Databricks で構築するエンドツーエンドの深層学習パイプライン

深層学習(DL)モデルは、金融サービスにおける不正検知、メディアにおけるパーソナライゼーション、ヘルスケアにおける画像認識など、あらゆる業界のユースケースに適用されています。このような応用範囲の拡大により、深層学習技術の使用は、ほんの数年前に比べてはるかに容易になっています。TensorFlow や Pytorch などよく使用される深層学習フレームワークは、精度の高いパフォーマンスを発揮できるまでに成熟しています。マネージド MLflow を備えた Databricks のレイクハウスプラットフォームのような機械学習(ML)環境では、Horovod や Pandas UDF などのツールを使用した深層学習の分散実行が非常に容易になりました。
課題
現在でも引き続き残っている主要な課題の 1 つは、制御・再現可能な方法で深層学習の機械学習パイプラインを自動化し、運用を最適化することです。Kubeflow のような技術はソリューションを提供していますが、多くの場合、深い専門知識を必要とし、利用可能なマネージドサービスもほとんどないため、エンジニアによる複雑な環境の管理が必要になります。データと分析プラットフォーム自体に、深層学習パイプラインの管理を統合することができれば、もっとシンプルになるはずです。
This blog post will outline how to easily manage DL pipelines within the Databricks environment by utilizing Databricks Jobs Orchestration, which is currently a public preview feature. Jobs Orchestration makes managing multi-step ML pipelines, including deep learning pipelines, easy to build, test and run on a set schedule. Please note that all code is available in this GitHub repo. For instructions on how to access it, please see the final section of this blog.
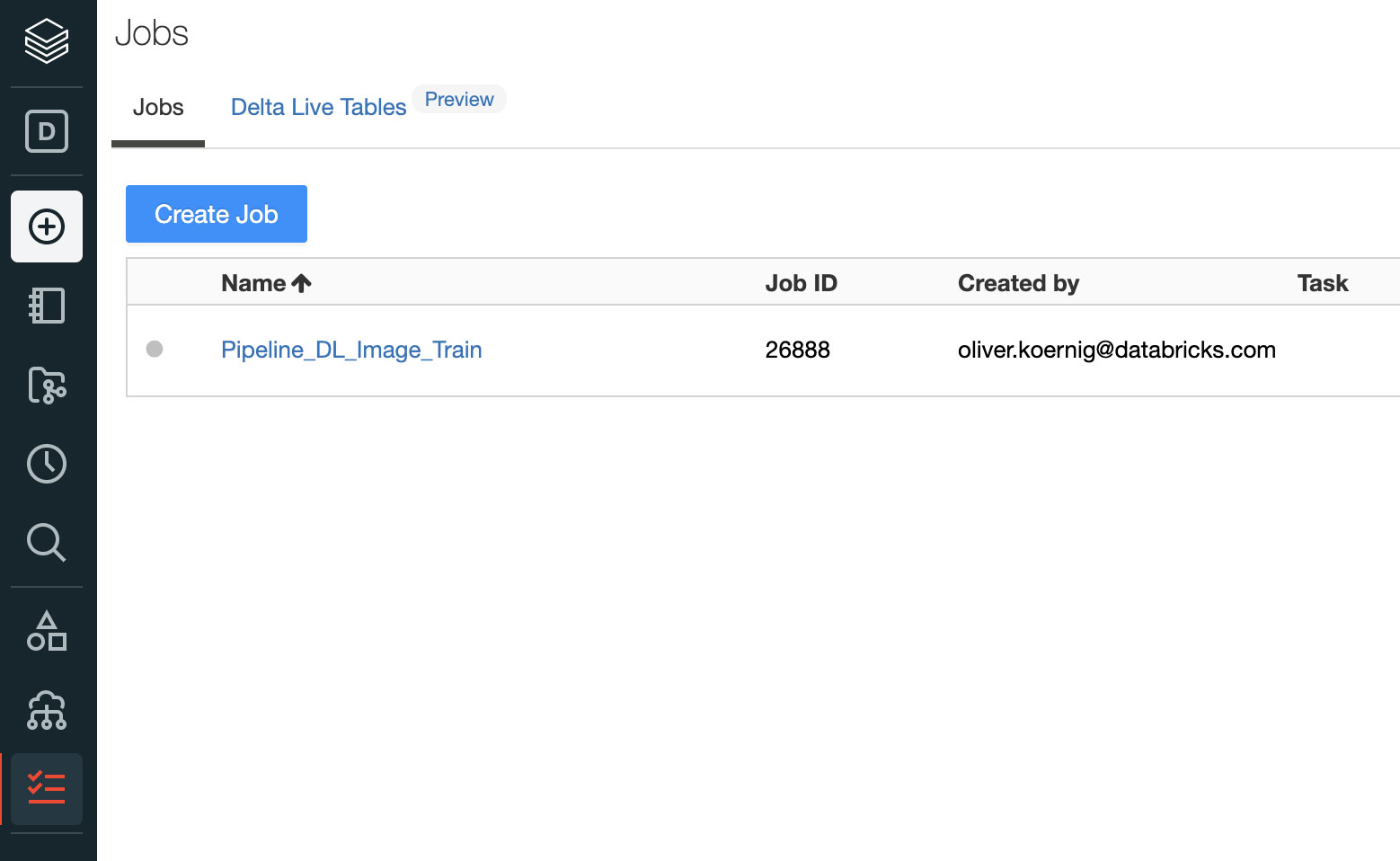
リアルワールドのビジネスに�おけるユースケースを見てみましょう。CoolFundCo は、投資会社(架空)です。コンテンツを分類するために、日々何万枚もの画像を分析し、その画像が何を表しているかを特定しています。CoolFundCo では、この手法をさまざまな形で活用しています。例えば、全国のショッピングモールの写真を分析し、短期的な経済動向を把握します。そして、これを投資のための 1 つのデータポイントとしています。CoolFundCo のデータサイエンティストと ML エンジニアは、このプロセスの管理に多大な時間と労力を費やしていました。CoolFundCo は既存の画像を大量にストックしており、毎日新たな画像が大量にクラウドのオブジェクトストレージに送られてきます。この例では Microsoft Azure Data Lake Storage(ADLS)を想定していますが、 AWS S3 や Google Cloud Storage(GCS)でも同様です。
このプロセスの管理は極めて困難です。エンジニアは日々、画像をコピーし、深層学習モデルを実行して画像のカテゴリーを予測し、モデルの出力を CSV ファイルに保存して結果を共有します。画像認識の品質を維持するためには、深層学習モデルの検証と再トレーニングを定期的に行う必要がありますが、これもチーム内の開発環境で手作業で行っていました。このような場合、基礎となる ML モデルの最新かつ最良のバージョンや、現在のプロダクションモデルのトレーニングにどの画像を使用したかを把握できなくなることがよくあります。パイプラインの実行は外部ツールで行われるため、エンドツーエンドのフローを制御するためには異なる環境を管理しなければなりません。
ソリューション
この煩雑な状況を整理すべく CoolFundCo は、プロセスを自動化するために Databricks を導入しました。まず最初に行ったのは、トレーニングとスコアリングのワークフローにプロセスを分離することです。
トレーニングのワークフローでは、以下が必要となります。
- ラベル付き画像をクラウドストレージから一元管理されたレイクハウスに取り込む
- 既存のラベル付き画像を使用して機械学習モデルをトレーニングする
- 新たにトレーニングしたモデルを一元管理されたリポジトリに登録する
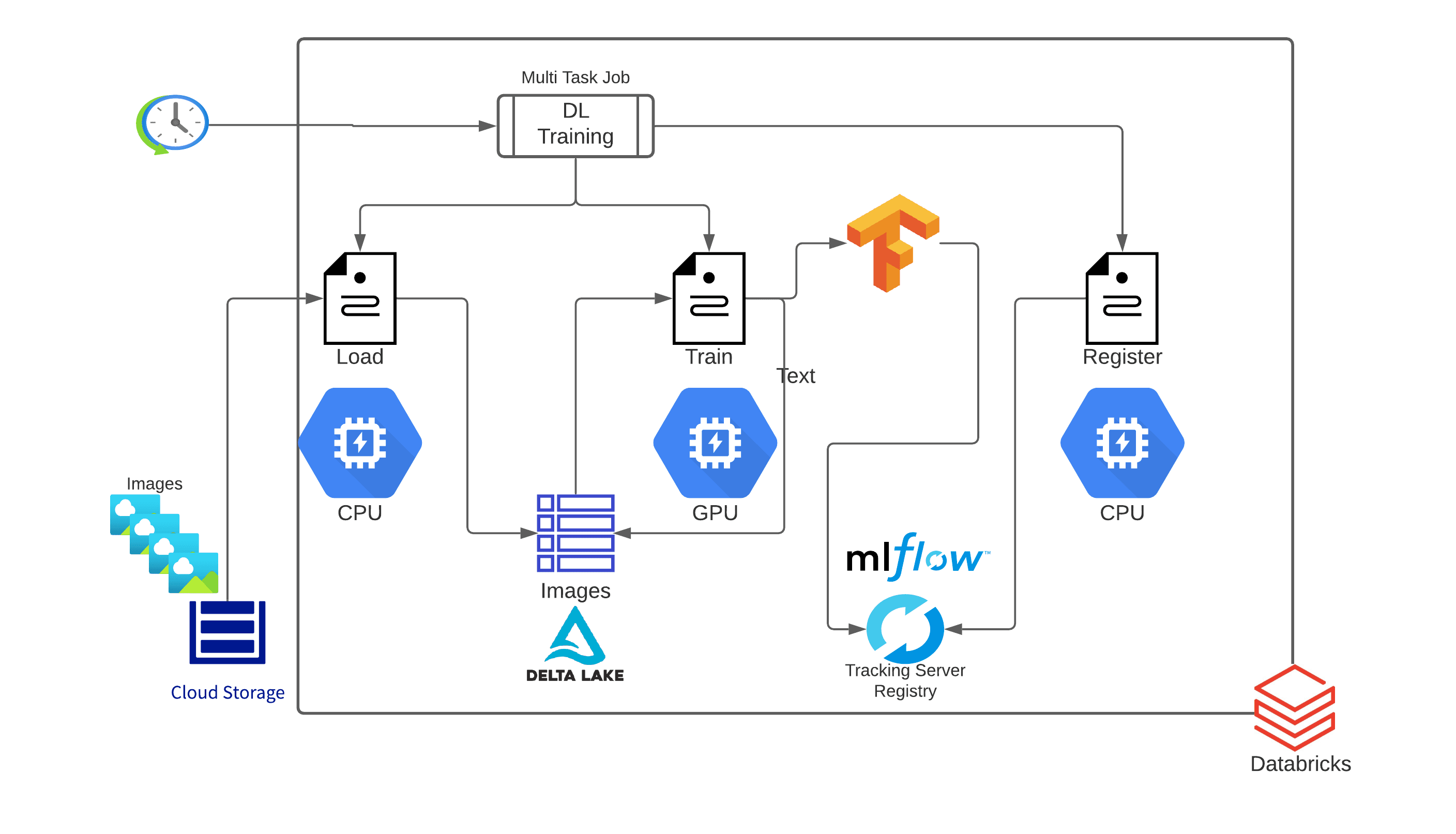
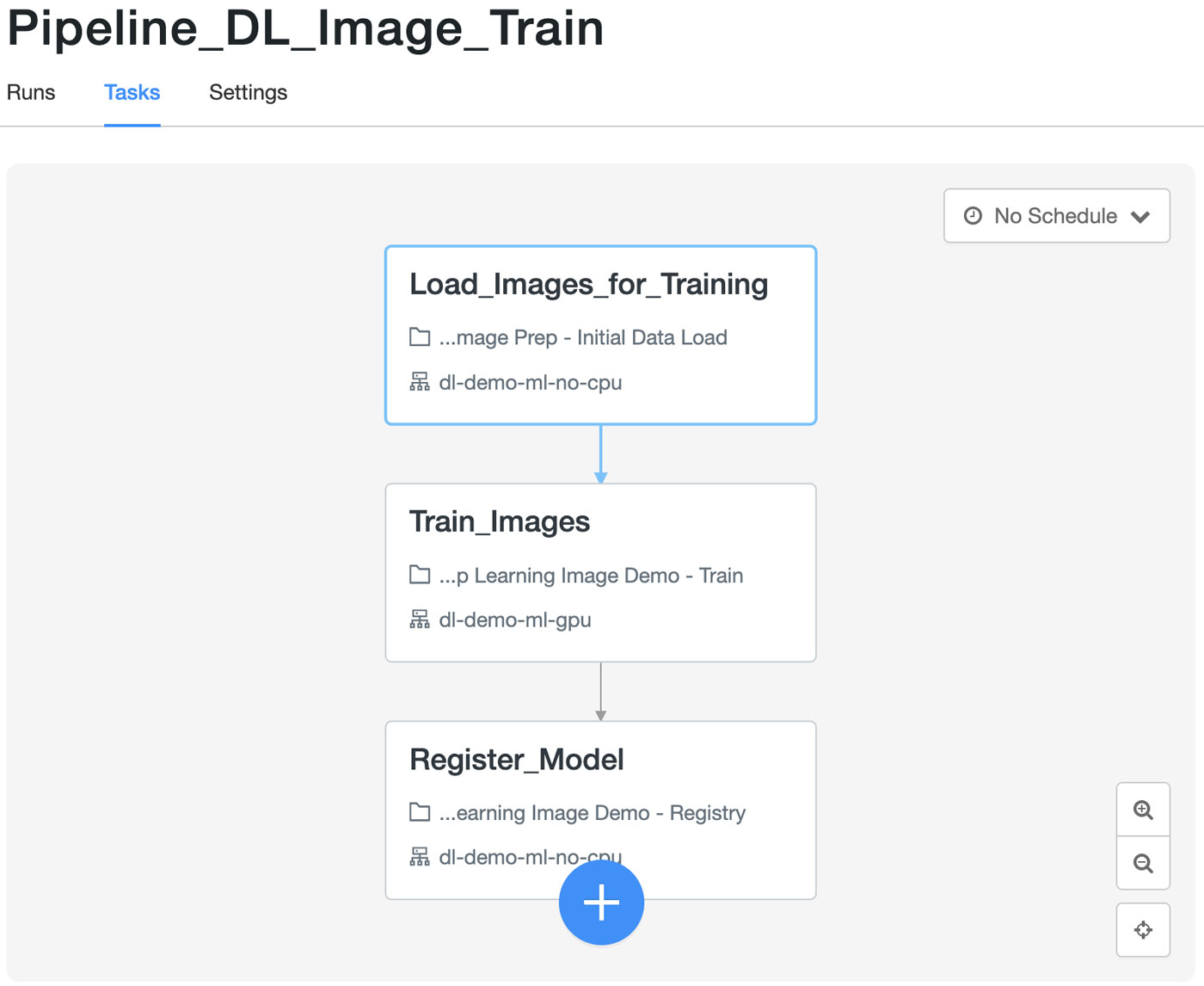
それぞれのワークフローは、望ましい結果を得るための一連のタスクで構成されています。各タスクは異なるツールや機能を使用するため、異なるリソース構成(クラスタサイズ、インスタンスタイプ、CPU か GPU など)が必要になります。CoolFundCo では、これらのタスクをそれぞれ別の Databricks Notebook として実装することにしました。解像度のアーキテクチャは、図 2 に示されています。
スコアリングのワークフローは、以下のステップで構成されています。
- 新たな画像をクラウドストレージから一元管理されたレイクハウスに取り込む
- リポジトリの最新モデルを使って、各画像をできるだけ早くスコアリングを実行する
- スコアリング結果を一元管理されたレイクハウスに格納する
- 画像のサブセットを手動のラベリングサービスに送り、精度を検証する
深層学習トレーニングパイプライン
次に、トレーニングパイプラインの各タスクを見ていきましょう。
-
ラベル付き画像をクラウドストレージから一元化されたデータレイクに取り込む
[望ましいインフラ:大規模 CPU クラスタ]
このプロセスの最初のステップは、モデルトレーニングに使用可能な形式で画像データを読み込むことです。あらゆるトレーニングデータ(新たな画像)の読み込みには、Databricks オートローダを使用しています。Databricks オートローダは、クラウドストレージに入る新たなデータファイルを段階的かつ効率的に処理します。オートローダ機能はデータ管理に役立ち、継続的に送られてくる新たな画像を自動処理します。CoolFundCo のチームは、オートローダの「トリガーワンス(trigger once)」機能を活用することにしました。これにより、オートローダのストリーミングジョブが開始され、最後にトレーニングジョブが実行された後の新たな画像ファイルを検出し、新規ファイルのみを読み込んで、ストリームをオフにできます。Apache Spark™ の binaryFile リーダーを利用して全ての画像を読み込み、ファイル名からラベルを解析して、それを独自のカラムとして保存しています。binaryFile リーダーは、各画像ファイルを、未加工のコンテンツおよびファイルのメタデータを含む DataFrame の単一レコードに変換します。DataFrame には以下の列があります。
- パス(StringType):ファイルのパス
- modificationTime(TimestampType):ファイルの更新時刻。一部の Hadoop ファイルシステムの実装では、このパラメータが使用できない場合があり、その場合はデフォルト値が設定されます。
- length(LongType):ファイルの長さ(バイト単位)
- コンテンツ(BinaryType):ファイルの内容
次に、全てのデータを Delta Lake のテーブルに書き込み、残りのトレーニングやスコアリングのパイプラインを介して、アクセスおよび更新できるようにします。Delta Lake は、データレイクに信頼性、スケーラビリティ、セキュリティ、パフォーマンスをもたらし、標準的な SQL クエリを使用してデータウェアハウスと同様のアクセスを可能にします。そのため、このようなアーキテクチャはレイクハウスとも呼ばれます。Delta テーブルでは、自動的にバージョン管理が追加されるので、テーブ�ルが更新されるたびに、新たなバージョンにどの画像が追加されたののかが表示されます。
-
既存のラベル付き画像を使用して機械学習モデルをトレーニングする
[望ましいインフラ:GPU クラスタ]
この 2 つ目のステップでは、事前にラベル付けしたデータを使用してモデルをトレーニングします。また、オープンソースのデータアクセスライブラリである Petastorm を利用することで、Parquet ファイルや Spark DataFrames から直接、深層学習モデルのトレーニングができます。画像の Delta テーブルを直接 Spark データフレームに読み込み、各画像を正しい形とフォーマットに処理した後、Petastorm の Spark コンバータを使ってモデルの入力特徴量を生成します。
深層学習のトレーニングをスケーリングするために、チームでは、単一の大規模な GPU だけでなく、GPU のクラスタの活用を考えています。Databricks では、HorovodRunner をインポートして使用するだけで、この作業を行うことができます。これは、Uber の Horovod フレームワークを使用して Spark Cluster 上で分散型深層学習ワークロードを実行するための一般的な API です。
MLflow を活用することで、ハイパーパラメータ、トレーニング期間、損失や精度のメト��リクス、モデルのアーティファクトそのものから MLflow の実験結果まで、モデルのトレーニングプロセス全体を追跡することができます。MLflow API は、Spark MLlib、Keras、TensorFlow、SKlearn、XGBoost などの一般的な ML ライブラリに対応したオートロギング機能を備えています。この機能は、モデル固有のメトリクス、パラメータ、モデルのアーティファクトを自動的に記録します。Databricks では、Delta のトレーニングデータソースを使用している場合、オートロギングはモデルのトレーニングに使用されているデータのバージョンも追跡するので、元のデータセットでトレーニングを実行しても容易に再現可能です。
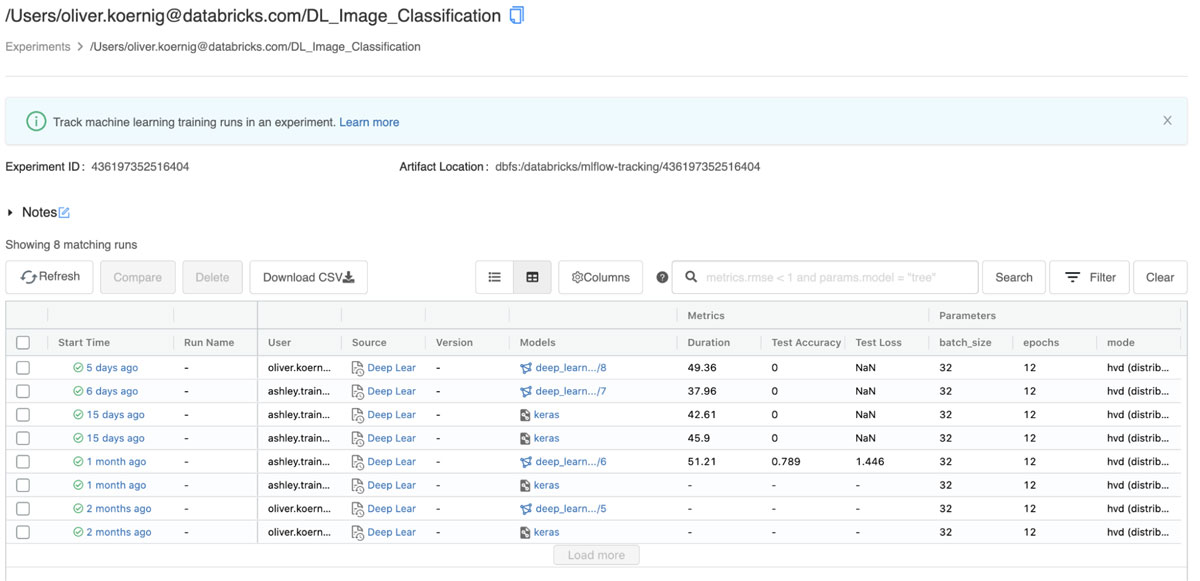
- 新たにトレーニングしたモデルを MLflow レジストリに登録する
[望ましいインフラ:シングルノード CPU クラスタ]
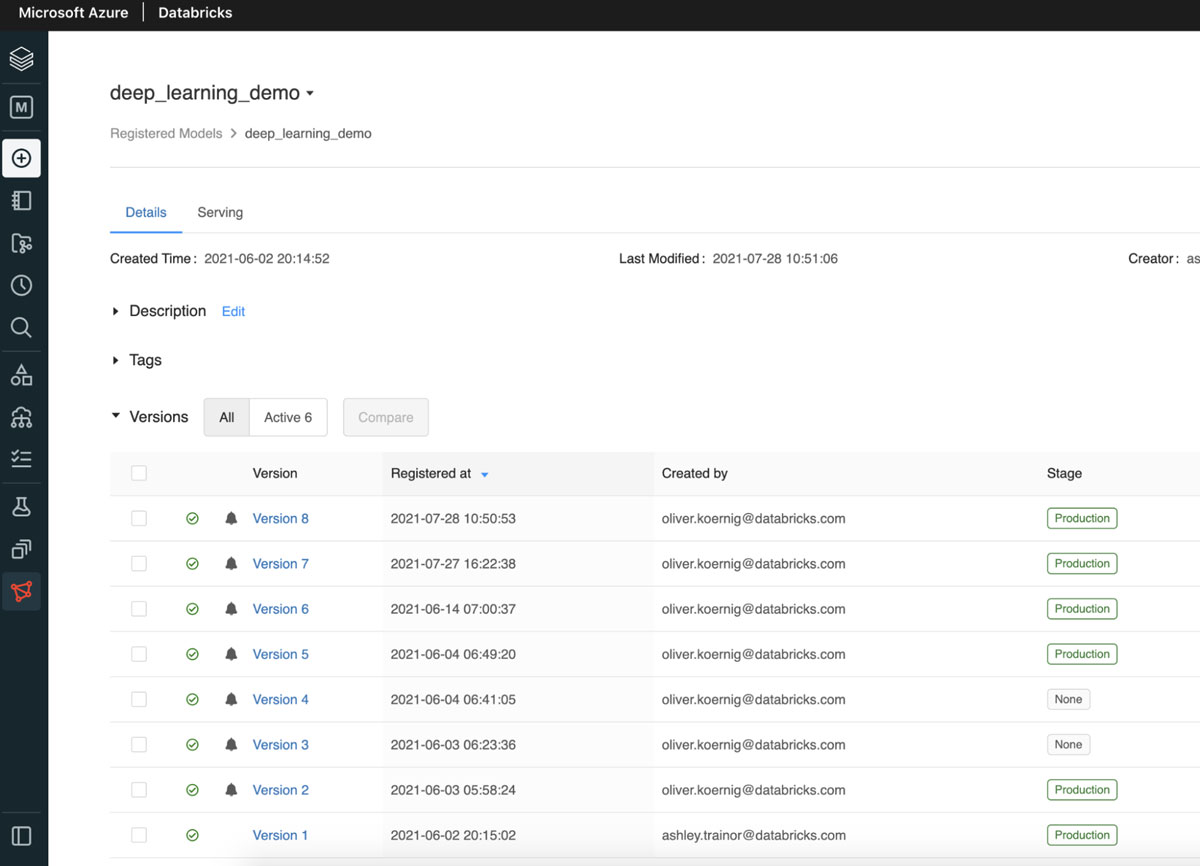
モデルトレーニングパイプラインの最後のステップは、新しくトレーニングされたモデルを Databricks モ��デルレジストリ に登録することです。前のトレーニングステップで保存されたアーティファクトを使って、新たなバージョンの画像分類器を作成することができます。新たなモデルのバージョンからステージング、そして本番環境へとモデルが移行していく中で、モデルのパフォーマンスやスケーラビリティなどを検証できる他のタスクを開発し実行できます。Databricks のモデルの UI には、モデルの最新の状態が表示されます(下記参照)。
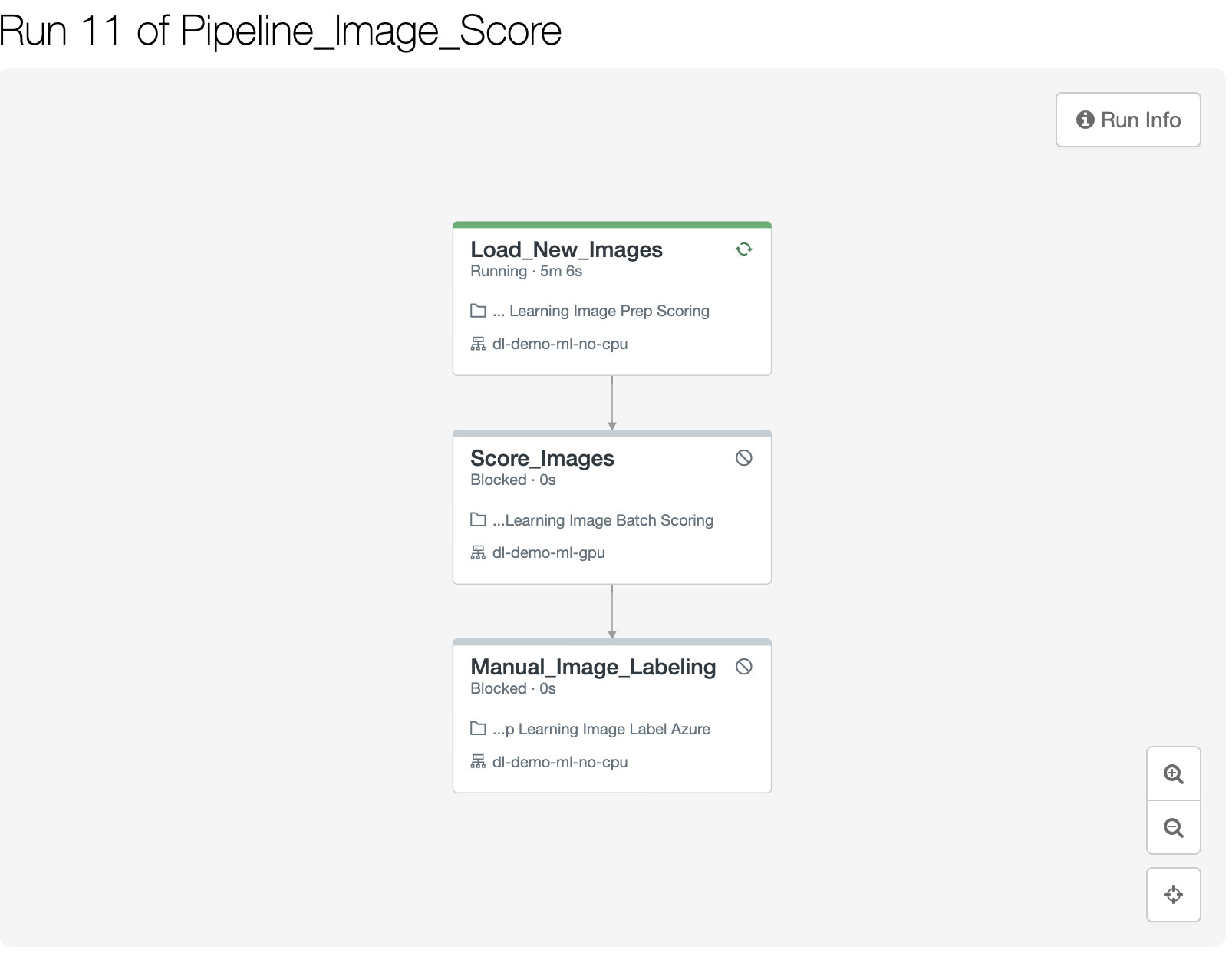
スコアリングパイプライン
次に、CoolFundCo のスコアリングパイプラインのステップを見てみましょう。
-
新たなラベルなし画像をクラウドストレージから一元化されたデータレイクに取り込む [望ましいインフラ:大規模 CPU クラスタ]
スコアリングプロセスの最初のステップは、新たに取り込まれた画像データを、モデルが分類可能なフォーマットに読み込むことです。CoolFundCo のチームは、ここでも新たな画像は全て Databricks オートローダを使用して読み込み、「トリガーワンス」機能を活用することを再度決定しました。これにより、オートローダのストリーミングジョブが開始され、最後にスコアリングジョブが実行された後の新たな画像ファイルを検出し、新たなファイルのみをロードして、ストリームをオフにするできます。将来的には、このジョブを連続したストリームとして実行するように変更することも可能です。その場合、クラウドストレージに取り込まれた新たな画像は、届いた時点でピックアップされ、スコアリングのためにモデルに送信されます。
最後のステップとして、全てのラベルなし画像は Delta Lake テーブルに格納され、残りのスコアリングパイプラインを介して、アクセスおよび更新することができます。
-
新たな画像をスコアリングし、その予測ラベルを Delta テーブルで更新する
[望ましいインフラ:GPU クラスタ]
新たな画像が Delta テーブルに読み込まれると、モデルスコアリング Notebook を実行できます。この Notebook は、テーブルの中でラベルや予測ラベルが付いていない全てのレコード(画像)を受け取り、トレーニングパイプラインで学習された本番環境の分類器モデルを読み込み、そのモデルを使って各画像を分類し、予測ラベルで Delta テーブルを更新します。Delta フォーマットを使用しているので、MERGE INTO コマンドを使用して、テーブル内の新たな予測値を持つ全てのレコードを更新することができます。
-
Azure による手動ラベリングのために画像を送信する
[望ましいインフラ:シングルノード CPU]
CoolFundCo では、 Azure Machine Learning のラベリングサービスを使用して、新たな画像のサブセットに手動でラベルを付けます。具体的には、深層学習モデルが確信的に判断できない画像、つまりラベルの確信度が 95% 未満の画像をサンプリングします。その後、その画像は、Delta テーブルから容易に選択できます。Delta テーブルには、スコアリングパイプラインの結果として、全ての画像、画像メタデータ、ラベル予測が格納されています。その画像は、ラベリングサービスのデータストアとして使用される場所に書き込まれます。ラベリングサービスのインクリメンタルなリフレッシュでは、ラベリングプロジェクトがラベル付けすべき画像を検出し、ラベル付けを行います。ラベリングサービスの出力は、Databricks によって再処理され、Delta テーブルにマージされ、画像のラベルフィールドに入力されます。
ワークフローの展開
トレーニング、スコアリング、ラベリングの各タスク Notebook が正常にテストされたら、本番用のパイプラインに投入できます。これらのパイプラインは、チームが希望するスケジュールに基づいて、トレーニング、スコアリング、ラベリングの各プロセスを一定の間隔(日次、週次、隔週、月次など)で実行します。このような機能の実現には、Databricks の新機能であるジョブオーケストレーションが理想的なソリューションとなります。依存関係のある複数のタスクを含むジョブのシーケンスを確実に予定してトリガーできるからです。各 Notebook はタスクであり、そのトレーニングパイプライン全体は、有向非巡回グラフ(DAG)を作成します。これは、 Apache Airflow のようなオープンソースツールが作成するものと同様のコンセプトですが、エンドツーエンドのプロセス全体が Databricks 環境内に完全に組み込まれているため、これらのプロセスの管理、実行、監視が一元化され容易になるというメリットがあります。
タスクの設定
ワークフローの各ステップや「タスク」には、それぞれ Databricks Notebook とクラスタ構成が割り当てられています。これにより、ワークフローの各ステップを、インスタン��ス数、インスタンスタイプ(メモリ/コンピュートの最適化、CPU/GPU)、プリインストールされたライブラリ、オートスケーリングの設定などを異なるクラスタ上で実行できます。また、個々のタスクにパラメータを設定することも可能です。
ジョブオーケストレーションのパブリックプレビュー機能を使用するには、ワークスペース管理者が Databricks ワークスペースで有効化する必要があります。これは既存の(シングルタスクの)ジョブ機能を置き換えるもので、元に戻すことはできません。そのため、ここまでに定義したシングルタスクジョブとの互換性の問題を確認するために、可能であれば別の Databricks ワークスペースでこの作業を試してみることをお勧めします。
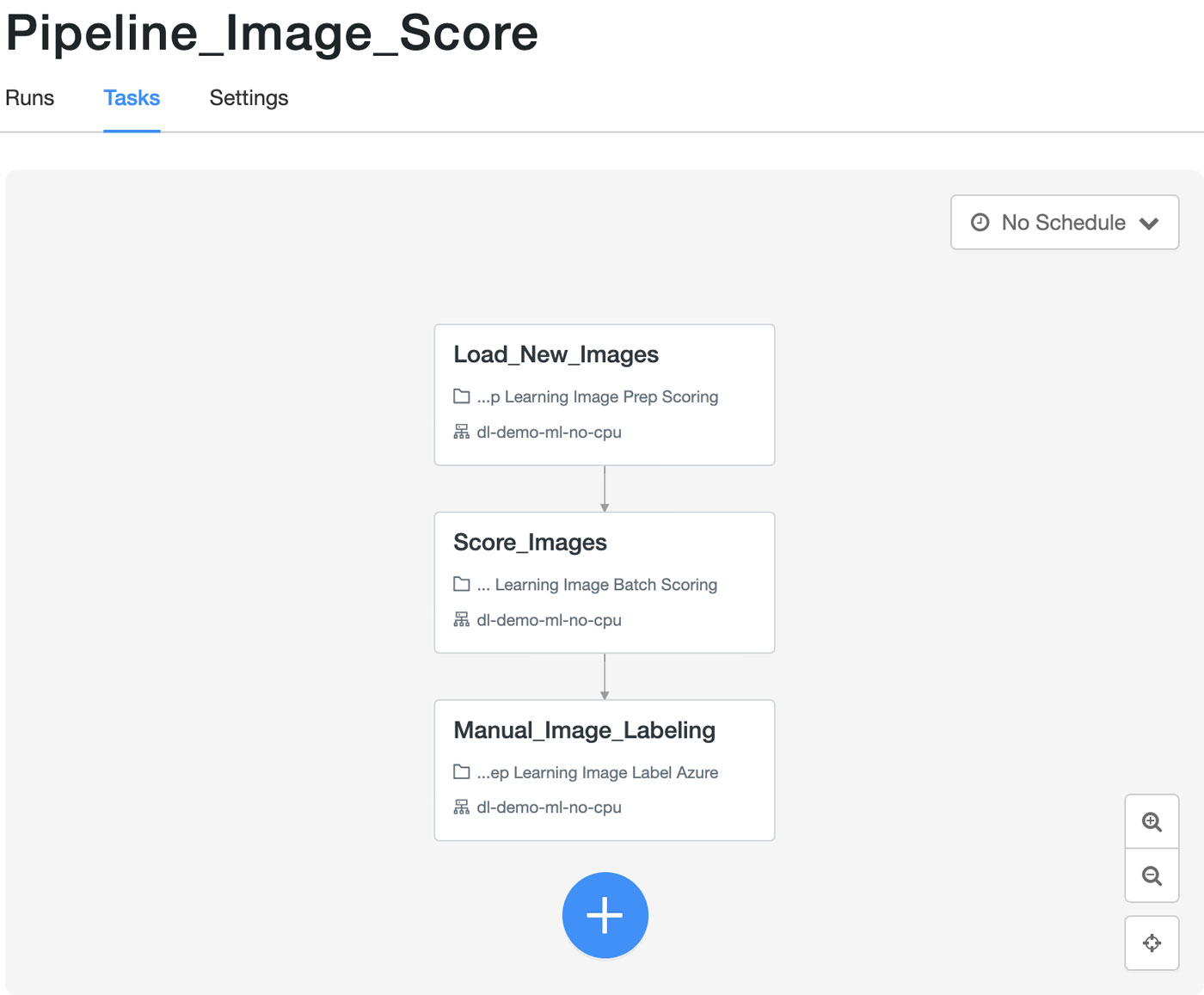
画像スコアリングのワークフローは、日次で実行される独立したジョブオーケストレーションパイプラインです。画像のスコアリングには GPU では十分な効果が得られない可能性があるため、全てのノードで通常の CPU ベースのコンピュートクラスタを使用しています。
最後に、分類の精度をさらに改善し検証するために、スコアリングワークフローは画像のサブセットを選択し、手動の画像ラベリングサービスで利用できるようにします。この例では、Azure ML の手動ラベリングサービスを使用しています。他のクラウドプロバイダも同様のサービスを提供しています。
ジョブオーケストレーションパイプラインの実行とモニタリング
ジョブオーケストレーションパイプラインが実行されると、ユーザーはジョブの表示機能で進捗状況をリアルタイムに確認できます。これにより��、パイプラインが正常に動作しているか、どのくらいの時間が経過したかを容易に確認できます。
ジョブオーケストレーションのパイプラインの管理方法については、オンラインドキュメントを参照してください。
まとめ
Databricks に深層学習パイプラインを導入したことにより、CoolFundCo では主要な課題を解決できました。
- 全ての画像とそのラベルは、一元管理された場所に格納され、エンジニアやデータサイエンティスト、アナリストなどが容易にアクセスできるようになりました。
- モデルの新バージョンや改良版は、中央のリポジトリ(MLflow レジストリ)で管理され、アクセス可能です。どのモデルが適切にテストされているか、どれが最新のモデルか、さらに、どのモデルが本番環境で使用可能かなどの混乱はありません。
- 同一のワークフローであっても、異なるパイプライン(トレーニングとスコアリング)を異なる時間に実行し、異なるコンピューティングリソースを使用することができます。
- Databricks ジョブオーケストレーションを使用することで、パイプラインの実行は同じ Databricks 環境で行われ、スケジュール、監視、管理が容易になりました。
改善された新プロセスを活用することで、データサイエンティストと ML エンジニアは、ML Ops 関連の問題に時間を浪費することなく、注力すべきこと、つまり、深い知見を得ることに集中できるようになりました。
まずはここから
このブログの全てのコードは、以下の GitHub リポジトリにあります。
https://GitHub.com/koernigo/databricks_dl_demo
Databricks Repos 機能を使用すれば、自分のワークスペースに Repos をクローンするだけです。
補足:
このデモで使用されている画像は、Kaggle でアクセスできる Caltech256 データセットに基づいています。データセットは、Databricks ファイルシステム(DBFS)の /tmp/256_ObjectCategories/ に格納されています。Databricks Notebook を使ってデータセットをダウンロードしてインストールする方法の例は、リポジトリにあります。
https://github.com/koernigo/databricks_dl_demo/blob/main/Create%20Sample%20Images.py
リポジトリでは、セットアップ Notebook も用意されています。パイプラインで使用される Delta テーブルの D深層学習が含まれています。また、上記のステップで Kaggle からダウンロードした画像データのサブセットを、別のスコアリングフォルダに分けます。
このフォルダは、DBFS の /tmp/unlabeled_images/256_ObjectCategories/ にあります。ラベルなし画像がモデルによってスコアリングされる必要がある場合に、ラベルなし画像が置かれる場所を表します。
この Notebook は、こちらのリポジトリにあります。
https://github.com/koernigo/databricks_dl_demo/blob/main/setup.py
また、トレーニングジョブとスコアリングジョブも JSON ファイルとしてリポジトリに含まれています。
現在、ジョブオーケストレーション UI では、UI を使用した JSON によるジョブの作成はできません。リポジトリからの JSON を使用する場合は、 Databricks CLI をインストールする必要があります。
CLI のインストールと設定が完了したら、以下の手順で Databricks ワークスペースにジョブを複製してください。
- ローカルにリポジトリをクローンする(コマンドライン)
: git clone https://github.com/koernigo/databricks_dl_demo
cd databricks_dl_demo - GPU と非 GPU(CPU クラスタ)の作成
今回のデモでは、GPU を搭載したクラスタと CPU を搭載したクラスタを使用しています。2 つのクラスタを作成してください。クラスタの仕様例はこちらをご覧ください。
https://github.com/koernigo/databricks_dl_demo/blob/main/dl_demo_cpu.json
https://github.com/koernigo/databricks_dl_demo/blob/main/dl_demo_ml_gpu.json
このクラスタ仕様の一部の機能(ノードタイプなど)は Azure Databricks 固有のものであることにご注意ください。AWS や GCP でコードを実行する場合は、同等の GPU/CPU ノードタイプを使用する必要があります。 - JSON ジョブの仕様を編集する
作成するジョブの JSON 仕様を選択します。例えば、トレーニングパイプライン (https://github.com/koernigo/databricks_dl_demo/blob/main/Pipeline_DL_Image_train.json)などがあります。全てのクラスタのクラスタ ID を、上記のステップで作成したクラスタ(CPU とGPU)に置き換える必要があります。 - Edit the Notebook path
In the existing JSON the repo path is /Repos/[email protected]/… Please find and replace them with the repos path in your workspace (usually /Repos/<your_e_mail_address)/… - Databricks CLI を使用してジョブを作成
databricks jobs create -json-file Pipeline_DL_Image_train.json -profile<お使いの CLI プロファイル名> - ジョブ UI でジョブが正常に作成されたことを確認