Hadoop からレイクハウスへの移行:成功のための 5 つのステップ
Hadoop (ハドゥープ)からレイクハウスアーキテクチャのようなモダンなクラウドベースのアーキテクチャへの移行は、技術的な判断ではなく、ビジネス的な判断です。以前のブログ、It’s Time to Re-evaluate Your Relationship With Hadoop では、組織がHadoop との関係を再評価する必要がある理由を解説しました。テクノロジー、データ、ビジネス部門のステークホルダーが、企業としてHadoopからの移行を決定した場合、実際の移行を開始する前に考慮すべきいくつかの事項があります。このブログでは、実際の移行プロセスそのものに焦点を当てて解説します。移行を成功させるための重要なステップや、新たなデータドリブンなイノベーションの成功にレイクレイクハウスアーキテクチャが果たす役割を説明します。
移行のステップ
はっきり言いましょう。移行は決して簡単ではありません。しかし、移行を構造化することで、リスクを最小限に抑え、ビジネスの継続性を確保し、コストを効果的に管理できます。そのためには、Hadoop からの移行を以下の 5 つのステップに分けて実行ことことをお勧めします。
- 管理
- データの移行
- データ処理
- セキュリティとガバナンス
- SQL および BI レイヤー
ステップ 1:管理
Hadoop に不可欠な概念を管理の�視点から確認し、Databricks との比較対照を行ってみましょう。
Hadoop は、基本的にモノリシックな分散型ストレージおよびコンピューティングプラットフォームです。複数のノードとサーバーで構成され、それぞれが独自のストレージ、CPU、およびメモリを備えています。作業はこれら全てのノードに分散されます。リソース管理は YARN によって行われ、ワークロードがそれぞれコンピューティングの割り当てを得られるようにベストエフォートを行います。
また、Hadoop はメタデータ情報で構成されています。Hive メタストアがあり、HDFS に保存されているアセットに関する構造化情報が含まれています。データへのアクセス制御には Sentry や Ranger を活用できます。データアクセスの観点から、ユーザーやアプリケーションは、HDFS (または対応する CLI/API)、または SQL タイプのインターフェースを介してデータに直接アクセスできます。一方、SQL インターフェースは JDBC/ODBC 接続経由で、一般的な SQL (場合によっては ETL スクリプト)に Hive を使用するか、インタラクティブなクエリに Hive 上の Impala または Tez を使用できます。Hadoop は、HBase API や関連するデータソースサービスも提供しています。Hadoop のエコシステムの詳細は、こちらを参照してください。
次に、 Databricks のレイクハウスプラットフォームで、これらのサービスがどのようにマッピングされ、扱われているかについて説明します。まず注目すべき最初の違いは、Databricks 環境では、複数のクラスタを見ていることが挙げられます。各クラスタは、特定のユースケース、特定のプロジェクト、ビジネスユニット、チーム、開発グループなどに使用できます。さらに重要なのは、これらのクラスタは一時的なものとして設計されている点です。ジョブクラスタの場合、クラスタの寿命はワークフロー期間中、継続されます。ワークフローが実行され、完了すると自動的に環境が停止されます。例えば、開発者がコンピューティング環境を共有するインタラクティブなユースケースでは、この環境を始業時に起動し、開発者は一日中コードを実行できます。使用されていない期間は、プラットフォームに組み込まれている(設定可能な)自動終了機能により、Databricks は自動的に環境を停止します。
Hadoop とは異なり、Databricks は Hbase や SOLR のようなデータストレージサービスを提供しません。データは、ファイルストレージや、オブジェクトストレージに存在します。Hbase や SOLR のようなサービスの多くは、代替または同等の技術をクラウドで提供しています。例えば、クラウドネイティブ、あるいは ISV ソリューションなどがあります。
上図のように、Databricks の各クラスタノードは、Spark ドライバまたはワーカーのいずれかに対応しています。ここで重要なのは、それぞれの Databricks クラスタが互いに完全に分離されていることです。これにより、特定のプロジェクトやユースケースにおいて、厳しい SLA を満たすことができます。ストリーミングやリアルタイムのユースケースを、他のバッチ指向のワークロードから�完全に分離できます。また、クラスタのリソースを長時間占有する可能性のある長時間稼働のジョブを手動で分離することを心配する必要もありません。異なるユースケースに対するコンピューティングとして、新しいクラスタを起動するだけでよいのです。Databricks では、ストレージとコンピューティングを切り離し、AWS S3、Azure Blob Storage、Azure Data Lake Store(ADLS)など既存のクラウドストレージの活用も可能です。
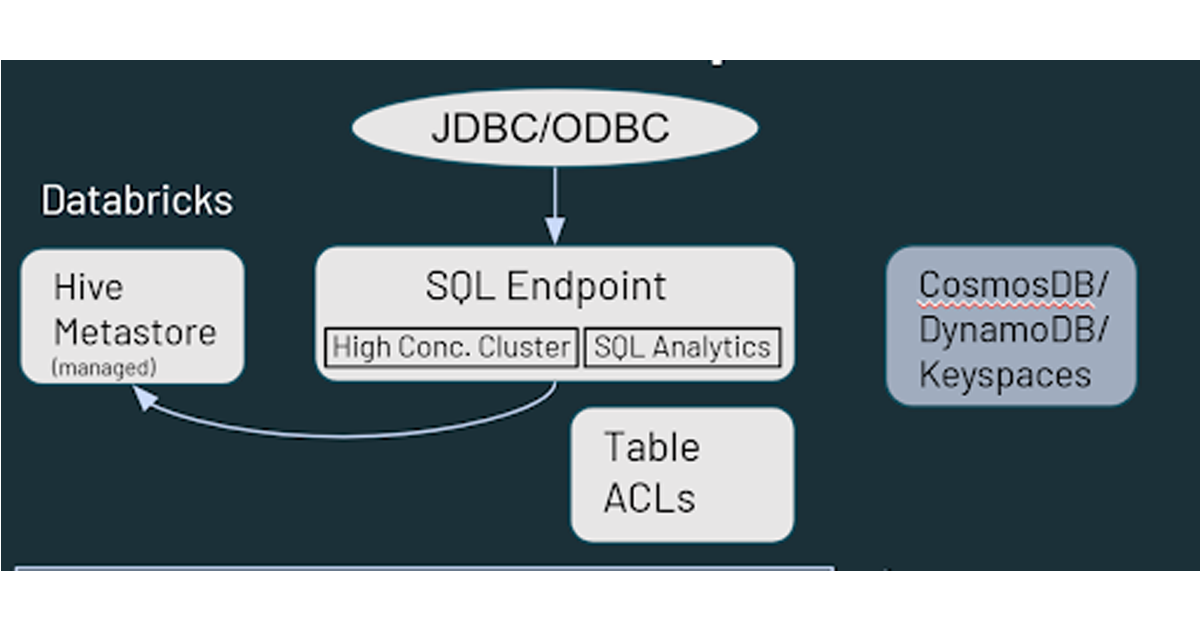
また、Databricks には、デフォルトで管理されている Hive メタストアがあり、クラウドストレージに存在するデータ資産に関する構造化情報を格納しています。AWS Glue、Azure SQL Server、Azure Purview などの外部メタストアの使用もサポートしています。オブジェクトストレージの権限に加え、Databricks 内のテーブル ACL などセキュリティ制御の指定もできます。
データアクセスに関しては、ユーザーがデータをどのように扱うかという点で、Databricks は Hadoop と同様の機能を提供します。クラウドストレージに保存されたデータは、Databricks 環境では複数のパスを経由してアクセスできます。ユーザーは、SQL Endpoints や Databricks SQL を使って、インタラクティブなクエリや分析を行うことができます。また、クラウドストレージに保存されたデータに対して、データエンジニアリングや機械学習のケイパビリティのための Databricks の Notebook を使用することもできます。Hadoop の Hbase は、Azure CosmosDB、または AWS DynamoDB/Keyspaces にマッピングされ、ダウンストリームアプリケーションのサービングレイヤーとして活用できます。
ステップ 2:データの移行
Hadoop の使用経験者であれば、 HDFS をご存知と思います。HDFS は、Hadoop 導入時に使用されるストレージファイルシステムで、Hadoop クラスタのノード上のディスクを利用します。そのため、HDFSをスケールする場合、クラスター全体に容量を追加する必要があります(つまり、コンピュートとストレージを一緒にスケーリングする必要があります)。その際に、追加のハードウェアを調達して設置するのは、多くの時間と労力を要します。
クラウドでは、AWS S3、Azure Data Lake Storage や Blob Storage、Google Storage などのクラウドストレージという形で、ほぼ無限のストレージ容量を持つことができます。メンテナンスやヘルスチェックの必要がなく、導入した瞬間から内蔵の冗長性、高レベルの耐久性と可用性を実現します。データの移行にはネイティブクラウドサービスの利用を推奨しており、容易な移行を可能にするいくつかのパートナー/ISVが存在します。
では、どうやってスタートするか?最も一般的に推奨される方法は、デュアル取り込み戦略 (つまり、オンプレミス環境に加えて、データをクラウド ストレージにアップロードするフィードを追加すること) です。これにより、既存のセットアップに影響を与えることなく、新たなデータを活用した新規のユースケースをクラウドで開始できます。組織内の他のグループからの賛同を得たい場合、手始めのバックアップ戦略として位置づけることができます。HDFS は従来、その規模と労力からバックアップが課題でした。そのため、クラウドにデータをバックアップすることは、いずれにせよ生産性の高い取り組みとなります。
ほとんどの場合、既存のデータ配信ツールを活用してフィードを分岐し、Hadoop だけでなくクラウドストレージにも書き込むことができます。例えば、Informatica や Talend などのツール/フレームワークを使用してデータを処理し、Hadoop に書き込んでいる場合、追加のステップを加えれば、容易にクラウドストレージに書き込み可能です。クラウドにデータを移行できれば、そのデータを扱う方法は多数あります。
データの方向性としては、オンプレミスからクラウドにプルするか、オンプレミスからクラウドにプッシュするかのどちらかです。データをクラウドにプッシュするために活用できるツールとして、社内フレームワークに加え、クラウドネイティブソリューション(Azure Data Box、AWS Snow Family など)、DistCP(Hadoop ツール)、その他のサードパーティ製ツールがあります。セキュリティチームから必要な承認を得るという点では、プッシュ型の方が容易です。
クラウドにデータをプルするには、 Spark/Kafka Streaming、またはクラウドからトリガーされる バッチ取り込みパイプラインを使用できます。バッチの場合は、ファイルを直接取り込むか、JDBC コネクタを使って関連のアップストリーム技術のプラットフォームに接続し、データを引き出すことができます。サードパーティ製のツールも利用可能です。プッシュ型のオプションは、広く受け入れられ、理解されているので、ここではプル型のアプローチについて少し掘り下げてみましょう。
まず必要なのは、オンプレミス環境とクラウドとの接続の設定です。これは、インターネット接続とゲートウェイがあれば実現できます。AWS Direct Connect、Azure ExpressRoute などの専用接続オプションも活用できます。組織でクラウドの利用実績がある場合は、すでにセットアップが完了している可能性があるため、Hadoop 移行プロジェクトで再利用できます。
Hadoop 環境でのセキュリティも検討すべき事項です。Kerberos (ケルベロス)対応の環境であれば、Databricks 側からの対応が可能です。クラスタ起動時に実行される Databricks の初期化スクリプトの設定、必要な Kerberos クライアントのインストールと設定、クラウドストレージの場所に保存されている krb5.conf と keytab ファイルへのアクセスを行い、最終的に kinit() 関数を実行することで、Databricks クラスタが Hadoop 環境と直接やり取りできるようになります。
最後に、外部の共有メタストアも必要になります。Databricks にはデフォルトでメタストアサービスが導入されていますが、外部メタストアの使用もサポートしています。外部メタストアは、Hadoop と Databricks で共有され、オンプレミス(Hadoop 環境内)、またはクラウドのいずれかに導入できます。例えば、Hadoop で実行されている既存の ETL プロセスがあり、それらをまだ Databricks に移行できない場合、既存のオンプレミスのメタストアでこのセットアップを活用して、Hadoop から最終キュレート済みのデータセットを Databricks で処理させることができます。
ステップ 3:データ処理
データ処理について留意すべき点は、Databricks にある全ての機能が Apache Spark を活用していることです。MapReduce、Pig、Hive QL、Java などのすべての Hadoop プログラミング言語は、Pyspark、Scala、Spark SQL、さらには R を介して、Spark で実行するように変換で�きます。コードとIDEに関しては、Apache ZeppelinとJupyterノートブックの両方をDatabricksノートブックに変換できますが、Jupyterノートブックをインポートする方が少し簡単です。Zeppelin Notebook は、インポートする前に Jupyter または Ipython に変換する必要があります。データサイエンスチームが Zeppelin や Jupyter でコードを書き続ける場合は、Databricks Connect を利用できます。これにより、ローカルの IDE(Jupyter、Zeppelin、あるいは IntelliJ、VScode、RStudio など)を活用して Databricks 上でコードを実行できます。
Apache Spark™ のジョブを移行する際、最も考慮すべき点は Spark のバージョンです。オンプレミスの Hadoop クラスタでは古いバージョンの Spark が稼働している可能性がありますが、Spark 移行ガイドを使用すれば、変更履歴を調べ、コードへの影響を確認できます。もう 1 つ考慮すべき点は、RDD にデータフレームに変換することです。RDD は Spark 2.x まではよく使われており、Spark 3.x でも使うことはできますが、その場合、Spark オプティマイザの機能を十分に活用できなくなる可能性があります。可能な限り RDD をデータフレームに変換することをお勧めします。
また、移行の際によくある問題の 1 つとして、リファレンスがローカルの Hadoop 環境にハードコードされている点があります。もちろん、これらの更新が必要です。更新しないと、新たな設定ではコードが壊れてしまいます。
次に、Spark 以外のワークロードの変換についてです。ほとんどの場合、コードの書き換えが必要です。MapReduceでは、Java ライブラリの形で共有ロジックを使用していれば、そのコードを Spark で活用できる場合があります。ただし、MapReduce ではなく Spark 環境で実行するには、コードの一部の書き換えが必要な場合があります。新しい環境では JDBC ソースを使って、(MapReduce コマンドではなく) Spark コマンドのセットを実行することになるので、Sqoop は比較的容易に移行できます。Spark のコードでは、Sqoop と同じ方法でパラメータを指定できます。Flume では、Kafka からデータを処理したり、HDFS に書き込んだりするユースケースが多いようです。これは、Spark ストリーミングを使って容易に実現できるタスクです。Flume を移行する際の主な作業は、構成ファイルベースのアプローチを Sparkのもっとプログラム的なアプローチに変換することです。最後に Nifi ですが、これは主に Hadoop 以外で使用され、ドラッグ&ドロップでセルフサービスのインジェストツールとして使用されています。Nifi はクラウドでも活用できますが、多くのお客様がクラウドへの移行を機に、クラウドで利用できる他の新たなツールに Nifi を置き換えています。
HiveQL の移行は、おそらく最も容易な作業です。Hive と Spark SQL の間には高い互換性があり、ほとんどのクエリはそのまま Spark SQL で実行できるはずです。HiveQL と Spark SQL の DDL には、いくつかマイナーな違いがあり、一例は、HiveQL の "FORMAT" 句に対して Spark SQL では "USING" 句を使用することです。コードをSpark SQL 形式に変更することをお勧めします。これにより、オプティマイザが Databricks 内のコードに対して最適な実行プランを準備できます。Hive SerDe や UDF を活用できるので、HiveQL を Databricks に移行する際には、さらに容易になります。
ワークフローのオーケストレーションに関しては、ジョブのサブミットの方法が変わる可能性を考慮する必要があります。Spark のサブミットセマンティクスを引き続き利用することもできますが、より高速でシームレスに統合されたオプションもあります。Databricks のジョブや Delta Live Tables をコードフリーの ETL として活用して Oozie のジョブを置き換え、 Databricks 内でエンドツーエンドのデータパイプラインを定義することができます。外部処理に依存するワークフローの場合、自動化やスケジューリングのために、Apache Airflow や Azure Data Factory などの技術で同等のワークフロー/パイプラインを作成する必要があります。Databricks の REST API を使えば、ほぼ全てのスケジューリングプラットフォームを統合し、Databricks と連携するように設定できます。
また、Hadoop から Databricks へのワークロードの移行を支援する KnowledgeLens 社が作成したMLens という自動化ツールもあります。MLens は PySpark コードと HiveQL の移行をサポートします。Hive の仕様の一部を Spark SQL に変換し、Spark SQL オプティマイザの機能とパフォーマンスの利点をフルに活用することも可能です。また、Oozie のワークフローを Airflow や Azure Data Factory などへの移行することも、近々サポートが予定されています。
ステップ 4:セキュリティとガバナンス
次に、セキュリティとガバナンスについて説明します。Hadoop の世界では、Ambari や Cloudera Manager、あるいは Impala や Solr などの管理コンソールに接続するための LDAP 統合があります。また、Hadoop には、他のサービスとの認証に使用される Kerberos があります。認証の観点からは、Ranger と Sentry がよく使われるツールです。
Databricks では、SAML 2.0 をサポートする全ての ID プロバイダとシングルサインオン(SSO)の統合が可能です。これには、Azure Active Directory、Google Workspace SSO、AWS SSO、および Microsoft Active Directory が含まれます。認証については、Databricks は Databricks オブジェクトの ACL (Access Control Lists)を提供しており、Notebook、ジョブ、クラスタなどのエンティティに権限を設定できます。データの権限やアクセス制御については、テーブル ACL やビューを定義して列や行のアクセスを制限したり、認証のパススルーなどを活用して、ワークスペースのログイン認証情報をストレージレイヤー(S3、ADLS、Blob ストレージ)に渡して、データへのアクセスが許可されているかどうかを判断できます。属性ベースの制御やデータマスキングなどの機能が必要な場合は、Immuta や Privacera などのパートナーツールを利用できます。また、エンタープライズガバナンスの観点からは、AWS Glue、Informatica Data Catalog、Alation、Collibra などの企業データカタログに Databricks を接続可能です。
ステップ 5:SQL および BI レイヤー
Hadoop では、前述のとおり、ETL やアドホックなクエリや分析を行うためのインターフェースとして Hive や Impala があります。Databricksでは、Databricks SQL で同様のケイパビリティが利用できます。また、Databricks SQL は、Delta エンジンによる優れたパフォーマンスに加え、自動スケーリングクラスタによる高度な並列処��理を必要とするユースケースをサポートしています。Delta エンジンには Photon も含まれており、これは C++ でゼロから作られた新しい MPP エンジンであり、データレベルと命令レベルの両方の並列性を利用するためにベクトル化されています。
Databricks は、Tableau、PowerBI、Qlik、Looker などの BI ツールとのネイティブな統合に加え、それらのツールで活用できる高度に最適化された JDBC/ODBC コネクタを提供します。新たな JDBC/ODBC ドライバは、オーバーヘッドが非常に小さく(1/4 秒)、Apache Arrow を使用した場合には転送速度が 50% 向上し、また、いくつかのメタデータ操作では、大幅に高速なメタデータ検索操作をサポートしています。Databricks では、 PowerBI の SSO をサポートしており、他の BI/ダッシュボードツールとの SSO のサポートも近日中に開始予定です。
Databricks は、前述した Notebook エクスペリエンスに加え、SQL UX を提供します。SQL ユーザーに SQL ワークベンチへの独自の視点を提供し、簡単なダッシュボードやアラート機能も備えています。これにより、データレイク内のデータをデータウェアハウスなどのプラットフォームにダウンストリームで移動させることなく、SQL ベースのデータ変換や探索的な分析が可能になります。
ガートナー®: Databricks、クラウドデータベースのリーダー

次のステップ
以下は、レイクハウスアーキテクチャのような最新のクラウドアーキテクチャへの移行プロセスを考えるうえで、覚えておくべき点です。
- 主要なビジネスステークホルダーとの連携を忘れないでください。この移行は、技術的な決定であると同時に経営面での決定でもあり、ビジネスのステークホルダーがこのプロセスとその最終状態に賛同する必要があります。
- Databricks やパートナー企業が支援します。再現可能なベストプラクティスを構築した経験豊富なエキスパートが、組織の時間、費用、リソースを節約し、全体的なストレスの軽減を支援します。
- Hadoop から Databricksへの移行を開始するためのステップバイステップのガイドや Notebook、コードが記載された技術移行ガイド「Hadoop to Databricks Technical Migration guide」は、こちらから入手できます。
Hadoop からの移行により、Databricks がどのようにしてビジネス価値を向上させるのかを、databricks.com/migration でご覧いただき、移行計画を開始してください。
