Databricks SQL の最新イテレーション、新たな性能、速度改善
Data+AI サミット 2020 Europe で発表した Databricks SQL は、マルチクラウドのレイクハウスアーキテクチャの運用を可能にし、データウェアハウスの性能とデータレイクの経済性を同時に実現します。Databricks では、レイクハウスを活用した知見の抽出および共有を容易にすることを目標に、データアナリスト向けに、最適化された SQL UI や主要な BI ツールの充実したサポート機能を含む、シンプルで使いやすいツールの提供に尽力しています。
Databricks SQL についても同様に、性能、使いやすさ、ガバナンスの向上を目指してイノベーションに日々取り組んでいます。その内容について、複数回のブログを通じてご紹介する予定です。今回は、その第一弾として、以下の各シナリオにおける Databricks SQL の性能の最適化について詳しく解説します。
- 同時実行性の高い分析ワークロード
- インテリジェントなワークロード管理
- 並行性の高い読み取り
- Cloud Fetch によるビジネスインテリジェンス(BI)結果取得の効率化
大規模クエリ以外にも優れた実性能を発揮
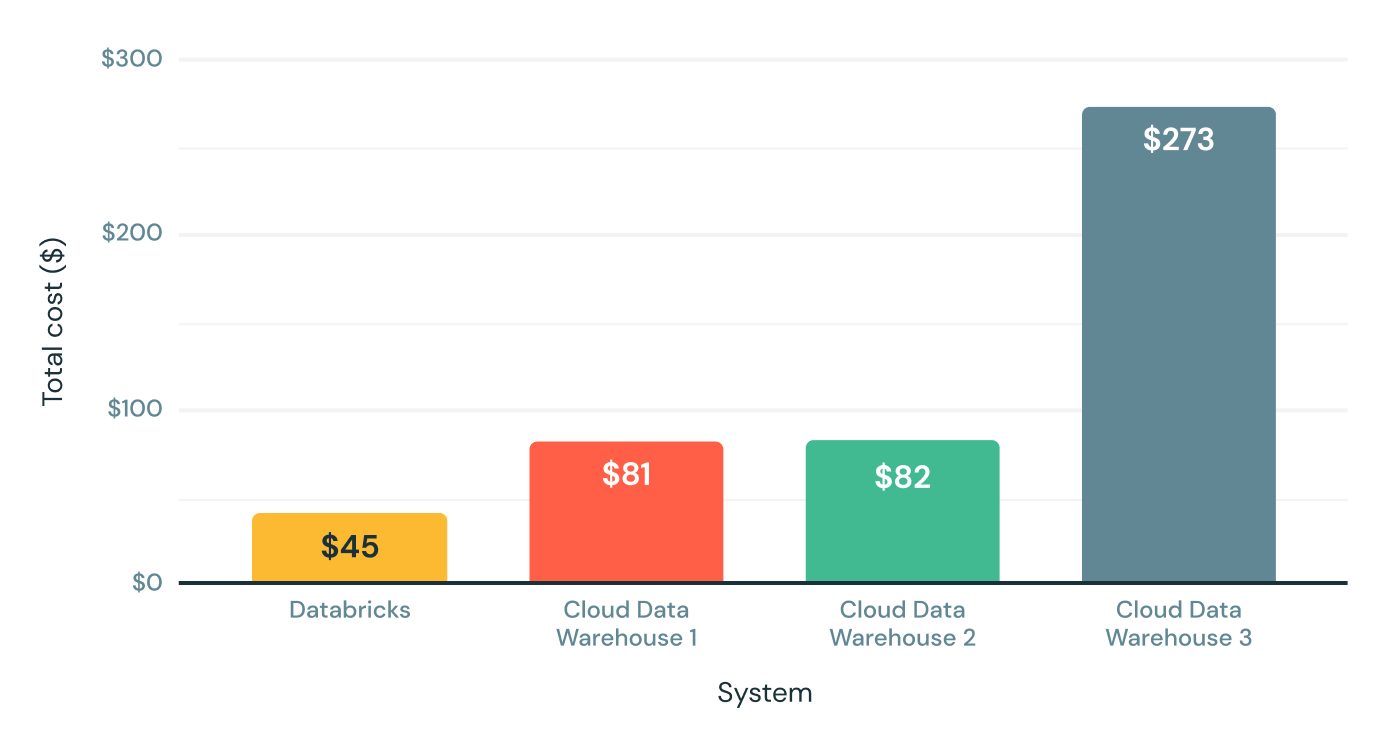
Databricks SQL の初期リリースで��は、大幅な性能アップに成功しました。下図に示すように、従来のクラウド型データウェアハウスと比較して、TPC-DS の 30 TB クラスで最大 6 倍の価格性能を実現しています。TPC-DS は、複数のデータウェアハウスベンダーによって定義された業界標準のベンチマークであることから、私たちはこの結果を極めて喜ばしいと捉えています。
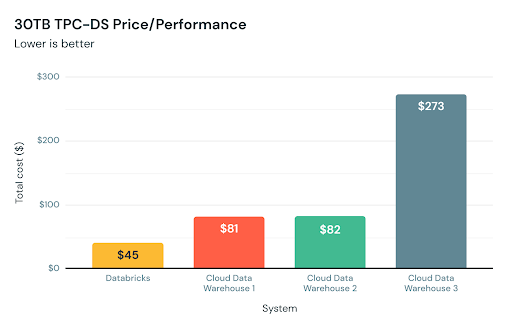
このベンチマーク結果は、ETL ワークロードや深層分析ワークロードなどの大規模なクエリをうまくシミュレートしますが、お客様が実行する全てのクエリをカバーするわけではありません。そのため、私たちは、実際のデータ分析ワークロードや SQL データクエリにおいて、より高速で予測可能な性能を提供できるように、数か月間で数百ものお客様と緊密に連携してきました。
今回、最新の Databricks SQL の正式プレビュー版を公開するにあたり、これまでの成果と性能の向上についてご報告できることをうれしく思います。
シナリオ 1 :同時実行性の高い分析ワークロード
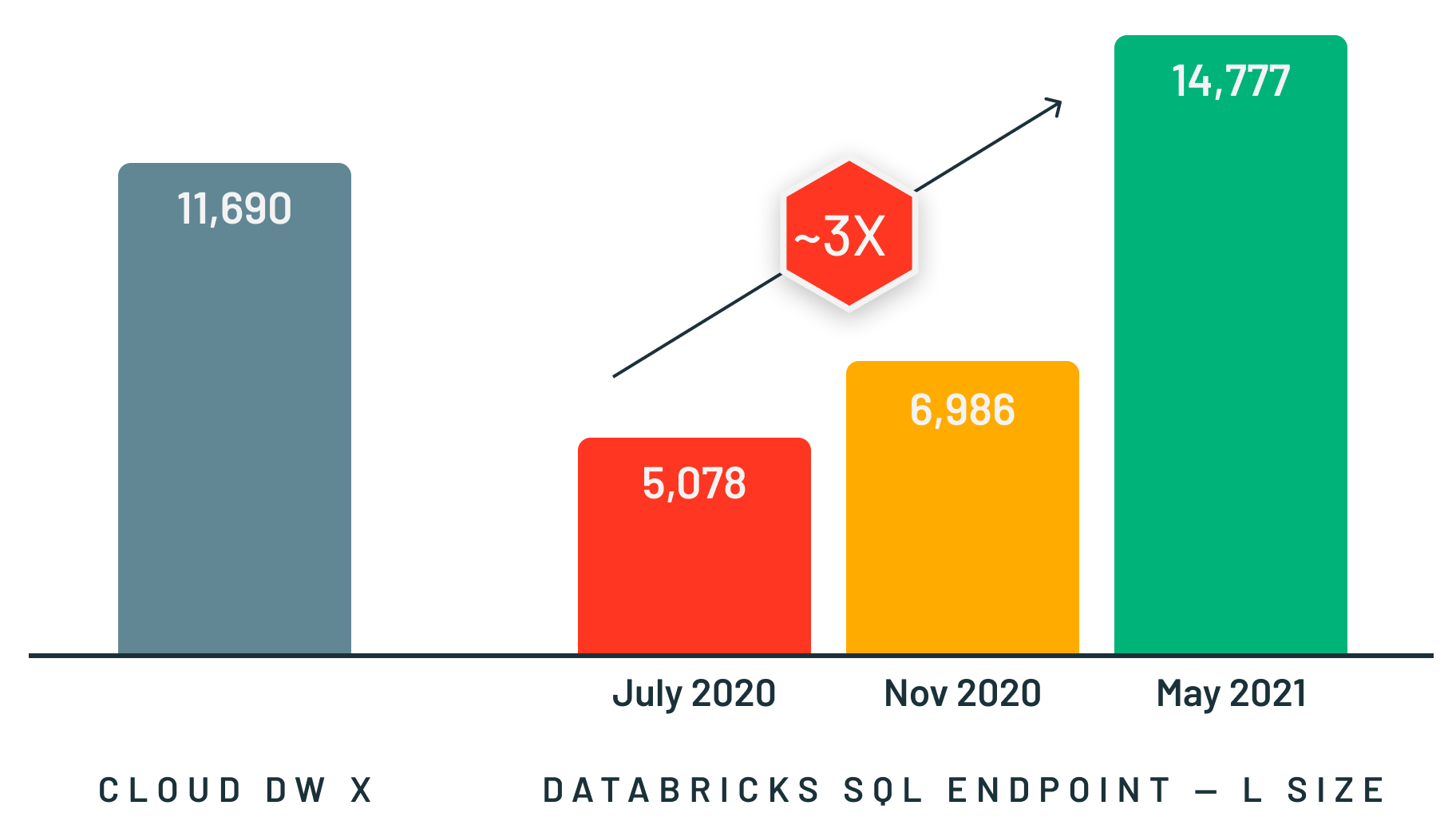
お客様と連携する中で、小規模のデータセットに対して同時実行性の高い分析ワークロードが実行されることが多いことに気づきました。これは、アナリストが通常、フィルターを適用し、過去データよりも最新データを扱う傾向を考えると理にかなっています。私たちは、この一般的なユースケースを高速化することにしました。同時実行性を最適化すべく、小規模のスケールファクター(10 GB)と 32 の同時実行ストリームで、同じ TPC-DS ベンチマークを使用しました。これにより、32 のボットがシステムに継続的にクエリを送信することになります。ボットは休むことなくクエリを実行するため、多くのリアルユーザーを高速にシミュレートできます。
結果を分析してボトルネックを特定、除去するプロセスを何度も繰り返しました。数百もの最適化を行った結果、同時実行性が 3 倍向上しました。Databricks SQL は現在、大規模なクエリとユーザーの多い小規模なクエリの両方で、他の優れたクラウドデータウェアハウスを凌駕しています。
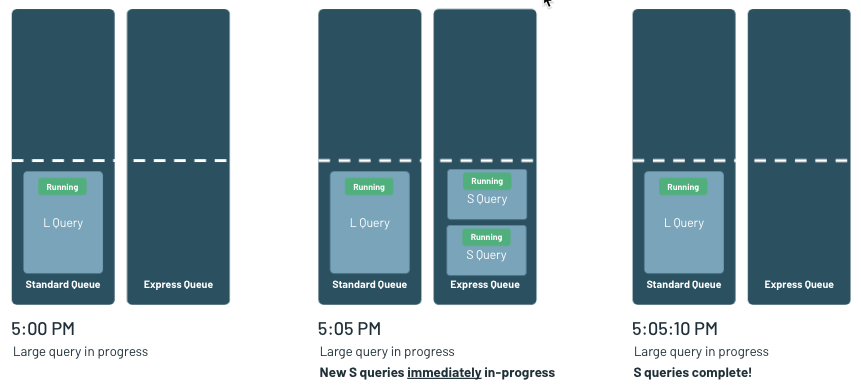
シナリオ 2:インテリジェントなワークロード管理
実環境のワークロードでは、大規模なクエリ、小規模なクエリという括りだけではありません。多くの場合、大・小規模のクエリが混在しています。そのため、Databricks SQL データベースのキューイングと負荷分散の機能において、この点も考慮する必要があります。アナリストは小規模なクエリのレイテンシを重視することが多いため、最新の Databricks SQL では、大規模なクエリよりも小規模なクエリを優先するデュアルキューイングシステムを採用しています。
ガートナー®: Databricks、クラウドデータベースのリーダー

シナリオ 3:並行性の高い読み取り
継続的に送り込まれる IoT データの取り込みのようなストリーミングシナリオなど、レイクハウスのテーブルのいくつかが、多くのファイルで構成されていることはよくあることです。レガシーシステムでは、実行エンジンがクエリを実行するよりも、このようなファイルのリスト作成に多くの時間を要することがあります。お客様からは「データの鮮度のために性能を犠牲にしたくない」という声もありました。
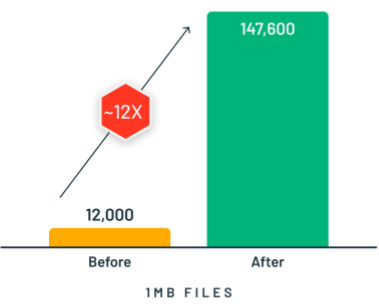
私たちは、Databricks SQL への非同期で並列性の高い IO の実装を実現しました。クエリを実行すると、Databricks は現在のデータブロックを処理している間に、クラウドストレージからデータの次のブロックを自動的に読み取ります。これにより、小規模なファイル(1 MB のファイルに対して 12 倍)や「コールドデータ」(キャッシュされていないデータ)のユースケースにおける全体的なクエリ性能が、大幅に向上し、高速化に寄与します。
シナリオ 4:Cloud Fetch による BI 結果取得の効率化
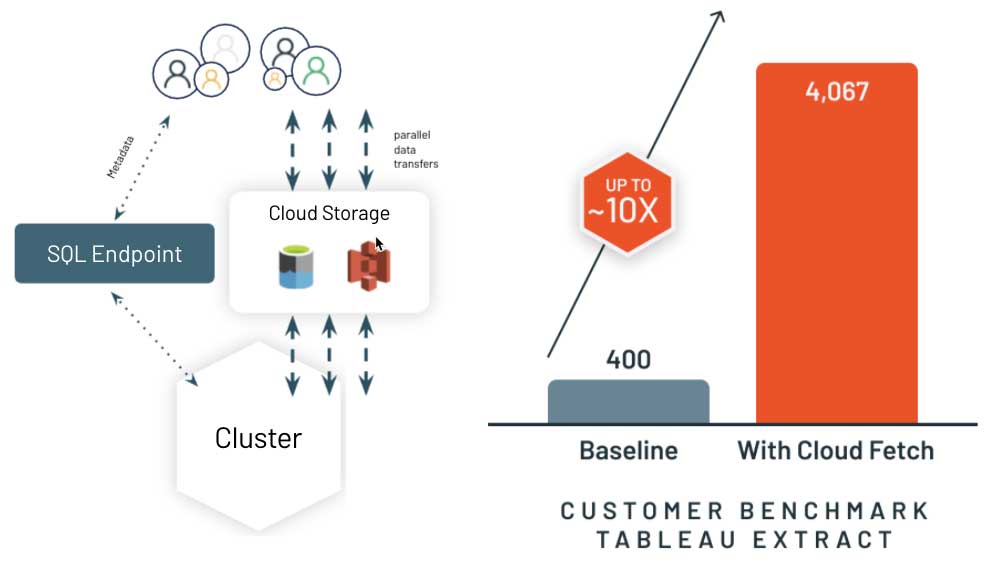
クエリの結果がコンピューティングされた後の重要な最終プロセスは、システムが PowerBI や Tableau などのクライアントに結果を迅速に提供することです。従来のクラウドデータウェアハウスは、多くの場合、結果をリーダー(ドライバ)ノードに収集し、クライアントに結果を返却します。数メガバイト以上の結果を取得する場合、BI ツールでの処理は大幅に遅延します。
そこで私たちは、新たなアーキテクチャ Cloud Fetch によるアプローチを再考しました。大規模な結果の場合、Databricks SQL は、全てのコンピューティングノードで並列に結果をクラウドストレージに書き込み、事前サイン済みの URL を用いてファイルのリストをクライアントに送り返します。クライアントはデータをクラウドストレージから並列でダウンロードできます。Databricks SQL をご利用中のお客様の実シナリオにおいて、最大で 10 倍の速度改善が報告されています。私たちは、主要な BI ツールと連携させ、この機能の自動化を実現しました。
Databricks SQL の仕組み
これらは、オープンなアプローチの利点、任意のデータレイクでのクラス最高の SQL パフォーマンスを提供する Databricks SQL における性能の最適化とイノベーションのほんの一例です。では、Databricks SQL はどのような仕組みになっているのでしょうか?
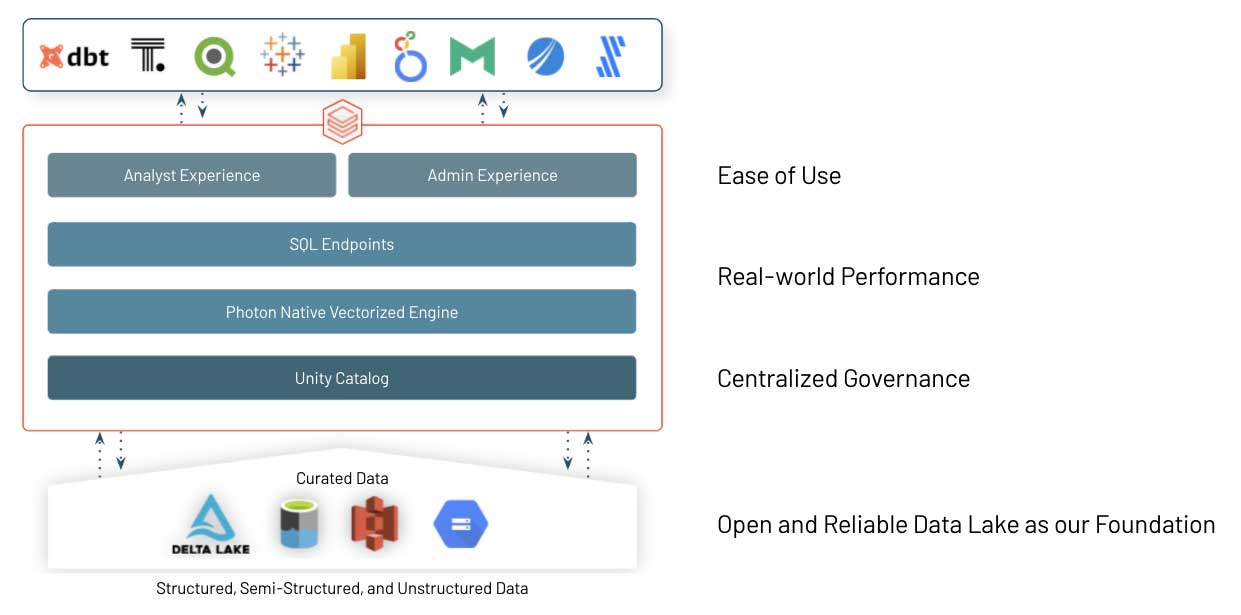
Databricks SQL の基盤は、オープンソースの Delta Lake です。Delta Lake は、ACID トランザクション、データリネージ、バージョニング、データシェアリングなどの機能を備え、構造化、非��構造化、半構造化データの種類を問わず、データウェアハウスシステムの利点をデータレイクにもたらすオープンデータストレージフォーマットです。
Databricks SQL のコアは、SQL ワークロードの高速実行を可能にする Databricks の新たなネイティブベクトル化エンジン Photon です。Photon についての詳細は、こちらのブログ記事、あるいは Radical Speed for SQL Queries on Databricks:Photon Under the Hood(Databricks の SQL クエリを画期的に高速化:Photon の仕組み)をご覧ください。
私たちは、データチーム(アナリスト、データサイエンティスト、SQL 開発者)が Databricks SQL で任意のツールを容易に活用できるように、多くのソフトウェアベンダーと緊密に連携しています。接続、データの取り込み、シングルサインオンによる認証をシンプルにし、先述した同時実行性とクエリ性能の改善により、高速性を実現しています。
次のステップ
Databricks では、今後もヒアリングを継続し、お客様に役立てていただけるようなイノベーションを提供してまいります。Databricks SQL は、既に Atlassian や Comcast をはじめとする多くのお客様に多大な価値を提��供しています。貴社においてもぜひご活用ください。
Databricks のお客様は、今すぐ最新の Databricks SQL をご利用いただけます。詳しくは、Azure Databricks または AWS 向けのスタートガイドをご覧ください。Databricks をまだご利用でない方には無料トライアルがお薦めです。databricks.com/try-databricks からお申し込みください。
Databricks のレイクハウスプラットフォームについて詳しく知りたい方は、Web セミナー Data Management, the good, the bad, the ugly をご視聴ください。Databricks SQL を実際に体験できるオンライントレーニングや、個人向けのワークショップも提供しています。詳しくは、営業担当者にお問い合わせください。また、利用方法やデータレイクでの BI やデータ分析のシンプル化など、お客様における Databricks SQL の活用について、ぜひお聞かせください。
Data+AI Summit の基調講演、デモを視聴する