臨床データによる腫瘍学の知見抽出に NLP を活用
公開日: 2021年9月22日
によって アミール・カーマニー、Moritz Steller、David Talby 、 マイケル・サンキー による投稿
このブログで参照しているソリューションアクセラレータのノートブックは、オンラインでご参照いただくか、ノートブックをダウンロードしてお使いの Databricks アカウントにインポートすることで、すぐにご利用いただけます。
米国における死亡原因および疾病原因の第 1 位は悪性腫瘍(がん)です。その数は驚異的で、今年、米国では新たに診断されるがん患者は約 200 万人になると予想されています。また、米国における医療費は、悪性腫瘍(がん)に関連するものが大部分を占めており、その額は、2020 年で 2,000 億ドルを超えると推定されています。このため、バイオ医薬品業界では、がん治療のための創薬に特に注力しています。2019 年、2020 年だけでも、FDA によっておよそ 40 種類の新たな抗がん剤が承認されており、1,300 種類以上の新薬、ワクチンが臨床開発段階にあ�ります。
患者に適切な治療を提供するためには、腫瘍治療の効果を計測が重要となります。オンコロジー(腫瘍学)データとそれに関連するリアルワールドのエビデンスは、臨床研究、臨床試験のデザイン、規制上の意思決定、安全性の評価、治療計画などに情報を提供するポテンシャルを持っています。しかし、腫瘍治療の高度な専門性から、疾患の基準やエンドポイントは多くのケースで構造化されたフォーマットでは利用できず、データサイロに閉じ込められたままとなっており、集約や分析を困難なものにしています。
腫瘍学の分野においては、病理学のレポート(ほとんどの場合 PDF フォーマットであり、EMR システムのサイロに格納される)には、腫瘍のサイズ、グレード、ステージ、組織構造などの重要な情報が含まれています。自然言語処理(NLP)システムによって抽出された変数は、疾患のコホートの定義、疾患の重症度の評価、病状進行のベースラインを作成に活用でき、前述した臨床試験のマッチングや治療計画などのユースケースに適用できます。しかし、構造化されていない診療テキストデータから情報を抽出することが、データチームにとって極めて大きな課題となる場合があります。
ヘルスケア NLP のリーダーであるジョン・スノー・ラボと Databricks は、この問題に正面から取り組み、ヘルスケアエコシステムにおける多くのお客様と協業し、構造化されていない腫瘍学データを実用的なエビデンスに変換しています。
Databricks とジョン・スノー・ラボによる大規模な医療自然言語処理
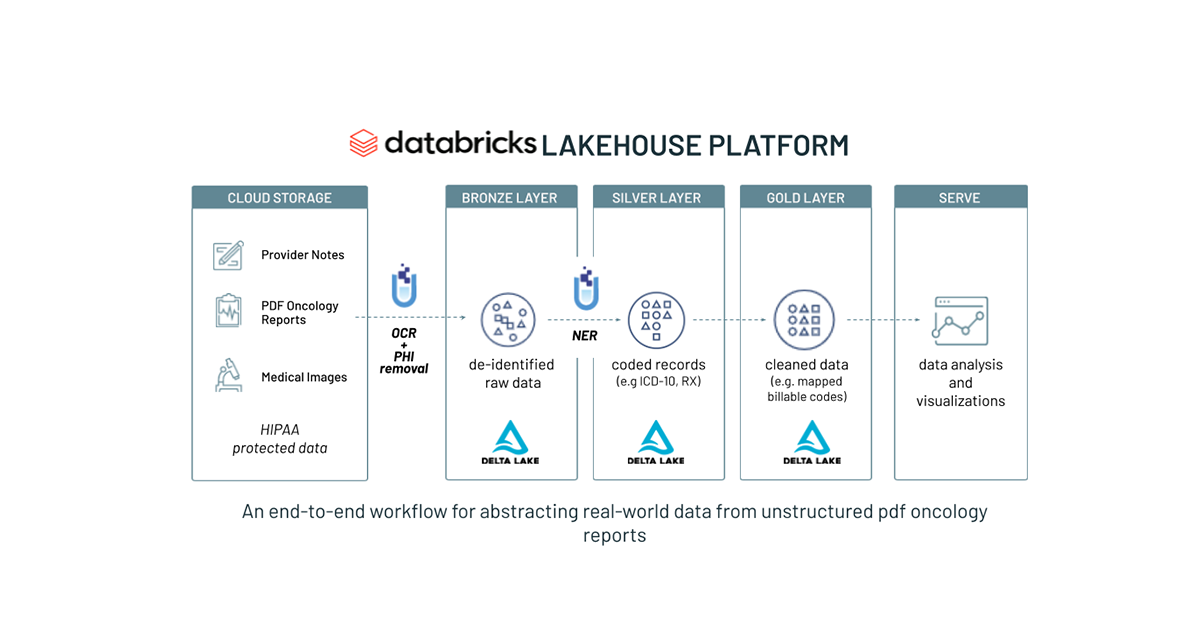
このソリューションの基盤は、データ管理、性能などのデータウェアハウスの優れた要素と、クラウドデータレイクの低コスト、柔軟性、スケーラビリティを兼ね備えたモダンなデータプラットフォームである Databricks のレイクハウスプラットフォームです。この、ヘルスケアシステムを有用にする新たなシンプルなアーキテクチャは、構造化データ(EHR データベースにおける診断/プロシージャコード)、半構造化データ(HL7、FHIR メッセージ)、非構造化データ(フリーテキストのメモや画像)といったあらゆるデータを単一の高性能なプラットフォームに統合し、従来の分析とデータサイエンス両方に対応します。

Databricks のレイクハウスプラットフォームには、データレイクに性能(Apache Spark™ を通じて)、信頼性、ガバナンスをもたらす、オープンソースストレージレイヤーの Delta Lake が中核にあります。ヘルスケア機関は、未加工の診断書、放射線医学レポート、PDF の病理レポートなど、あらゆるデータを Delta Lake に格納できます。これにより、データ変換を実行する前に、信頼できる唯一のソースを保持できます。一方、従来のデータウェアハウスでは、変換はデータを読み込む前に実行されます。そのため、非構造化テキストから抽出された全ての構造化変数は、ネイティブのテキストから切り離された状態になります。
このレイクハウスの基盤上に、 ジョン・スノー・ラボによる医療・ヘルスケアのための Spark NLP が構築されています。これは、ヘルスケア・ライフサイエンス業界で最も広く使用されている NLP ライブラリです。Databricks 上で動作するように最適化されたヘルスケア向け Spark NLP は、医療、生物医学テキストデータをシームレスかつ大規模、最先端の精度で、分類、構造化、抽出します。Python、Java、Scala に対応している唯一のネイティブ分散オープンソーステキスト処理ライブラリであり、全ての Spark NLP パイプラインは Spark ML パイプラインであるため、統合された NLP、機械学習パイプラインの構築に特に適しています。Spark NLP は、従来の NLP ライブラリ(spaCy、nltk、Stanford CoreNLP、Open NLP など)の機能に加え、スペルチェック、感情分析、文書分類などの追加機能を備えた Python、Java、Scala のライブラリを提供します。Databricks とジョン・スノー・ラボのジョイントソリューションの詳細に関しては、以�前のブログ記事「医療分野における NLP(自然言語処理)の大規模な活用方法とは」をご参照ください。
ETL を実行する

リアルワールドの腫瘍学データを抽出
Databricks とジョン・スノー・ラボによるソリューションの成果を実証するために、オンコロジーレポートからリアルワールドデータ(RWD)を抽出するソリューションアクセラレータを作成しました。このソリューションアクセラレータには、ダウンストリーム分析およびリアルワールドのエビデンスのためのオンコロジーレポートの取り込み、準備に関するステップバイステップの手順書、構築済みのコード、サンプルデータが含まれています。ソリューションは Databrikcs ノートブックとして実行できるようになっています�。いますぐご利用できるように、以下にソリューションの簡単な手順を解説します。
本ソリューションにおいては、MT ONCOLOGY NOTES データセットを使用しました。これには、主に医療専門家によって書き起こされた医療記録のサンプルと、医療記録の一部を構成する特定のセクション、例えば、物理的検査(physical examination)あるいは PE、システムレビュー(review of system)あるいは ROS といったセクションにおける医療単語、フレーズの書き起こし、研究データ、精神状態の試験などから構成されています。
ここでは、非構造化テキストのソースとして MT Oncology notes データセットから匿名化された 50 のオンコロジーレポートを選択し、Delta Lake のブロンズレイヤーに未加工のテキストデータを取り込みました。デモのため、サンプル数を 50 に限定していますが、このソリューションアクセラレータで提供されるフレームワークは、数百万の診断ノート、テキストデータに対応しています。
このアクセラレータの最初のステップは、固有表現抽出(Named-Entity Recognition:NER)のさまざまなモデルを用いて変数を抽出することです。このために、最初に NLP パイプラインをセットアップします。これには、特にヘルスケア関係の NER 向けにトレーニングされた documentAssembler、sentenceDetector、tokenizer のような annotators が含まれます。以下の例では、医療 NER モデルである bionlp_ner と医療単語向けにトレーニングされたディープ NER モデルである jsl_ner を組み合わせました。中皮腫(mesothelioma)の患者には、咳などの症状があることがわかります。

テキストからの固有表現の抽出は、AI アシスト ETL の素晴らしい例となります。学習済みのディープラーニング(DL)モデルによって、ダウンストリームの医療分析で活用できるよう�に非構造化データを構造化フォーマットに変換することができます。
症状を抽出することで、メディケアリスクの調整のためのコーディング精度を改善し、Hierarchical Condition Category(HCC)コーディングを自動化するために使用される ICD-10 コードにマッピングできます。治療のパターンを分析し、症状と腫瘍学エンティティとの関係性を分析するために、このデータを活用できます。
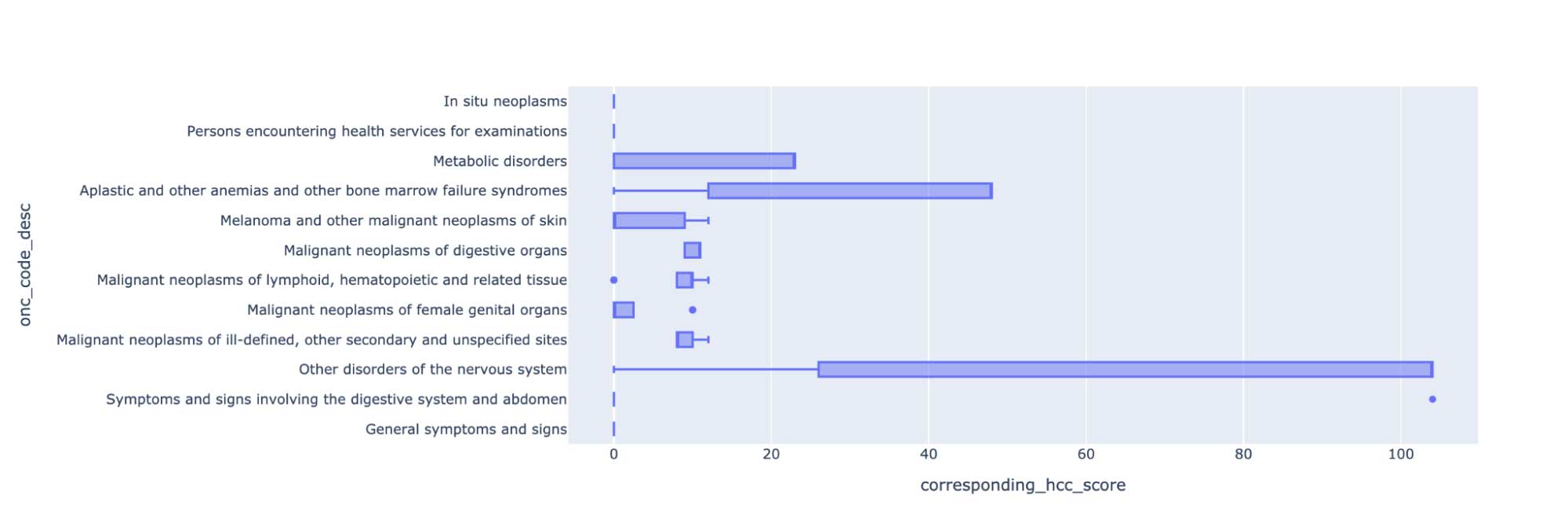
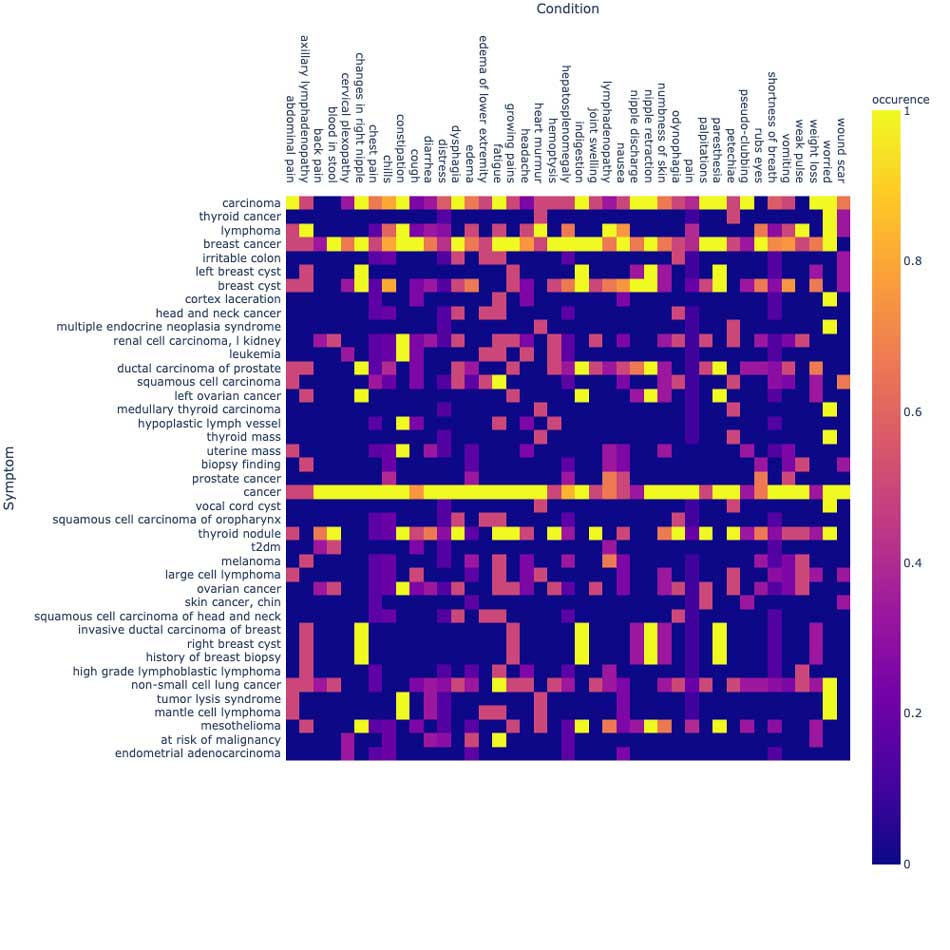
さらに、これらの症状の有無、あるいは、例えば家族など他の誰かと関連しているなどといった患者による訴えの状態を研究するためのチャートを作成できます。
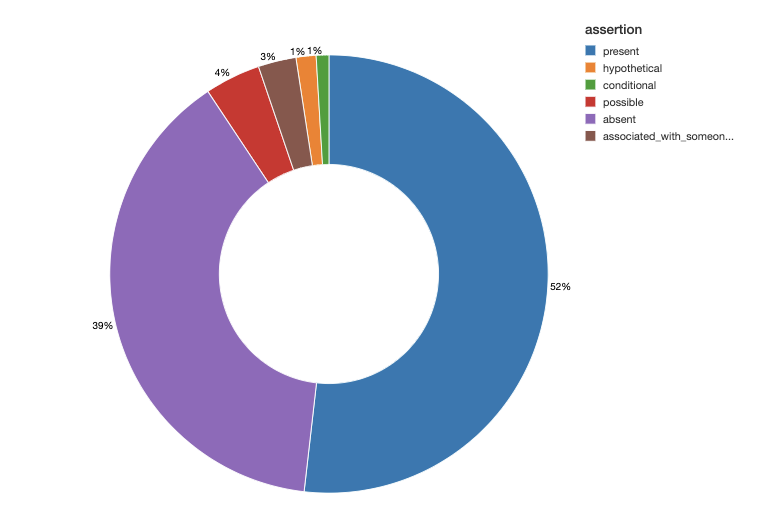
同じノートデータセットに対して、最も一般的な腫瘍学エンティティと患者の主訴を重ね合わせることで、解説的かつビジュアルな統計処理を実行できます。
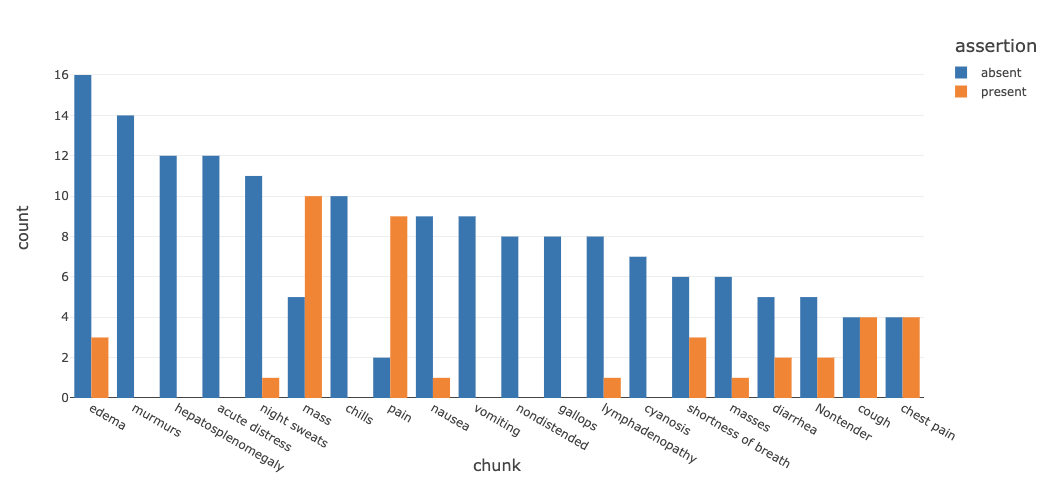
次に、投薬の頻度、期間を含む治療を見ていきます。これは、がん腫瘍治療の基礎となります。以下は投薬治療と期間に関する情報を抽出するソリューションノートブックに含まれている NLP モデルのスクリーンショットです。

これにより、治療に関連する症状や、再発などの疾患の状態を信頼スコアと関連付けることができます。

これらのデータは、個々の患者ケアの品質保証と、人工レベルの研究において重要なものであり、リアルワールドにおける介入の効果と安全性を判断するのに役立ちます。
Databricks のレイクハウスプラットフォームを用いることで、状態、症状、治療、そして構造化されていないノートから抽��出された他の適切な情報を含むデータベースを容易に構築することができ、ダウンストリームでの分析、医療上の意思決定サポート、研究に活用できるようになります。
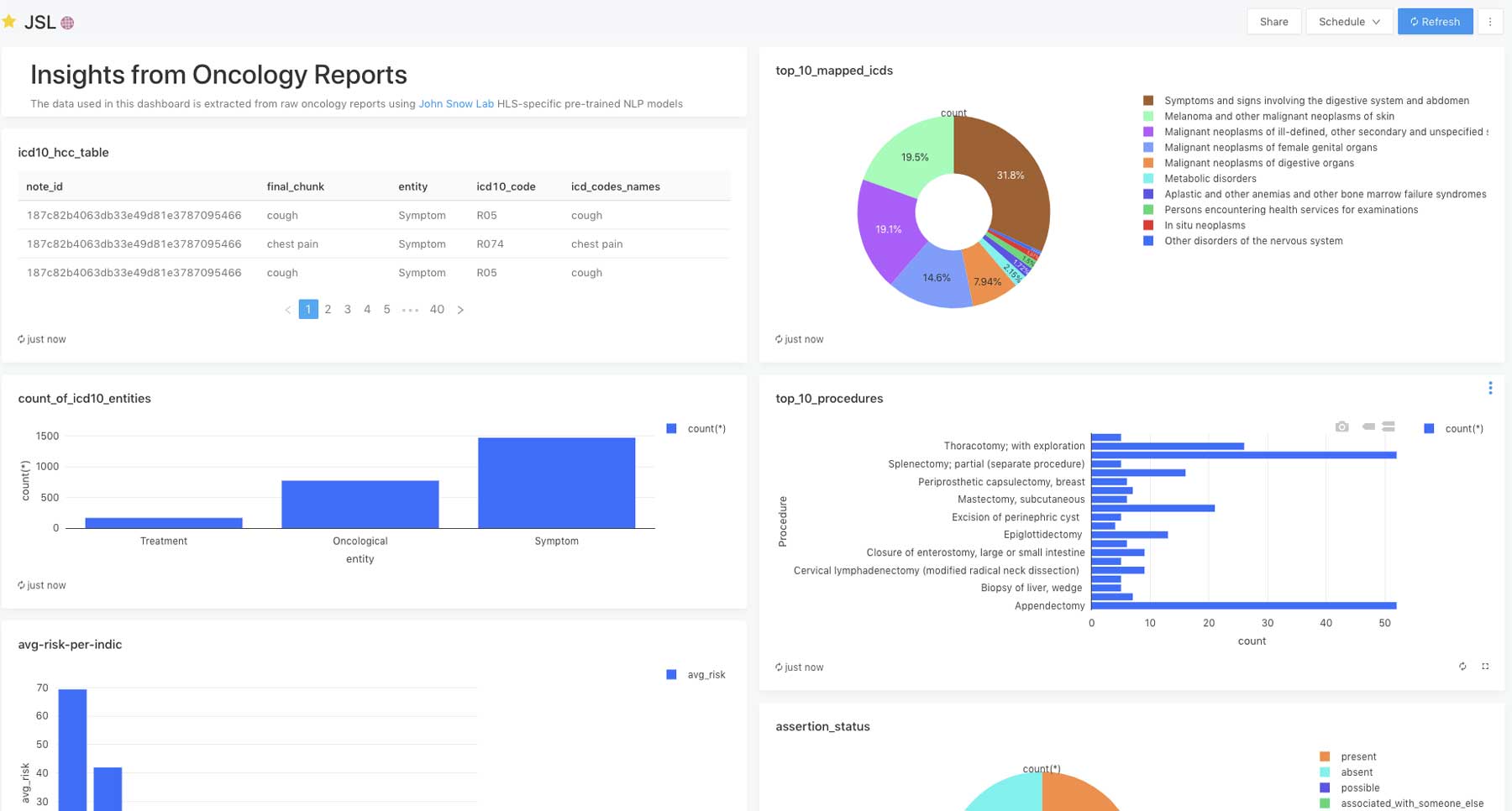
このソリューションアクセラレータにより、Databricks とジョン・スノー・ラボは、リアルワールドのエビデンス生成に求められる品質で大規模な腫瘍学データから情報を抽出できるようになりました。
NLP を活用したオンコロジーレポートからの RWD の抽出
このソリューションは、オンラインのノートブックを参照いただくか、またはノートブックをダウンロードしてお使いの Databricks アカウントにインポートすることですぐにご利用いただけます。このノートブックには、ジョン・スノー・ラボの関連する NLP ライブラリやライセンス�キーをインストールするためのガイダンスが含まれています。