医療分野におけるNLP(自然言語処理)の大規模な活用方法とは
ジョン・スノー・ラボとの共同ソリューションで、臨床テキストに隠された知見を抽出
によって Michael Ortega, マイケル・サンキー 、 Moritz Steller による投稿
This is a co-authored post written in collaboration with Moritz Steller, AI Evangelist, at John Snow Labs. Don't miss our virtual workshop, Extract Real-World Data with NLP, on July 15 to learn about our new NLP solutions.
HIMSS は 2015 年、年間 12 億件の臨床文書が米国ヘルスケア産業によって作成されていると報告しました。これらは電子カルテや症候群サーベイランスなど膨大な量の非構造化テキストデータです。その後もヘルスケアのデジタル化が進み、年間に生成される臨床テキストデータの量はますます増大しています。デジタルフォーム、オンラインポータル、レポートの PDF ファイル、メール、テキストメッセージ、チャットボットなどが、現在のヘルスケアにおけるコミュニケーション手段として利用されています。これらの手段を介して生み出されるテキストの量はあまりに膨大、かつ広範に過ぎるため、測定が困難であり、人が扱うのは現実的ではありません。また、これらは非構造化データであるため、分析が容易でなく、サイロ化されたままの状態で放置されるのが実情です。
症候群サーベイランス、検査レポート、診断書、チャット履歴には貴重な情報が閉じ込められており、この状況は、あらゆるヘルスケア機関にとってのリスクとなっています。これらのデータを患者の電子カルテ(EHR)と組み合わせることができれば、患者の健康状態の詳細の把握が可能になります。また、集団レベルでは、これらのデータセットを創薬、治療経路、現実世界での安全性評価に利活用できるようになります。
NLP の活用による医療・ヘルスケア知見の抽出
自然言語処理(NLP)とは、コンピューターが文章や音声、画像のテキストの理解を可能にする人工知能の分野のことです。この NLP の発展により、テキストから知見を抽出できるようになったことは、喜ばしい前進です。NLP の手法を用いることで、電子カルテデータベースなどの非構造化の臨床テキストを抽出、コード化し、構造化された形式で蓄積できます。これにより、下流で分析を行い、機械学習(ML)モデルに�直接供給できます。これらの技術は、研究や治療に大きな革新をもたらしています。
米国最大の非営利医療プランとヘルスケアのプロバイダーである Kaiser Permanente (カイザーパーマネンテ)のユースケースでは、NLP(自然言語処理)を活用して何百万もの緊急治療室のトリアージノートを処理し、病床、看護師、臨床医の需要を予測し、最終的に患者のフローを改善しています。また、NLP を活用して、HIV 陽性の青少年のためのモバイルサポートグループの非標準テキストメッセージを分析したこの研究では、グループへの参加と服薬アドヒアランス(用法・用量の遵守)の改善は、社会的支援への感情との間に強い相関関係があることが明らかになっています。
ヘルスケア NLP(自然言語処理)の課題とは?
このような素晴らしい革新があるにもかかわらず、多くの医療・ヘルスケア機関が電子カルテなどの臨床テキストデータを活用していないのはなぜでしょうか。私たちは、最大規模のペイヤー、医療機関、製薬会社の顧客との協業経験から、次に挙げる 3 つの課題があると考えています。
NLP システムの多くが医療・ヘルスケア向けに設計されていない。
臨床テキス��トは特殊な言語です。EHR、臨床メモ、PDF レポートなど、多岐にわたるソースシステムからのデータには一貫性はなく、臨床専門分野によって言語が大きく異なります。従来の NLP 技術は、医療テキスト特有の語彙や、文法、意図を理解するためには構築されていません。例えば、下の図の文字列から NLP モデルは、アジスロマイシンが医薬品であること、500mg が服用量であること、SOB は、患者の肺炎に関連する状態の「shortness of breath (息切れ)」の臨床的な略語であることを理解する必要があります。また、テキストの「W/O (without)」から、患者は息切れをしていないことや、「Prescribing」から、処方されたばかりで、まだ薬は服用していないことを推察することも重要です。

従来型のヘルスケアデータアーキテクチャは、柔軟性に欠ける。
テキストデ�ータには膨大な情報が含まれていますが、これだけは患者の健康状態を把握することはできません。テキストデータと他のヘルスケアデータを組み合わせることで、真の価値が生まれ、患者を包括的に把握できるようになります。しかし、データウェアハウスをベースとして構築された従来型のデータアーキテクチャでは、スキャンしたレポート、生物医学画像、ゲノムシーケンス、医療機器のストリームなどの非構造化データをサポートしていないため、患者データとの組み合わせは不可能です。さらに、これらのアーキテクチャは、拡張にコストがかかり複雑です。大規模なヘルスケアデータのコーパスのシンプルなアドホック分析ですら、処理に数時間から数日要することがあります。これでは、患者のニーズのリアルタイムな調整にあまりに時間がかかりすぎます。
高度な分析機能が欠如している。
多くのヘルスケア機関では、データウェアハウスと BI プラットフォーム上で分析を実行しています。これは、病院で以前の週に使用された病床数を計算するような記述的な分析には適していますが、将来の病床数を予測する AI/ML の機能には欠けています。一般的に、AI に投資した組織は、このシステムをサイロ化された追加のソリューションとして扱います。しかし、この方法では、データを異なるシステムに複製することが必要になり、一貫性のない分析結果をもたらし、知見抽出まで多くの時間がかかります。
Databricks とジョン・スノー・ラボの連携で、ヘルスケア NLP のパワーを引き出す
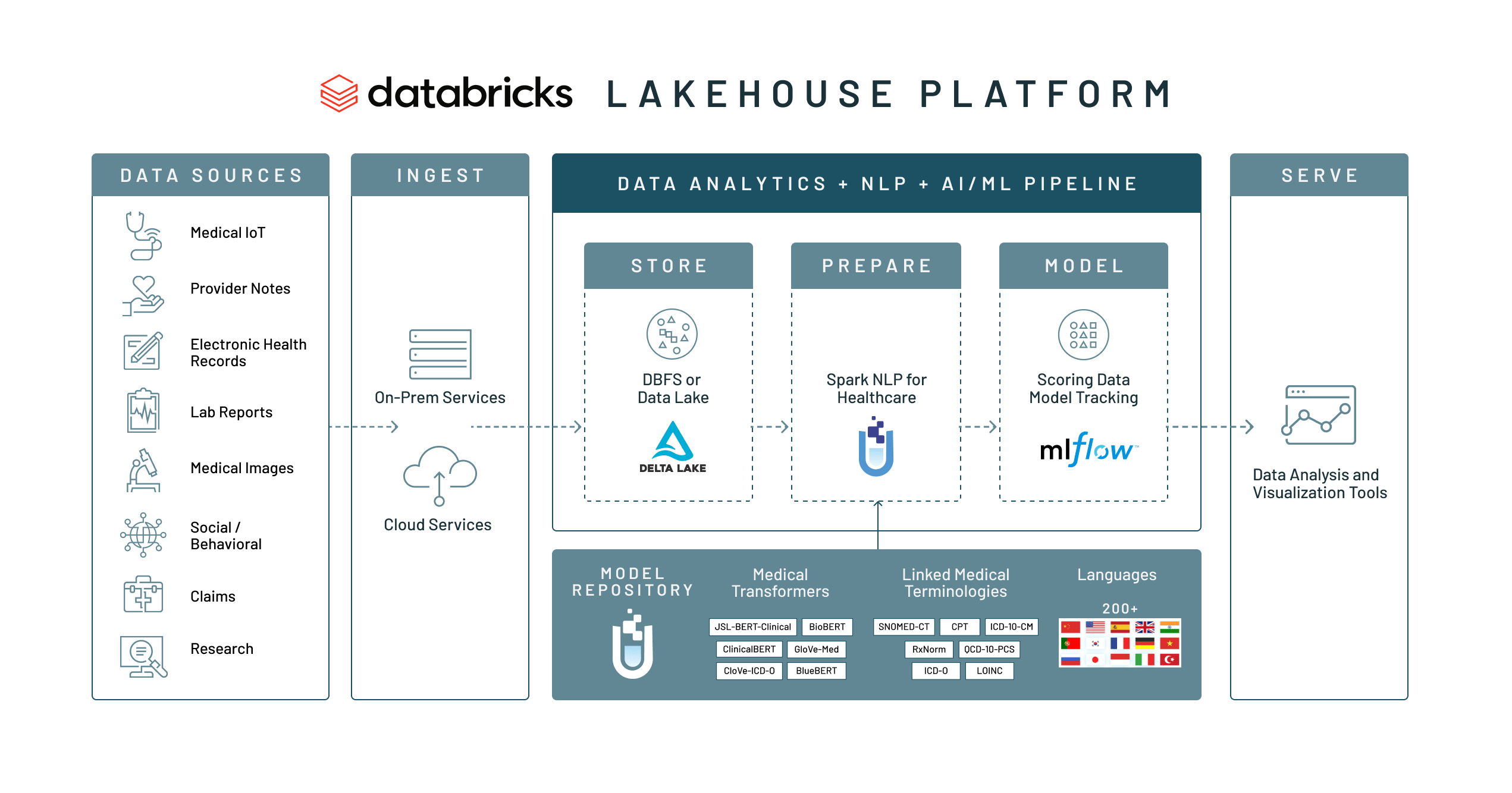
Databricks は、オープンソースの Spark NLP ライブラリ、 ヘルスケアのための Spark NLP��、 Spark OCR を開発したジョン・スノー・ラボと連携して、医療・ヘルスケアおよびライフサイエンス組織向けの新たなソリューションスイートを発表しました。このソリューションは、組織における膨大なテキストデータを患者の新たな知見に変換することを可能にします。この共同ソリューションは、ベストオブブリードのヘルスケア NLP ツールと、あらゆるデータ、分析、AI に対応するスケーラブルなプラットフォームを組み合わせたものです。

この NLP ソリューションの基盤となるのは、データウェアハウスの利点と、クラウドデータレイクの経済性、柔軟性、スケーラビリティを併せ持つ最新のデータアーキテクチャである Databricks のレイクハウスプラットフォームです。シンプルかつスケーラブルなアーキテクチャにより、ヘルスケアシステムの構造化、半構造化、非構造化データを、単��一で、高性能プラットフォームに統合し、従来の分析やデータサイエンスが可能になります。
Databricks のレイクハウスプラットフォームには、Apache Spark™ と、データレイクに性能、信頼性、ガバナンスをもたらす、オープンソースストレージレイヤーの Delta Lake が中核にあります。ヘルスケア機関では、未加工の診断書や、検査レポートの PDF ファイルを含むあらゆるデータを Delta Lake の「ブロンズ」インジェストレイヤーに取り込み、データ変換を実行する前に信頼できる唯一のソースを保持できます。一方、従来のデータウェアハウスでは、変換はデータを読み込む前に実行されます。そのため、非構造化テキストから抽出された全ての構造化変数は、ネイティブのテキストから切り離された状態になります。
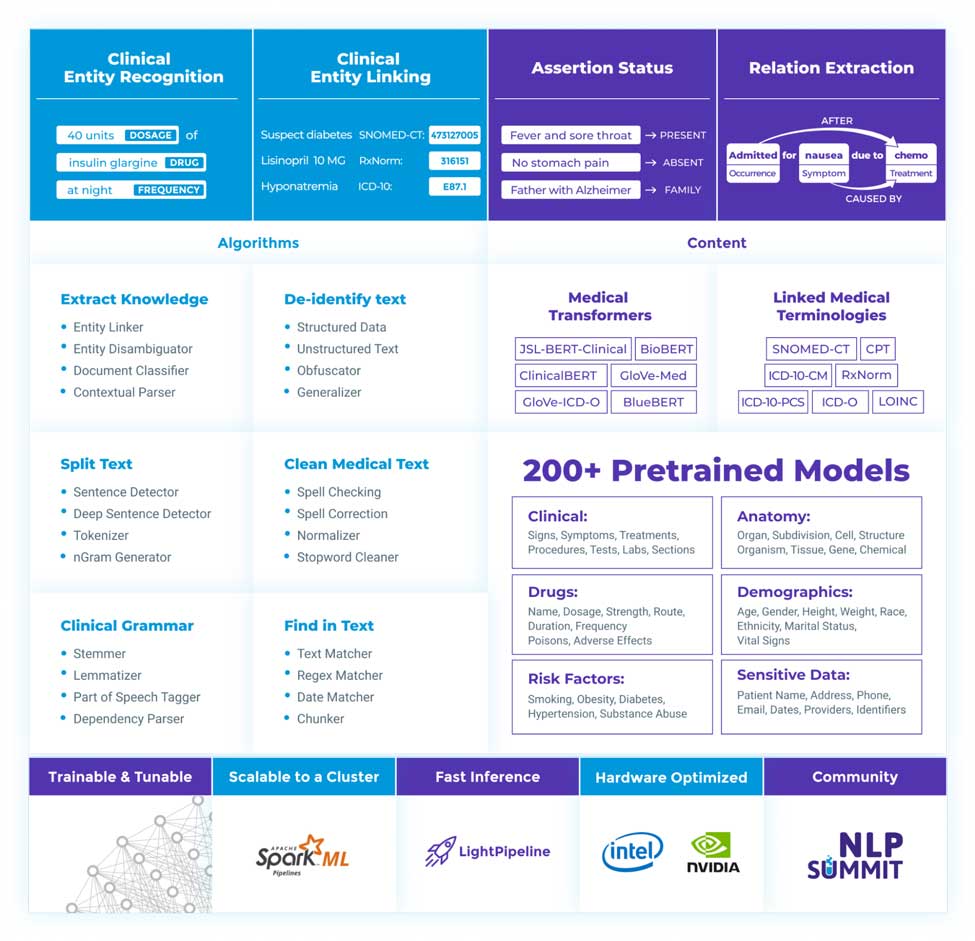
ジョン・スノー・ラボによる医療・ヘルスケアのための Spark NLP は、Databricks のレイクハウスプラットフォームを基盤として構築されています。ヘルスケア・ライフサイエンス業界で最も広く使用されている NLP ライブラリであり、臨床・生物医学関連のテキストデータをシームレスに、極めて高確度で抽出、分類、構造化します。スケーラブルでトレーニング可能かつ実運用グレードという特長を持つ最新のヘルスケア向け深層学習・転移学習技法の実装と、事前学習済みで常時更新される 200 以上の NLP モデルが、これを可能にしています。
ジョン・スノー・ラボのソフトウェアラ��イブラリの注目すべき機能は次のとおりです。
- 症状と薬、解剖学、社会的決定要因、ラボ、画像、遺伝子など、100 以上の臨床および生物医学の名前付きエンティティをすぐに識別。
- SNOMED-CT、ICD-10-CM、ICD-10-PCS、RxNorm、LOICS、UMLS、MESH、HPO など、臨床用語の中から意味的に最も近い用語コードにエンティティを解決。
- 事前トレーニング済みのリレーション抽出モデルにより、医療のイベント間、治療と薬、遺伝子と表現型など、30 種類以上のリレーションタイプを検知。
- フリーテキスト、PDFドキュメント、スキャンしたレポート、DICOM 画像にある機密情報の検知、非識別化、難読化をカスタマイズ。
- 他にはない、ヘルスケアに特化した用語、単語のまとまり(チャンク)、それらが埋め込まれた文章を、新たな用語やコンテンツで定期的に更新。
私たちの共同ソリューションは、ジョン・スノー・ラボによる医療・ヘルスケアのための Spark NLP の優れた処理能力と Databricks のコラボレーション可能な分析および AI 機能の融合です。インフォマティクスチームは、未加工のデータを直接 Databricks にインジェストし、ヘルスケアのための Spark NLP により大規模にデータを処理、ダウンストリームの SQL Analytics や機械学習を単一のプラットフォームで利用できます。トレーニングと推論のプロセスは、Databricks で直接実行されるため、スピードやスケーラビリティだけでなく、データが第三者に漏洩することを防ぐメリットもあります。これにより、機密性の高い医療データを処理する際のプライバシーとコンプライアンスの重要な要件を満たすことができます。何よりも、Apache Spark™ 上に構築されている Databricks は、ヘルスケアのための Spark NLP のような Spark アプリケーションの実行に最適なプラットフォームです。
ヘルスケア NLP の大規模展開 ― 次のステップ
- Check out our latest NLP Solution Accelerators for extracting oncology insights from clinical data and adverse drug event detection.
- Download our Healthcare NLP solution sheet for more information
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。