レイクハウスによるデータの民主化がアムジェンの医薬品開発・提供を加速

この記事は、アムジェン(Amgen)社のプロダクトオーナー Jaison Dominic 氏と、ディスティングイッシュドソフトウェアエンジニア Kerby Johnson 氏によるゲスト執筆記事です。
世界最大の独立系バイオテクノロジー企業であるアムジェンは、長い間、イノベーションの代名詞とされてきました。40 年にわたり、新しい医薬品製造プロセスを開拓し、命を救う医薬品を開発し、世界中の何百万人もの人々の生活にプラスの影響を及ぼしてきました。患者さんに最高のサービスを提供するという使命を果たし続けるために、私たちは最近、完全なデジタル変革という新たなイノベーションのジャーニーに乗り出しました。
研究開発の生産性向上からサプライチェーンや商品化の最適化まで、ビジネス全体の成果を上げるためのデータ活用を再考する過程で、データチームが解決しようとしている問題の種類がここ数年で劇的に変化していることがすぐに明らかになりました。さらに、これらの問題は、もはやスキルセットや部門、機能によって隔離されているわけではありません。その代わりに、最も影響力のある問題は部門横断的であり、異なる独自の専門知識を持つ人々を集めて、斬新な方法で問題を解決することが必要でした。近代化を目指す私たちは、デジタル変革のジャーニーの基盤として Databricks レイクハウスプラットフォームを選びました。その結果、さまざまな組織でデータの潜在能力を引き出し、業務効率を合理化し、創薬を加速させることができました。
今日、私たちは、他の人々が私たちのジャーニーから学び、自らのビジネス戦略に活かしてくれることを願い、そのサクセスストーリーを分かち合います。
データウェアハウスからデータレイクへ ― その中の課題
アムジェン社の臨床試験、製造、商業化という 3 つのコアバーティカルには、貴重なデータが豊富に存在します。しかし、データ量の増加により、そのデータを実際に効率的に利用することが課題となっていました。
私たちは、ビジネスのさまざまな側面を真に結びつけることができず、社内と顧客数の両方が拡大するにつれて、業務効率に影響を及ぼしていました。重要なのは、データへのアクセスと処理を容易にするだけでなく、データに対して異なる視点を持つペルソナを結び付け、部門を超えたコラボレーションを可能にするコネクテッドデータファブリックを実現することでした。もしあなたが 1 つか 2 つの視点からしか見ていないなら、他の人からの貴重なキーポイントを見逃すことになるでしょう。
例えば、次のような質問を考えてみましょう。どのように需要をきめ細かく予測すれば、必要としている患者さんに適切な量の治療薬を提供することができるでしょうか?
サプライチェーンと製造の観点から答えを見ている場合、商業販売予測データが不足しています。一方、販売予測を必要な生産量の福音と見なしたくはないでしょう。なぜなら、もし販売予測が大外れで、製造に必要な生産量を過小評価していたとしたらどうでしょう。
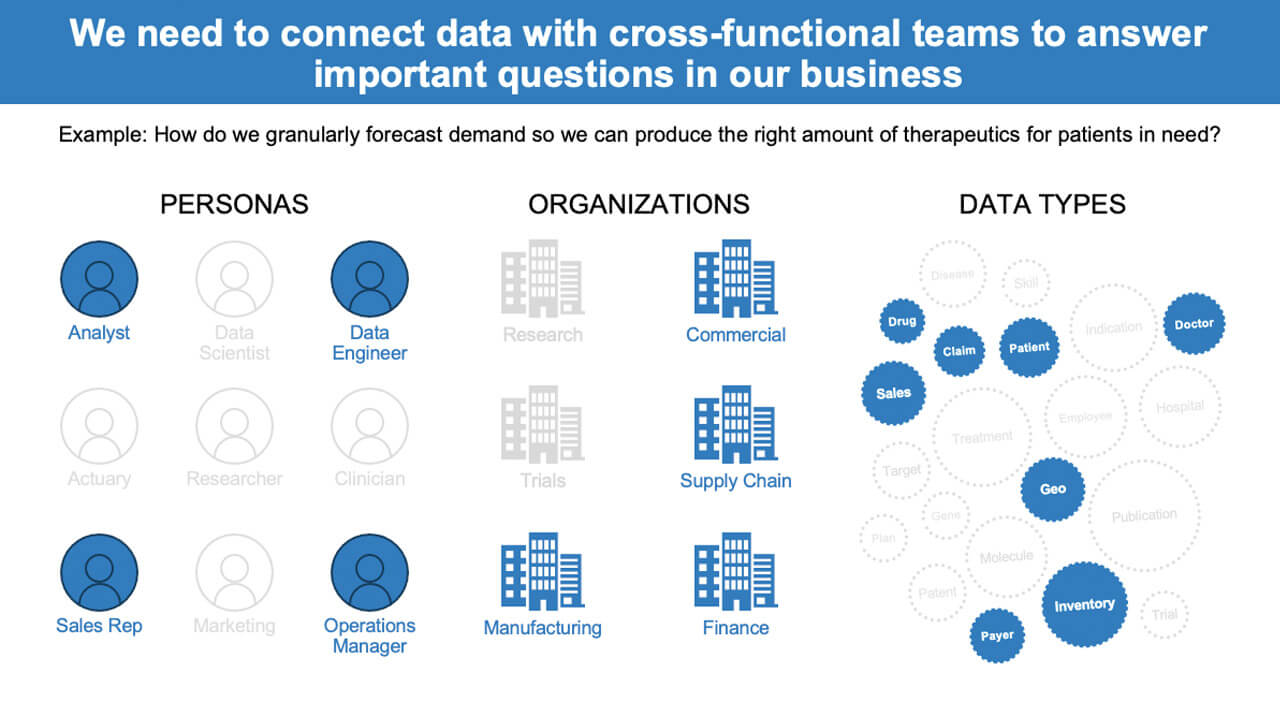
今日の問題を解決するために、企業は同じデータを複数のレンズから見ることができるように、さまざまなデータの関係や接続に注目する必要があります。しかし、どうすればこれを可能にできるのでしょうか?アムジェンは、現代のデータ要件の基礎を以下のように分解しています。
- データは整理され、使いやすくなっている必要があります。
- データを共有し、自然な形で他者のデータを再利用することが必要です。
- アナリティクスは、信頼できるデータの共有ビューから操作できるようにする必要があります。
- 記述的分析(BI)から予測的分析(ML)まで、さまざまな形式の分析が、1 つのバージョンのデータで新しい発見や予測を促進するのに役立ちます。
- データは、新しい種類のものが入ってきたり、あるシステムから別のシステムに変わったり、新しいドメインが追加されたりするたびに進化していく必要がありますが、全ての核心は一貫している必要があります。
しかし、各チームがそれぞれ異なるデータを所有し、管理し、整理しているため、データを共有しようとすると別のプロジェクトが必要になるなど、直感的でないプロセスを持�つ企業にとっては特に難しいことでした。私たちも、数年にわたり、使い道がないほど多くのデータを蓄積してきただけでなく、誰もが同じデータで仕事ができるようにするためのプロセスやインフラの欠如に苦労してきました。
初期のデータニーズに対応するため、数年前にレガシーテクノロジーのインフラから Hadoop ベースのデータレイクに移行しました。Hadoop データレイクでは、構造化データと非構造化データを一箇所に集めることができましたが、技術面でもプロセス、コスト、組織面でも、データに関する大きな課題が残りました。共有クラスタは「Noisy Neighbor」問題を引き起こし、拡張が困難でコストがかかるという問題がありました。
プラットフォームのプロダクトオーナーである私の役割としては、単一の共有クラスターを管理することは悪夢でした。例えば、あるグループには高いストレージと低いコンピュート、別のグループには高いコンピュートと低いストレージというように、コストを分散して課金する方法を考えなければなりませんでした。
また、このアプローチでは、各グループのニーズを満たすためにさまざまなツールを組み合わせる必要があり、コラボレーションに大きな課題がありました。また、他の多くの企業と同様に、エンドユーザーがデータを利用する方法もさまざまでした。Jupyter Notebooks、R Studio、Spotfire、Tableau など、エンドユーザーがデータを利用する方法はさまざまで、データを必要とする人がすぐに利用できるようにすることは、複雑さと課題をさらに増やすことになったのです。
レイクハウスアーキテクチャが私たちの問題をどのように解決するか
Databricks レイクハウスプラットフォームを採用したことで、さまざまなチームやペルソナがデータをより有効に活用できるようになりました。この統一されたコラボレーションプラットフォームにより、あらゆるタイプのユーザーとその好みのツールが単一の環境で利用できるようになり、一貫したデータセットに裏打ちされたオペレーションを維持することができるようになりました。
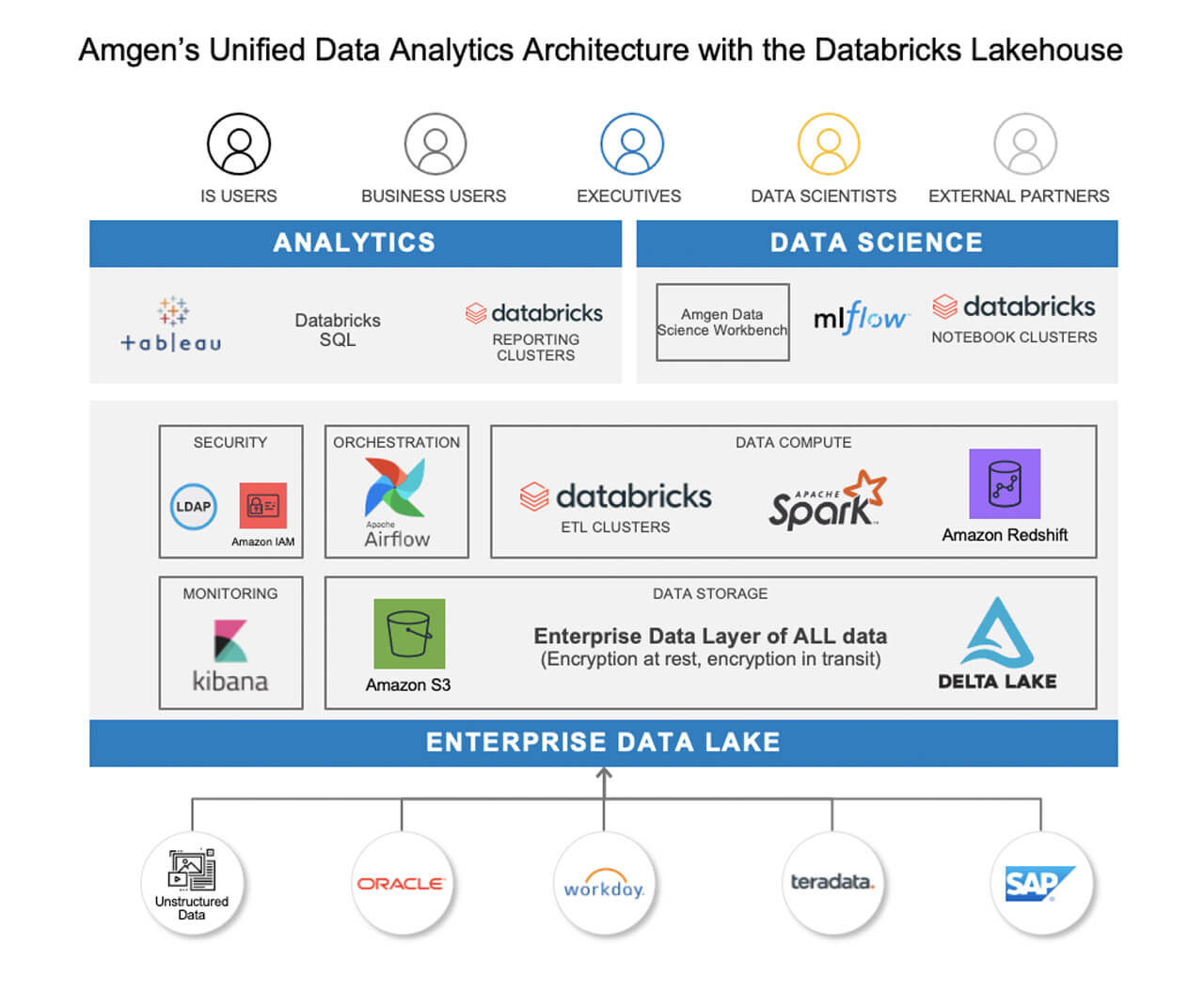
私たちは、Delta Lake を活用して、ACIDコンプライアンス、ヒストリカルルバック、そして開発者がコーディングを始める際の障壁を下げ、データアナリストやデータサイエンティストが同様にサプライチェーンの最適化やオペレーション改善にデータを活用できるよう共通のデータレイヤーを提供しています。また、AWS Glue を利用して異なる Databricks 環境を接続することで、データが 1 つの AWS アカウントに保存されているか、10 個の異なるアカウントに保存されているかを問わず、1つのデータレイクとなります。すべてつながっているのです。
これにより、データと分析のために Apache Spark™ を標準化しながら、様々なニーズに対して十分な柔軟性を提供することができました。レイクハウス内の統一されたデータレイヤーにより、アムジェン社はあらゆる種類とサイズのデータを確実に処理することができ、同時にアプリケーションチームにはビジネスを前進させる柔軟性を提供することができます。
欲しいクラスターの大きさは?予算は?レポートを 1 時間早く出すことが重要なのか、それともコストを削減することが重要なのか?このような判断は、個々のチームでもできるようになりました。このようにツールや言語を標準化し、データサイエンティスト、アナリスト、エンジニアのためのシングル・ソース・オブ・トゥルースを実現することで、コネクテッド・チームの実現が可能になったのです。
現在のデータアーキテクチャは、Amazon S3 をすべてのデータのシングルソースとして、Delta Lake を共通のデータレイヤーとして、Glue データカタログを Databricks の集中メタストアとして、ELK スタックを Kibana でモニタリングに、Airflow をオーケストレーションに、アナリストやデータサイエンティストの消費はすべて Databricks レイクハウスプラットフォームから操作するようになっています。
この共通データアーキテクチャとアーキテクチャパターンの統合により、プラットフォームのメンテナンスから、ビジネスが実際に何を求めているか、ユーザーが何に関心を持っているかを深く掘り下げることへと、私たちのフォーカスを移行することができました。重要なのは、レイクハウスアプローチを活用して、さまざまなデータチーム間でデータを統一しながら、ビジネス目標に沿うことができるようになったことです。
データをすぐに利用できるため、エンジニアリングからデータサイエンス、アナリストまで、さまざまなデータチームがデータにアクセスし、コラボレーションを行うことができ��ます。Databricks のコラボレーションノートブックは、彼らが選択したプログラミング言語をサポートし、簡単にデータを探索し、ダウンストリーム分析や ML への活用を開始することができます。Databricks SQLを使い始めると、アナリストはデータをデータウェアハウスに移動することなく、最新かつ新鮮なデータを見つけて探索できるようになります。パフォーマンスを犠牲にすることなくクエリを実行し、内蔵のビジュアライゼーションやダッシュボード、または社内のビジネスパートナーが主に使用する Tableau など、選択したツールで簡単に結果を可視化することができます。
当社のデータサイエンティストも、Databricks Machine Learning を使用してMLのあらゆる側面を簡素化することで利益を得ています。Databricks ML は Delta Lake と MLflow を含むレイクハウス基盤上に構築されているため、当社のデータサイエンティストはデータエンジニアリングのサポートに依存せずに、データの準備と処理、チーム間のコラボレーションの効率化、実験から生産までのライフサイクルの標準化を行うことができます」。このようなML管理アプローチの改善は、臨床試験の登録にかかる時間の短縮に直接的な影響を及ぼしました。
Databricks 101: 実践入門

コネクテッドデータとチームによる患者転帰(アウトカム)の改善
Databricks レイクハウスプラットフォームの導入は、現代社会で患者にサービスを提供し、医薬品開発のライフサイクルを改善するという当社の目標を達成し続けるために、最終的に役立っています。データの取り込み率が大幅に向上し、処理時間が 75% 短縮された結果、ビジネスへのインサイトを 2 倍早く提供できるようになりました。
Databricks を利用することで、技術だけでなく、データ、関係、つながりに着目したモダンなアプローチで、無数のユースケースを実現することができるのです。2017 年に Databricks と提携して以来、全社的に大規模な成長導入が進んでいます。現在までに、データエンジニアリングからアナリストまで 2,000 人以上のデータユーザーが Databricks を通じて 400 TB のデータにアクセスし、40 以上のデータレイクプロジェクトと 240 のデータサイエンスプロジェクトを支援しています。

実際にどのようなものかというと、使いやすく、見つけやすいデータで、会社全体のさまざまなユースケースを可能にするものです。
- ゲノムの探索と研究を大規模にゲノムデータの力を活用することで、創薬プロセスを加速することができます。これにより、悲惨な病気を治療するための新薬を見つけるチャンスが大幅に増えるでしょう。
- 臨床試験デザインの最適化購入データから実際のエビデンスまで、さまざまなデータを取り込み、この多種多様な臨床データからの洞察を活用することで、成功の可能性を高め、数千万ドルのコスト削減を実現できる可能性があるようになりました。
- サプライチェーンと在庫の最適化製造効率と在庫管理は、すべての製造業にとって課題であり、医薬品製造も例外ではありません。効率的な製造と最適なサプライチェーン管理は、ビジネスに数百万ドルの節約をもたらし、適切な患者に適切な薬を適切なタイミングで届けることに貢献します。

アムジェン社の成功が示すように、古くからある問題に対する斬新な解決策には、ビジネスのプラットフォーム、ツール、イノベーションの方法を一新することが必要です。アムジェン社での採用が進むにつれ、私たちは、Delta Sharing のようなツールを使って、コラボレーションと透明性を促進する湖水型アプローチを活用する新しい方法を探っていきます。また、Delta Live Tables は、ETL の開発と管理をさらに簡素化し、下流のデータ消費者に利益をもたらす可能性のある、魅力的なツールです。最終的には、Databricks のおかげで高度な分析のスタートラインに立つことができ、治療を必要とする患者のためになる問題解決により多くの時間を費やし、それを可能にする基盤インフラの再構築に時間をかけずに済むようになりました。
次のステップ
- Databricks Lakehouse for Healthcare and Life Sciences の詳細
- 最近の Web セミナーでのアムジェン社による講演
