Databricks と同等の価格性能を持つという Snowflake の主張に対する反論

データブリックスでは、Databricks SQL のレイクハウスプラットフォームが、データウェアハウスの公式世界記録を更新したことを 2021 年 11 月 2 日にブログで発表しました。この結果は、Transaction Processing Performance Council (TPC) によって公式に監査、報告されており、tpc.org にて 37 ページのドキュメントとしてオンラインで公開されています。また、そのブログで、サードパーティのバルセロナ・スーパーコンピューティング・センター(BSC)によるベンチマークテストの結果を共有し、Databricks SQL が競合 Snowflake よりも大幅に高速で高コスト効率であった結果もご報告しました。
ブログの公開後、多くのお祝いのメッセージやお問い合わせなど、さまざまな反響をいただきました。その中には負け惜しみと思われる意見もありました。私たちは、この機会に改めて、データウェアハウスのワークロード(TPC-DS)において、Databricks SQL が Snowflake よりも優れた価格性能を提供することをお伝えしたブログ記事の内容を支持することを表明します。
Snowflake 社の反応:「整合性の欠如」?
Snowflake 社は、私たちがブログを発表してから 10日後に、この結果は「整合性に欠けたものである」と反論する記事を公開しました。独自のベンチマーク結果を提示し、Snowflake 社が提供する製品は $267 であり、Databricks SQL の $242 と価格性能はほぼ同じであると主張しています。しかし、これは価格のみを見たもので、Snowflake 社の最も低価格な製品と、データブリックスが提供する最も高価な SQL を比較しているという事実を無視しています。(ビジネスクリティカル層の Snowflake は、一番低い層の製品と比べて 2 倍の価格です。)また、ほとんどのお客様が利用しているスポットインスタンスを Databricks で利用できる事実を無視して、価格を $146 まで下げています。しかし、私たちが今回のブログ記事でお伝えしたいのはこのことではありません。
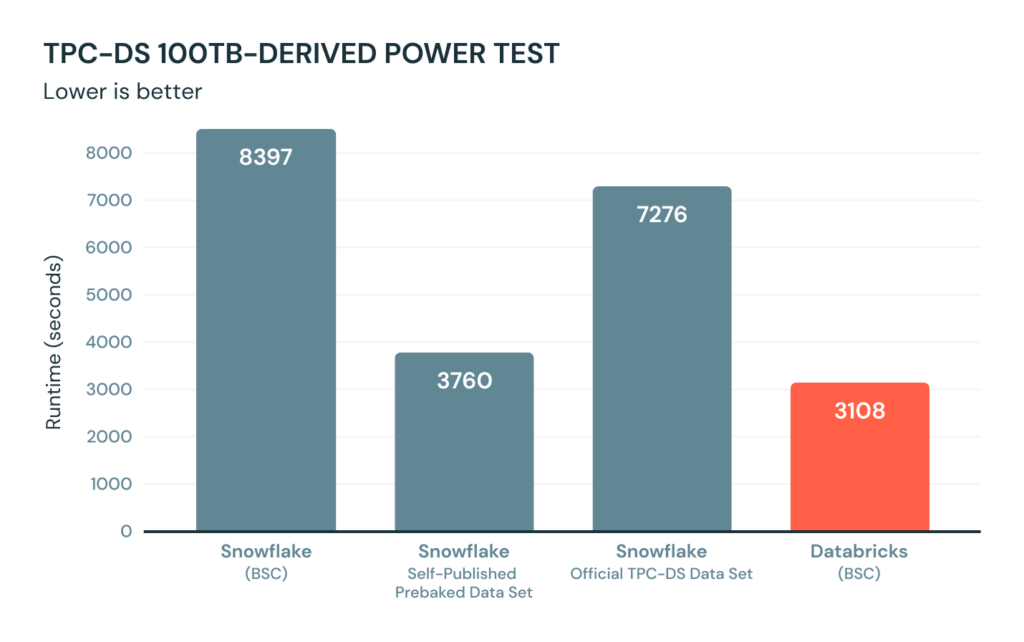
Snowflake 社の反論の主旨は、BSC と同じベンチマークテストを同社で実施した結果、Snowflake は BSC が測定したベンチマーク 8,397 秒よりも高速で、3,760 秒であったことです。Snowflake は何がすごいのかを理解するために、ブログ読者にアカウントを登録して実際に試してみることすら勧めています。TPC-DS データセットにはすぐに使用できる Snowflake が付属しており、実行方法のチュートリアルも用意されています。結果の検証が容易にできるはずなので、私た��ちも実行してみました。
検証結果をご報告する前にまず、Snowflake 社が私たちの呼びかけに応え、競合他社によるプラットフォームのベンチマークの公開を禁止する DeWitt 条項を削除してくれたことを感謝します。そのおかけで、私たちはトライアルアカウントを取得し、彼らが主張する「整合性の欠如」の根拠を確認することができました。
TPC-DS を Snowflake 上で再現
私たちは、Snowflake のアカウントを作成し、Snowflake の何がすごいのかを確認するため、TPC-DS の Tutorial 4 を実行しました。結果は、彼らが主張するベンチマークとほぼ一致する 4,025 秒で、 BSC が測定した 8,397 秒よりもはるかに高速でした。しかし、私たちはベンチマークの実行中に興味深いことに気づきました。
Snowflake 社によって事前準備された TPC-DS データセットは、ベンチマークの結果が発表されてから 2 日後に再作成されていたのです。公式なベンチマークテストの重要な点は、データセットの作成が検証されていることです。そこで私たちは、Snowflake 社によって事前準備されたデータセットではなく、公式な TPC-DS データセットをアップロードし、同じスキーマ(クラスタリングカラムのセットも含む)、クラスタサイズ(4XL) を検証に使用してみることにしました。POWER テストを 3 回実施し、時間を計測しました。最初のコールドランは 10,085 秒、3 回のうち最も速いものでも 7,276 秒でした。まとめると、公式の TPC-DS データセットを Snowflake にロードして実行した POWER テストの結果は、Snowflake 社が��ブログで報告している時間の 1.9倍 (最大 3 倍)かかったということです。
Databricks 101: 実践入門

この結果は誰でも容易に検証可能です。Snowflake のアカウントを取得し、公式の TPC-DS スクリプトを使用して、100 TB のデータウェアハウスを作成します。Snowflake にそれらのファイルをインジェストし、その後、POWER ランを何度か実行し、時間を計測するだけです。おそらく結果は、7,000 秒に近いものになるか、クラスタリングカラムを使用しない場合は、さらに長くかかるでしょう(クラスタリングカラムについては次のセクションで説明します)。また、Snowflake に同梱されているデータセットを使用して、POWER テストを実行��することも可能です。こちらの結果は、彼らがブログで報告しているものと近似したものになるでしょう。
公式 TPC-DS を使用する理由
Snowflake 社が事前準備したデータセットで TPC-DS を実行した場合と、公式データセットを Snowflake にロードした場合で、これほど大きな差がでるのはなぜでしょうか。私たちも正確にはわかりませんが、データをどのように配置するかは、TPC-DS をはじめとする、あらゆるワークロードに大きな影響を与えます。ほとんどのシステムでは、特定のワークロード(クエリで使用されるフィールドの組み合わせでソートするなど)のデータにクラスタリングやパーティショニングをすることで、ワークロードのパフォーマンスが改善します。しかし、そのような最適化には追加のコストが必要です。ベンチマーク結果には、そこにかかる時間とコストも含めるべきです。
公式ベンチマークテストでは、データウェアハウスへのデータのロードに要した時間をレポートするよう求められます。システムがレイアウトを最適化するために要した時間とコストを正しく計上するためです。この時間は、ストレージスキーマによっては、POWER テストクエリよりも長くかかることもあります。公式ベンチマークテストには、実世界のデータセットやワークロード同様に、データの更新やメンテナンスも含まれています。(変更のないデータセットをどのくらいの頻度でクエリしますか?)これは「システムが膨大なリソースを費やして、オフラインの静的データセットを不変のワークロードに最適化し、それらのワークロードを極めて高速に実行できるようにする」というシナリオを防ぐためです。
さらに、公式ベンチマークテストでは再現性が求められます。そのため submission で、私たちの記録を再現するコードを確認できるようになっています。
これが最後のポイントにつながります。ベンチマークは、業界関係者によってベンチマークを向上させるために、設定ノブや特別な設定、詳細な最適化を追加する形になりがちであるという Snowflake 社の意見に同意します。自社のベンチマークテストでは、誰でもよい結果を得ています。自社の製品をよく見せるベンダーのテスト結果を鵜呑みにしないためにも、私たちは、Snowflake 社に TPC の公式ベンチマークテストに参加することを求めます。
お客様の立場に立ったベンチマークテスト
データブリックスでは、このベンチマークテストへの参加を決めたとき、エンジニアリングチームに対して、過去のエントリーとは異なり、実際にお客様が行っている一般的な最適化のみ使用することの制約を設けました。Snowflake 社が事前準備したデータセットにクラスタリングカラムを追加して行ったような、データセットやクエリに対して深い理解を必要とする最適化の適用は許可しませんでした。これは、実世界のワークロード、多くのお客様が確認したいもの(チューニングをしなくても優れた性能を発揮するシステム)と一致します。
私たちが提出した内容の詳細をご覧いただければ、一般的なお客様のデータ管理方法に合致した再現可能なステップを見つけることができます。Databricks SQL の主要設計目標の 1 つは、新たなデータセットで生産性を高めるための労力を最小限に抑えることでした。
まとめ
データブリックスの共同創業者である私たちは、お客様に最高の価値を提供すること、お客様のビジネスニーズを解決するソフトウェアを構築することに注力しています。ベンチマークテストの結果が、自分の理解と一致しない場合、感情的、直感的な反応をしてしまう可能性があります。私たちはそのような状況に陥らないようベストを尽くします。検証可能なエンドツーエンドの結果を公表し、真実を追求します。私たちは、Snowflake 社がブログで公表した結果について、整合性に欠けるものだと非難するつもりはありません。しかし、その結果を公式な TPC 協議会で検証すべきだと主張します。
データブリックスが TPC のデータウェアハウスのベンチ―マークに参加した本来の動機は、どのデータウェアハウスが高速で安価であることを証明するためではありませんでした。むしろ、私たちは、あらゆる企業が FAANG 企業と同じようにデータドリブンになれるべきだと考えています。これらの企業はデータウェアハウスに依存していません。あらゆるデータ(構造化、テキスト、ビデオ、音声)をオープンフォーマットで格納し、データサイエンス、機械学習、リアルタイム分析、従来の BI やデータウェアハウスなど、あらゆる種類の分析に単一のコピーを使用するなど、よりシンプルなデータ戦略を持っています。これらの企業では、SQL は Python、R、およびオープンソースエコシステム内のデータを活用する多数のツール同様、重要なツールの 1 つであり、SQL のみに全てを頼っていません。私たちは、このパラダイムをデータレイクハウスと呼んでいます。データレイクハウスはデータウェアハウスと異なり、データサイエンス、機械学習、リアルタイムストリーミングのネイティブなサポートを提供します。また、SQL や BI にもネイティブに対応しています。私たちが目指したのは、データレイクハウスがクラス最高の価格性能を実現できない、という神話を覆すことでした。そのために、Snowflake 社のように独自のベンチマークを作り出すのではなく、真実を追求すべく公式のベンチ―マークテストに参加することにしたのです。それゆえに、古典的なデータウェアハウスのワークロード(TPC-DS)においても、データレイクハウスのパラダイムが、データウェアハウスよりも優れた価格性能を実現したことを嬉しく思います。これにより、エンタープライズでは、データ管理に複数のデータレイク、データウェアハウス、ストリーミングシステムを維持する必要がなくなります。また、このシンプルなアーキテクチャによってリソースの再配置が可能になり、日々直面するビジネスニーズや問題の解決に注力できるようになります。