Delta Lake で機械学習の課題を解決

既存のデータレイクファイルストレージ上に構築されるオープンソースのストレージレイヤーである Delta Lake や機械学習の開発で使用される MLflow が話題に上る機会が増えています。しかし、多くのケースでは 2 つが別々の製品として取り上げられています。本ブログでは、機械学習の開発の際に起こりうるデータのバージョン管理や OOM エラーなどの課題において Delta Lake と MLflow の相乗効果に焦点を当て、堅牢なデータ基盤に基づく有用な機械学習結果を得るために Delta Lake をいかに活用すべきかについて解説します。
データサイエンティストであれば、機械学習のモデル作成のプロセスは既に整っており、MLflow を機械学習モデルの本番環境へのデプロイに活用したことがあるでしょう。MLflow には、実験を追跡できる機能や、モデルのプロモーションに活用できる MLflow モデルレジストリが備わっています。また、コードのバージョン、クラスタのセットアップ、データの場所などの追跡機能による再現性も優れています。
しかし、機械学習の開発やデプロイメントの過程では、データ探索に費やす時間の短縮や、開発に使用したデータの正確なバージョンの確認が必要になります。また、トレーニングジョブのパフォーマンスが期待どおりでなかったり、OOM(Out of Memory)エラーが頻発したりする場合もあります。
これらは全て機械学習開発の際に起こりうる課題です。機械学習開発における課題解決のソリューションを見出すのは極めて困難ですが、Delta Lake を活用することで、このようなスケーラビリティの課題を解決できます。
Delta Lake(略称:Delta)は、既存のデータレイクに信頼性をもたらすオープンソースのストレージレイヤーです。業務プロセスを変えたり、新たな API について学んだりすることもなく、有効に活用できます。このブログでは、データサイエンティストや ML エンジニアが経験する一般的な機械学習開発の課題を取り上げ、Delta によってそれらがどのように緩和されるかについて説明します。
クエリに遅延が生じているが、原因が不明
データセットのサイズによっては、データの詳細を把握するのに時間がかかることがあります。クエリを並列化しても、内部プロセスが異なると、クエリの遅延が発生することも考えられます。Delta には、ETL や探索的データ分析に使用できるアドホッククエリなどのさまざまなクエリのパフォーマンスを向上させる最適化 Delta Engine があります。それでも期待どおりのパフォーマンスが得られない場合には、Delta フォーマットにより DESCRIBE DETAIL 機能を使用できます。この機能では、クエリを実行しているテーブルのサイズやファイル数、スキーマに関する重要な情報の迅速な取得が可能です。このように、Delta では Notebook 上で操作できる組み込みツールを使ってパフォーマンスの問題を特定し、複雑さを軽減します。

クエリ実行の待ち時間が問題になることがよくあります。この問題は、データ量の増加にともない悪化します。しかし、Delta ではデータスキッピングなどの最適化機能を提供しています。データが増加し、新たなデータが Databricks の Delta テーブルに挿入されると、サポートされているタイプの全ての列について、ファイルレベルの最小/最大統計が収集されます。そして、テーブルに対してクエリが実行されると、Delta がまずこれらの統計情報を参照して、どのファイルが安全にスキップでき、どのファイルに関連性があるかを判別します。Delta では、この情報をクエリの実行時に活用して高速なクエリを実現します。設定は不要です。
データスキッピングの機能は、Delta に対して列に関するデータの最適化を明示的に指示することにも活用可能です。これは、関連する情報を同じファイルセットに配置する Z 階数曲線手法を使用して行われます。すなわち、列に ZORDER BY を適用すれば、列にフィルターを指定してテーブルに繰り返しクエリを実行するよりも、結果を早く取得できるということです。特に、列に異なる値が多数含まれており、カーディナリティが高い場合��に有効です。
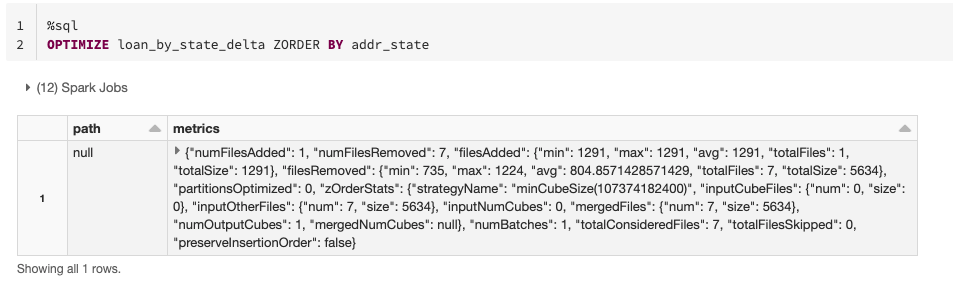
テーブルに対する一般的な条件式が不明な場合や、探索段階である場合は、小さなファイルをより大きなファイルにまとめてテーブルを最適化できます。そうすることで、データにクエリを実行する際のファイルのスキャン数を減らし、パフォーマンスを改善できます。ZORDER 列を指定せずに、OPTIMIZE コマンドの使用も可能です。
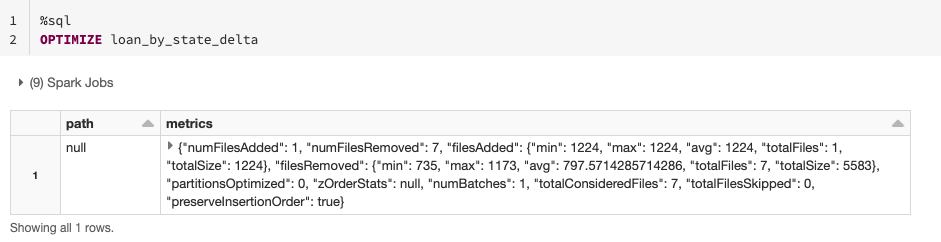
膨大なデータがあり、そのうちの一部だけを最適化したい場合は、WHERE を使ってオプションのパーティション条件式を指定し、一部のデータ(例:最近追加されたデータ)だけを最適化するように指示できます。

メモリに対してデータが大きすぎる
機械学習のモデルトレーニングの際には、全データセットではなく、特定のデータサブセットでトレーニングをしたり、フィルターを指定して特定期間内のデータに絞り込んだりしたい場合があります。通常のワークフローでは全てのデータが読み込まれます。全データがスキャンされてメモリに読み込まれ、関連する部分が保持されることになります。したがって、この段階で処理に問題がなくとも、非常に時間がかかります。最終的には不要となるデータでマシンに過剰な負荷がかかるわけですから、最初から必要なファイルだけを読み込めばいいのではないでしょうか。このような場合には、パーティションプルーニングが役立ちます。
ここではパーティションといっていますが、実際には、パーティション列の異なる値ごとに用意されるサブディレクトリのことを指しています。フィルターを適用する列でデータにパーティションが指定されている場合、プルーニングを行うことで、適切なサブディレクトリのみをスキャンして残りを無視し、必要なファイルだけを読み取ることができます。この処理自体は単純なものかも知れませんが、モデルの完成までに必要となる反復/読み取り回数を考えれば、非常に大き��な効果が期待できます。クエリ実行時の頻出パターンを認識することで、より適切なパーティションの選択が可能になり、全体的な運用コストを削減できます。
また、データにパーティションが指定されておらず、単体のエクゼキュータで処理しきれずに OOM エラーが発生する場合には、DESCRIBE DETAIL、パーティショニング、ZORDER を組み合わせることで、OOM エラーの原因を特定して解決できます。
データ品質の改善に時間がかかる
ETL を実行する

データチームがデータセットの処理中に、変数に誤ったデータ(タイムスタンプが 1485 年になっているなど)が含まれていることに気づく場合があります。このようなデータの問題を特定し、それらの値を削除するには相応の工数が必要です。また、.filter() を使ったクエリは非常に高コストであるため、これらの行の削除は、コンピューティングの面でも大きな負担となります。理想的なシナリオは、誤ったデータをテーブルに追加されないようにすることです。Delta の制約と Delta Live Tables のエクスペクテーションがここで役に立ちます。特に、Delta Live Tables では、期待されるデータの品質と要件を満たさないデータの処理方法を指定できます。過去に遡ってデータを削除するのではなく、積極的にデータをクリーンに保ち、いつでも使用できる状態にします。
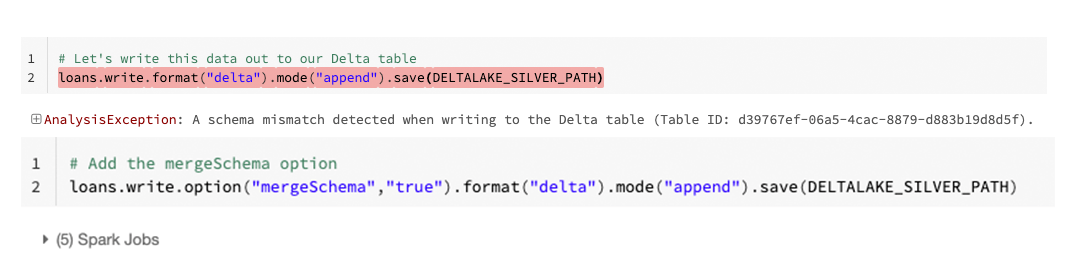
同様に、機械学習のモデリングに使用しているデータに誤って列を追加してしまうことを避ける必要もあるでしょう。Delta は、自動スキーマ更新というシンプルなソリューションでこれに対処しています。デフォルトでは、Delta のテーブルにデータが書き込まれる場合、特に指定がない限りは既知のスキーマに準拠する必要があります。
スキーマが変更された場合も、describe detail コマンドと DESCRIBE HISTORY コマンドを使用して、スキーマの現状と誰がスキーマを変更したかを容易に確認できます。これにより、データチーム内の他のデータサイエンティスト、データエンジニア、データアナリストと連絡を取り合い、変更した理由やその妥当性について把握可能です。
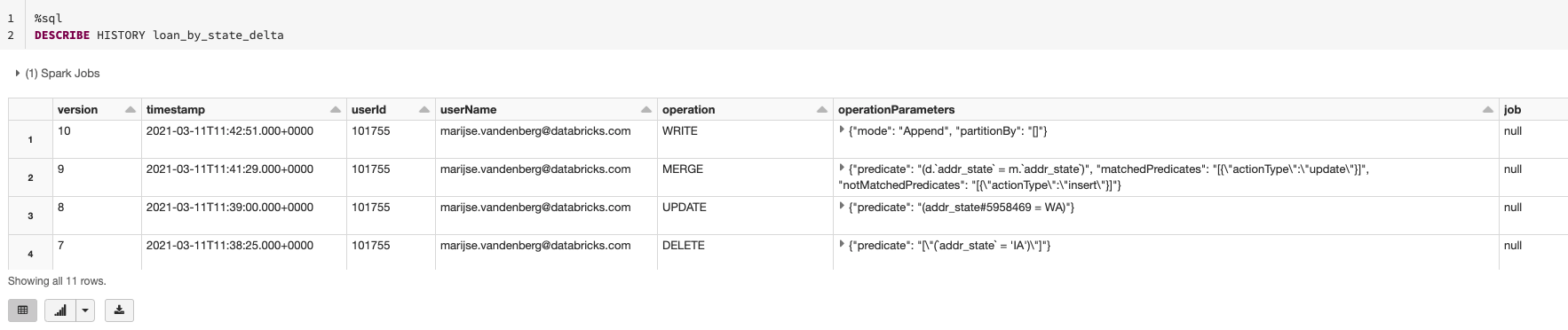
また、変更が不適切または過失によるものであった場合には、タイムトラベル機能を使って、元に戻したり以前のバージョンのデータを復元させたりすることもできます。
トレーニングに使用したデータが不明で結果を再現できない
機械学習モデルの特徴量を生成する際には、その過程でさまざまなバージョンの特徴量を試す場合があります。複数バージョンの特徴量を使用することで、次のような課題が生じる可能性があります。
- トレーニングに使用した特�徴量の具体的なバージョンのトラッキングができず、トレーニング結果が再現できなくなる。
- 本番環境で使用する特徴量がトレーニングで使用したものと異なる可能性があり、本番環境でのモデルの結果がトレーニング時の結果の基準を満たさない。
これらの課題を避けるための解決策としては、複数バージョンの特徴量テーブルを作成し、Apache Parquet などを使用して blob ストレージに保存する方法が挙げられます。そうすることで、MLflow の実行時に、使用したデータへのパスがパラメータとして記録されます。ただし、手動プロセスであり、相当量のデータストレージが必要です。そこで、Delta では別の手法を用意しました。複数バージョンのデータを手動で保存するのではなく、Delta のバージョン管理機能を使用して、データに加えられた変更を自動的にトラッキングします。さらに、Delta は MLflow のさまざまなフレーバーと統合されており、モデルトレーニングに使用されたデータの場所やデータが Delta に保存されている場合のバージョンをトラッキングする mlflow.spark.autolog() などの自動ロギングをサポートしています。このように Delta のデータバージョン管理機能は、複数バージョンのデータを保存しなくてすむため、ストレージコストを削減できるだけでなく、特定のトレーニングランで使用されたデータを容易に把握できます。
しかし、データのバージョンを際限なく保存し管理するとなると、やはりストレージのコストが問題になります。Delta では、保持するデータバージョンの数を指定して保持期間のしきい値(VACUUM)を設定することで、この問題に対処しています。また、新しいモデルの A/B テストに備えて、後からデータを取り出せるように長期間データを保存したい場合などには、Delta のクローンが使用できます。ディープクローンであれば、指定されたバージョンのメタデータとデータファイルの完全なコピーが作成されます。パーティショニング、制約、その他の情報も含まれます。ディープクローンの構文はシンプルで、モデルテストに備えたテーブルの保存も非常に簡単です。

機械学習の本番環境と開発で特徴量が一致しない
データのバージョン管理の課題が解決したとしても、特定の特徴量に関するコードの再現性の課題があるかもしれません。この課題における機械学習のソリューションは、Databricks の特徴量ストアです。特徴量ストアは Delta を基盤として構成されており、このブログで解説したアプローチを全面的にサポートしています。Delta テーブル上で行われた特徴量の開発については、特徴量ストアに容易に記録でき、コードとバージョンを作成時点からトラッキング可能です。また、特徴量に対する追加のガバナンスや、特徴量をより見つけやすく、使いやすくするための検索ロジックなど、さまざまな機能も提供しています。
その他の情報
このブログでご紹介したさまざまなコンセプトの詳細は、以下の資料をご覧ください。
- Delta Lake のクローンを容易に作成し、テスト、共有、ML の再現に活用
- Databricks Feature Store — データ/MLOps プラットフォームの協調設計による特徴量ストア
- テックトーク:Delta Lake の ACID トランザクション - Delta Lake 入門
- Delta Live Tables:信頼性のあるデータライフサイクル管理で SSOT(Single Source of Truth)を容易に実現
- Delta タイムマシンによるタイムトラベル
- Delta Lake:決定版ガイド
まとめ
このブログでは、データサイエンティストが直面するいくつかの一般的な問題を取り上げ、Delta Lake によるこれらの問題の緩和や解決について説明しました。データサイエンティストは、これを活用して、データサイエンスや機械学習プロジェクトを成功に導くことができます。
Delta Lake を詳しく見る