DatabricksのサーバーレスコンピュートでVM起動を7倍高速化

公開日: 2024年11月26日
によって Xinyang Ge、Shuo Chen、Shuai Chang、Simha Venkataramaiah、Anders Liu 、 Rohit Jnagal による投稿
Summary
- Databricksはサーバーレスコンピュートインフラを使用して、3つの大きなクラウドプロバイダー上で毎日数百万台の仮想マシン(VM)を起動および管理しています。
- VMの起動時間を短縮するために、Databricksはシステムレベルの最適化を開発しました。
- 最適化には、専用のサーバーレスOS、遅延コンテナファイルシステム、事前初期化済みコンテナのチェックポイント作成/復元が含まれます。
Databricksのサーバーレスコンピュートインフラは、3大クラウドプロバイダー上で毎日数百万台の仮想マシン(VM)を起動・管理しています��。この規模で効率的にインフラを運用することは、大きな課題です。本日は、真のサーバーレス体験を実現するための最近の取り組みをご紹介します。これにより、コンピュートリソースだけでなく、Apache SparkクラスタやLLMの提供など、あらゆるデータとAIのワークロードを大規模に処理するための基盤システムが数秒で準備完了します。
私たちの知る限り、これほど多様なデータおよびAIワークロードを大規模に数秒以内で実行できるサーバーレスプラットフォームは他にありません。最大の課題は、VM環境を最適なパフォーマンスでセットアップするための時間とコストにあります。このセットアップには、さまざまなソフトウェアパッケージのインストールだけでなく、実行環境の十分なウォームアップも必要です。たとえば、Databricks Runtime(DBR)では、JVMのJITコンパイラをウォームアップすることで、開始直後から最高のパフォーマンスを提供する必要があります。
このブログでは、DatabricksソフトウェアをプリロードしたVM(Databricks VM)の起動時間を数分から数秒に短縮するために開発したシステムレベルの最適化について説明します。これは、サーバーレスプラットフォームのリリース以来、7倍の改善を達成したものであり、現在ではほぼすべてのDatabricks製品を支えています。これらの最適化は、OSやコンテナランタイムからホストされたアプリケーションに至るまで、ソフトウェアスタック全体にわたり、毎日数千万分の計算時間を節約し、Databricksサーバーレスのお客様に最高の価格パフォーマンスを提供しています。
Databricks VMの起動
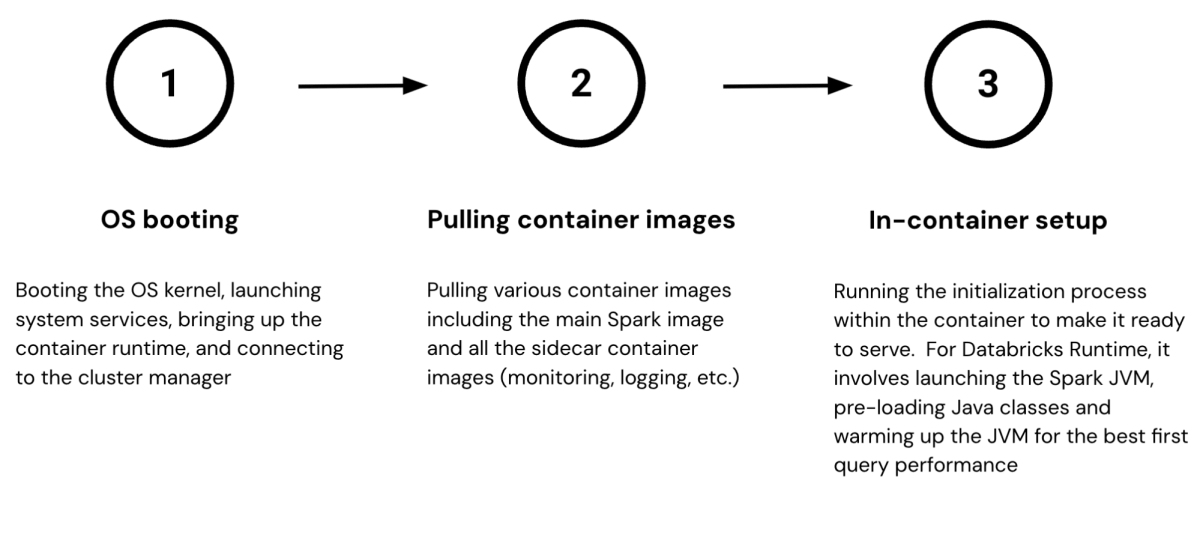
図1で示される3つの主要な起動ステージについて、それぞれが時間を要する理由を以下に簡単に説明します:
1. OSの起動
Databricks VMは、一般的なOSの起動シーケンスからスタートします。これには、カーネルの起動、システムサービスの開始、コンテナランタイムの起動が含まれ、最終的にはVMフリート全体を管理するクラスタマネージャーへの接続が行われます。
2. コンテナイメージの取得
Databricksでは、アプリケーションをコンテナイメージとしてパッケージ化しています。これにより、実行時リソースの管理が簡素化され、デプロイが効率化されます。VMがクラスタマネージャーに接続すると、コンテナ仕様のリストを受け取り、コンテナレジストリから数ギガバイトにおよぶイメージをダウンロードします。これらのイメージには、最新のDatabricks Runtimeだけでなく、ログ処理、VMのヘルスモニタリング、メトリック収集などのユーティリティアプリケーションも含まれています。
3. コンテナ内のセットアップ
最後に、VMはワークロードコンテナを起動し、環境を初期化して稼働可能な状態にします。たとえば、Databricks Runtimeの場合、その初期化プロセスには数千ものJavaライブラリの読み込みや、JVMをウォームアップするための一連の厳選されたクエリの実行が含まれます。これらのウォームアップクエリを実行することで、JVMが一般的なコードパスのバイトコードをネイティブマシン命令にジャストインタイム(JIT)コンパイルし、最初のクエリから最高の実行パフォーマンスを提供します。多くのウォームアップクエリを実行することで、すべての種類のクエリやデータ処理ニーズに対して低レイテンシの体験を保証します。しかし、クエリの数が多いほど、初期化プロセスに数分を要する場合があります。
これらの各ステージで、以下の最適化を開発することでレイテンシを改善しました。
専用のサーバーレスOS
Databricks Serverlessでは、ソフトウェアスタック全体を管理しているため、一時的なVMを実行するために特化したServerless OSを構築できます。基本方針は、Serverless OSを軽量化することです。具体的には、コンテナを実行するために必要不可欠なソフトウェアのみを含め、汎用OSよりも重要なサービスを早く起動するようにブートシーケンスを調整しています。また、ブート時のディスクボトルネックを軽減するため、バッファ付きI/O書き込みを優先するようOSをチューニングしています。
不要なOSコンポーネントを削除することで、初期化が必要な要素を最小化し(例: クラウドVMには不要なUSBサブシステムを無効化)、ブートプロセスをクラウド環境向けに最適化できます。VMでは、OSはリモートディスクから起動され、ブート中にディスク内容が物理ホストに取得されます。クラウドプロバイダーは、アクセスが予測されるブロックセクタに基づいてディスク内容をキャッシュすることでこのプロセスを最適化します。OSイメージを小さくすることで、クラウドプロバイダーがディスク内容をより効果的にキャッシュできるようになります。
さらに、Serverless OSをカスタマイズして、ブートプロセス中のI/O競合を減らしています。ブート中には大量のファイル書き込みが発生するため、システム設定を調整して、カーネルがディスクにデータをフラッシュする前に、より多くのファイル書き込みをメモリにバッファリングできるようにしています。また、イメージの取得やコンテナ作成時に発生する同期的なブロッキング書き込みを減らすようにコンテナランタイムを変更しています。これらの最適化は、電源障害やシステムクラッシュによるデータ損失をほとんど考慮する必要がない短命で一時的なVM向けに設計されています。
Databricks アプリのハンズオンガイド

遅延コン��テナファイルシステム
Databricks VMがクラスタマネージャに接続した後、Databricks Runtimeやログ処理、メトリクス発行などのユーティリティアプリケーションを初期化する前に、数ギガバイトのコンテナイメージをダウンロードする必要があります。ダウンロードプロセスは、ネットワーク帯域幅やディスクスループットをフルに利用しても、完了するまでに数分かかることがあります。一方、以前の研究では、コンテナの起動時間の76%がコンテナイメージのダウンロードに費やされている一方で、初期の有用な作業を開始するために必要なデータは6.4%しかないことが示されています。
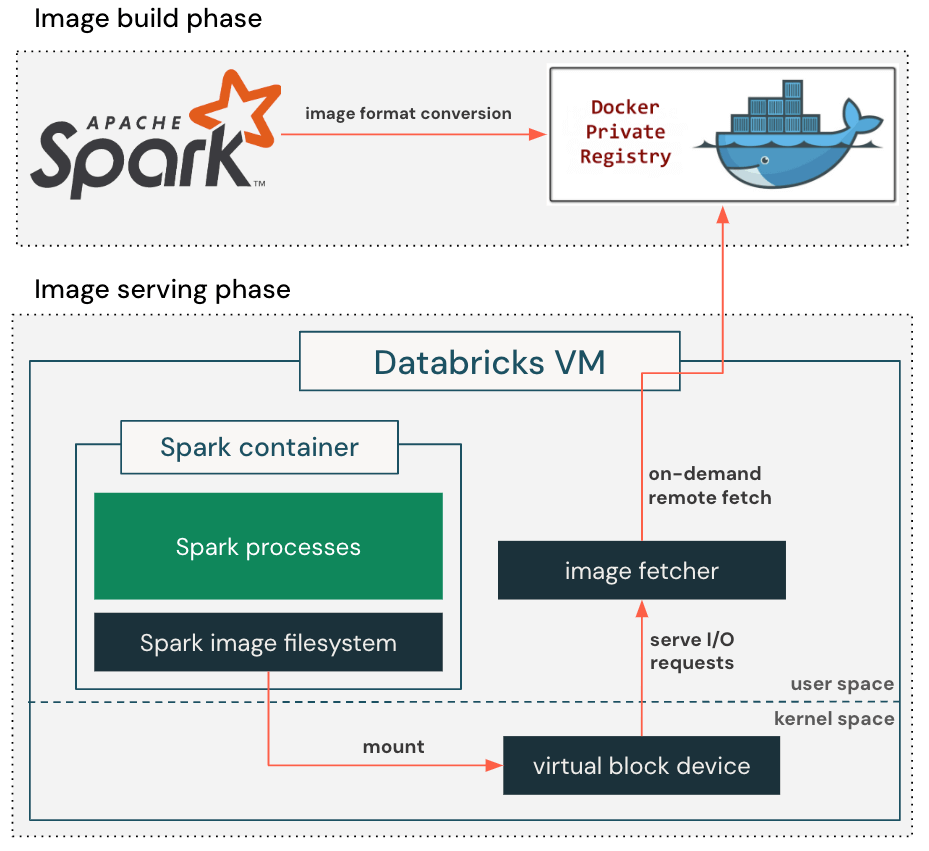
この観察結果を活用するため、図2に示すように遅延ロード対応のコンテナファイルシステムを導入しています。コンテナイメージを構築する際、標準的なgzipベースのイメージ形式をブロックデバイスベースの形式に変換する追加のステップを加えます。この形式は遅延ロードに適しており、本番環境では4MBセクター単位でシーク可能なブロックデバイスとしてコンテナイメージを表現できます。
コンテナイメージを取得する際、カスタマイズされたコンテナランタイムは、ルートディレクトリのセットアップに必要なメタデータ(ディレクトリ構造、ファイル名、権限など)だけを取得し、仮想ブロックデバイスを作成します。その後、この仮想ブロックデバイスをコンテナにマウントし、アプリケーションを即座に実行可能にします。アプリケーションがファイルを初めて読み取ると、仮想ブロックデバイスへのI/O要求がイメージ取得プロセスにコールバックを発行し、リモートのコンテナレジストリから実際のブロックコンテンツを取得します。取得したブロックコンテンツはローカルにキャッシュされ、コンテナレジストリへのネットワーク往復を繰り返す必要がなくなり、将来の読み取り時に可変的なネットワーク遅延の影響を軽減します。
この遅延ロード対応のコンテナファイルシステムにより、アプリケーションを開始する前にコンテナイメージ全体をダウンロードする必要がなくなります。これにより、イメージ取得の遅延が数分から数秒に短縮されます。また、イメージのダウンロードをより長い時間に分散することで、Blobストレージの帯域幅への負担を軽減し、スロットリング(帯域制限)を回避します。
事前初期化済みコンテナのチェックポイント作成/復元
最終ステップでは、VMを稼働可能とする前に、コンテナ内で長い初期化シーケンスを実行してコンテナをセットアップします。Databricks Runtimeの場合、必要なすべてのJavaクラスを事前にロードし、Spark JVMプロセスをウォームアップするための大�規模な手順を実行します。このアプローチは、ユーザーの初期クエリに対して最高のパフォーマンスを提供しますが、起動時間を大幅に増加させます。さらに、このセットアッププロセスは、Databricksが起動するすべてのVMで繰り返し実行されます。
この高コストな起動プロセスを解決するために、完全にウォームアップされた状態をキャッシュする方法を採用しました。具体的には、事前に初期化されたコンテナのプロセスツリーのチェックポイントを取得し、それをテンプレートとして同じワークロードタイプの将来のインスタンスを起動します。この設定では、コンテナは一貫した初期化済み状態に直接「復元」されるため、繰り返される高コストなセットアッププロセスを完全に回避できます。
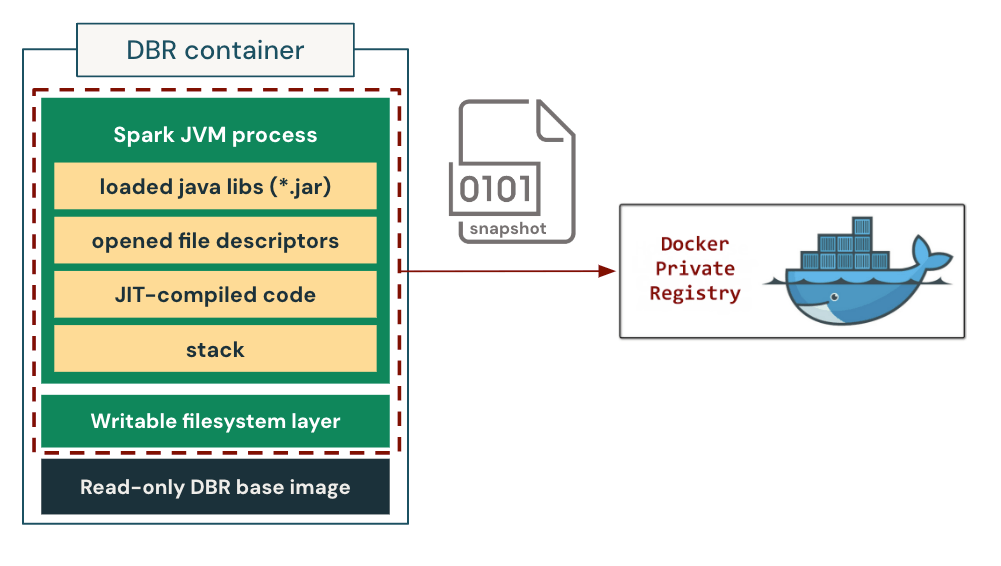
私たちは、チェックポイント/復元機能をカスタマイズしたコンテナランタイムに実装し、統合しています。その仕組みを図3に示しています。
チェックポイント作成中、コンテナランタイムはまずコンテナのプロセスツリー全体をフリーズして、状態の一貫性を確保します。その後、以下を含むプロセス状態をディスクにダンプします:
- ロード済みのライブラリ
- 開いているファイルディスクリプタ
- 全ヒープ状態(JITコンパイルされたネイティブコードを含む)
- スタックメモリ
さらに、コンテナの初期化プロセス中に作成/変更されたファイルを保持するため、コンテナファイルシステムの書き込み可能なレイヤーも保存します。これにより、後にメモリ内プロセス状態とディスク上のファイルシステム状態の両方を復元することが可能になります。チェックポイントはOCI/Docker互換イメージにパッケージ化され、標準的なコンテナイメージとしてコンテナレジストリを利用して保存および配布されます。
このアプローチは概念的にはシンプルですが、いくつかの課題があります:
-
Databricks Runtimeのチェックポイント/復元互換性
初期状態ではDatabricks Runtimeは互換性がありませんでした。その理由は以下の通りです:- Databricks Runtimeは、ホスト名やIPアドレス、ポッド名などの特定情報にアクセスする場合がありますが、チェックポイントは複数の異なるVMで復元される可能性があります。
- チェックポイントが作成された時点と復元時の間に数日または数週間が経過することがあり、その間の時刻の変化に対応できませんでした。
これに対応するため、Databricks Runtimeにチェックポイント/復元互換モードを導入しました。このモードでは、ホスト固有の情報のバインディングを復元後まで遅らせます。また、チェックポイント作成前��と復元後にカスタムロジックを実行できるフックを追加しました。たとえば、Databricks Runtimeはこれらのフックを利用して、ハートビートの一時停止と再開、外部ネットワーク接続の再確立などを管理できます。
-
チェックポイントはDatabricks Runtimeのバージョンだけでは決まらない
チェックポイントはコンテナの最終プロセス状態をキャプチャするため、以下のような要因によって決定されます:- Databricks Runtimeのバージョン
- アプリケーション設定
- ヒープサイズ
- CPUの命令セットアーキテクチャ(ISA)
たとえば、64GBのVMで作成されたチェックポイントを32GBのVMに復元するとメモリ不足(OOM)エラーが発生する可能性があります。また、Intel CPUで作成されたチェックポイントをAMD CPUに復元すると、JVMのJITコンパイラがISAに基づいて最適化したネイティブコードの影響で不正な命令が実行される可能性があります。これに対応するため、すべての可能な組み合わせを網羅するのではなく、本番環境で新しい組み合わせが検出された際にオンデマンドでチェックポイントを作成します。作成されたチェックポイントはコンテナレジストリにアップロードおよび配布され、同じ組み合わせのワークロードで将来再利用されます。このアプローチにより、チェックポイント生成パイプラインの設計が簡素化され、すべてのチェックポイントが実際に本番環境で利用されることが保証されます。
-
一意性の復元
同じチェックポイントから複数のコンテナを起動すると、一意性の保証が失われる可能性があります。た��とえば、乱数生成器(RNG)は同じシードを共有し、復元後に同じ乱数列を出力し始めます。この問題に対応するため、初期化中に作成されたRNGオブジェクトを追跡し、復元後フックを利用してRNGオブジェクトを再シードして一意性を復元します。
我々の評価では、この最適化によりDatabricks Runtimeの初期化とウォームアップ時間が数分から約10秒に短縮されました。この機能により、JVMのウォームアップをより深く実行できるようになり、初期化時間が制約になることを心配する必要がなくなりました。
まとめ
Databricksでは、継続的なイノベーションを通じてお客様に最大限の価値を提供し、最良の価格性能を実現することに取り組んでいます。このブログでは、Databricks VMの起動時間を7倍短縮する一連の深いシステムレベルの最適化について説明しました。これにより、サーバーレスのお客様に大幅に改善されたレイテンシとパフォーマンス体験を提供できるだけでなく、これを可能な限り低価格で実現することができます。また、VMの起動時間短縮を考慮し、ウォームプールのサイズを調整してサーバーレスのコストをさらに削減する予定です(詳細は続報をお待ちください!)。最後に、この最適化を実現するにあたり、大きな恩恵を受けたオープンソースコミュニティに感謝を申し上げます。
ぜひ無料トライアルに参加して、Databricks Serverlessの体験をお試しください!