クラウドスケールでのサイバーセキュリティのためのSIEMの強化

オリジナル記事:Augment Your SIEM for Cybersecurity at Cloud Scale
この10年間で、セキュリティインシデント・イベント管理ツール(SIEM)は、企業のセキュリティ運用における標準的なものとなっています。しかし、SIEMには常に否定的な意見もあります。しかし、クラウドが爆発的に普及したことで、「クラウドスケールの世界ではSIEMは正しい戦略なのか?HSBCのセキュリティ・リーダーは、そう考えていません。HSBCは、最近の講演「サイバーセキュリティのためのDatabricks LakehouseでSplunkやその他のSIEMを強化する」で、レガシーSIEMの限界とDatabricks Lakehouseプラットフォームがサイバーセキュリティをどのように変革しているかを強調しました。3兆ドルの資産を持つHSBCの話は、少し調べてみる価値がありそうです。
このブログでは、変化するITとサイバー攻撃の脅威の状況、SIEMのメリット、Databricks Lakehouseのメリット、そしてなぜSIEM + Lakehouseがセキュリティ運用チームの新しい戦略になりつつあるのかについてお話しします。もちろん、私が愛用しているSIEMについてもお話しします!しかし、これは「オンプレミスの世界のために作られたレガシーテクノロジー」を批判する記事ではないので、ご注意ください。この記事は、高度な持続的脅威から企業を守るために、セキュリティ・オペレーション・チームがどのように武装できるのかについて書かれています。
エンタープライズ・テックのフットプリント
クラウドファーストと呼ぶところもあれば、クラウドスマートと呼ぶところもある。いずれにせよ、あらゆる組織が何らかのクラウド変革や評価に取り組んでいることは一般的に認められています。その結果、米国の主要なクラウドサービスプロバイダーは、いずれも世界の時価総額上位5社にランクインしています。技術的な足跡がクラウドに移行するにつれて、サイバーセキュリティ・チームに対する要件も変化しています。検知、調査、脅威の発見といった業務は、新しいフットプリントの複雑さと膨大なデータ量によって、すべて困難なものとなっています。IBMによると、セキュリティ侵害の検出と封じ込めに平均280日かかるという。Data + AI SummitでのHSBCの講演によると、280日というのは、ネットワークとEDR(エンドポイント脅威検出・対応)のデータソースだけで1ペタバイトを超えるデータ量になります。
組織が検知と対応にこれだけのデータを必要とする場合、どうすればいいのだろうか。 多くの企業は、クラウドデータをクラウドに置いておきたいと考えています。しかし、あるクラウドから他のクラウドへの移動はどうでしょうか?今週、ある大手金融機関に話を聞いたところ、"クラウドプロバイダーに100万ドル以上のイグレスコストを支払っている "と言っていました。なぜか?なぜなら、現在のSIEMツールはあるクラウドサービス上にあり、最大のデータ生産者は別のクラウドサービス上にいるからです。 同社のSIEMはマルチクラウドではありません。そして、長年にわたって、あるクラウドプロバイダーから別のクラウドプロバイダーへデータを取得するために、複雑なトランスポートパイプラインを構築してきました。このような複雑さが、テクノロジーに対する期待値を歪めているのです。例えば、彼らはデータの5分遅れをリアルタイムとみなしています。このような複雑な問題を抱えているのは、私が話を聞いたグループだけではないはずです。
クラウドの世界におけるセキュリティ分析
10年前にビッグデータと呼ばれていたものは、今日のクラウドの基準からすると、ちっぽけなデータでしかありません。今日のネットワーク・トラフィックの規模では、ギガバイトがペタバイトになり、生成に数ヶ月かかっていたものが数時間で生成され�るようになりました。スタックも新しくなり、セキュリティチームはそれらを学ぶ必要があります。これらのIPを以前に見たことがある」というようなありふれたタスクが、SIEMやロギング・ツールで数時間から数日かけて検索されるようになりました。ネットワークイベントにユーザー名を追加するような、少し高度なコンテキスト化タスクは、ほぼ不可能な試練に変わりつつある。また、1日あたりテラバイトのデータで外部脅威情報のストリーミングエンリッチメントを行いたい場合、幸運なことに、少人数の軍隊と深いポケットを持っていることを祈ります。また、異常検知や脅威狩りのユースケースにも手をつけていない。これは、決してSEIMを非難しているわけではありません。現実には、地形が変わり、適応する時期が来ているのです。セキュリティ・チームには、この仕事に最適なツールが必要なのです。
クラウドの世界では、セキュリティチームはどのような能力を必要としているのでしょうか。まず第一に、ITやセキュリティのツールチェーンと統合でき、データを独自のデータストアに提供する必要がないオープンなプラットフォームです。また、マルチクラウドプラットフォームであることも重要な要素で、好みのクラウド(複数)上で動作させることができます。さらに、コンピュートとストレージが分離され、エンドツーエンドのストリーミングとバッチ処理をサポートできる、スケーラブルで高性能な分析プラットフォームも必要です。そして最後に、データサイエンティスト、データエンジニア、SOCアナリスト、ビジネスアナリストなど、すべてのデータ関係者に力を与える統合プ�ラットフォームです。これがDatabricks Lakehouse Platformの機能です。
DatabricksのSaaSと自動スケーリング機能は、これらの高度な機能の使用を簡素化します。Databricksを利用するセキュリティ企業は、ペタバイトのデータを10分以内に解析しています。あるお客様は、1,500万以上のエンドポイントから収集し、1時間以内に脅威指標を分析することができます。あるグローバルな石油・ガス生産会社は、ランサムウェアを警戒して、複数の分析を実行し、環境内のすべてのpowershell実行をコンテキスト化しています -- アナリストは信頼性の高いアラートだけを見ることができます。
レイクハウス+SIEM : クラウド規模でのセキュリティ運用のパターン
HSBCでサイバーセキュリティ・サイエンス&アナリティクスの責任者を務めるジョージ・ウェブスター氏は、「レイクハウス+SIEMは、セキュリティ運用のTHEパターン」と説明する。マルチクラウドネイティブなストレージとアナリティクスを実現するLakehouseアーキテクチャと、セキュリティ運用のワークフローを実現するSIEMという、2つのコンポーネントの強みを活かしているのです。Databricksのお客様にとって、この統合には2つの一般的なパターンがあります。しかし、どちらもウェブスターが「The Cybersecurity Data Lake with Lakehouse」と呼ぶものによって支えられています。
最初のパターンです: レイクハウスでは、すべてのデータを最大保存期間分保存します。データの�サブセットはSIEMに送信され、ほんのわずかな期間だけ保存されます。 このパターンでは、アナリストがSIEMを使って直近のデータを照会できる一方で、Databricksで履歴分析やより高度な分析を行えるという利点があります。そして、SIEMの導入に必要なライセンスやストレージのコストも管理します。
2つ目のパターンは、最もボリュームのあるデータソースをDatabricksに送ることです(例:クラウドネイティブログ、エンドポイント脅威検出および応答ログ、DNSデータ、ネットワークイベントなど)。比較的ボリュームの少ないデータソースはSIEMに送る(例:アラート、電子メールログ、脆弱性スキャンデータ)。このパターンにより、Tier 1アナリストはSIEMにある優先度の高いアラートを迅速に処理することができます。脅威ハントチームや調査員は、Databricksの高度な分析機能を活用することができます。このパターンでは、処理、取り込み、保存をSIEMからオフロードすることで、コスト面でのメリットがあります。
レイクハウスとSplunkを連携させる
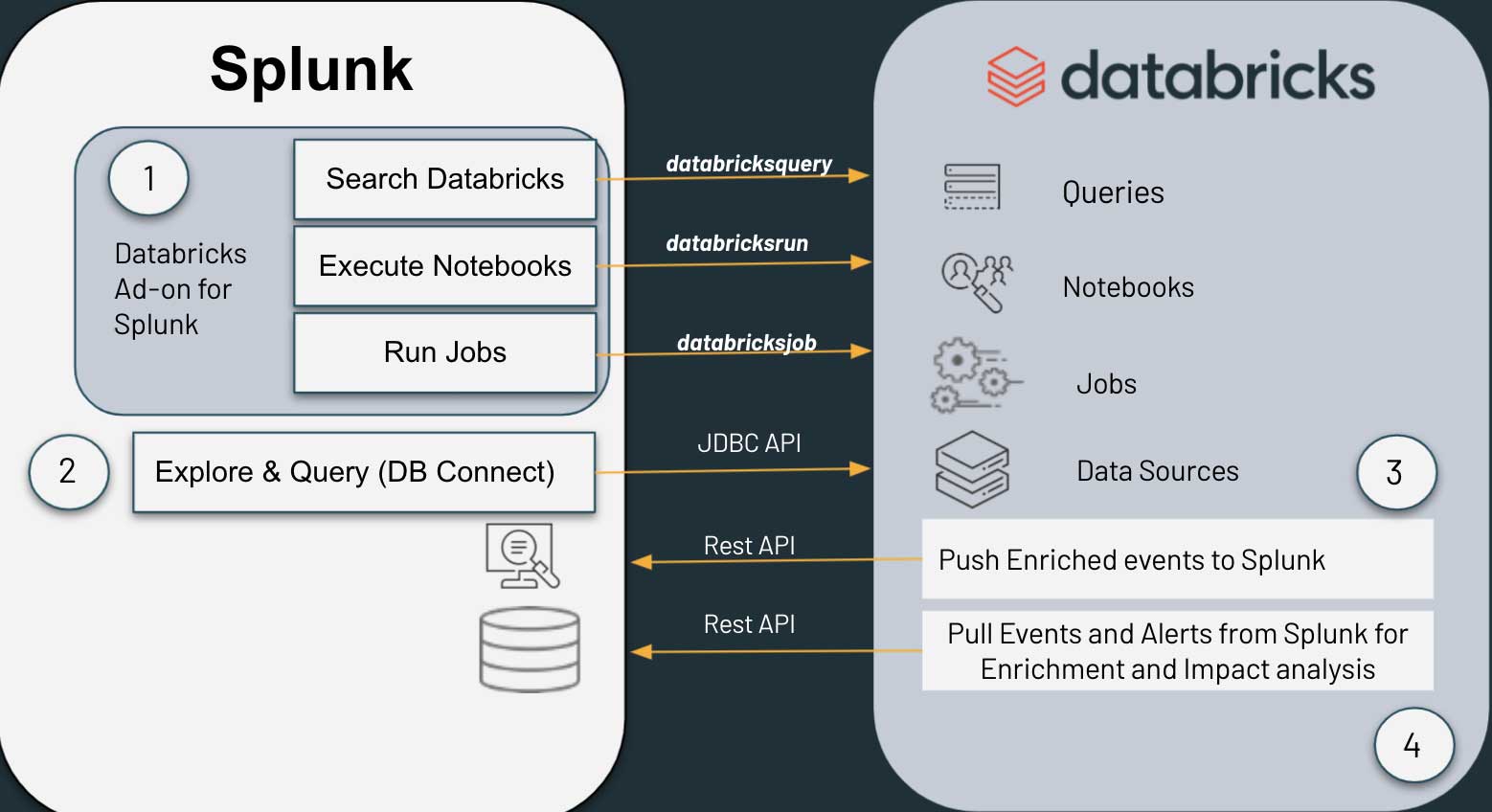
実用例はどのようなものだろうか。顧客からの要望により、Databricks Cybersecurity SME チームは Splunk 用 Databricks アドオンを作成しました。このアドオンにより、セキュリティアナリストは Splunk から Databricks のクエリとノートブックを実行し、その結果を Splunk に戻すことができるようになりました。付属の Databricks ノートブックにより、Databricks は Splunk へのクエリ、Splunk の結果の取得、Databricks から Splunk へのイベントと結果の転送が可能です。
これら 2 つの機能により、Splunk の検索バーにいるアナリストは、Splunk UI を離れることなく Databricks と対話することができます。また、Splunk の検索ビルダーやダッシュボードは、検索の一部として Databricks を含めることができます。しかし、最もエキサイティングなのは、セキュリティチームが Splunk と Databricks の間で双方向の分析自動化パイプラインを作成できることです。 例えば、Splunkでアラートが発生した場合、Splunkは自動的にDatabricksを検索して関連イベントを探し、その結果をアラートインデックスやダッシュボード、その後の検索に追加することができます。また逆に、DatabricksのノートブックコードブロックがSplunkに問い合わせ、その結果を後続のコードブロックの入力として使用することができます。
このリファレンス・アーキテクチャにより、企業は現在のプロセスや手順を維持しながら、インフラを近代化し、マルチクラウド・ネイティブになって、拡大するデジタルフットプリントのサイバーセキュリティリスクに対応することができます。
スケール、スピード、セキュリティ、コラボレーションを実現する
Databricksとの提携以来、HSBCはコスト�を削減し、脅威の検出と対応を加速させ、セキュリティ態勢を向上させました。金融機関は必要なデータをすべて処理できるだけでなく、PBスケールでオンラインクエリの保持期間をわずか数日から数ヶ月に延長しました。攻撃者のスピードと、HSBCが悪意のある活動を検知して調査を行う能力との間のギャップが縮まっています。敵のペースとスピードに合わせて高度な分析を行うことで、HSBCは悪質な行為者よりも速く動くという目標に近づいているのです。
データ保持機能の結果、HSBCの脅威狩りの範囲は大幅に拡大されました。HSBCは現在、ハードウェアの制限を受けることなく、アナリスト1人当たり2~3倍の脅威狩りを実行できるようになりました。Databricksのノートブックを通じて、ハントは再利用可能で自己文書化され、将来のハントのために過去のデータをそのまま保持することができます。この情報は、調査や脅威ハンティングのライフサイクルと同様に、HSBCのチーム間で共有され、脅威検出の反復と自動化を行うことができるようになりました。効率性、スピード、機械学習/人工知能の革新が可能になったことで、HSBCはコストの合理化、リソースの再配分、ビジネスクリティカルなデータの保護を強化することができるようになりました。
次のステップ
Empower Splunk and Other SIEMs with Databricks Lakehouse for Cybersecurityをご覧いただくと、HSBCとDatabricksがどのようにサイバーセキュリティ要件に取り組んでいるか、直接お聞きいただけます。
SplunkのDatabricksアドオンの詳細についてはこちらをご覧ください。
参考リンク
Market caps: https://www.visualcapitalist.com/the-biggest-companies-in-the-world-in-2021/
Breach lifecycle: https://www.ibm.com/security/digital-assets/cost-data-breach-report/#/

