レイクハウスによるデータレイク・データウェアハウスの統合

このブログは、CIDR レポート「Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics」(レイクハウス:データウェアハウスと高度な分析を統合する新世代のオープンプラットフォーム)の著者の許可を得て、レポートの内容をベースに執筆したブログシリーズの第一弾です。
データアナリスト、データサイエンティスト、AI のスペシャリストたちは、高品質で信頼性の高い、最新のデータが不足していることにストレスを感じています。ストレスの一部は、フォーチュン 500 企業の大半で現在使用されている 2 層データアーキテクチャ(データレイクとデータウェアハウス)の弱点に起因しています。一方で、データの信頼性とリアルタイム性を両立する DWH (データウェアハウス)である「オープンレイクハウスアーキテクチャ」とその基盤となる技術は、データチームの生産性を著しく向上させます。したがって、オープンレイクハウスアーキテクチャの採用は、企業の効率性向上につながります。
2 層データアーキテクチャ(データレイク + データウェアハウス)の課題
この一般的なアーキテクチャでは、オペレーショナルデータベースから抽出した組織全体のデータを未加工のままデータレイクにロードします。このデータはすぐに使用できず信頼性が乏しいため、このような状態は、データ(魚)を見つけにくいスワンプ(沼)になる様子になぞらえて「データスワンプ(data swamp)」と呼ばれます。次に、別の ETL(抽出、変換、ロード)処理をスケジュールに沿って実行し、重要なデータのサブセットをデータウェアハウス(DWH)に移動させ、ビジネスインテリジェンス(BI)および意思決定�に活用します。
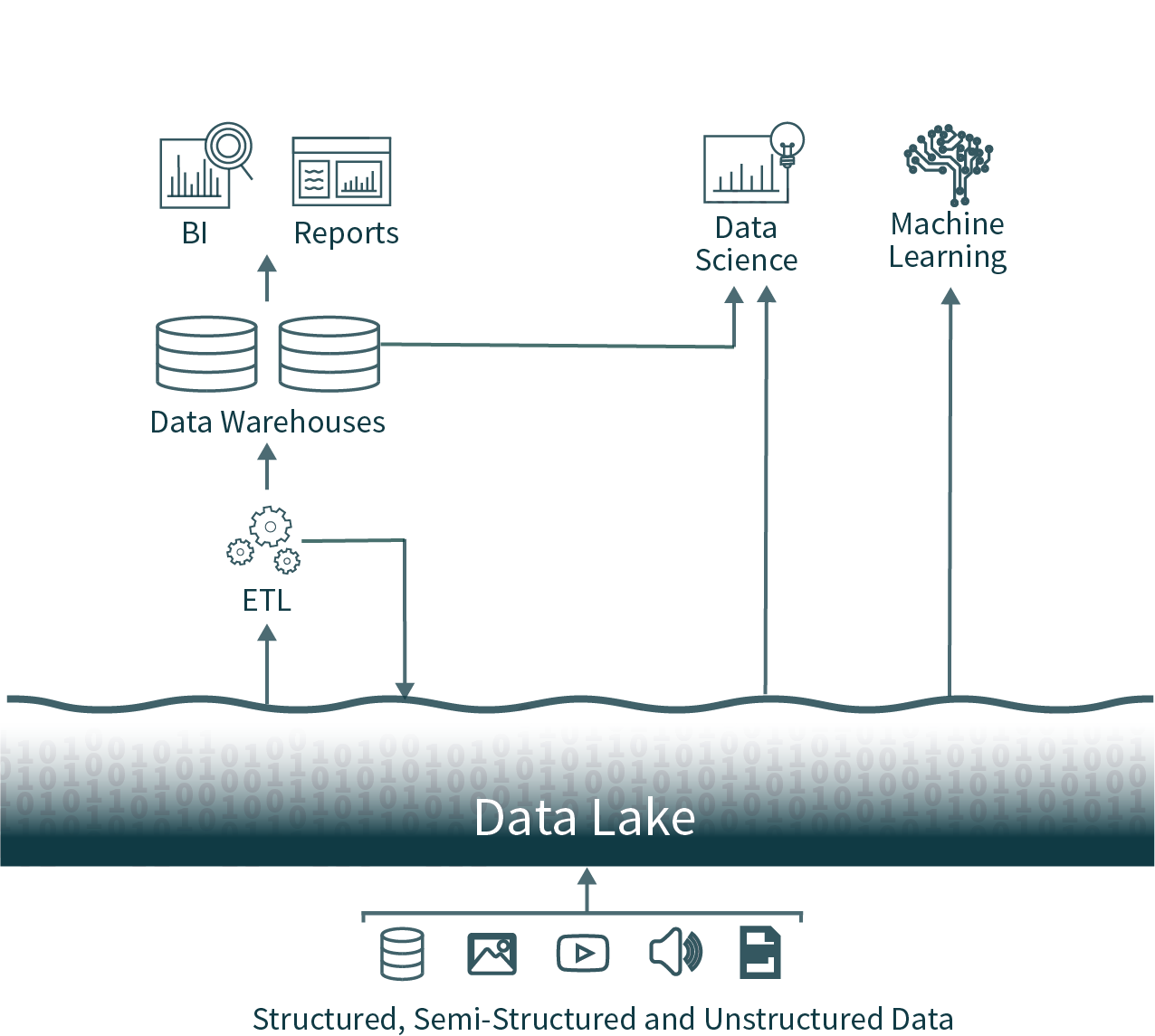
このようなアーキテクチャのもと、データアナリストは、タイムリーではあるが品質の低いデータレイクのデータ、あるいは、高品質ではあるがタイムリーでないデータウェアハウスのデータという、難しい二択を迫られます。また、一般的なデータウェアハウスソリューションはクローズドフォーマットであるため、高品質なデータソースの分析が可能なオープンソースのデータ分析フレームワークを利用しようとすると、新たな ETL 処理の実行が必要になり、ここでもデータのリアルタイム性が失われることになります。
We can do better: Introducing the Data Lakehouse
2 層データアーキテクチャは現在多くのエンタープライズに採用されていますが、ホスト環境がオンプレミスかクラウドかに関わらず ETL 処理などを含む運用管理が複雑で、データエンジニアおよびユーザーにとって扱いが困難だという問題があります。
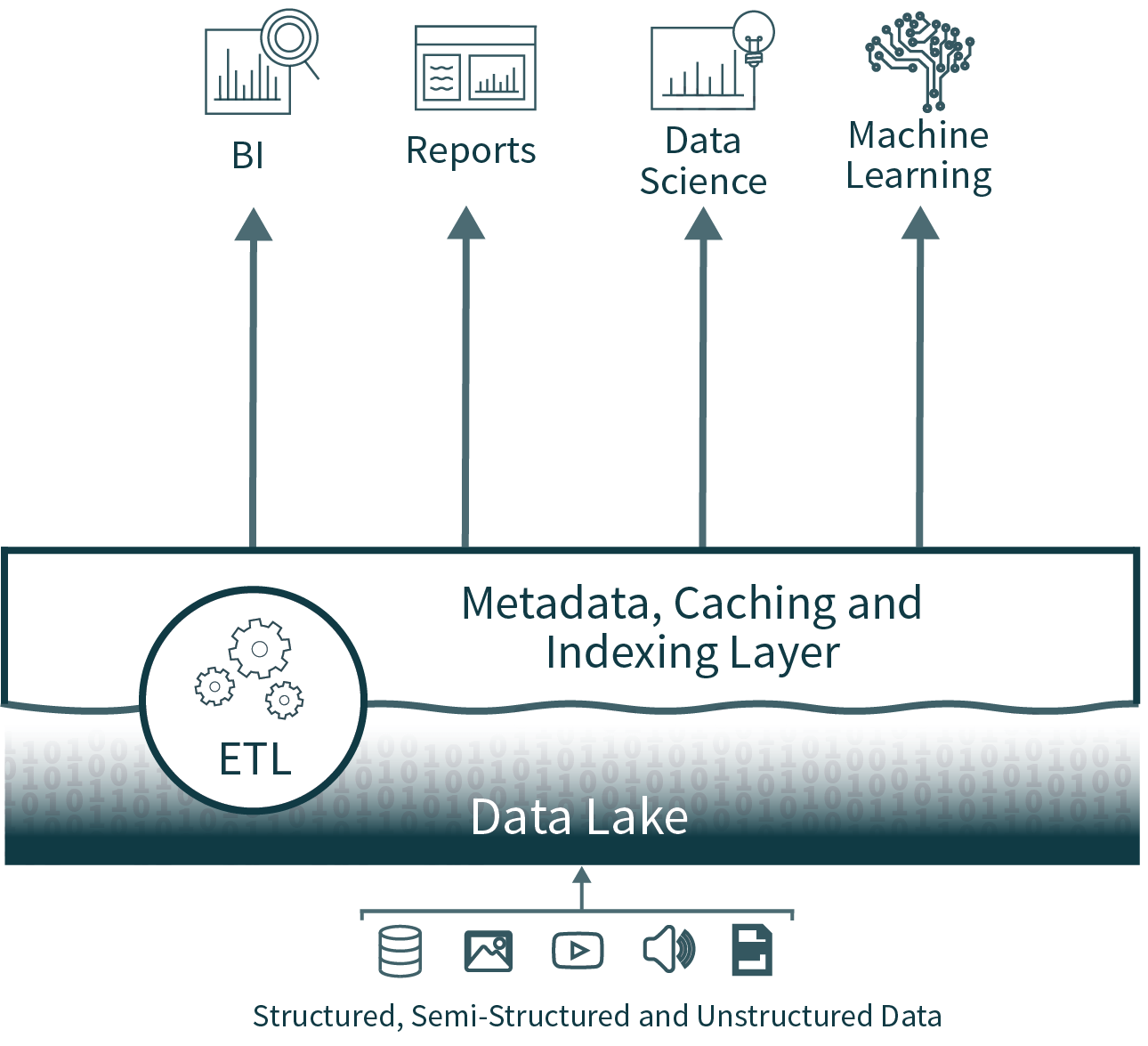
レイクハウスアーキテクチャは、データウェアハウス層の持つデータの信頼性や性能といった主要なメリットをデータレイクにもたらすことで、複雑さ、コスト、運用管理のオーバーヘッドを削減し、最終的にはウェアハウス層を不要にします。
データの信頼性
複数のデータコピーを同期させる際に、データの一貫性を維持するのは容易ではありません。このアーキテクチャは複数の ETL プロセスを必要とします。オペレーショナルデータベースからデータレイクにデータを移動し、さらにデータレイクからデータウェアハウスにそのデータを移動します。プロセスが追加されるたびに、複雑さ、遅延、不具合のリスクが増大します。
データレイクハウスのアーキテクチャでは、第2層を排除することで、ETL 処理の一部を取り除きます。さらに、スキーマの適用と展開のサポートをデータレイク上に直接追加し、タイムトラベル機能などのサポートにより、データのクリーンさの履歴検証も有効にします。
データのリアルタイム性
データウェアハウスのデータは、データレイクから移入するため、データのリアルタイム性が失われています。Fivetran 社による最近の調査では、このことが原因で 86% のアナリストが古いデータを使用せざるを得ない状況にあるとされています。

レイクハウスでは、データウェアハウス層を排除することで、この問題を解決します。また、リアルタイムストリーミングとバッチ処理のマージを高効率、高信頼性をもって実施できるため、アナリストは常に最新のデータを分析に活用できます。
高度な分析のサポート
機械学習や予測分析などの高度な分析では、多くの場合、大規模なデータセットを処理する必要があります。TensorFlow、PyTorch、XGBoostなどの一般的なツールを使うと、オープンデータ形式でデータレイクにある未加工データの読み込みは容易になりますが、これらのツールは、データウェアハウスで使用されるETLデータで使用される独自のデータ形式のほとんどを読み込めません。そのため、データウェアハウスベンダーは、このデータをファイルにエクスポートして処理することを推奨しています。しかし、これではETLの3番目のステップを追加することになり、複雑さと古いデータを増大させる結果となります。
一方、オープンレイクハウスアーキテクチャでは、これらのツールセットを使用することで、データレイクに保存されている高品質でタイムリーなデータを直接操作できます。
総所有コスト(TCO)
データレイクとデータウェアハウスを使用する 2 層アーキテクチャでは、データ分析の際に、エンタープライズデータの大部分が、オペレーショナルデータベース、データレイク、データウェアハウスの 3 か所にオンラインコピーとして保存されます。クラウドのストレージコストは低下しているとはいえ、3 つのコピー分のストレージコストが発生することになります。
また、データを同期させるためにも多大なエンジニアリングコストを要するため、TCO はさらに増大します。
データレイクハウスアーキテクチャでは、最もコストのかかるデータコピーのプロセス1つと、それに関連する同期プロセスが不要になります。
ETL を実行する

BI のための性能
ビジネスインテリジェンス(BI)と意思決定を支援するには、探索的データ分析(EDA)クエリやダッシュボード、データの視覚化、その他の重要なシステムのためのクエリを高性能で実行する必要があります。これまで企業がデータレイクに加えてデータウェアハウスを利用していたのは、データレイクの性能に懸念があることが理由でした。しかし、最近ではデータレイク上のクエリを最適化する技術が大幅に改善され、性能に対する懸念事項がほとんど解消されています。
レイクハウスは、インデックス、ローカリティコントロール、クエリの最適化、ホットデータキャッシュを��サポートし、性能を向上させます。これにより、データレイクSQLの性能は、TPC-DSにおける主要なクラウドデータウェアハウスの性能を上回り、さらにデータウェアハウスに求められる柔軟性とガバナンスの提供を実現しています。
結論と次のステップ
先進的な企業や技術者集団は、現在使用されているデータレイクとデータウェアハウスの 2 層データアーキテクチャに関して、「もっとよい方法で置き換えられるべきである」という意見を持っています。その方法を私たちは「オープンデータレイクハウス」と呼んでいます。オープンデータレイクハウスは、データレイクのオープン性や柔軟性と、従来のデータウェアハウスの信頼性、性能、低レイテンシ、高並行性を兼ね備えたアーキテクチャです。
データレイクの性能の改善については、シリーズの次回の記事で詳しく解説します。
今すぐ詳細を知りたいという方には、CIDR レポートをダウンロードしていただくか、あるいは、最新のレイクハウスの基盤技術を解説した動画をご覧いただくことをお薦めします。