Community Editionで始めるDatabricks

Community Editionに代わり、Free Editionでは無料でより充実した機能をご利用いただけます。ぜひ今日からぜひFree Editionをお試しください。
Databricksはあらゆるデータ・分析・データサイエンスのワークロードに対応可能なオープンかつシンプルなLakehouseを提供しています。そして、Databricksではその機能を無償でお試しいただけるよう、2通りの方法を用意しております。
- 2週間の無償トライアル: Databricksのフル機能をお試しいただけます。
- Community Edition: 機能が限定されますが、期限なし・無償でご利用いただけます。
このブログでは、後者のCommunity Editionを使用したDatabricksの始め方について説明します。
Community Editionの機能と制限
Community Editionでは、Databricksのフルバージョンの機能に対して以下の制限があります。
- 作成できるクラスターは15GB RAM, 2 Core CPUのシングルノードのみ
- ワークスペースに追加できるユーザー数は最大3名まで
- クラスターのリージョンはus-westのみ
- 使用できない機能
- ジョブのスケジュール機能
- クラスターのオートスケーリング機能
- Git連携
- MLflowの一部モデル管理機能(レジストリ、RESTサービング)
- REST APIによるワークスペースの制御
- セキュリティ、ロールベースのアクセス制御、監査、シングルサインオン
- BIツール連携のサポート
一方で、使用期間の制限はありません。そのため、Databricks機能の使用感の確認や、Databricksのトレーニング教材を実行していただく環境として広くご利用いただけます。例えば、以下の機能・環境がCommunity Edition上で利用することができます。
- Databricks Workspace/Notebook環境(共同編集・コラボレーション機能)
- Spark (Databricks Runtime版)
- Delta Lake (Databricks版)
- MLflow(モデルトラッキング機能)
- Koalas(SparkのPandas API)
- MLlib(Sparkネイティブの機械学習ライブラリ)
- 一般的な機械学習ライブラリ環境(TensorFlow, Keras, Pytorch, Scikit Learn, XGBoostなど)
- 一般的なデータサイエンス環境(Scipy, Numpy, Pandas, Matplotlibなど)
プリインストールされているライブラリ一覧はこちらで確認できます。
Community Editionのアカウント作成
Community Editionのアカウント作成方法を説明いたします。
- データブリックスの無料トライアルにアクセスし、必要事項を記入後、”GET STARTED FOR FREE”をクリックします。
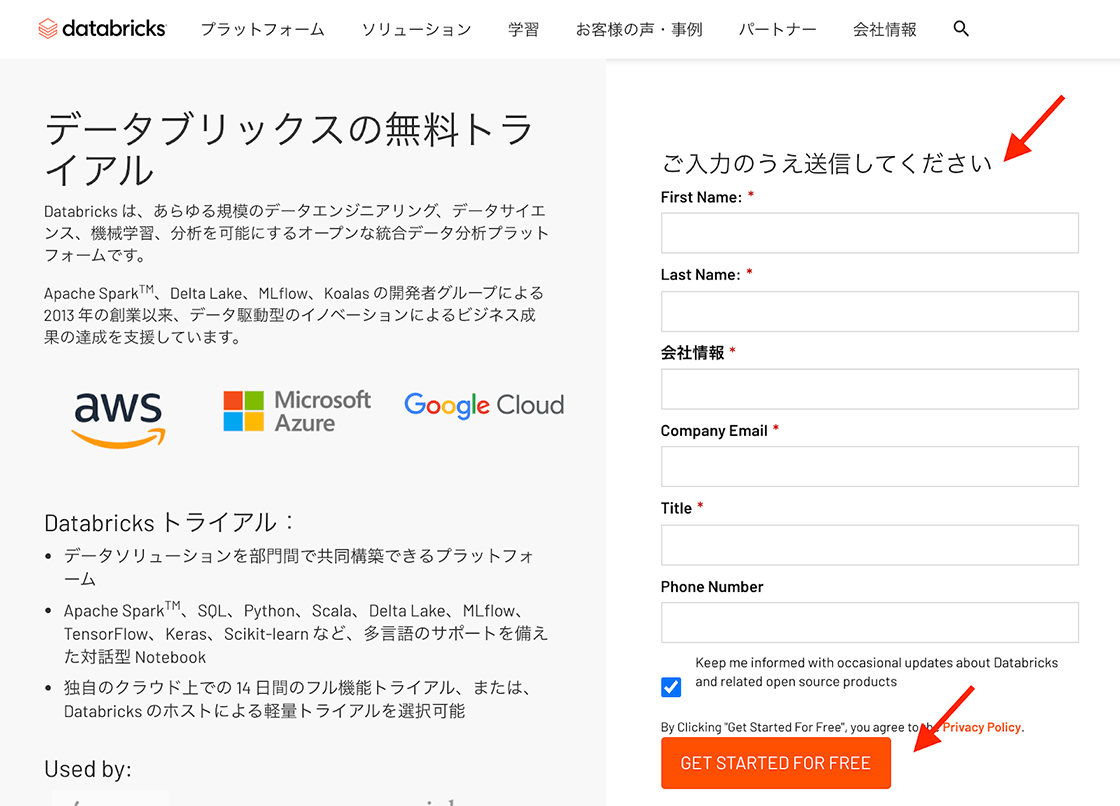
- 続いて、コミュニティ版の”GET STARTED”をクリックします。
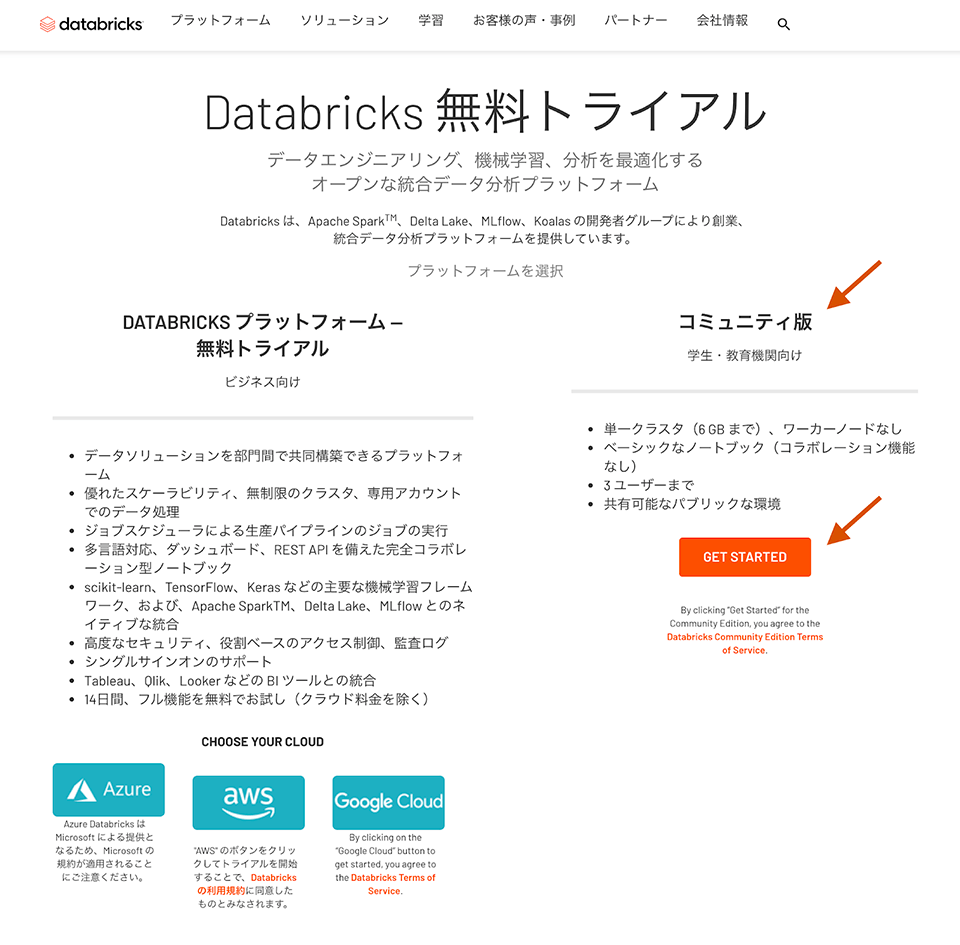
- 登録したメールアドレス宛に初期パスワード設定のリンクが送付されるので、ガイドにしたがって設定します。
- Community Editionのログインページを開き、上記で設定したメールアドレス、パスワードでログインします。
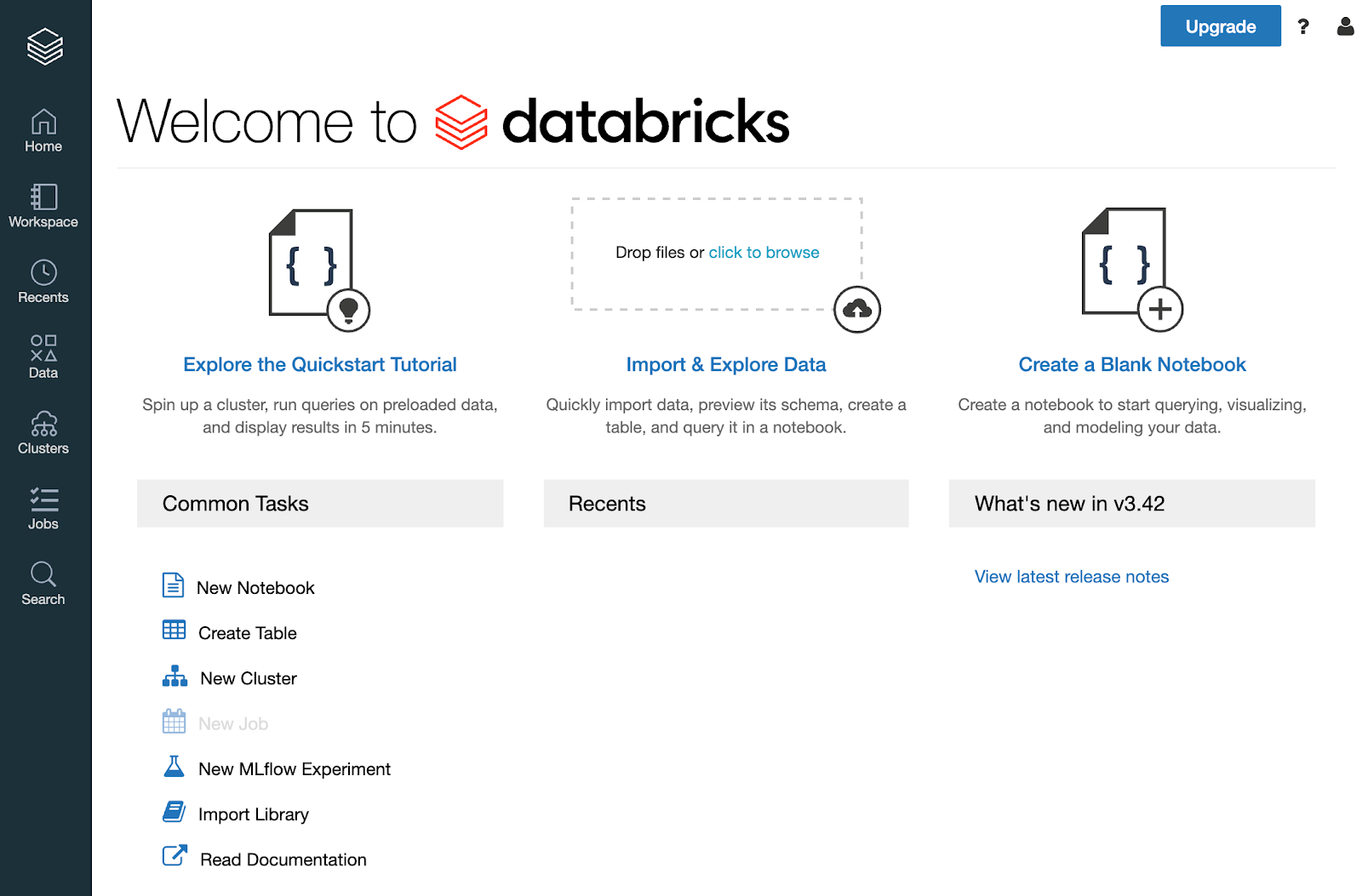
以上で、Community Editionが利用できようになりました。
クラスター起動、Notebookの作成・実行
DatabricksはブラウザベースのUIでクラスター管理、Notebookの実行など、Databricksの機能の大部分が操作可能になっています。ここでは、Databricksの基本的な操作として、クラスターを作成・起動し、それを使用してサンプルのノートブックを実行する方法を見ていきます。
まず、クラスターを作成し、起動します。ログイン後のトップページの左にあるメニューバーから”Clusters”をクリックし、続いて、遷移後のページにある”Create Cluster”ボタンをクリックします。クラスター構成のページが表示されるので、以下の項目を適宜選択、入力します。
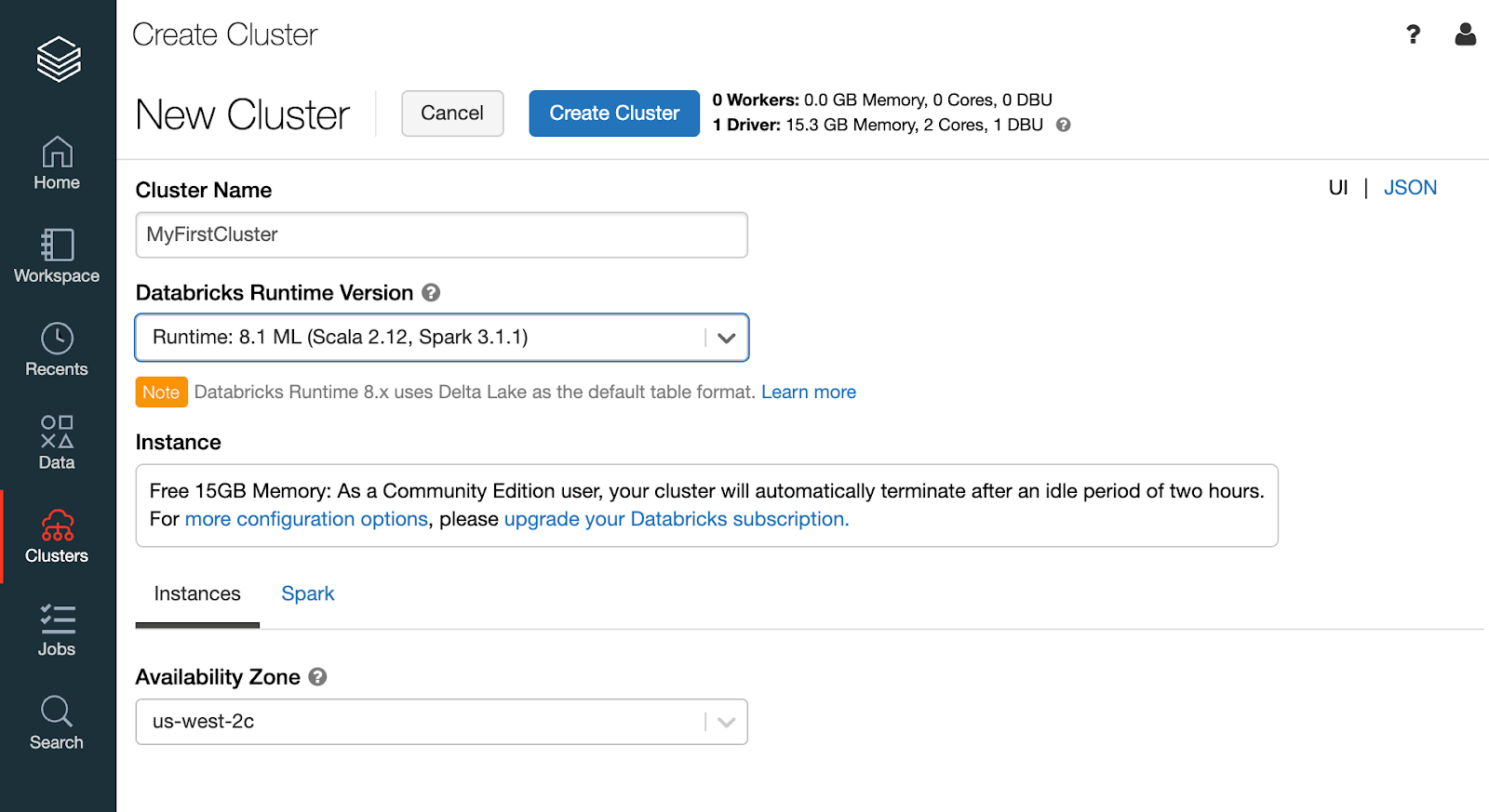
- Cluster Name: 作成するクラスターの名前(任意の文字列)。
- Databricks Runtime Version: Runtime, Spark, Scalaのversion指定。機械学習ライブラリを使用する場合は、”ML”ラベルのあるversionを指定してください。
- Availability Zone: クラスターを配置するリージョン・AZを指定。
最後に、”Create Cluster”をクリックします。これでクラスターの作成が完了しました。クラスターが起動するまで待ちます(数分程度かかる場合があります)。
続いて、サンプルのNotebookを実行してみましょう。画面左上にあるDatabricksのアイコン(ロゴ)をクリックして、トップページに移動します。中央左にある”Explore Quickstart Tutorial ”リンクをクリックすると、サンプルのNotebookが開きます。
Notebook上の左上部で使用するクラスターが選択できます。先ほど作成したクラスターを選択してください。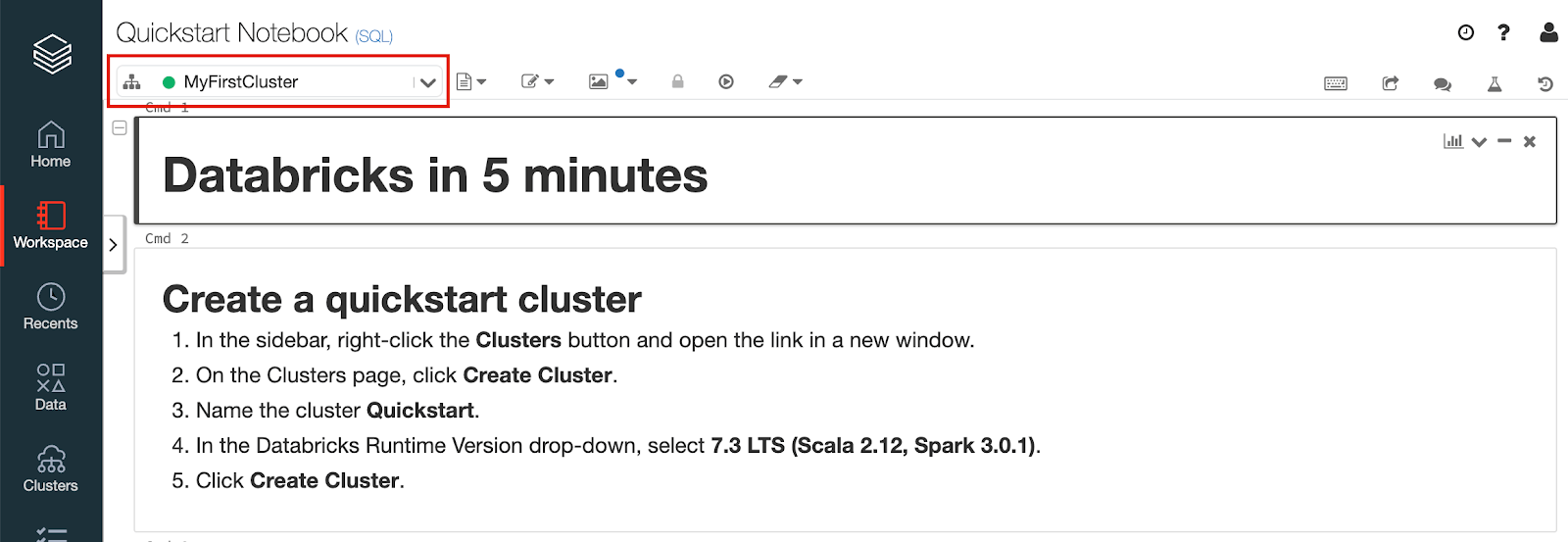
Jupyter Notebookと同様に、セルごとにコードを実行することができます。セルの右上にある実行アイコンから”Run Cell”をクリックします。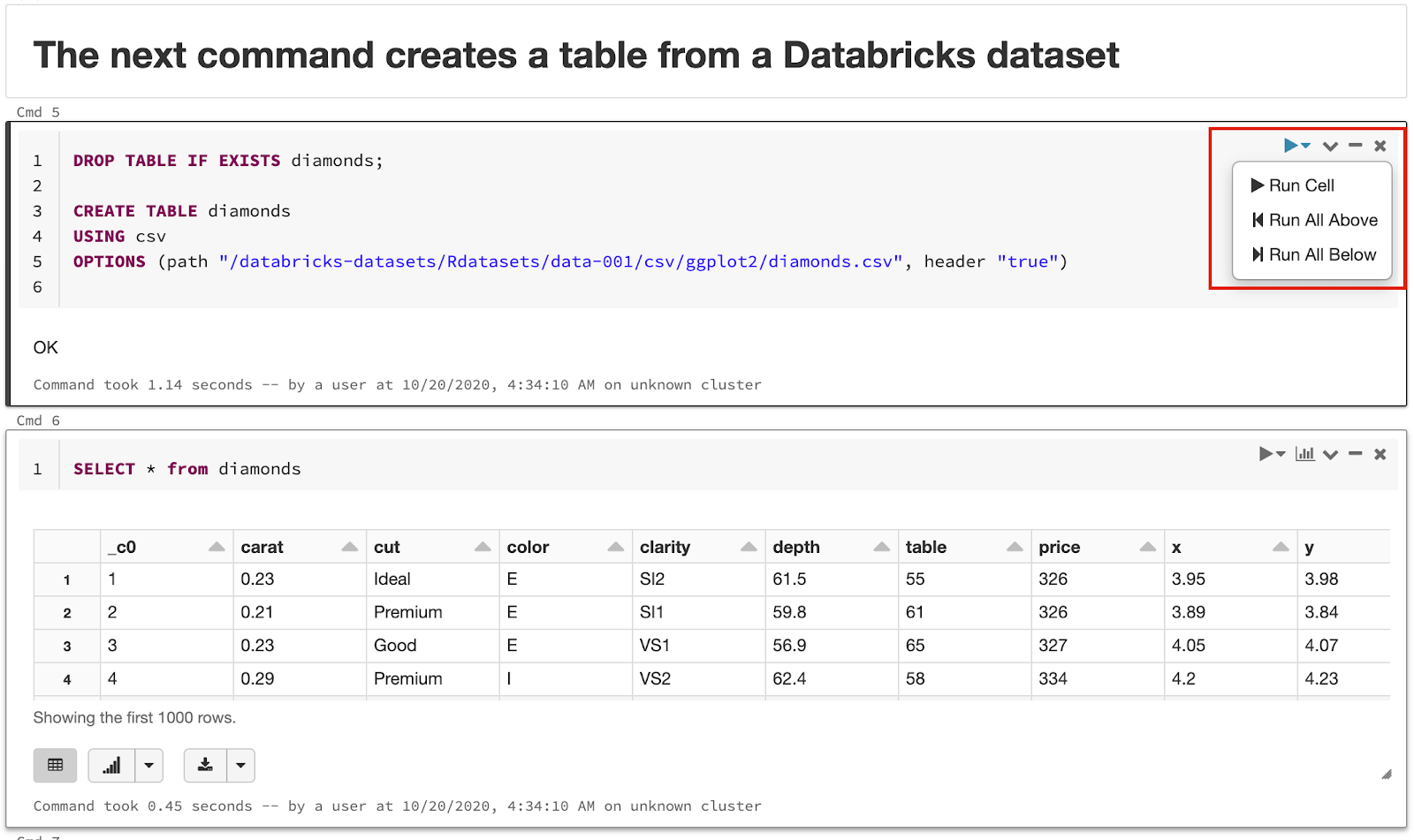
上記の実行結果からわかるように、DatabricksのNotebookには実行結果のデータをテーブルフォーマットで表示する機能が備わっています。さらに、インタラクティブにグラフ化する機能も標準で用意されています。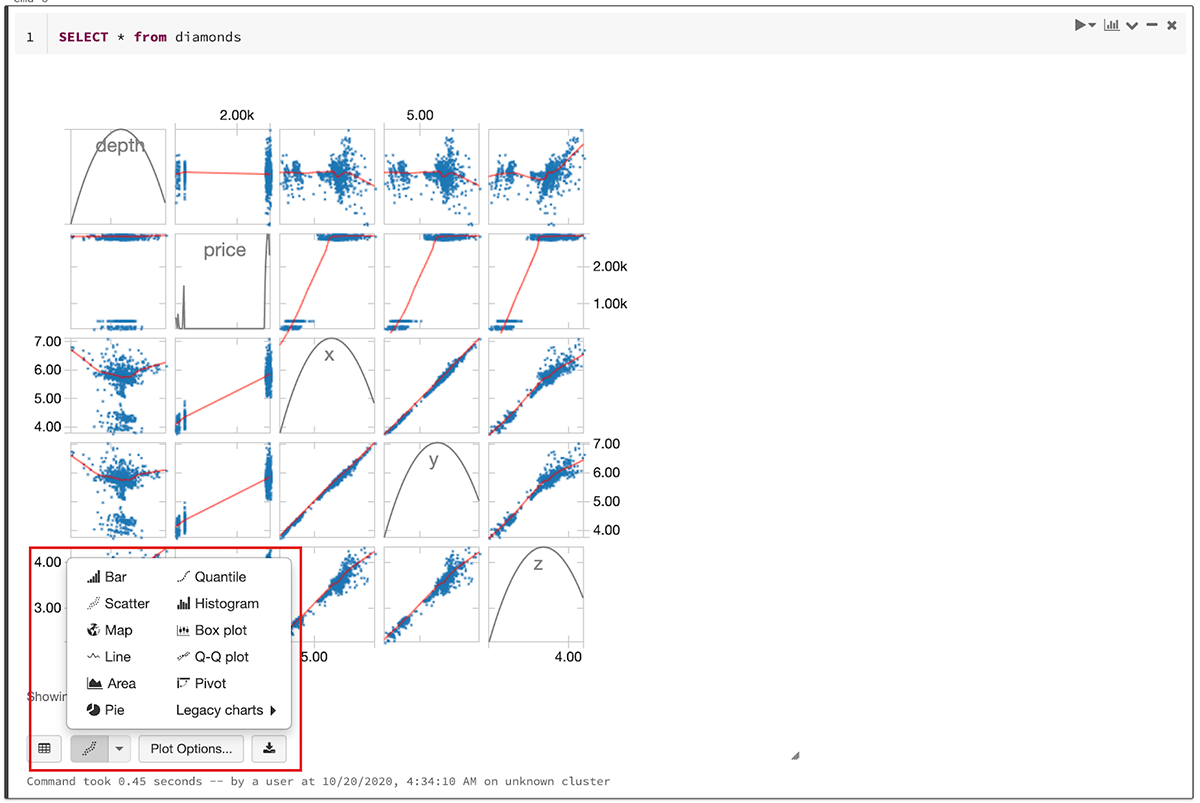
このサンプルのNotebookを一通り実行していただくことで、DatabricksのNotebookの基本的な使い方が理解いただけると思います。
サンプルデータ
Databricksは、すぐに試せるサンプルNotebookに加えて、parquet, json, csv, 画像などのサンプルデータも提供されおり、すぐに使える状態になっています。DatabricksのNotebook上から dbfs:/databricks-datasets/ 配下に配置してあるので、以下のコマンドで一覧を確認できます。
%fs ls dbfs:/databricks-datasets/
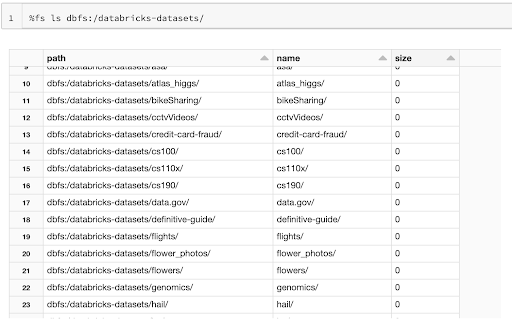
例えば、以下のようなデータが含まれています。
dbfs:/databricks-datasets/learning-spark-v2/flights/departuredelays.csvdbfs:/databricks-datasets/learning-spark-v2/loans/loan-risks.snappy.parquetdbfs:/databricks-datasets/learning-spark-v2/us_population.jsondbfs:/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean.parquetdbfs:/databricks-datasets/flower_photos/tulips/ [*.jpg]
最初に挙げた departuredelays.csv を読み込んでテーブル表示させてみましょう。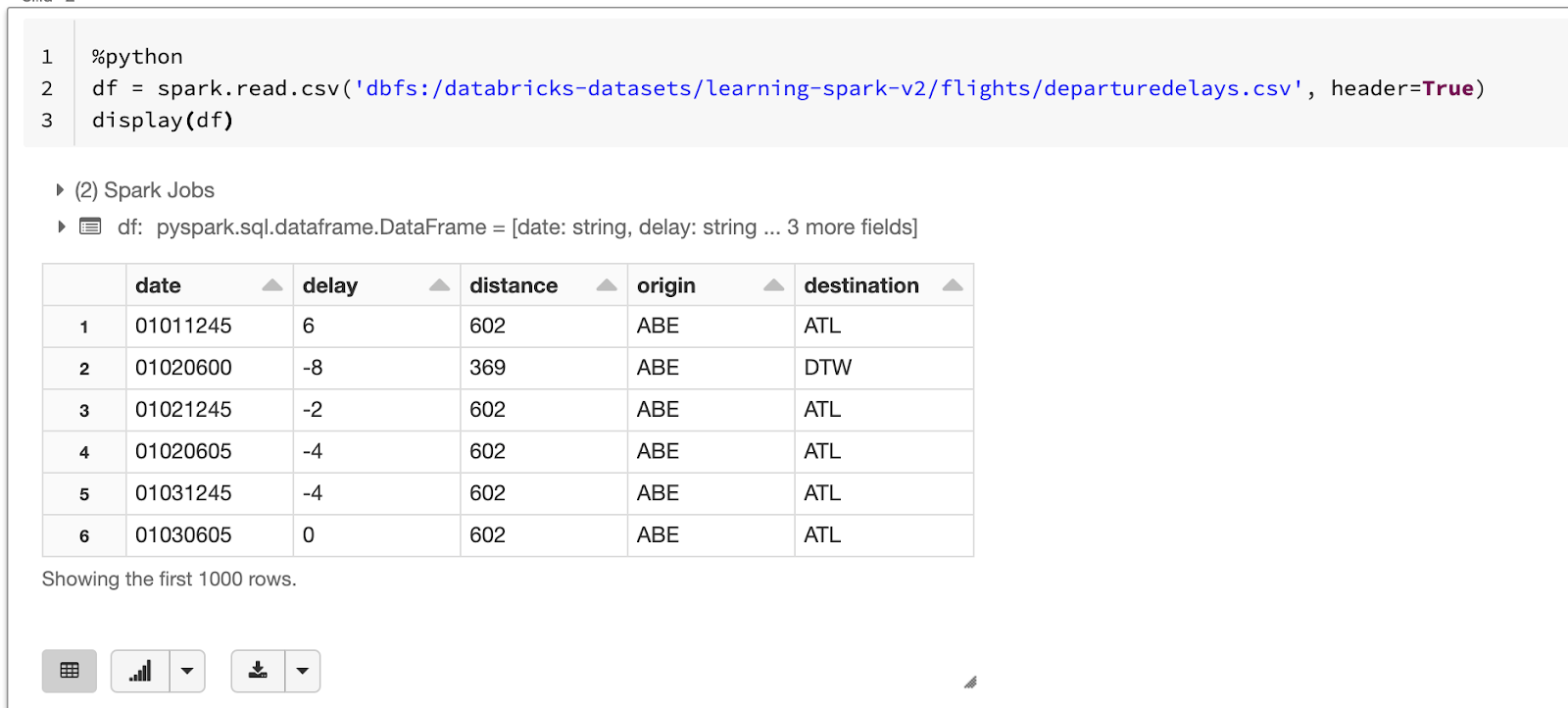
また、DatabricksではScikit-learnなどの機械学習ライブラリが標準で使用できるため、これらのライブラリに含まれるサンプルデータもすぐに使用できます。
次のステップ
Databricksでは、以下のようなData/AIのための様々な機能を提供しております。
- Lakehouseを実現するDelta Lake
- ストリーミング処理とバッチ処理を統合するStructured Streaming
- Sparkで分散学習をサポートする機械学習ライブラリMLlib
- 機械学習モデルのライフサイクルを管理するMLflow
そして、これらの機能はCommunity Editionでも使用することができます。各機能の使い方に関してはドキュメントを参照ください。
- Delta Engine および Delta Lake ガ��イド
- 機械学習およびディープ ラーニング ガイド
- MLflow ガイド
- Apache Spark チュートリアル: Apache Spark チュートリアルを開始する(一部英語)
また、併せて以下のリソースも参照ください。
- データレイクハウスとは
- 用語集(Data/AI/Databricks関連)
- 機械学習ユースケースのビッグブック
よくある質問
- Q) Community Editionにおいて、通常のPythonコード上からDBFSへの参照、例えば、
open('/dbfs/databricks-datasets/README.md')でエラーが発生します。
- A) Community EditionではDBFSがNodeローカルの/dbfs/にマウントされておらず、上記のように直接ファイルを参照できません。よって、dbutilsを使用して、一度DBFSからローカルにコピーした後、読み込んでください。以下がコード例になります。
%python dbutils.fs.cp('dbfs:/databricks-datasets/README.md', 'file:/tmp/README.md') f=open('/tmp/README.md')

