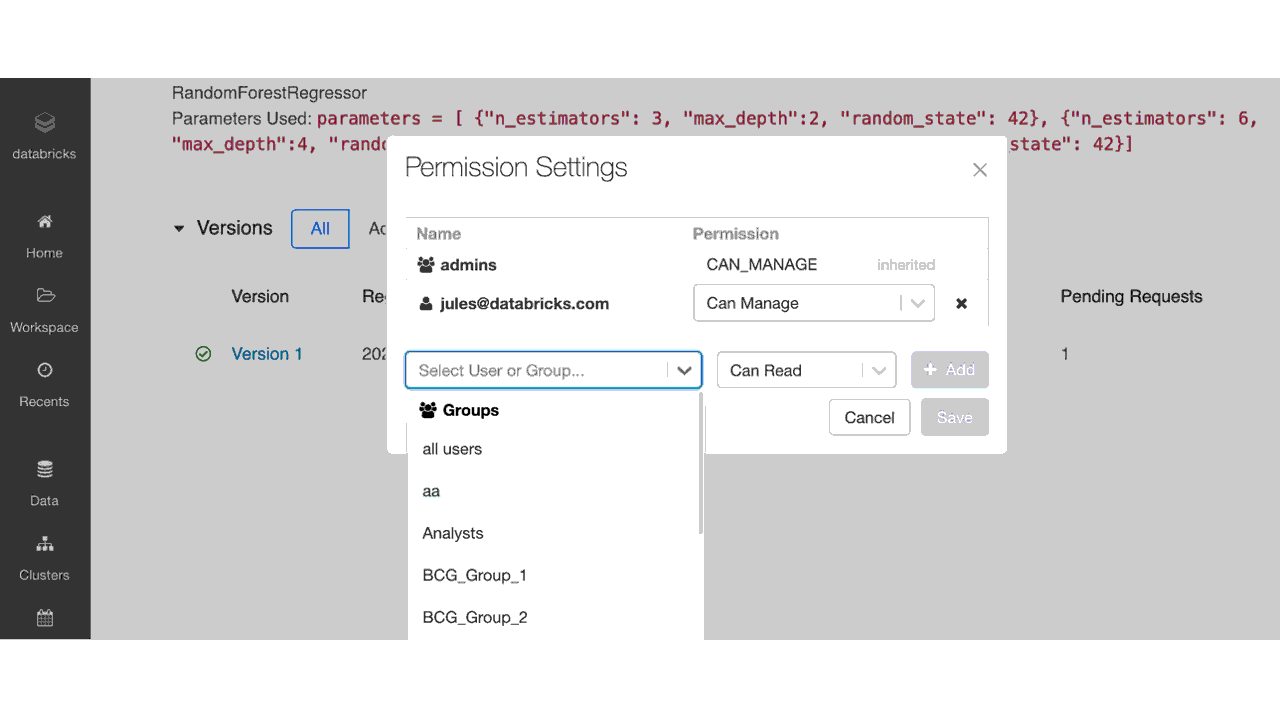
図4:モデルレジストリ UI での ACL を使ったアクセス権の設定
以下の表に示すように、管理者は MLflow モデルレジストリに登録されたモデルに、アクセス権なし、読み取り、編集、管理の 4 つのアクセス権�レベルを割り当てることができます。チームメンバーがモデルにアクセスするための要件に応じて、以下に示す操作ごとに、個々のユーザーまたはグループにアクセス権を付与できます。
| 許可される操作(X) | アクセス権なし | 読み取り | 編集 | 管理 |
| モデルの作成 | X | X | X | X |
| モデルとモデルバージョンのリスト表示 | X | X | X | |
| モデルの詳細、バージョンとその詳細、ステージ遷移リクエスト、アクティビティ、アーティファクトのダウンロード URI の表示 | X | X | X | |
| モデルバージョンのステージ遷移リクエスト | X | X | X | |
| モデルへの新たなバージョンの追加 | X | X | ||
| モデル、バージョンの説明の更新 | X | X | ||
| モデル名の変更 | X | |||
| ステージ間でのモデルバージョンの遷移 | X | |||
| モデルバージョンのステージ遷移リクエストの承認、拒否、またはキャンセル | X | |||
| アクセス権の変更 | X | |||
| モデル、モデルバージョンの削除 | X |
表:モデルレジストリのアクセス権のレベルと許可される操作
モダンアナリティクスへのコンパクトガイド

MLflow モデルレジストリの使用方法
MLflow を使用するデータサイエンティストは、多くの実験を実施して、実験ごとに複数のランでメトリクスやパラメータをトラッキングして記録するのが一般的です。このような開発サイクルの中で、実験の中から最適なランを選択し、そのモデルをレジストリに登録します。その後、レジストリを使用することで、ステージング、プロダクション、アーカイブ のライフサイクルステージに各バージョンを割り当て、複数バージョンのモデルの進行過程をトラッキングできるようになります。
MLflow モデルレジストリの操作には 2 つの方法があります(AWS、Azure)。Databricks ワークスペースに統合されたモデルレジストリ UI を使用する方法と、MLflow トラッキングクライアント API を使用する方法です。API の使用では、MLOps エンジニアが登録されたモデルにアクセスして、モデルのランやメタデータの検証のために CI/CD ツールと統合できます。
モデルレジストリ UI のワークフロー
モデルレジストリ UI には、Databricks のワークスペースからアクセスできます。モデルレジストリ UI からは、ワークフローの一環として以下のアクティビティを行うことができます。
- ランのページからモデルを登録
- モデルバージョンの説明の編集
- モデルバージョンの遷移
- モデルバージョンのアクティビティとア�ノテーションの表示
- 登録されたモデルの表示と検索
- モデルバージョンの削除
モデルレジストリ API のワークフロー
MLflow Model Registry を操作するもう 1 つの方法として、MLflow モデルフレーバー、または MLflow クライアントトラッキング API のインターフェースを使用する方法があります。API を使用して、上に示した UI のワークフローと同様の操作を、登録されたモデルに対して行うことができます。これらの API は、毎晩テストを実施するためにモデルへのアクセスを必要とする外部ツールの検証や統合に活用できます。
モデルレジストリからのモデルのロード
モデルレジストリ API により、Jenkins などの継続的インテグレーション/デプロイメント(CI/CD)ツールと統合したテストを行うことができます。例えば、ユニットテストの際に上述の適切なアクセス権を付与すれば、テスト用のモデルバージョンをロードできます。
以下のコードスニペットでは、同じモデルの 2 つのバージョン(ステージングではバージョン 3、プロダクションでは最新バージョン)をロードしています。
これで、テストの際に、Jenkins ジョブがステージングになっているバージョン 3 のモデルにアクセスできるようになりました。最新のプロダクションバージョンをロードしたい場合は、model:/URI を変更するだけ�でプロダクションモデルを取得できます。
Apache Spark ジョブとの統合
デプロイメント(CI/CD)ツールとの統合だけでなく、レジストリからモデルをロードし、Spark のバッチジョブで使用することもできます。登録されたモデルを Spark UDF としてロードするのが一般的なシナリオです。
登録されたモデル情報の調査、リスト化、検索
モデルに関する MLflow エンティティ情報を確認するために、プログラミングインターフェースを介して登録されたモデルの情報を調査したいこともあるでしょう。例えば、レジストリに登録されている全モデルのリストを簡単なメソッドで取得し、バージョン情報でイテレーションすることもできます。
出力は以下のようになります。
モデルが多数ある場合、この呼び出しで返された結果の精査や出力には手間がかかる可能性があります。より効率的な方法としては、search_model_versions() メソッドで "name='sk-learn-random-forest-reg-model'" のようなフィルタ文字列を指定し、特定のモデル名で検索してバージョンの詳細をリスト化する方法があります。
MLfow モデルレジストリは、Databricks の全てのお客様がデフォルトで利用可能です。ML モデルの集中管理ハブとして、大規模組織のデータチームに、モデルのコラボレーションと共有、遷移の管理、リネージのアノテーションと調査の機能を提供します。制御された状態でコラボレーションを行うために、モデルの管理者が ACL でポリシーを設定し、登録されたモデルにアクセスするための権限を付与します。
また、モデルのライフサイクルのワークフローの一部として、Databricks ワークスペースの MLflow UI または MLflow API を使用してレジストリを操作することも可能です。
MLflow モデルレジストリを使ってみる
モデルレジストリを使ってみませんか?MLflow モデルレジストリの利用にあたっては、各環境での利用についての資料(AWS、Azure)を参照してください。サンプルノートブック(AWS、Azure)もお試しいただけます。
MLflow を初めてご利用になる場合は、最新の MLflow 1.7 を使ったオープンソースの MLflow クイックスタートをご覧ください。また、 Databricks のマネージド MLflow では実運用のユースケースを紹介しています。MLflow モデルレジストリの使用開始にお役立てください。
また、Databricks 上で MLflow を使用し、完全な機械学習ライフサイクル管理のための最新の開発やベストプラクティスを解説したインタラクティブな MLOps バーチャルイベントをオンデマンドで視聴いただけます。